18 KiB
Jälkikirjoitus: Mallin virheenkorjaus koneoppimisessa vastuullisen tekoälyn hallintapaneelin komponenttien avulla
Esiluennon kysely
Johdanto
Koneoppiminen vaikuttaa päivittäiseen elämäämme. Tekoäly löytää tiensä joihinkin tärkeimpiin järjestelmiin, jotka vaikuttavat meihin yksilöinä ja yhteiskuntana, kuten terveydenhuoltoon, rahoitukseen, koulutukseen ja työllisyyteen. Esimerkiksi järjestelmät ja mallit osallistuvat päivittäisiin päätöksentekotehtäviin, kuten terveysdiagnooseihin tai petosten havaitsemiseen. Tekoälyn kehitys ja sen nopeutunut käyttöönotto kohtaavat kuitenkin jatkuvasti muuttuvia yhteiskunnallisia odotuksia ja kasvavaa sääntelyä. Näemme jatkuvasti alueita, joissa tekoälyjärjestelmät eivät täytä odotuksia; ne paljastavat uusia haasteita, ja hallitukset alkavat säännellä tekoälyratkaisuja. Siksi on tärkeää analysoida näitä malleja, jotta ne tuottavat oikeudenmukaisia, luotettavia, osallistavia, läpinäkyviä ja vastuullisia tuloksia kaikille.
Tässä oppimateriaalissa tarkastelemme käytännön työkaluja, joita voidaan käyttää arvioimaan, onko mallissa vastuullisen tekoälyn ongelmia. Perinteiset koneoppimisen virheenkorjaustekniikat perustuvat yleensä kvantitatiivisiin laskelmiin, kuten keskimääräiseen tarkkuuteen tai virhehäviöön. Kuvittele, mitä voi tapahtua, kun käyttämäsi data mallien rakentamiseen ei sisällä tiettyjä demografisia ryhmiä, kuten rotua, sukupuolta, poliittista näkemystä tai uskontoa, tai edustaa näitä ryhmiä epätasaisesti. Entä jos mallin tulkinta suosii jotakin demografista ryhmää? Tämä voi johtaa tiettyjen herkkien ominaisuusryhmien yli- tai aliedustukseen, mikä aiheuttaa mallin oikeudenmukaisuus-, osallistavuus- tai luotettavuusongelmia. Lisäksi koneoppimismalleja pidetään usein "mustina laatikoina", mikä vaikeuttaa ymmärtämistä ja selittämistä, mikä ohjaa mallin ennusteita. Nämä ovat haasteita, joita data-analyytikot ja tekoälykehittäjät kohtaavat, kun heillä ei ole riittäviä työkaluja mallin oikeudenmukaisuuden tai luotettavuuden arviointiin.
Tässä oppitunnissa opit virheenkorjaamaan mallejasi seuraavien avulla:
- Virheanalyysi: tunnista, missä datan jakaumassa mallilla on korkeat virheprosentit.
- Mallin yleiskatsaus: suorita vertailuanalyysi eri datakohorttien välillä löytääksesi mallin suorituskykymittareiden eroja.
- Data-analyysi: tutki, missä datan yli- tai aliedustus voi vääristää mallia suosimaan yhtä demografista ryhmää toisen sijaan.
- Ominaisuuksien merkitys: ymmärrä, mitkä ominaisuudet ohjaavat mallin ennusteita globaalilla tai paikallisella tasolla.
Esitietovaatimukset
Esitietovaatimuksena tutustu Vastuullisen tekoälyn työkaluihin kehittäjille

Virheanalyysi
Perinteiset mallin suorituskykymittarit, joita käytetään tarkkuuden mittaamiseen, perustuvat pääasiassa oikeiden ja väärien ennusteiden laskemiseen. Esimerkiksi mallin, joka on tarkka 89 % ajasta ja jonka virhehäviö on 0,001, voidaan katsoa suoriutuvan hyvin. Virheet eivät kuitenkaan usein jakaudu tasaisesti taustalla olevassa datassa. Saatat saada 89 %:n tarkkuusluvun, mutta huomata, että tietyillä datan alueilla malli epäonnistuu 42 % ajasta. Näiden virhekuvioiden seuraukset tietyissä dataryhmissä voivat johtaa oikeudenmukaisuus- tai luotettavuusongelmiin. On tärkeää ymmärtää, missä mallin suorituskyky on hyvä ja missä ei. Dataryhmät, joissa mallilla on korkea virheprosentti, voivat osoittautua tärkeiksi demografisiksi ryhmiksi.

RAI-hallintapaneelin virheanalyysikomponentti havainnollistaa, miten mallin virheet jakautuvat eri kohorttien välillä puun visualisoinnin avulla. Tämä auttaa tunnistamaan ominaisuuksia tai alueita, joissa datasetissä on korkea virheprosentti. Näkemällä, mistä suurin osa mallin virheistä tulee, voit alkaa tutkia ongelman juurisyytä. Voit myös luoda datakohortteja analysointia varten. Nämä datakohortit auttavat virheenkorjausprosessissa selvittämään, miksi mallin suorituskyky on hyvä yhdessä kohortissa mutta virheellinen toisessa.

Puun visualisoinnin värilliset indikaattorit auttavat paikantamaan ongelma-alueet nopeammin. Esimerkiksi mitä tummempi punainen väri puun solmussa on, sitä korkeampi virheprosentti.
Lämpökartta on toinen visualisointitoiminto, jota käyttäjät voivat käyttää tutkiessaan virheprosenttia yhden tai kahden ominaisuuden avulla löytääkseen mallin virheiden aiheuttajia koko datasetissä tai kohorteissa.

Käytä virheanalyysiä, kun tarvitset:
- Syvällistä ymmärrystä siitä, miten mallin virheet jakautuvat datasetissä ja useiden syöte- ja ominaisuusulottuvuuksien välillä.
- Yhdistettyjen suorituskykymittareiden purkamista automaattisesti virheellisten kohorttien löytämiseksi, jotta voit suunnitella kohdennettuja korjaustoimenpiteitä.
Mallin yleiskatsaus
Koneoppimismallin suorituskyvyn arviointi vaatii kokonaisvaltaista ymmärrystä sen käyttäytymisestä. Tämä voidaan saavuttaa tarkastelemalla useampaa kuin yhtä mittaria, kuten virheprosenttia, tarkkuutta, muistia, tarkkuutta tai MAE:ta (Mean Absolute Error), jotta löydetään suorituskykymittareiden välisiä eroja. Yksi suorituskykymittari voi näyttää hyvältä, mutta epätarkkuudet voivat paljastua toisessa mittarissa. Lisäksi mittareiden vertailu datasetin tai kohorttien välillä auttaa valottamaan, missä malli suoriutuu hyvin ja missä ei. Tämä on erityisen tärkeää mallin suorituskyvyn tarkastelussa herkkien ja ei-herkkien ominaisuuksien välillä (esim. potilaan rotu, sukupuoli tai ikä), jotta voidaan paljastaa mahdollinen mallin epäoikeudenmukaisuus. Esimerkiksi, jos havaitaan, että malli on virheellisempi kohortissa, jossa on herkkiä ominaisuuksia, tämä voi paljastaa mallin mahdollisen epäoikeudenmukaisuuden.
RAI-hallintapaneelin Mallin yleiskatsaus -komponentti auttaa analysoimaan datakohorttien suorituskykymittareita ja antaa käyttäjille mahdollisuuden vertailla mallin käyttäytymistä eri kohorttien välillä.

Komponentin ominaisuuspohjainen analyysitoiminto antaa käyttäjille mahdollisuuden rajata datan alaryhmiä tietyn ominaisuuden sisällä, jotta poikkeavuudet voidaan tunnistaa tarkemmalla tasolla. Esimerkiksi hallintapaneelissa on sisäänrakennettu älykkyys, joka automaattisesti luo kohortteja käyttäjän valitsemalle ominaisuudelle (esim. "time_in_hospital < 3" tai "time_in_hospital >= 7"). Tämä mahdollistaa käyttäjän eristää tietyn ominaisuuden suuremmasta dataryhmästä ja nähdä, onko se avaintekijä mallin virheellisissä tuloksissa.

Mallin yleiskatsaus -komponentti tukee kahta eriarvoisuusmittariluokkaa:
Mallin suorituskyvyn eriarvoisuus: Nämä mittarit laskevat eriarvoisuuden (erot) valitun suorituskykymittarin arvoissa datan alaryhmien välillä. Esimerkkejä:
- Tarkkuusprosentin eriarvoisuus
- Virheprosentin eriarvoisuus
- Tarkkuuden eriarvoisuus
- Muistin eriarvoisuus
- Keskiabsoluuttisen virheen (MAE) eriarvoisuus
Valintaprosentin eriarvoisuus: Tämä mittari sisältää valintaprosentin (suotuisa ennuste) eron alaryhmien välillä. Esimerkki tästä on lainan hyväksymisprosenttien eriarvoisuus. Valintaprosentti tarkoittaa datan pisteiden osuutta kussakin luokassa, joka on luokiteltu 1:ksi (binaariluokittelu) tai ennustearvojen jakaumaa (regressio).
Data-analyysi
"Jos kidutat dataa tarpeeksi kauan, se tunnustaa mitä tahansa" - Ronald Coase
Tämä lausunto kuulostaa äärimmäiseltä, mutta on totta, että dataa voidaan manipuloida tukemaan mitä tahansa johtopäätöstä. Tällainen manipulointi voi joskus tapahtua tahattomasti. Ihmisinä meillä kaikilla on ennakkoluuloja, ja on usein vaikeaa tietoisesti tietää, milloin tuomme ennakkoluuloja dataan. Oikeudenmukaisuuden takaaminen tekoälyssä ja koneoppimisessa on edelleen monimutkainen haaste.
Data on suuri sokea piste perinteisille mallin suorituskykymittareille. Saatat saada korkeat tarkkuusluvut, mutta tämä ei aina heijasta datasetissä mahdollisesti olevaa taustalla olevaa datan ennakkoluuloa. Esimerkiksi, jos työntekijöiden datasetissä on 27 % naisia johtotehtävissä ja 73 % miehiä samalla tasolla, työpaikkailmoituksia tekevä tekoälymalli, joka on koulutettu tällä datalla, saattaa kohdistaa pääasiassa miesyleisöön johtotehtäviä varten. Tämä datan epätasapaino vääristi mallin ennustetta suosimaan yhtä sukupuolta. Tämä paljastaa oikeudenmukaisuusongelman, jossa tekoälymallissa on sukupuolinen ennakkoluulo.
RAI-hallintapaneelin Data-analyysi -komponentti auttaa tunnistamaan alueita, joissa datasetissä on yli- ja aliedustusta. Se auttaa käyttäjiä diagnosoimaan virheiden ja oikeudenmukaisuusongelmien juurisyitä, jotka johtuvat datan epätasapainosta tai tietyn dataryhmän edustuksen puutteesta. Tämä antaa käyttäjille mahdollisuuden visualisoida datasetit ennustettujen ja todellisten tulosten, virheryhmien ja tiettyjen ominaisuuksien perusteella. Joskus aliedustetun dataryhmän löytäminen voi myös paljastaa, että malli ei opi hyvin, mikä johtaa korkeisiin epätarkkuuksiin. Malli, jossa on datan ennakkoluuloja, ei ole vain oikeudenmukaisuusongelma, vaan se osoittaa, että malli ei ole osallistava tai luotettava.

Käytä data-analyysiä, kun tarvitset:
- Datasetin tilastojen tutkimista valitsemalla eri suodattimia datan jakamiseksi eri ulottuvuuksiin (tunnetaan myös kohortteina).
- Datasetin jakauman ymmärtämistä eri kohorttien ja ominaisuusryhmien välillä.
- Sen määrittämistä, johtuvatko oikeudenmukaisuuteen, virheanalyysiin ja kausaalisuuteen liittyvät havainnot (muista hallintapaneelin komponenteista) datasetin jakaumasta.
- Päätöstä siitä, mihin alueisiin kerätä lisää dataa virheiden lieventämiseksi, jotka johtuvat edustuksen ongelmista, luokittelumelusta, ominaisuusmelusta, luokitteluvääristymistä ja vastaavista tekijöistä.
Mallin tulkittavuus
Koneoppimismallit ovat usein "mustia laatikoita". Ymmärtäminen, mitkä keskeiset dataominaisuudet ohjaavat mallin ennustetta, voi olla haastavaa. On tärkeää tarjota läpinäkyvyyttä siitä, miksi malli tekee tietyn ennusteen. Esimerkiksi, jos tekoälyjärjestelmä ennustaa, että diabeetikko on vaarassa joutua takaisin sairaalaan alle 30 päivän kuluessa, sen tulisi pystyä tarjoamaan tukidataa, joka johti ennusteeseen. Tukidatan indikaattoreiden tarjoaminen tuo läpinäkyvyyttä, joka auttaa lääkäreitä tai sairaaloita tekemään hyvin perusteltuja päätöksiä. Lisäksi kyky selittää, miksi malli teki ennusteen yksittäisen potilaan kohdalla, mahdollistaa vastuullisuuden terveyssäädösten kanssa. Kun koneoppimismalleja käytetään tavoilla, jotka vaikuttavat ihmisten elämään, on ratkaisevan tärkeää ymmärtää ja selittää, mikä vaikuttaa mallin käyttäytymiseen. Mallin selitettävyys ja tulkittavuus auttavat vastaamaan kysymyksiin tilanteissa, kuten:
- Mallin virheenkorjaus: Miksi mallini teki tämän virheen? Miten voin parantaa malliani?
- Ihmisen ja tekoälyn yhteistyö: Miten voin ymmärtää ja luottaa mallin päätöksiin?
- Sääntelyvaatimusten noudattaminen: Täyttääkö mallini lakisääteiset vaatimukset?
RAI-hallintapaneelin Ominaisuuksien merkitys -komponentti auttaa virheenkorjaamaan ja saamaan kattavan ymmärryksen siitä, miten malli tekee ennusteita. Se on myös hyödyllinen työkalu koneoppimisen ammattilaisille ja päätöksentekijöille selittämään ja näyttämään todisteita ominaisuuksista, jotka vaikuttavat mallin käyttäytymiseen sääntelyvaatimusten noudattamiseksi. Käyttäjät voivat tutkia sekä globaaleja että paikallisia selityksiä ja vahvistaa, mitkä ominaisuudet ohjaavat mallin ennustetta. Globaalit selitykset listaavat tärkeimmät ominaisuudet, jotka vaikuttivat mallin kokonaisennusteeseen. Paikalliset selitykset näyttävät, mitkä ominaisuudet johtivat mallin ennusteeseen yksittäisessä tapauksessa. Paikallisten selitysten arviointikyky on myös hyödyllinen virheenkorjauksessa tai auditoinnissa yksittäisen tapauksen ymmärtämiseksi ja tulkitsemiseksi, miksi malli teki tarkan tai epätarkan ennusteen.
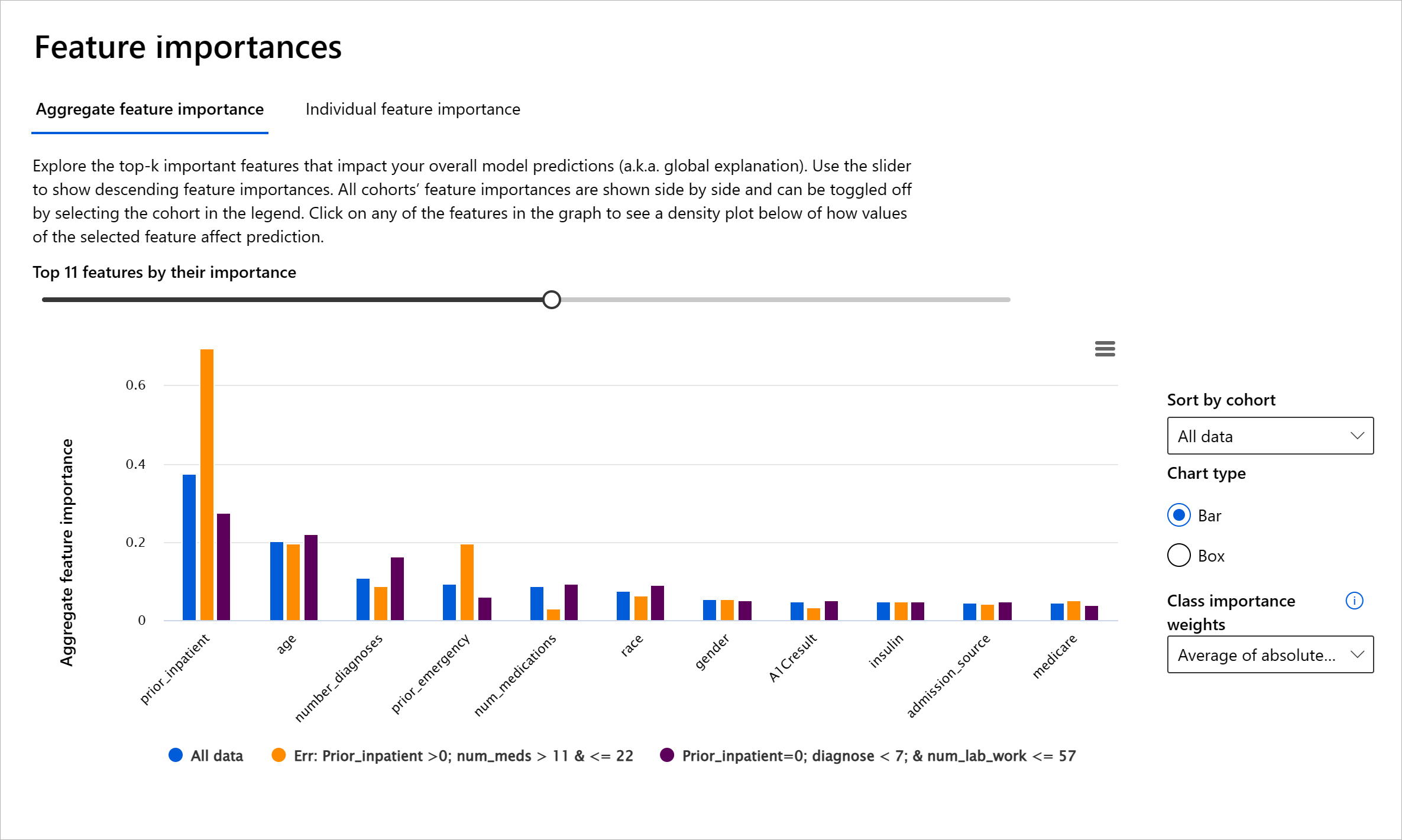
- Globaalit selitykset: Esimerkiksi mitkä ominaisuudet vaikuttavat diabeteksen sairaalaan takaisinottamisen mallin yleiseen käyttäytymiseen?
- Paikalliset selitykset: Esimerkiksi miksi yli 60-vuotias diabeetikko, jolla on aiempia sairaalahoitoja, ennustettiin joutuvan takaisin sairaalaan alle 30 päivän kuluessa tai ei?
Mallin suorituskyvyn tutkimisessa eri kohorttien välillä Ominaisuuksien merkitys näyttää, kuinka suuri vaikutus ominaisuudella on kohorttien välillä. Se auttaa paljastamaan poikkeavuuksia vertaamalla ominaisuuden vaikutuksen tasoa mallin virheellisten ennusteiden ohjaamisessa. Ominaisuuksien merkitys -komponentti voi näyttää, mitkä arvot ominaisuudessa vaikuttivat positiivisesti tai negatiivisesti mallin tulokseen. Esimerkiksi, jos malli teki epätarkan ennusteen, komponentti antaa mahdollisuuden porautua syvemmälle ja tunnistaa, mitkä ominaisuudet tai ominaisuusarvot ohjasivat ennustetta. Tämä yksityiskohtaisuuden taso auttaa paitsi virheenkorjauksessa myös tarjoaa läpinäkyvyyttä ja vastuullisuutta auditointitilanteissa. Lopuksi komponentti voi auttaa tunnistamaan oikeudenmukaisuusongelmia. Esimerkiksi, jos herkkä ominaisuus, kuten etnisyys tai sukupuoli, vaikuttaa voimakkaasti mallin ennusteeseen, tämä voi olla merkki rodullisesta tai sukupuolisesta ennakkoluulosta mallissa.

🎥 Klikkaa yllä olevaa kuvaa nähdäksesi videon: Responsible AI Dashboard: Yhden luukun ratkaisu RAI:n operationalisointiin käytännössä, esittäjät Besmira Nushi ja Mehrnoosh Sameki
Tutustu seuraaviin materiaaleihin oppiaksesi lisää vastuullisesta tekoälystä ja luodaksesi luotettavampia malleja:
-
Microsoftin RAI-kojelautatyökalut ML-mallien debuggaamiseen: Vastuullisen tekoälyn työkaluresurssit
-
Tutustu vastuullisen tekoälyn työkalupakkiin: Github
-
Microsoftin RAI-resurssikeskus: Vastuullisen tekoälyn resurssit – Microsoft AI
-
Microsoftin FATE-tutkimusryhmä: FATE: Reiluus, vastuullisuus, läpinäkyvyys ja etiikka tekoälyssä - Microsoft Research
Tehtävä
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa väärinkäsityksistä tai virhetulkinnoista, jotka johtuvat tämän käännöksen käytöstä.