16 KiB
Aloita Pythonin ja Scikit-learnin käyttö regressiomallien kanssa

Luonnosmuistiinpanon tekijä Tomomi Imura
Esiluennon kysely
Tämä oppitunti on saatavilla myös R-kielellä!
Johdanto
Näissä neljässä oppitunnissa opit rakentamaan regressiomalleja. Keskustelemme pian siitä, mihin niitä käytetään. Mutta ennen kuin aloitat, varmista, että sinulla on oikeat työkalut valmiina prosessin aloittamiseen!
Tässä oppitunnissa opit:
- Konfiguroimaan tietokoneesi paikallisia koneoppimistehtäviä varten.
- Työskentelemään Jupyter-notebookien kanssa.
- Käyttämään Scikit-learnia, mukaan lukien asennus.
- Tutustumaan lineaariseen regressioon käytännön harjoituksen avulla.
Asennukset ja konfiguroinnit

🎥 Klikkaa yllä olevaa kuvaa lyhyen videon katsomiseksi, jossa käydään läpi tietokoneen konfigurointi ML:ää varten.
-
Asenna Python. Varmista, että Python on asennettu tietokoneellesi. Pythonia käytetään monissa data-analytiikan ja koneoppimisen tehtävissä. Useimmissa tietokonejärjestelmissä Python on jo valmiiksi asennettuna. Käytettävissä on myös hyödyllisiä Python Coding Packeja, jotka helpottavat asennusta joillekin käyttäjille.
Joissakin Pythonin käyttötapauksissa tarvitaan yksi versio ohjelmistosta, kun taas toisissa tarvitaan eri versio. Tämän vuoksi on hyödyllistä työskennellä virtuaaliympäristössä.
-
Asenna Visual Studio Code. Varmista, että Visual Studio Code on asennettu tietokoneellesi. Seuraa näitä ohjeita Visual Studio Coden asentamiseksi perusasennusta varten. Tässä kurssissa käytät Pythonia Visual Studio Codessa, joten kannattaa tutustua siihen, miten Visual Studio Code konfiguroidaan Python-kehitystä varten.
Tutustu Pythonin käyttöön käymällä läpi tämä kokoelma Learn-moduuleja

🎥 Klikkaa yllä olevaa kuvaa videon katsomiseksi: Pythonin käyttö VS Codessa.
-
Asenna Scikit-learn seuraamalla näitä ohjeita. Koska sinun täytyy varmistaa, että käytät Python 3:a, on suositeltavaa käyttää virtuaaliympäristöä. Huomaa, että jos asennat tämän kirjaston M1 Macille, sivulla on erityisohjeita.
-
Asenna Jupyter Notebook. Sinun täytyy asentaa Jupyter-paketti.
ML-kehitysympäristösi
Käytät notebookeja Python-koodin kehittämiseen ja koneoppimismallien luomiseen. Tällainen tiedostotyyppi on yleinen työkalu data-analyytikoille, ja ne tunnistaa niiden päätteestä .ipynb.
Notebookit ovat interaktiivinen ympäristö, joka mahdollistaa sekä koodauksen että dokumentaation lisäämisen koodin ympärille, mikä on erittäin hyödyllistä kokeellisiin tai tutkimusprojekteihin.

🎥 Klikkaa yllä olevaa kuvaa lyhyen videon katsomiseksi, jossa käydään läpi tämä harjoitus.
Harjoitus - työskentele notebookin kanssa
Tässä kansiossa löydät tiedoston notebook.ipynb.
-
Avaa notebook.ipynb Visual Studio Codessa.
Jupyter-palvelin käynnistyy Python 3+:lla. Löydät notebookista alueita, jotka voidaan
ajaa, eli koodinpätkiä. Voit ajaa koodilohkon valitsemalla kuvakkeen, joka näyttää toistopainikkeelta. -
Valitse
md-kuvake ja lisää hieman markdownia sekä seuraava teksti # Tervetuloa notebookiisi.Lisää seuraavaksi Python-koodia.
-
Kirjoita print('hello notebook') koodilohkoon.
-
Valitse nuoli ajaaksesi koodin.
Näet tulostetun lauseen:
hello notebook

Voit yhdistää koodisi kommentteihin dokumentoidaksesi notebookin itse.
✅ Mieti hetki, kuinka erilainen web-kehittäjän työympäristö on verrattuna data-analyytikon työympäristöön.
Scikit-learnin käyttöönotto
Nyt kun Python on asennettu paikalliseen ympäristöösi ja olet mukautunut Jupyter-notebookeihin, tutustutaan yhtä mukavasti Scikit-learniin (lausutaan sci kuten science). Scikit-learn tarjoaa laajan API:n, joka auttaa sinua suorittamaan ML-tehtäviä.
Heidän verkkosivustonsa mukaan "Scikit-learn on avoimen lähdekoodin koneoppimiskirjasto, joka tukee ohjattua ja ohjaamatonta oppimista. Se tarjoaa myös erilaisia työkaluja mallien sovittamiseen, datan esikäsittelyyn, mallien valintaan ja arviointiin sekä moniin muihin hyödyllisiin toimintoihin."
Tässä kurssissa käytät Scikit-learnia ja muita työkaluja koneoppimismallien rakentamiseen suorittaaksesi niin sanottuja 'perinteisiä koneoppimistehtäviä'. Olemme tarkoituksella välttäneet neuroverkkoja ja syväoppimista, sillä ne käsitellään paremmin tulevassa 'AI aloittelijoille' -opetussuunnitelmassamme.
Scikit-learn tekee mallien rakentamisesta ja niiden arvioinnista helppoa. Se keskittyy pääasiassa numeerisen datan käyttöön ja sisältää useita valmiita datasettiä oppimistyökaluiksi. Se sisältää myös valmiiksi rakennettuja malleja, joita opiskelijat voivat kokeilla. Tutustutaan prosessiin, jossa ladataan valmiiksi pakattua dataa ja käytetään sisäänrakennettua estimaattoria ensimmäisen ML-mallin luomiseen Scikit-learnilla perusdatan avulla.
Harjoitus - ensimmäinen Scikit-learn notebookisi
Tämä opetus on saanut inspiraationsa lineaarisen regression esimerkistä Scikit-learnin verkkosivustolla.

🎥 Klikkaa yllä olevaa kuvaa lyhyen videon katsomiseksi, jossa käydään läpi tämä harjoitus.
Poista notebook.ipynb-tiedostosta kaikki solut painamalla 'roskakori'-kuvaketta.
Tässä osiossa työskentelet pienen datasetin kanssa, joka liittyy diabetekseen ja joka on sisäänrakennettu Scikit-learniin oppimistarkoituksia varten. Kuvittele, että haluaisit testata hoitoa diabeetikoille. Koneoppimismallit voivat auttaa sinua määrittämään, mitkä potilaat reagoisivat hoitoon paremmin, perustuen muuttujien yhdistelmiin. Jopa hyvin yksinkertainen regressiomalli, kun se visualisoidaan, voi paljastaa tietoa muuttujista, jotka auttaisivat sinua järjestämään teoreettisia kliinisiä kokeita.
✅ Regressiomenetelmiä on monenlaisia, ja valinta riippuu siitä, mitä haluat selvittää. Jos haluat ennustaa todennäköistä pituutta tietyn ikäiselle henkilölle, käyttäisit lineaarista regressiota, koska etsit numeerista arvoa. Jos haluat selvittää, pitäisikö tiettyä ruokakulttuuria pitää vegaanisena vai ei, etsit kategoriaa, joten käyttäisit logistista regressiota. Opit lisää logistisesta regressiosta myöhemmin. Mieti hetki, mitä kysymyksiä voisit esittää datasta ja mikä näistä menetelmistä olisi sopivampi.
Aloitetaan tehtävä.
Kirjastojen tuonti
Tätä tehtävää varten tuomme joitakin kirjastoja:
- matplotlib. Se on hyödyllinen graafinen työkalu, ja käytämme sitä viivakaavion luomiseen.
- numpy. numpy on hyödyllinen kirjasto numeerisen datan käsittelyyn Pythonissa.
- sklearn. Tämä on Scikit-learn -kirjasto.
Tuo joitakin kirjastoja auttamaan tehtävissäsi.
-
Lisää tuonnit kirjoittamalla seuraava koodi:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionYllä tuodaan
matplotlib,numpysekädatasets,linear_modeljamodel_selectionsklearn-kirjastosta.model_selectionkäytetään datan jakamiseen harjoitus- ja testijoukkoihin.
Diabetes-datasetti
Sisäänrakennettu diabetes-datasetti sisältää 442 näytettä diabetekseen liittyvästä datasta, jossa on 10 ominaisuusmuuttujaa, joista osa sisältää:
- age: ikä vuosina
- bmi: kehon massan indeksi
- bp: keskimääräinen verenpaine
- s1 tc: T-solut (eräänlainen valkosolu)
✅ Tämä datasetti sisältää 'sukupuolen' käsitteen tärkeänä ominaisuusmuuttujana diabetekseen liittyvässä tutkimuksessa. Monet lääketieteelliset datasetit sisältävät tällaisen binääriluokituksen. Mieti hetki, miten tällaiset luokitukset saattavat sulkea pois tiettyjä väestönosia hoidoista.
Lataa nyt X- ja y-data.
🎓 Muista, että tämä on ohjattua oppimista, ja tarvitsemme nimetyn 'y'-kohteen.
Uudessa koodisolussa lataa diabetes-datasetti kutsumalla load_diabetes(). Syöte return_X_y=True ilmoittaa, että X on datamatriisi ja y on regressiotavoite.
-
Lisää joitakin tulostuskäskyjä näyttämään datamatriisin muoto ja sen ensimmäinen elementti:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Saat vastauksena tuplen. Teet niin, että määrität tuplen kaksi ensimmäistä arvoa
X:lle jay:lle. Lue lisää tuplista.Näet, että tämä data sisältää 442 kohdetta, jotka on muotoiltu 10 elementin taulukoiksi:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Mieti hetki datan ja regressiotavoitteen välistä suhdetta. Lineaarinen regressio ennustaa suhteita ominaisuuden X ja tavoitemuuttujan y välillä. Voitko löytää tavoitteen diabetes-datasetille dokumentaatiosta? Mitä tämä datasetti havainnollistaa, kun otetaan huomioon tavoite?
-
Valitse seuraavaksi osa tästä datasetistä piirtämistä varten valitsemalla datasetin 3. sarake. Voit tehdä tämän käyttämällä
:-operaattoria valitaksesi kaikki rivit ja sitten valitsemalla 3. sarakkeen indeksillä (2). Voit myös muotoilla datan 2D-taulukoksi - kuten vaaditaan piirtämistä varten - käyttämälläreshape(n_rows, n_columns). Jos yksi parametreista on -1, vastaava ulottuvuus lasketaan automaattisesti.X = X[:, 2] X = X.reshape((-1,1))✅ Tulosta data milloin tahansa tarkistaaksesi sen muodon.
-
Nyt kun sinulla on data valmiina piirtämistä varten, voit nähdä, voiko kone auttaa määrittämään loogisen jaon numeroiden välillä tässä datasetissä. Tätä varten sinun täytyy jakaa sekä data (X) että tavoite (y) testaus- ja harjoitusjoukkoihin. Scikit-learn tarjoaa yksinkertaisen tavan tehdä tämä; voit jakaa testidatasi tietyssä pisteessä.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Nyt olet valmis kouluttamaan mallisi! Lataa lineaarinen regressiomalli ja kouluta sitä X- ja y-harjoitusjoukoilla käyttämällä
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()on funktio, jonka näet monissa ML-kirjastoissa, kuten TensorFlowssa. -
Luo sitten ennuste testidatan avulla käyttämällä funktiota
predict(). Tätä käytetään piirtämään viiva dataryhmien välille.y_pred = model.predict(X_test) -
Nyt on aika näyttää data kaaviossa. Matplotlib on erittäin hyödyllinen työkalu tähän tehtävään. Luo scatterplot kaikesta X- ja y-testidatasta ja käytä ennustetta piirtääksesi viiva sopivimpaan kohtaan dataryhmien välillä.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()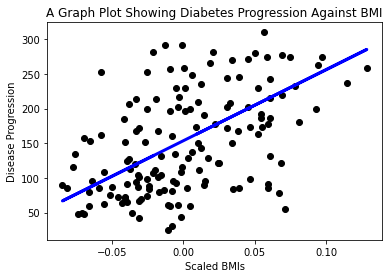 ✅ Mieti hetki, mitä tässä tapahtuu. Suora viiva kulkee monien pienten datapisteiden läpi, mutta mitä se oikeastaan tekee? Voitko nähdä, miten tämän viivan avulla pitäisi pystyä ennustamaan, mihin uusi, ennennäkemätön datapiste sijoittuu suhteessa kuvaajan y-akseliin? Yritä pukea sanoiksi tämän mallin käytännön hyöty.
✅ Mieti hetki, mitä tässä tapahtuu. Suora viiva kulkee monien pienten datapisteiden läpi, mutta mitä se oikeastaan tekee? Voitko nähdä, miten tämän viivan avulla pitäisi pystyä ennustamaan, mihin uusi, ennennäkemätön datapiste sijoittuu suhteessa kuvaajan y-akseliin? Yritä pukea sanoiksi tämän mallin käytännön hyöty.
Onnittelut, loit ensimmäisen lineaarisen regressiomallisi, teit ennusteen sen avulla ja esittelit sen kuvaajassa!
🚀Haaste
Piirrä kuvaaja, jossa käytetään eri muuttujaa tästä datasetistä. Vinkki: muokkaa tätä riviä: X = X[:,2]. Tämän datasetin tavoitteen perusteella, mitä pystyt päättelemään diabeteksen etenemisestä sairautena?
Luennon jälkeinen kysely
Kertaus & Itseopiskelu
Tässä opetusmateriaalissa työskentelit yksinkertaisen lineaarisen regression parissa, etkä univariaatin tai monimuuttujaisen regression kanssa. Lue hieman näiden menetelmien eroista tai katso tämä video.
Lue lisää regressiokonseptista ja pohdi, millaisiin kysymyksiin tällä tekniikalla voidaan vastata. Syvennä ymmärrystäsi ottamalla tämä opetusohjelma.
Tehtävä
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäinen asiakirja sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa väärinkäsityksistä tai virhetulkinnoista, jotka johtuvat tämän käännöksen käytöstä.