|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 3 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 3 weeks ago | |
README.md
Erstellen einer Web-App zur Empfehlung von Küchen
In dieser Lektion wirst du ein Klassifikationsmodell erstellen, indem du einige der Techniken anwendest, die du in den vorherigen Lektionen gelernt hast, und mit dem köstlichen Küchendatensatz arbeitest, der in dieser Serie verwendet wurde. Außerdem wirst du eine kleine Web-App entwickeln, um ein gespeichertes Modell zu nutzen, indem du die Web-Laufzeit von Onnx einsetzt.
Eine der nützlichsten praktischen Anwendungen des maschinellen Lernens ist der Aufbau von Empfehlungssystemen, und du kannst heute den ersten Schritt in diese Richtung machen!

🎥 Klicke auf das Bild oben für ein Video: Jen Looper erstellt eine Web-App mit klassifizierten Küchendaten
Quiz vor der Lektion
In dieser Lektion wirst du lernen:
- Wie man ein Modell erstellt und es als Onnx-Modell speichert
- Wie man Netron verwendet, um das Modell zu inspizieren
- Wie man das Modell in einer Web-App für Inferenz verwendet
Erstelle dein Modell
Der Aufbau angewandter ML-Systeme ist ein wichtiger Teil der Nutzung dieser Technologien für Geschäftssysteme. Du kannst Modelle innerhalb deiner Webanwendungen verwenden (und sie somit bei Bedarf offline nutzen), indem du Onnx einsetzt.
In einer vorherigen Lektion hast du ein Regressionsmodell über UFO-Sichtungen erstellt, es "eingemacht" und in einer Flask-App verwendet. Obwohl diese Architektur sehr nützlich ist, handelt es sich um eine vollständige Python-App, und deine Anforderungen könnten die Nutzung einer JavaScript-Anwendung umfassen.
In dieser Lektion kannst du ein einfaches JavaScript-basiertes System für Inferenz erstellen. Zunächst musst du jedoch ein Modell trainieren und es für die Verwendung mit Onnx konvertieren.
Übung - Klassifikationsmodell trainieren
Trainiere zunächst ein Klassifikationsmodell mit dem bereinigten Küchendatensatz, den wir verwendet haben.
-
Beginne mit dem Import nützlicher Bibliotheken:
!pip install skl2onnx import pandas as pdDu benötigst 'skl2onnx', um dein Scikit-learn-Modell in das Onnx-Format zu konvertieren.
-
Arbeite dann mit deinen Daten wie in den vorherigen Lektionen, indem du eine CSV-Datei mit
read_csv()liest:data = pd.read_csv('../data/cleaned_cuisines.csv') data.head() -
Entferne die ersten beiden unnötigen Spalten und speichere die verbleibenden Daten als 'X':
X = data.iloc[:,2:] X.head() -
Speichere die Labels als 'y':
y = data[['cuisine']] y.head()
Beginne die Trainingsroutine
Wir werden die 'SVC'-Bibliothek verwenden, die eine gute Genauigkeit bietet.
-
Importiere die entsprechenden Bibliotheken aus Scikit-learn:
from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.model_selection import cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report -
Teile die Trainings- und Testdaten:
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3) -
Erstelle ein SVC-Klassifikationsmodell wie in der vorherigen Lektion:
model = SVC(kernel='linear', C=10, probability=True,random_state=0) model.fit(X_train,y_train.values.ravel()) -
Teste nun dein Modell, indem du
predict()aufrufst:y_pred = model.predict(X_test) -
Gib einen Klassifikationsbericht aus, um die Qualität des Modells zu überprüfen:
print(classification_report(y_test,y_pred))Wie wir zuvor gesehen haben, ist die Genauigkeit gut:
precision recall f1-score support chinese 0.72 0.69 0.70 257 indian 0.91 0.87 0.89 243 japanese 0.79 0.77 0.78 239 korean 0.83 0.79 0.81 236 thai 0.72 0.84 0.78 224 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
Konvertiere dein Modell in Onnx
Stelle sicher, dass die Konvertierung mit der richtigen Tensor-Anzahl erfolgt. Dieser Datensatz enthält 380 aufgelistete Zutaten, daher musst du diese Zahl in FloatTensorType angeben:
-
Konvertiere mit einer Tensor-Anzahl von 380.
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 380]))] options = {id(model): {'nocl': True, 'zipmap': False}} -
Erstelle die Onnx-Datei und speichere sie als model.onnx:
onx = convert_sklearn(model, initial_types=initial_type, options=options) with open("./model.onnx", "wb") as f: f.write(onx.SerializeToString())Hinweis: Du kannst Optionen in deinem Konvertierungsskript übergeben. In diesem Fall haben wir 'nocl' auf True und 'zipmap' auf False gesetzt. Da es sich um ein Klassifikationsmodell handelt, hast du die Möglichkeit, ZipMap zu entfernen, das eine Liste von Wörterbüchern erzeugt (nicht erforderlich).
noclbezieht sich darauf, ob Klasseninformationen im Modell enthalten sind. Reduziere die Größe deines Modells, indem dunoclauf 'True' setzt.
Wenn du das gesamte Notebook ausführst, wird ein Onnx-Modell erstellt und in diesem Ordner gespeichert.
Betrachte dein Modell
Onnx-Modelle sind in Visual Studio Code nicht sehr sichtbar, aber es gibt eine sehr gute kostenlose Software, die viele Forscher verwenden, um das Modell zu visualisieren und sicherzustellen, dass es korrekt erstellt wurde. Lade Netron herunter und öffne deine model.onnx-Datei. Du kannst dein einfaches Modell visualisiert sehen, mit seinen 380 Eingaben und dem Klassifikator:
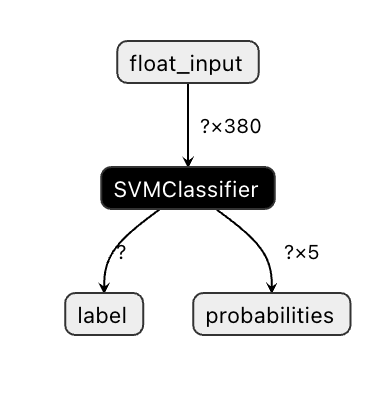
Netron ist ein hilfreiches Tool, um deine Modelle zu betrachten.
Jetzt bist du bereit, dieses praktische Modell in einer Web-App zu verwenden. Lass uns eine App erstellen, die nützlich ist, wenn du in deinen Kühlschrank schaust und herausfinden möchtest, welche Kombination deiner übrig gebliebenen Zutaten du verwenden kannst, um eine bestimmte Küche zu kochen, wie von deinem Modell bestimmt.
Erstelle eine Empfehlungs-Webanwendung
Du kannst dein Modell direkt in einer Web-App verwenden. Diese Architektur ermöglicht es dir auch, sie lokal und sogar offline auszuführen, falls erforderlich. Beginne mit der Erstellung einer index.html-Datei im selben Ordner, in dem du deine model.onnx-Datei gespeichert hast.
-
Füge in dieser Datei index.html das folgende Markup hinzu:
<!DOCTYPE html> <html> <header> <title>Cuisine Matcher</title> </header> <body> ... </body> </html> -
Füge nun innerhalb der
body-Tags ein wenig Markup hinzu, um eine Liste von Kontrollkästchen anzuzeigen, die einige Zutaten widerspiegeln:<h1>Check your refrigerator. What can you create?</h1> <div id="wrapper"> <div class="boxCont"> <input type="checkbox" value="4" class="checkbox"> <label>apple</label> </div> <div class="boxCont"> <input type="checkbox" value="247" class="checkbox"> <label>pear</label> </div> <div class="boxCont"> <input type="checkbox" value="77" class="checkbox"> <label>cherry</label> </div> <div class="boxCont"> <input type="checkbox" value="126" class="checkbox"> <label>fenugreek</label> </div> <div class="boxCont"> <input type="checkbox" value="302" class="checkbox"> <label>sake</label> </div> <div class="boxCont"> <input type="checkbox" value="327" class="checkbox"> <label>soy sauce</label> </div> <div class="boxCont"> <input type="checkbox" value="112" class="checkbox"> <label>cumin</label> </div> </div> <div style="padding-top:10px"> <button onClick="startInference()">What kind of cuisine can you make?</button> </div>Beachte, dass jedes Kontrollkästchen einen Wert hat. Dieser spiegelt den Index wider, an dem die Zutat gemäß dem Datensatz gefunden wird. Apfel, zum Beispiel, in dieser alphabetischen Liste, belegt die fünfte Spalte, daher ist sein Wert '4', da wir bei 0 zu zählen beginnen. Du kannst die Zutaten-Tabelle konsultieren, um den Index einer bestimmten Zutat zu finden.
Setze deine Arbeit in der index.html-Datei fort und füge einen Skriptblock hinzu, in dem das Modell nach dem letzten abschließenden
</div>aufgerufen wird. -
Importiere zunächst die Onnx Runtime:
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.9.0/dist/ort.min.js"></script>Onnx Runtime wird verwendet, um die Ausführung deiner Onnx-Modelle auf einer Vielzahl von Hardwareplattformen zu ermöglichen, einschließlich Optimierungen und einer API zur Nutzung.
-
Sobald die Runtime eingerichtet ist, kannst du sie aufrufen:
<script> const ingredients = Array(380).fill(0); const checks = [...document.querySelectorAll('.checkbox')]; checks.forEach(check => { check.addEventListener('change', function() { // toggle the state of the ingredient // based on the checkbox's value (1 or 0) ingredients[check.value] = check.checked ? 1 : 0; }); }); function testCheckboxes() { // validate if at least one checkbox is checked return checks.some(check => check.checked); } async function startInference() { let atLeastOneChecked = testCheckboxes() if (!atLeastOneChecked) { alert('Please select at least one ingredient.'); return; } try { // create a new session and load the model. const session = await ort.InferenceSession.create('./model.onnx'); const input = new ort.Tensor(new Float32Array(ingredients), [1, 380]); const feeds = { float_input: input }; // feed inputs and run const results = await session.run(feeds); // read from results alert('You can enjoy ' + results.label.data[0] + ' cuisine today!') } catch (e) { console.log(`failed to inference ONNX model`); console.error(e); } } </script>
In diesem Code passieren mehrere Dinge:
- Du hast ein Array von 380 möglichen Werten (1 oder 0) erstellt, das je nach Auswahl eines Kontrollkästchens gesetzt und an das Modell zur Inferenz gesendet wird.
- Du hast ein Array von Kontrollkästchen erstellt und eine Möglichkeit, festzustellen, ob sie im
init-Funktion aktiviert wurden, die beim Start der Anwendung aufgerufen wird. Wenn ein Kontrollkästchen aktiviert ist, wird dasingredients-Array geändert, um die ausgewählte Zutat widerzuspiegeln. - Du hast eine
testCheckboxes-Funktion erstellt, die überprüft, ob ein Kontrollkästchen aktiviert wurde. - Du verwendest die
startInference-Funktion, wenn die Schaltfläche gedrückt wird, und wenn ein Kontrollkästchen aktiviert ist, startest du die Inferenz. - Die Inferenzroutine umfasst:
- Das Einrichten eines asynchronen Ladevorgangs des Modells
- Das Erstellen einer Tensor-Struktur, die an das Modell gesendet wird
- Das Erstellen von 'feeds', die den
float_input-Eingang widerspiegeln, den du beim Training deines Modells erstellt hast (du kannst Netron verwenden, um diesen Namen zu überprüfen) - Das Senden dieser 'feeds' an das Modell und das Warten auf eine Antwort
Teste deine Anwendung
Öffne eine Terminal-Sitzung in Visual Studio Code im Ordner, in dem sich deine index.html-Datei befindet. Stelle sicher, dass du http-server global installiert hast, und gib http-server an der Eingabeaufforderung ein. Ein localhost sollte sich öffnen und du kannst deine Web-App anzeigen. Überprüfe, welche Küche basierend auf verschiedenen Zutaten empfohlen wird:
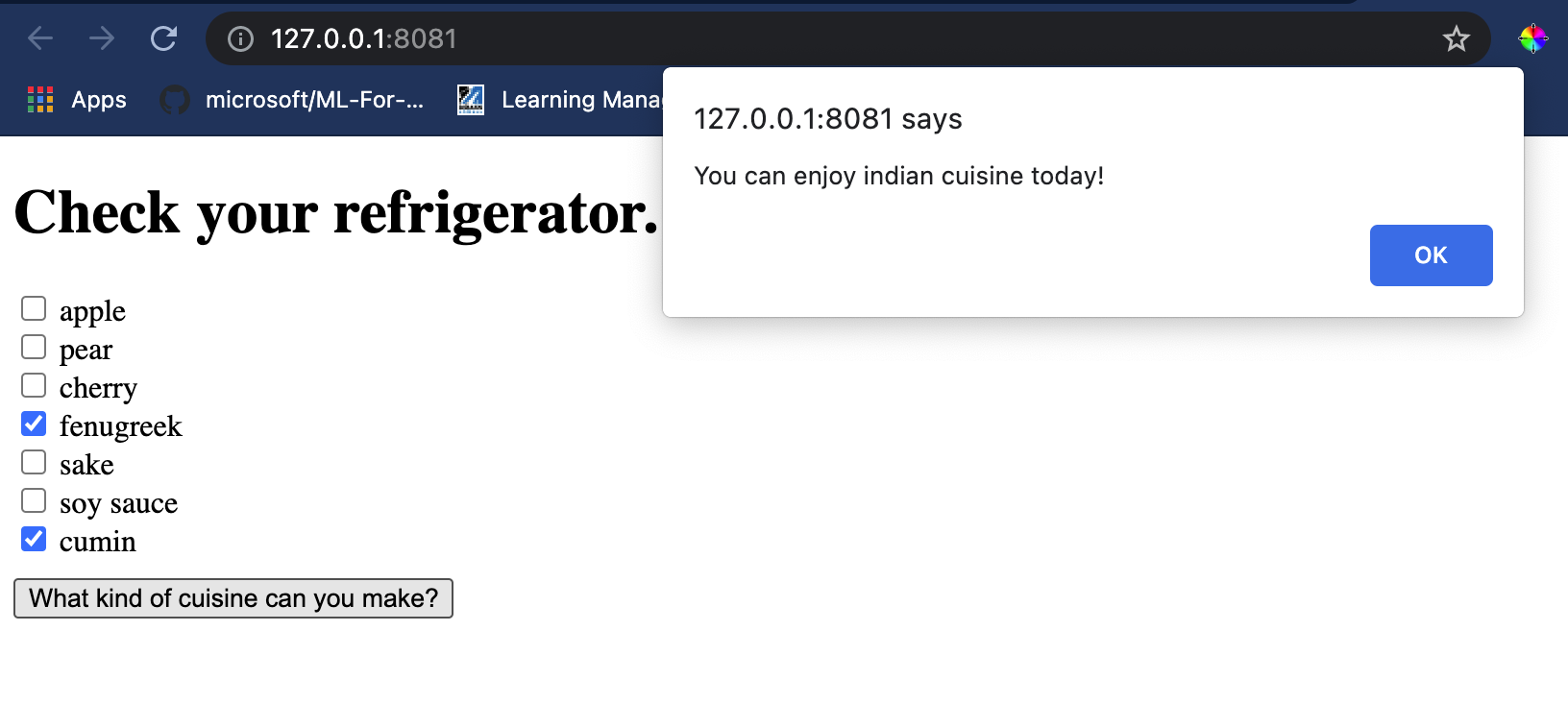
Herzlichen Glückwunsch, du hast eine Empfehlungs-Web-App mit einigen Feldern erstellt. Nimm dir etwas Zeit, um dieses System weiter auszubauen!
🚀 Herausforderung
Deine Web-App ist sehr minimal, also baue sie weiter aus, indem du Zutaten und ihre Indizes aus den ingredient_indexes-Daten verwendest. Welche Geschmacksrichtungen funktionieren, um ein bestimmtes Nationalgericht zu kreieren?
Quiz nach der Lektion
Überprüfung & Selbststudium
Während diese Lektion nur kurz die Nützlichkeit der Erstellung eines Empfehlungssystems für Lebensmittelzutaten berührt hat, ist dieser Bereich der ML-Anwendungen sehr reich an Beispielen. Lies mehr darüber, wie diese Systeme aufgebaut werden:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
Aufgabe
Erstelle einen neuen Empfehlungsalgorithmus
Haftungsausschluss:
Dieses Dokument wurde mithilfe des KI-Übersetzungsdienstes Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, weisen wir darauf hin, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die aus der Nutzung dieser Übersetzung entstehen.