14 KiB
Geschichte des maschinellen Lernens
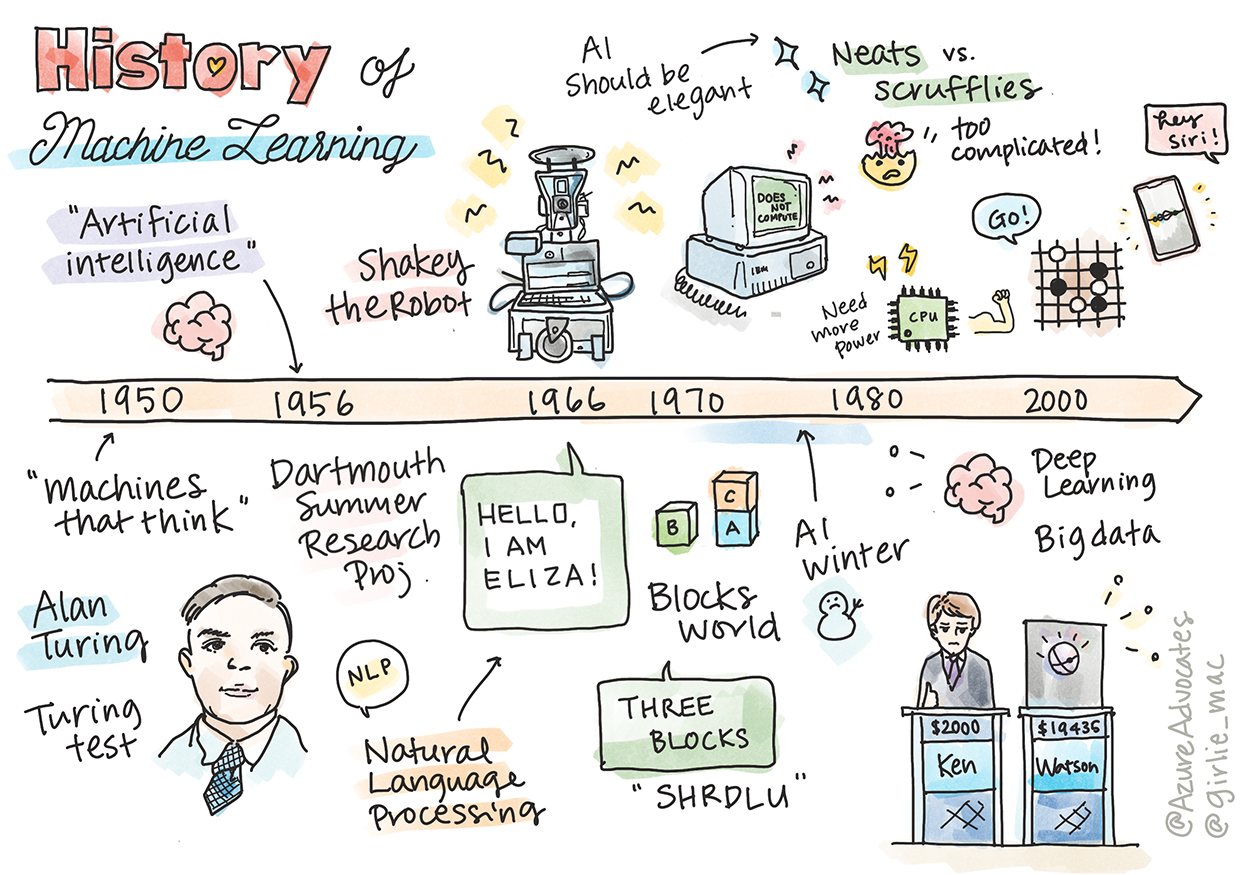
Sketchnote von Tomomi Imura
Quiz vor der Vorlesung

🎥 Klicken Sie auf das Bild oben, um ein kurzes Video zu dieser Lektion anzusehen.
In dieser Lektion gehen wir die wichtigsten Meilensteine in der Geschichte des maschinellen Lernens und der künstlichen Intelligenz durch.
Die Geschichte der künstlichen Intelligenz (KI) als Forschungsfeld ist eng mit der Geschichte des maschinellen Lernens verbunden, da die Algorithmen und rechnerischen Fortschritte, die ML zugrunde liegen, zur Entwicklung der KI beigetragen haben. Es ist hilfreich, sich daran zu erinnern, dass, obwohl sich diese Bereiche als eigenständige Forschungsgebiete in den 1950er Jahren herauskristallisierten, wichtige algorithmische, statistische, mathematische, rechnerische und technische Entdeckungen diese Ära vorwegnahmen und überlappten. Tatsächlich beschäftigen sich Menschen schon seit Hunderten von Jahren mit diesen Fragen: Dieser Artikel beleuchtet die historischen intellektuellen Grundlagen der Idee einer „denkenden Maschine“.
Bedeutende Entdeckungen
- 1763, 1812 Bayes-Theorem und seine Vorläufer. Dieses Theorem und seine Anwendungen bilden die Grundlage für Inferenz, indem sie die Wahrscheinlichkeit eines Ereignisses basierend auf Vorwissen beschreiben.
- 1805 Methode der kleinsten Quadrate des französischen Mathematikers Adrien-Marie Legendre. Diese Theorie, die Sie in unserer Regressionseinheit kennenlernen werden, hilft bei der Datenanpassung.
- 1913 Markow-Ketten, benannt nach dem russischen Mathematiker Andrey Markov, beschreiben eine Abfolge möglicher Ereignisse basierend auf einem vorherigen Zustand.
- 1957 Perzeptron, ein von dem amerikanischen Psychologen Frank Rosenblatt erfundener linearer Klassifikator, der die Grundlage für Fortschritte im Deep Learning bildet.
- 1967 Nächster-Nachbar-Algorithmus, ursprünglich entwickelt, um Routen zu kartieren. Im ML-Kontext wird er zur Mustererkennung verwendet.
- 1970 Backpropagation wird verwendet, um Feedforward-Neuronale Netze zu trainieren.
- 1982 Rekurrente Neuronale Netze sind künstliche neuronale Netze, die aus Feedforward-Netzen abgeleitet sind und zeitliche Graphen erstellen.
✅ Recherchieren Sie ein wenig. Welche anderen Daten sind Ihrer Meinung nach entscheidend in der Geschichte des maschinellen Lernens und der KI?
1950: Maschinen, die denken
Alan Turing, eine wahrhaft bemerkenswerte Persönlichkeit, die 2019 von der Öffentlichkeit zum größten Wissenschaftler des 20. Jahrhunderts gewählt wurde, wird zugeschrieben, das Fundament für das Konzept einer „denkenden Maschine“ gelegt zu haben. Er setzte sich mit Skeptikern auseinander und suchte nach empirischen Beweisen für dieses Konzept, unter anderem durch die Entwicklung des Turing-Tests, den Sie in unseren NLP-Lektionen näher kennenlernen werden.
1956: Dartmouth Summer Research Project
„Das Dartmouth Summer Research Project zur künstlichen Intelligenz war ein wegweisendes Ereignis für das Feld der künstlichen Intelligenz“, und hier wurde der Begriff „künstliche Intelligenz“ geprägt (Quelle).
Jeder Aspekt des Lernens oder eines anderen Merkmals von Intelligenz kann im Prinzip so präzise beschrieben werden, dass eine Maschine es simulieren kann.
Der leitende Forscher, Mathematikprofessor John McCarthy, hoffte, „auf der Grundlage der Vermutung vorzugehen, dass jeder Aspekt des Lernens oder eines anderen Merkmals von Intelligenz im Prinzip so präzise beschrieben werden kann, dass eine Maschine es simulieren kann.“ Zu den Teilnehmern gehörte auch eine weitere Koryphäe des Feldes, Marvin Minsky.
Der Workshop wird dafür verantwortlich gemacht, mehrere Diskussionen angestoßen und gefördert zu haben, darunter „den Aufstieg symbolischer Methoden, Systeme, die sich auf begrenzte Domänen konzentrieren (frühe Expertensysteme), und deduktive Systeme versus induktive Systeme.“ (Quelle).
1956 - 1974: „Die goldenen Jahre“
Von den 1950er Jahren bis Mitte der 1970er Jahre herrschte großer Optimismus, dass KI viele Probleme lösen könnte. 1967 erklärte Marvin Minsky zuversichtlich: „Innerhalb einer Generation ... wird das Problem, ‚künstliche Intelligenz‘ zu schaffen, im Wesentlichen gelöst sein.“ (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
Die Forschung zur Verarbeitung natürlicher Sprache blühte auf, Suchalgorithmen wurden verfeinert und leistungsfähiger, und das Konzept der „Mikrowelten“ wurde entwickelt, in denen einfache Aufgaben mit einfachen Sprachbefehlen ausgeführt werden konnten.
Die Forschung wurde gut von Regierungsbehörden finanziert, Fortschritte in der Rechenleistung und bei Algorithmen wurden erzielt, und Prototypen intelligenter Maschinen wurden gebaut. Einige dieser Maschinen umfassen:
-
Shakey der Roboter, der sich bewegen und „intelligent“ entscheiden konnte, wie Aufgaben ausgeführt werden sollten.

Shakey im Jahr 1972
-
Eliza, ein früher „Chatterbot“, konnte mit Menschen kommunizieren und als primitiver „Therapeut“ fungieren. Sie werden mehr über Eliza in den NLP-Lektionen erfahren.
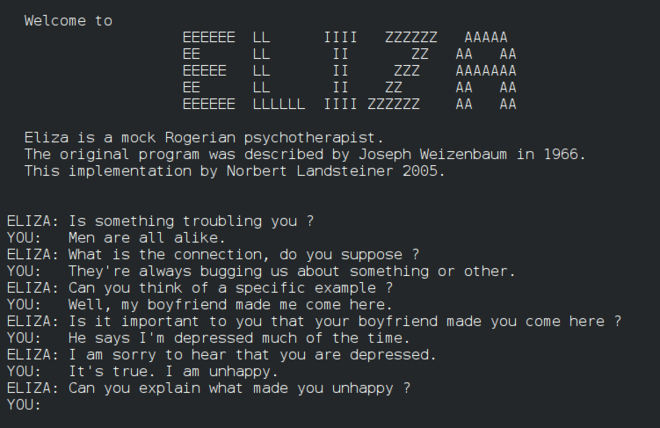
Eine Version von Eliza, einem Chatbot
-
„Blocks World“ war ein Beispiel für eine Mikrowelt, in der Blöcke gestapelt und sortiert werden konnten, und Experimente zur Entscheidungsfindung von Maschinen durchgeführt wurden. Fortschritte mit Bibliotheken wie SHRDLU trieben die Sprachverarbeitung voran.

🎥 Klicken Sie auf das Bild oben für ein Video: Blocks World mit SHRDLU
1974 - 1980: „KI-Winter“
Mitte der 1970er Jahre wurde klar, dass die Komplexität der Entwicklung „intelligenter Maschinen“ unterschätzt und ihr Potenzial angesichts der verfügbaren Rechenleistung überschätzt worden war. Die Finanzierung versiegte, und das Vertrauen in das Feld nahm ab. Einige Probleme, die das Vertrauen beeinträchtigten, waren:
- Einschränkungen. Die Rechenleistung war zu begrenzt.
- Kombinatorische Explosion. Die Anzahl der zu trainierenden Parameter wuchs exponentiell, je mehr von Computern verlangt wurde, ohne dass die Rechenleistung und -fähigkeit parallel dazu wuchsen.
- Mangel an Daten. Es gab einen Mangel an Daten, der den Prozess des Testens, Entwickelns und Verfeinerns von Algorithmen behinderte.
- Stellen wir die richtigen Fragen?. Die gestellten Fragen selbst wurden infrage gestellt. Forscher sahen sich Kritik an ihren Ansätzen ausgesetzt:
- Turing-Tests wurden unter anderem durch die „Chinese Room“-Theorie infrage gestellt, die besagt, dass „das Programmieren eines digitalen Computers zwar den Anschein erwecken kann, Sprache zu verstehen, aber kein echtes Verständnis erzeugen kann.“ (Quelle)
- Die Ethik der Einführung künstlicher Intelligenzen wie des „Therapeuten“ ELIZA in die Gesellschaft wurde hinterfragt.
Gleichzeitig begannen sich verschiedene Schulen der KI-Forschung zu bilden. Es entstand eine Dichotomie zwischen "Scruffy" vs. "Neat AI"-Praktiken. Scruffy-Labore optimierten Programme stundenlang, bis sie die gewünschten Ergebnisse erzielten. Neat-Labore „konzentrierten sich auf Logik und formale Problemlösung“. ELIZA und SHRDLU waren bekannte Scruffy-Systeme. In den 1980er Jahren, als die Nachfrage nach reproduzierbaren ML-Systemen wuchs, setzte sich der Neat-Ansatz allmählich durch, da seine Ergebnisse besser erklärbar sind.
1980er Jahre: Expertensysteme
Mit dem Wachstum des Feldes wurde sein Nutzen für Unternehmen deutlicher, und in den 1980er Jahren verbreiteten sich „Expertensysteme“. „Expertensysteme waren eine der ersten wirklich erfolgreichen Formen von KI-Software.“ (Quelle)
Dieser Systemtyp ist tatsächlich hybrid und besteht teilweise aus einer Regel-Engine, die Geschäftsanforderungen definiert, und einer Inferenz-Engine, die das Regelwerk nutzt, um neue Fakten abzuleiten.
In dieser Ära wurde auch den neuronalen Netzen zunehmend Aufmerksamkeit geschenkt.
1987 - 1993: „KI-Abkühlung“
Die Verbreitung spezialisierter Hardware für Expertensysteme hatte den unglücklichen Effekt, zu spezialisiert zu werden. Der Aufstieg von Personal Computern konkurrierte mit diesen großen, spezialisierten, zentralisierten Systemen. Die Demokratisierung des Rechnens hatte begonnen und ebnete schließlich den Weg für die moderne Explosion von Big Data.
1993 - 2011
Diese Epoche markierte eine neue Ära für ML und KI, um einige der Probleme zu lösen, die zuvor durch den Mangel an Daten und Rechenleistung verursacht worden waren. Die Menge an Daten begann rapide zu wachsen und wurde zunehmend verfügbar, sowohl zum Guten als auch zum Schlechten, insbesondere mit dem Aufkommen des Smartphones um 2007. Die Rechenleistung wuchs exponentiell, und Algorithmen entwickelten sich parallel dazu weiter. Das Feld begann, sich zu einer echten Disziplin zu entwickeln, während die unstrukturierten Ansätze der Vergangenheit allmählich einer gereiften Struktur wichen.
Heute
Heute berühren maschinelles Lernen und KI fast jeden Bereich unseres Lebens. Diese Ära erfordert ein sorgfältiges Verständnis der Risiken und potenziellen Auswirkungen dieser Algorithmen auf das menschliche Leben. Wie Brad Smith von Microsoft erklärt hat: „Informationstechnologie wirft Fragen auf, die das Herzstück grundlegender Menschenrechtsfragen wie Datenschutz und Meinungsfreiheit betreffen. Diese Fragen erhöhen die Verantwortung von Technologieunternehmen, die diese Produkte entwickeln. Unserer Ansicht nach erfordern sie auch eine durchdachte staatliche Regulierung und die Entwicklung von Normen für akzeptable Nutzungen.“ (Quelle)
Es bleibt abzuwarten, was die Zukunft bringt, aber es ist wichtig, diese Computersysteme sowie die Software und Algorithmen, die sie ausführen, zu verstehen. Wir hoffen, dass dieses Curriculum Ihnen hilft, ein besseres Verständnis zu erlangen, damit Sie selbst entscheiden können.

🎥 Klicken Sie auf das Bild oben für ein Video: Yann LeCun spricht in diesem Vortrag über die Geschichte des Deep Learning
🚀 Herausforderung
Tauchen Sie in einen dieser historischen Momente ein und erfahren Sie mehr über die Menschen dahinter. Es gibt faszinierende Persönlichkeiten, und keine wissenschaftliche Entdeckung wurde jemals in einem kulturellen Vakuum gemacht. Was entdecken Sie?
Quiz nach der Vorlesung
Rückblick & Selbststudium
Hier sind einige Inhalte zum Anschauen und Anhören:
Dieser Podcast, in dem Amy Boyd über die Entwicklung der KI spricht

Aufgabe
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, weisen wir darauf hin, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.