20 KiB
Postscript: Model Debugging i Maskinlæring ved hjælp af komponenter fra Responsible AI-dashboardet
Pre-lecture quiz
Introduktion
Maskinlæring påvirker vores daglige liv. AI finder vej ind i nogle af de mest betydningsfulde systemer, der berører os som individer og som samfund, fra sundhedspleje, finans, uddannelse og beskæftigelse. For eksempel er systemer og modeller involveret i daglige beslutningsprocesser, såsom sundhedsdiagnoser eller afsløring af svindel. Som følge heraf mødes fremskridt inden for AI og den accelererede adoption med udviklende samfundsmæssige forventninger og stigende regulering. Vi ser konstant områder, hvor AI-systemer ikke lever op til forventningerne; de afslører nye udfordringer; og regeringer begynder at regulere AI-løsninger. Derfor er det vigtigt, at disse modeller analyseres for at sikre retfærdige, pålidelige, inkluderende, transparente og ansvarlige resultater for alle.
I dette pensum vil vi se på praktiske værktøjer, der kan bruges til at vurdere, om en model har problemer med ansvarlig AI. Traditionelle debugging-teknikker inden for maskinlæring er ofte baseret på kvantitative beregninger såsom samlet nøjagtighed eller gennemsnitligt fejl-tab. Forestil dig, hvad der kan ske, når de data, du bruger til at bygge disse modeller, mangler visse demografiske grupper, såsom race, køn, politisk holdning, religion, eller uforholdsmæssigt repræsenterer sådanne grupper. Hvad med når modellens output tolkes til at favorisere en bestemt demografisk gruppe? Dette kan føre til over- eller underrepræsentation af disse følsomme egenskabsgrupper, hvilket resulterer i retfærdigheds-, inklusions- eller pålidelighedsproblemer fra modellen. En anden faktor er, at maskinlæringsmodeller ofte betragtes som "black boxes", hvilket gør det svært at forstå og forklare, hvad der driver modellens forudsigelser. Alle disse er udfordringer, som dataforskere og AI-udviklere står over for, når de ikke har tilstrækkelige værktøjer til at debugge og vurdere en models retfærdighed eller troværdighed.
I denne lektion vil du lære at debugge dine modeller ved hjælp af:
- Fejlanalyse: Identificer, hvor i din datadistribution modellen har høje fejlrater.
- Modeloversigt: Udfør sammenlignende analyser på tværs af forskellige datakohorter for at opdage uligheder i modellens præstationsmålinger.
- Dataanalyse: Undersøg, hvor der kan være over- eller underrepræsentation af dine data, som kan skævvride din model til at favorisere én demografisk gruppe frem for en anden.
- Feature Importance: Forstå hvilke egenskaber der driver modellens forudsigelser på et globalt eller lokalt niveau.
Forudsætning
Som forudsætning bedes du gennemgå Responsible AI tools for developers

Fejlanalyse
Traditionelle præstationsmålinger for modeller, der bruges til at måle nøjagtighed, er ofte beregninger baseret på korrekte vs. forkerte forudsigelser. For eksempel kan det at fastslå, at en model er nøjagtig 89% af tiden med et fejl-tab på 0,001, betragtes som en god præstation. Fejl er dog ofte ikke jævnt fordelt i det underliggende datasæt. Du kan få en modelnøjagtighed på 89%, men opdage, at der er forskellige områder i dine data, hvor modellen fejler 42% af tiden. Konsekvensen af disse fejlmønstre med visse datagrupper kan føre til retfærdigheds- eller pålidelighedsproblemer. Det er afgørende at forstå områder, hvor modellen klarer sig godt eller dårligt. De dataområder, hvor der er et højt antal unøjagtigheder i din model, kan vise sig at være en vigtig demografisk gruppe.

Fejlanalyse-komponenten på RAI-dashboardet viser, hvordan model-fejl er fordelt på tværs af forskellige kohorter med en trævisualisering. Dette er nyttigt til at identificere egenskaber eller områder, hvor der er en høj fejlrater i dit datasæt. Ved at se, hvor de fleste af modellens unøjagtigheder kommer fra, kan du begynde at undersøge årsagen. Du kan også oprette datakohorter til at udføre analyser på. Disse datakohorter hjælper i debugging-processen med at afgøre, hvorfor modelpræstationen er god i én kohorte, men fejlagtig i en anden.

De visuelle indikatorer på trædiagrammet hjælper med at lokalisere problemområderne hurtigere. For eksempel, jo mørkere rød farve en træknude har, jo højere er fejlraten.
Heatmap er en anden visualiseringsfunktion, som brugere kan anvende til at undersøge fejlraten ved hjælp af én eller to egenskaber for at finde bidragende faktorer til modellens fejl på tværs af hele datasættet eller kohorter.

Brug fejlanalyse, når du har brug for at:
- Få en dyb forståelse af, hvordan model-fejl er fordelt på tværs af et datasæt og på tværs af flere input- og egenskabsdimensioner.
- Bryde de samlede præstationsmålinger ned for automatisk at opdage fejlagtige kohorter og informere dine målrettede afhjælpningstrin.
Modeloversigt
Evaluering af en maskinlæringsmodels præstation kræver en holistisk forståelse af dens adfærd. Dette kan opnås ved at gennemgå mere end én måling, såsom fejlrater, nøjagtighed, recall, præcision eller MAE (Mean Absolute Error) for at finde uligheder blandt præstationsmålinger. Én præstationsmåling kan se godt ud, men unøjagtigheder kan afsløres i en anden måling. Derudover hjælper sammenligning af målinger for uligheder på tværs af hele datasættet eller kohorter med at belyse, hvor modellen klarer sig godt eller dårligt. Dette er især vigtigt for at se modellens præstation blandt følsomme vs. ufølsomme egenskaber (f.eks. patientens race, køn eller alder) for at afdække potentiel uretfærdighed, modellen måtte have. For eksempel kan det at opdage, at modellen er mere fejlagtig i en kohorte med følsomme egenskaber, afsløre potentiel uretfærdighed.
Modeloversigt-komponenten på RAI-dashboardet hjælper ikke kun med at analysere præstationsmålinger for datarepræsentationen i en kohorte, men giver også brugerne mulighed for at sammenligne modellens adfærd på tværs af forskellige kohorter.

Komponentens egenskabsbaserede analysefunktionalitet giver brugerne mulighed for at indsnævre datasubgrupper inden for en bestemt egenskab for at identificere anomalier på et detaljeret niveau. For eksempel har dashboardet indbygget intelligens til automatisk at generere kohorter for en bruger-valgt egenskab (f.eks. "time_in_hospital < 3" eller "time_in_hospital >= 7"). Dette gør det muligt for en bruger at isolere en bestemt egenskab fra en større datagruppe for at se, om den er en nøglefaktor for modellens fejlagtige resultater.

Modeloversigt-komponenten understøtter to klasser af ulighedsmålinger:
Ulighed i modelpræstation: Disse sæt af målinger beregner uligheden (forskellen) i værdierne for den valgte præstationsmåling på tværs af data-subgrupper. Her er nogle eksempler:
- Ulighed i nøjagtighedsrate
- Ulighed i fejlrater
- Ulighed i præcision
- Ulighed i recall
- Ulighed i Mean Absolute Error (MAE)
Ulighed i udvælgelsesrate: Denne måling indeholder forskellen i udvælgelsesrate (gunstig forudsigelse) blandt subgrupper. Et eksempel på dette er ulighed i lånegodkendelsesrater. Udvælgelsesrate betyder andelen af datapunkter i hver klasse klassificeret som 1 (i binær klassifikation) eller fordelingen af forudsigelsesværdier (i regression).
Dataanalyse
"Hvis du torturerer data længe nok, vil de tilstå hvad som helst" - Ronald Coase
Denne udtalelse lyder ekstrem, men det er sandt, at data kan manipuleres til at understøtte enhver konklusion. Sådan manipulation kan nogle gange ske utilsigtet. Som mennesker har vi alle bias, og det er ofte svært at bevidst vide, hvornår man introducerer bias i data. At garantere retfærdighed i AI og maskinlæring forbliver en kompleks udfordring.
Data er et stort blindt punkt for traditionelle modelpræstationsmålinger. Du kan have høje nøjagtighedsscorer, men dette afspejler ikke altid den underliggende databias, der kunne være i dit datasæt. For eksempel, hvis et datasæt af medarbejdere har 27% kvinder i lederstillinger i en virksomhed og 73% mænd på samme niveau, kan en jobannoncerings-AI-model, der er trænet på disse data, målrette sig mest mod en mandlig målgruppe for seniorjobstillinger. Denne ubalance i data skævvred modellens forudsigelse til at favorisere ét køn. Dette afslører et retfærdighedsproblem, hvor der er kønsbias i AI-modellen.
Dataanalyse-komponenten på RAI-dashboardet hjælper med at identificere områder, hvor der er over- og underrepræsentation i datasættet. Den hjælper brugere med at diagnosticere årsagen til fejl og retfærdighedsproblemer, der introduceres fra dataubalancer eller manglende repræsentation af en bestemt datagruppe. Dette giver brugerne mulighed for at visualisere datasæt baseret på forudsagte og faktiske resultater, fejlgrupper og specifikke egenskaber. Nogle gange kan det at opdage en underrepræsenteret datagruppe også afsløre, at modellen ikke lærer godt, hvilket resulterer i høje unøjagtigheder. At have en model med databias er ikke kun et retfærdighedsproblem, men viser også, at modellen ikke er inkluderende eller pålidelig.

Brug dataanalyse, når du har brug for at:
- Udforske dine datasætstatistikker ved at vælge forskellige filtre for at opdele dine data i forskellige dimensioner (også kendt som kohorter).
- Forstå fordelingen af dit datasæt på tværs af forskellige kohorter og egenskabsgrupper.
- Afgøre, om dine fund relateret til retfærdighed, fejlanalyse og kausalitet (afledt fra andre dashboard-komponenter) skyldes dit datasæts fordeling.
- Beslutte, i hvilke områder du skal indsamle flere data for at afhjælpe fejl, der kommer fra repræsentationsproblemer, label-støj, egenskabsstøj, label-bias og lignende faktorer.
Modelfortolkning
Maskinlæringsmodeller har en tendens til at være "black boxes". Det kan være udfordrende at forstå, hvilke nøgleegenskaber der driver en models forudsigelse. Det er vigtigt at give gennemsigtighed i forhold til, hvorfor en model laver en bestemt forudsigelse. For eksempel, hvis et AI-system forudsiger, at en diabetisk patient er i risiko for at blive genindlagt på et hospital inden for mindre end 30 dage, bør det kunne give understøttende data, der førte til denne forudsigelse. At have understøttende dataindikatorer skaber gennemsigtighed, der hjælper klinikere eller hospitaler med at træffe velinformerede beslutninger. Derudover gør det muligt at forklare, hvorfor en model lavede en forudsigelse for en individuel patient, at man kan opfylde ansvarlighed med sundhedsreguleringer. Når du bruger maskinlæringsmodeller på måder, der påvirker menneskers liv, er det afgørende at forstå og forklare, hvad der påvirker en models adfærd. Model-forklarbarhed og fortolkning hjælper med at besvare spørgsmål i scenarier såsom:
- Model-debugging: Hvorfor lavede min model denne fejl? Hvordan kan jeg forbedre min model?
- Menneske-AI-samarbejde: Hvordan kan jeg forstå og stole på modellens beslutninger?
- Regulatorisk overholdelse: Opfylder min model lovkrav?
Feature Importance-komponenten på RAI-dashboardet hjælper dig med at debugge og få en omfattende forståelse af, hvordan en model laver forudsigelser. Det er også et nyttigt værktøj for maskinlæringsprofessionelle og beslutningstagere til at forklare og vise beviser for egenskaber, der påvirker en models adfærd for regulatorisk overholdelse. Brugere kan derefter udforske både globale og lokale forklaringer for at validere, hvilke egenskaber der driver en models forudsigelse. Globale forklaringer viser de vigtigste egenskaber, der påvirkede en models samlede forudsigelse. Lokale forklaringer viser, hvilke egenskaber der førte til en models forudsigelse for en individuel sag. Muligheden for at evaluere lokale forklaringer er også nyttig i debugging eller revision af en specifik sag for bedre at forstå og fortolke, hvorfor en model lavede en korrekt eller ukorrekt forudsigelse.
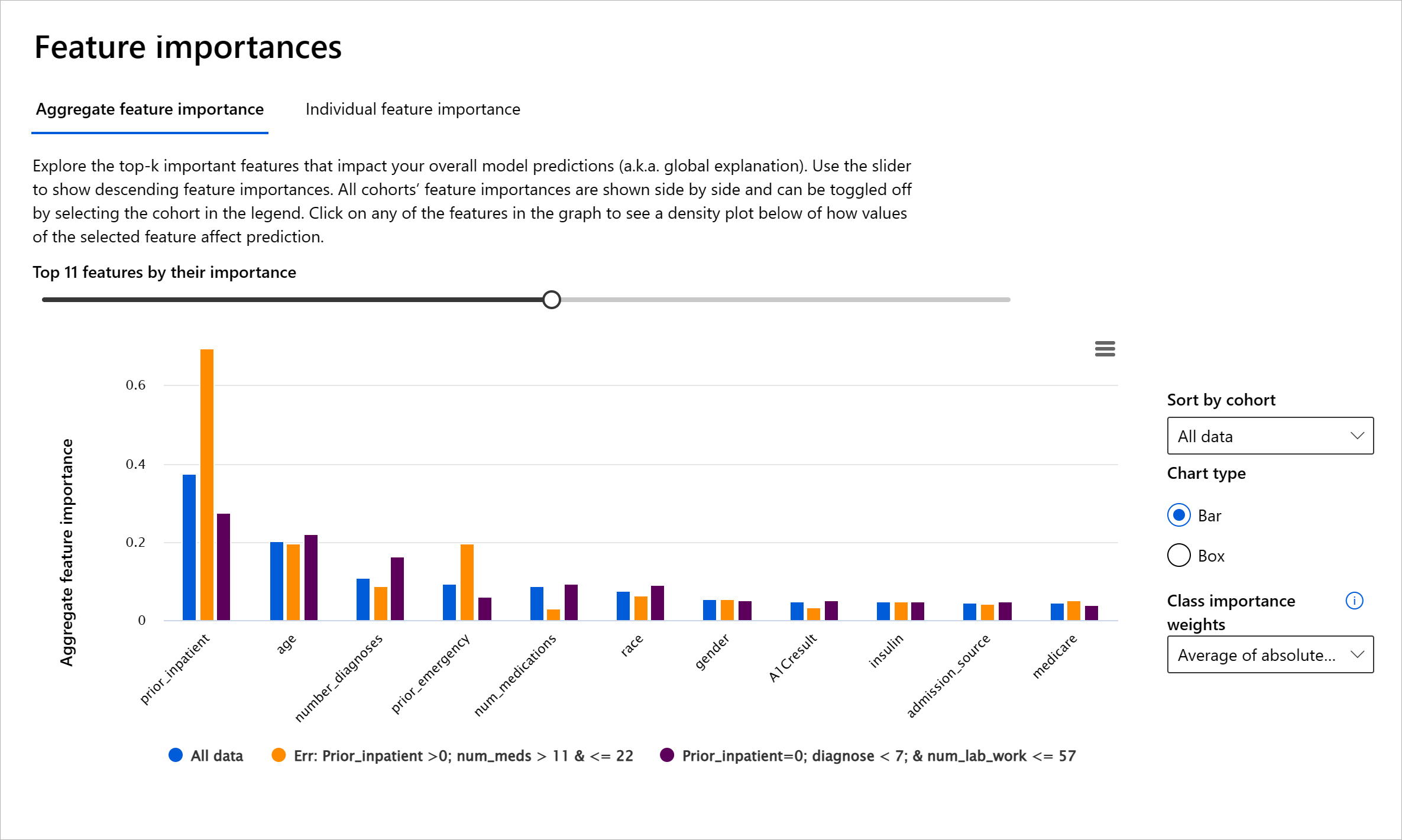
- Globale forklaringer: For eksempel, hvilke egenskaber påvirker den samlede adfærd af en diabetes-hospital-genindlæsningsmodel?
- Lokale forklaringer: For eksempel, hvorfor blev en diabetisk patient over 60 år med tidligere indlæggelser forudsagt til at blive genindlagt eller ikke genindlagt inden for 30 dage på et hospital?
I debugging-processen med at undersøge en models præstation på tværs af forskellige kohorter viser Feature Importance, hvilken grad af indflydelse en egenskab har på tværs af kohorter. Det hjælper med at afsløre anomalier, når man sammenligner niveauet af indflydelse, egenskaben har på at drive en models fejlagtige forudsigelser. Feature Importance-komponenten kan vise, hvilke værdier i en egenskab der positivt eller negativt påvirkede modellens resultat. For eksempel, hvis en model lavede en ukorrekt forudsigelse, giver komponenten dig mulighed for at bore ned og identificere, hvilke egenskaber eller egenskabsværdier der drev forudsigelsen. Dette detaljeringsniveau hjælper ikke kun med debugging, men skaber gennemsigtighed og ansvarlighed i revisionssituationer. Endelig kan komponenten hjælpe dig med at identificere retfærdighedsproblemer. For at illustrere, hvis en følsom egenskab såsom etnicitet eller køn har stor indflydelse på at drive en models forudsigelse, kan dette være et tegn på race- eller kønsbias i modellen.
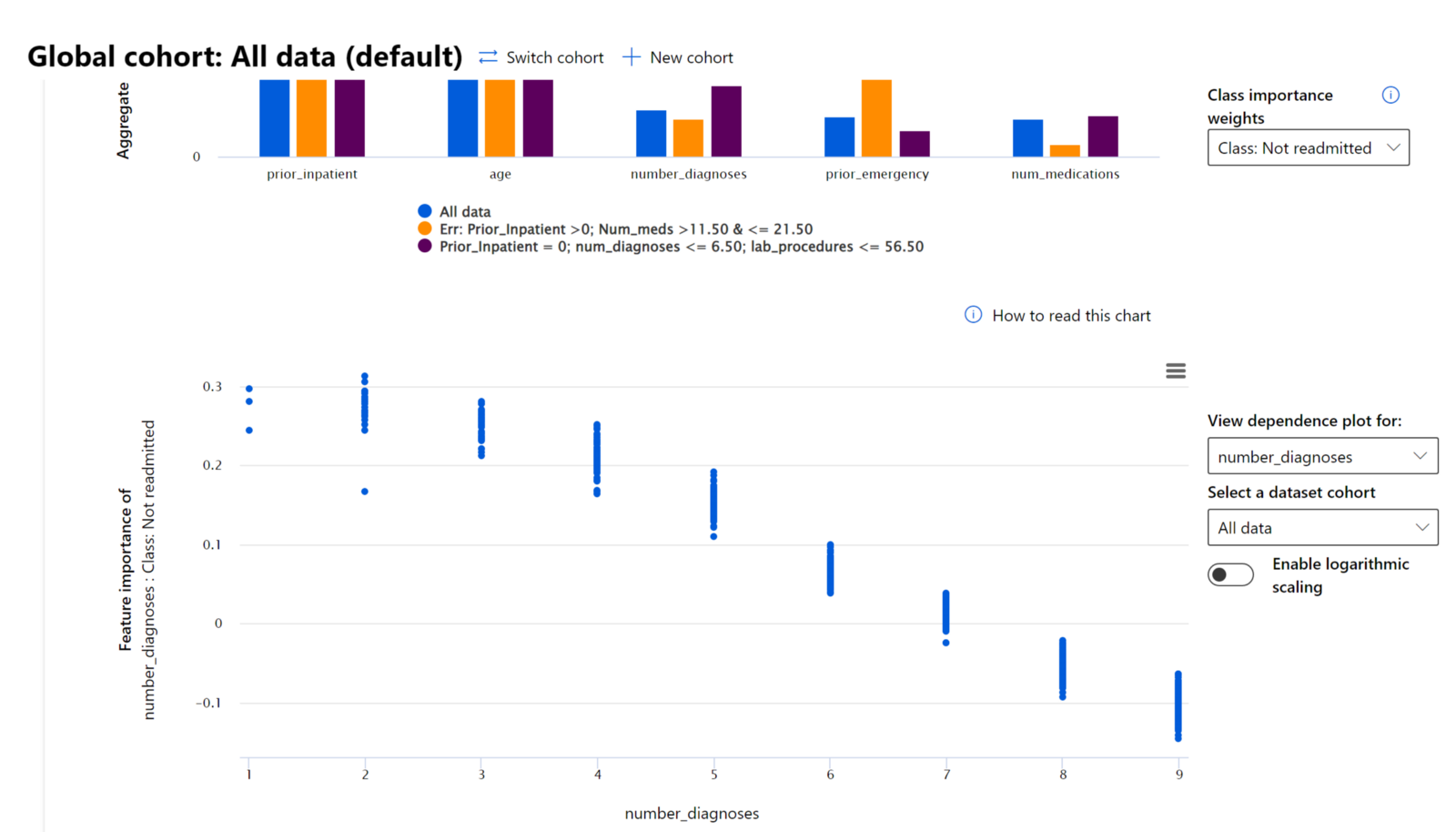
Brug fortolkning, når du har brug for at:
- Afgøre, hvor troværdige din AI-models forudsigelser er ved at forstå, hvilke egenskaber der er mest vigtige for forudsigelserne.
- Tilgå debugging af din model ved først at forstå den og identificere, om modellen bruger sunde egenskaber eller blot falske korrelationer.
- Afsløre potentielle kilder til uretfærdighed ved at forstå, om modellen baserer forudsigelser på følsomme egenskaber eller på egenskaber, der er stærkt korreleret med dem.
- Opbygge brugerens tillid til modellens beslutninger ved at generere lokale forklaringer for at illustrere deres resultater.
- Fuldføre en regulatorisk revision af et AI-system for at validere modeller og overvåge modellens beslutningers indvirkning på mennesker.
Konklusion
Alle komponenterne i RAI-dashboardet er praktiske værktøjer, der hjælper dig med at bygge maskinlæringsmodeller, der er mindre skadelige og mere troværdige for samfundet. Det forbedrer forebyggelsen af trusler mod menneskerettigheder; diskrimination eller eksklusion af visse grupper fra livsmuligheder; og risikoen for fysisk eller psykologisk skade. Det hjælper også med at opbygge tillid til modellens beslutninger ved at generere lokale forklaringer for at illustrere deres resultater. Nogle af de potentielle skader kan klassificeres som:
- Allokering, hvis et køn eller en etnicitet for eksempel favoriseres frem for en anden.
- Kvalitet af service. Hvis du træner data til et specifikt scenarie, men virkeligheden er langt mere kompleks, fører det til en dårligt fungerende service.
- Stereotyper. At associere en given gruppe med forudbestemte attributter.
- Nedvurdering. At kritisere og mærke noget eller nogen uretfærd
- Over- eller underrepræsentation. Ideen er, at en bestemt gruppe ikke er repræsenteret i et bestemt erhverv, og enhver tjeneste eller funktion, der fortsat fremmer dette, bidrager til skade.
Azure RAI-dashboard
Azure RAI-dashboard er bygget på open source-værktøjer udviklet af førende akademiske institutioner og organisationer, herunder Microsoft. Disse værktøjer er afgørende for dataforskere og AI-udviklere til bedre at forstå modeladfærd, opdage og afhjælpe uønskede problemer i AI-modeller.
-
Lær, hvordan du bruger de forskellige komponenter, ved at tjekke RAI-dashboardets dokumentation.
-
Se nogle RAI-dashboard eksempelsnotebooks til fejlfinding af mere ansvarlige AI-scenarier i Azure Machine Learning.
🚀 Udfordring
For at forhindre, at statistiske eller datamæssige skævheder opstår fra starten, bør vi:
- sikre en mangfoldighed af baggrunde og perspektiver blandt de personer, der arbejder på systemerne
- investere i datasæt, der afspejler mangfoldigheden i vores samfund
- udvikle bedre metoder til at opdage og rette skævheder, når de opstår
Tænk på virkelige scenarier, hvor uretfærdighed er tydelig i modeludvikling og brug. Hvad bør vi ellers overveje?
Quiz efter forelæsningen
Gennemgang & Selvstudie
I denne lektion har du lært nogle af de praktiske værktøjer til at integrere ansvarlig AI i maskinlæring.
Se denne workshop for at dykke dybere ned i emnerne:
- Responsible AI Dashboard: One-stop shop for operationalizing RAI in practice af Besmira Nushi og Mehrnoosh Sameki

🎥 Klik på billedet ovenfor for at se videoen: Responsible AI Dashboard: One-stop shop for operationalizing RAI in practice af Besmira Nushi og Mehrnoosh Sameki
Referér til følgende materialer for at lære mere om ansvarlig AI og hvordan man bygger mere pålidelige modeller:
-
Microsofts RAI-dashboardværktøjer til fejlfinding af ML-modeller: Ressourcer til ansvarlige AI-værktøjer
-
Udforsk Responsible AI-værktøjskassen: Github
-
Microsofts RAI-ressourcecenter: Responsible AI Resources – Microsoft AI
-
Microsofts FATE-forskningsgruppe: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Opgave
Ansvarsfraskrivelse:
Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på at opnå nøjagtighed, skal du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det originale dokument på dets oprindelige sprog bør betragtes som den autoritative kilde. For kritisk information anbefales professionel menneskelig oversættelse. Vi påtager os ikke ansvar for eventuelle misforståelser eller fejltolkninger, der måtte opstå som følge af brugen af denne oversættelse.