15 KiB
Začínáme s Pythonem a Scikit-learn pro regresní modely

Sketchnote od Tomomi Imura
Kvíz před lekcí
Tato lekce je dostupná v R!
Úvod
V těchto čtyřech lekcích se naučíte, jak vytvářet regresní modely. Brzy si vysvětlíme, k čemu slouží. Ale než začnete, ujistěte se, že máte správné nástroje pro zahájení procesu!
V této lekci se naučíte:
- Nastavit váš počítač pro úlohy strojového učení.
- Pracovat s Jupyter notebooky.
- Používat Scikit-learn, včetně instalace.
- Prozkoumat lineární regresi prostřednictvím praktického cvičení.
Instalace a konfigurace

🎥 Klikněte na obrázek výše pro krátké video o konfiguraci vašeho počítače pro ML.
-
Nainstalujte Python. Ujistěte se, že máte na svém počítači nainstalovaný Python. Python budete používat pro mnoho úloh v oblasti datové vědy a strojového učení. Většina počítačových systémů již obsahuje instalaci Pythonu. K dispozici jsou také užitečné Python Coding Packs, které usnadní nastavení pro některé uživatele.
Některé použití Pythonu však vyžaduje jednu verzi softwaru, zatímco jiné vyžaduje jinou verzi. Z tohoto důvodu je užitečné pracovat v virtuálním prostředí.
-
Nainstalujte Visual Studio Code. Ujistěte se, že máte na svém počítači nainstalovaný Visual Studio Code. Postupujte podle těchto pokynů pro instalaci Visual Studio Code pro základní instalaci. V tomto kurzu budete používat Python ve Visual Studio Code, takže byste si mohli osvěžit, jak konfigurovat Visual Studio Code pro vývoj v Pythonu.
Získejte jistotu v Pythonu prostřednictvím této sbírky modulů Learn

🎥 Klikněte na obrázek výše pro video: používání Pythonu ve VS Code.
-
Nainstalujte Scikit-learn podle těchto pokynů. Protože je potřeba zajistit, že používáte Python 3, doporučuje se použít virtuální prostředí. Pokud instalujete tuto knihovnu na Mac s procesorem M1, na stránce výše jsou speciální pokyny.
-
Nainstalujte Jupyter Notebook. Budete potřebovat nainstalovat balíček Jupyter.
Vaše prostředí pro tvorbu ML
Budete používat notebooky k vývoji vašeho Python kódu a vytváření modelů strojového učení. Tento typ souboru je běžným nástrojem pro datové vědce a lze jej identifikovat podle přípony .ipynb.
Notebooky jsou interaktivní prostředí, které umožňuje vývojáři nejen kódovat, ale také přidávat poznámky a psát dokumentaci kolem kódu, což je velmi užitečné pro experimentální nebo výzkumné projekty.

🎥 Klikněte na obrázek výše pro krátké video o tomto cvičení.
Cvičení - práce s notebookem
V této složce najdete soubor notebook.ipynb.
-
Otevřete notebook.ipynb ve Visual Studio Code.
Spustí se Jupyter server s Pythonem 3+. Najdete oblasti notebooku, které lze
spustit, tedy části kódu. Můžete spustit blok kódu výběrem ikony, která vypadá jako tlačítko přehrávání. -
Vyberte ikonu
mda přidejte trochu markdownu, například následující text # Vítejte ve vašem notebooku.Poté přidejte nějaký Python kód.
-
Napište print('hello notebook') do bloku kódu.
-
Vyberte šipku pro spuštění kódu.
Měli byste vidět vytištěný výstup:
hello notebook

Můžete prokládat váš kód komentáři, abyste si sami dokumentovali notebook.
✅ Zamyslete se na chvíli nad tím, jak se pracovní prostředí webového vývojáře liší od prostředí datového vědce.
Práce se Scikit-learn
Nyní, když máte Python nastavený ve vašem lokálním prostředí a jste si jisti prací s Jupyter notebooky, pojďme se stejně tak seznámit se Scikit-learn (vyslovujte sci jako science). Scikit-learn poskytuje rozsáhlé API, které vám pomůže provádět úlohy strojového učení.
Podle jejich webové stránky je "Scikit-learn open source knihovna strojového učení, která podporuje řízené a neřízené učení. Poskytuje také různé nástroje pro přizpůsobení modelů, předzpracování dat, výběr modelů a jejich hodnocení, a mnoho dalších užitečných funkcí."
V tomto kurzu budete používat Scikit-learn a další nástroje k vytváření modelů strojového učení pro provádění úloh, které nazýváme 'tradiční strojové učení'. Záměrně jsme se vyhnuli neuronovým sítím a hlubokému učení, protože ty jsou lépe pokryty v našem připravovaném kurzu 'AI pro začátečníky'.
Scikit-learn usnadňuje vytváření modelů a jejich hodnocení pro použití. Primárně se zaměřuje na práci s číselnými daty a obsahuje několik připravených datasetů pro použití jako učební nástroje. Obsahuje také předem připravené modely, které si studenti mohou vyzkoušet. Pojďme prozkoumat proces načítání předbalených dat a použití vestavěného odhadu pro první ML model se Scikit-learn s některými základními daty.
Cvičení - váš první notebook se Scikit-learn
Tento tutoriál byl inspirován příkladem lineární regrese na webu Scikit-learn.

🎥 Klikněte na obrázek výše pro krátké video o tomto cvičení.
V souboru notebook.ipynb přidruženém k této lekci vymažte všechny buňky stisknutím ikony 'koše'.
V této části budete pracovat s malým datasetem o diabetu, který je vestavěný ve Scikit-learn pro učební účely. Představte si, že chcete otestovat léčbu pro diabetické pacienty. Modely strojového učení vám mohou pomoci určit, kteří pacienti by na léčbu reagovali lépe, na základě kombinací proměnných. I velmi základní regresní model, pokud je vizualizován, může ukázat informace o proměnných, které by vám pomohly organizovat vaše teoretické klinické studie.
✅ Existuje mnoho typů regresních metod a výběr závisí na otázce, kterou chcete zodpovědět. Pokud chcete předpovědět pravděpodobnou výšku osoby určitého věku, použili byste lineární regresi, protože hledáte číselnou hodnotu. Pokud vás zajímá, zda by určitý typ kuchyně měl být považován za veganský nebo ne, hledáte kategorické přiřazení, takže byste použili logistickou regresi. Později se dozvíte více o logistické regresi. Zamyslete se nad některými otázkami, které můžete klást datům, a která z těchto metod by byla vhodnější.
Pojďme začít s tímto úkolem.
Import knihoven
Pro tento úkol importujeme některé knihovny:
- matplotlib. Je to užitečný nástroj pro grafy a použijeme ho k vytvoření čárového grafu.
- numpy. numpy je užitečná knihovna pro práci s číselnými daty v Pythonu.
- sklearn. Toto je knihovna Scikit-learn.
Importujte některé knihovny, které vám pomohou s úkoly.
-
Přidejte importy zadáním následujícího kódu:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionVýše importujete
matplotlib,numpya importujetedatasets,linear_modelamodel_selectionzsklearn.model_selectionse používá pro rozdělení dat na trénovací a testovací sady.
Dataset o diabetu
Vestavěný dataset o diabetu obsahuje 442 vzorků dat o diabetu s 10 proměnnými, mezi které patří:
- age: věk v letech
- bmi: index tělesné hmotnosti
- bp: průměrný krevní tlak
- s1 tc: T-lymfocyty (typ bílých krvinek)
✅ Tento dataset zahrnuje koncept 'pohlaví' jako důležitou proměnnou pro výzkum diabetu. Mnoho lékařských datasetů zahrnuje tento typ binární klasifikace. Zamyslete se nad tím, jak takové kategorizace mohou vyloučit určité části populace z léčby.
Nyní načtěte data X a y.
🎓 Pamatujte, že se jedná o řízené učení, a potřebujeme pojmenovaný cíl 'y'.
V nové buňce kódu načtěte dataset o diabetu pomocí load_diabetes(). Vstup return_X_y=True signalizuje, že X bude datová matice a y bude regresní cíl.
-
Přidejte příkazy pro zobrazení tvaru datové matice a jejího prvního prvku:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])To, co dostáváte jako odpověď, je tuple. To, co děláte, je přiřazení dvou prvních hodnot tuple k
Xay. Více se dozvíte o tuple.Můžete vidět, že tato data mají 442 položek uspořádaných v polích o 10 prvcích:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Zamyslete se nad vztahem mezi daty a regresním cílem. Lineární regrese předpovídá vztahy mezi proměnnou X a cílovou proměnnou y. Můžete najít cíl pro dataset o diabetu v dokumentaci? Co tento dataset demonstruje, vzhledem k cíli?
-
Dále vyberte část tohoto datasetu pro vykreslení výběrem 3. sloupce datasetu. Můžete to udělat pomocí operátoru
:pro výběr všech řádků a poté výběrem 3. sloupce pomocí indexu (2). Data můžete také přetvořit na 2D pole - jak je požadováno pro vykreslení - pomocíreshape(n_rows, n_columns). Pokud je jeden z parametrů -1, odpovídající rozměr se vypočítá automaticky.X = X[:, 2] X = X.reshape((-1,1))✅ Kdykoli si data vytiskněte, abyste zkontrolovali jejich tvar.
-
Nyní, když máte data připravená k vykreslení, můžete zjistit, zda stroj dokáže určit logické rozdělení mezi čísly v tomto datasetu. K tomu je potřeba rozdělit data (X) i cíl (y) na testovací a trénovací sady. Scikit-learn má jednoduchý způsob, jak to udělat; můžete rozdělit vaše testovací data na daném bodě.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Nyní jste připraveni trénovat váš model! Načtěte model lineární regrese a trénujte ho s vašimi trénovacími sadami X a y pomocí
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()je funkce, kterou uvidíte v mnoha knihovnách ML, jako je TensorFlow. -
Poté vytvořte predikci pomocí testovacích dat pomocí funkce
predict(). To bude použito k nakreslení čáry mezi skupinami dat.y_pred = model.predict(X_test) -
Nyní je čas zobrazit data v grafu. Matplotlib je velmi užitečný nástroj pro tento úkol. Vytvořte scatterplot všech testovacích dat X a y a použijte predikci k nakreslení čáry na nejvhodnějším místě mezi skupinami dat modelu.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()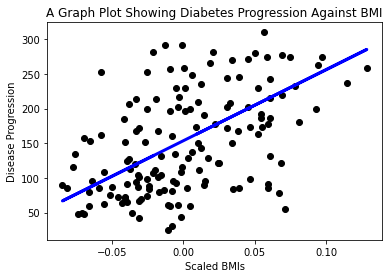 ✅ Zamyslete se nad tím, co se zde děje. Přímka prochází mnoha malými body dat, ale co přesně dělá? Vidíte, jak byste měli být schopni použít tuto přímku k předpovědi, kde by měl nový, dosud neviděný datový bod zapadnout ve vztahu k ose y grafu? Zkuste slovy popsat praktické využití tohoto modelu.
✅ Zamyslete se nad tím, co se zde děje. Přímka prochází mnoha malými body dat, ale co přesně dělá? Vidíte, jak byste měli být schopni použít tuto přímku k předpovědi, kde by měl nový, dosud neviděný datový bod zapadnout ve vztahu k ose y grafu? Zkuste slovy popsat praktické využití tohoto modelu.
Gratulujeme, vytvořili jste svůj první model lineární regrese, provedli předpověď a zobrazili ji v grafu!
🚀Výzva
Vykreslete jinou proměnnou z této datové sady. Tip: upravte tento řádek: X = X[:,2]. S ohledem na cíl této datové sady, co můžete zjistit o progresi diabetu jako nemoci?
Kvíz po přednášce
Přehled & Samostudium
V tomto tutoriálu jste pracovali s jednoduchou lineární regresí, nikoli s univariační nebo vícenásobnou lineární regresí. Přečtěte si něco o rozdílech mezi těmito metodami nebo se podívejte na toto video.
Přečtěte si více o konceptu regrese a zamyslete se nad tím, jaké typy otázek lze touto technikou zodpovědět. Absolvujte tento tutoriál, abyste si prohloubili své znalosti.
Zadání
Prohlášení:
Tento dokument byl přeložen pomocí služby pro automatický překlad Co-op Translator. Ačkoli se snažíme o přesnost, mějte na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho původním jazyce by měl být považován za autoritativní zdroj. Pro důležité informace se doporučuje profesionální lidský překlad. Neodpovídáme za žádné nedorozumění nebo nesprávné interpretace vyplývající z použití tohoto překladu.