16 KiB
Budování řešení strojového učení s odpovědnou AI
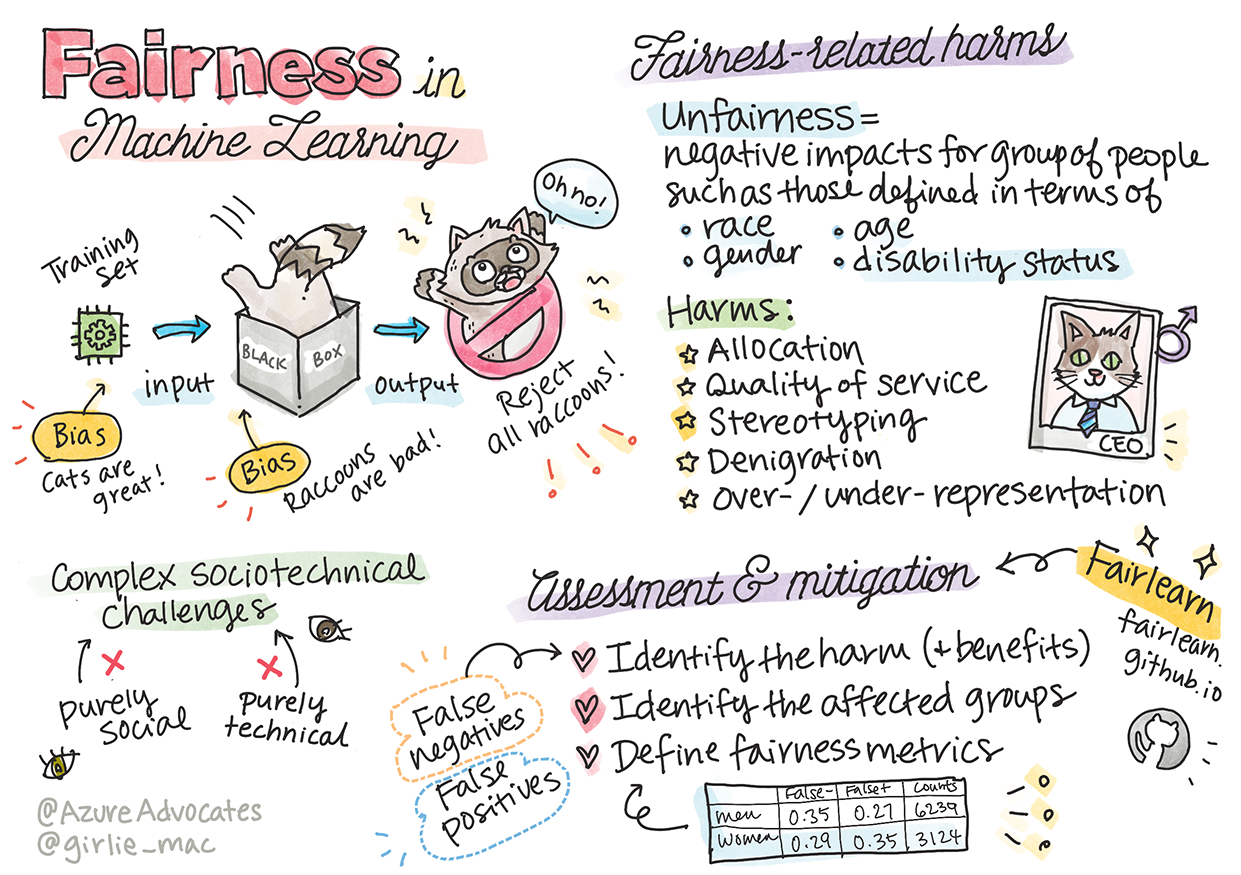
Sketchnote od Tomomi Imura
Kvíz před lekcí
Úvod
V tomto kurzu začnete objevovat, jak strojové učení ovlivňuje a může ovlivňovat náš každodenní život. Již nyní jsou systémy a modely zapojeny do každodenních rozhodovacích úkolů, jako jsou diagnózy ve zdravotnictví, schvalování půjček nebo odhalování podvodů. Je tedy důležité, aby tyto modely fungovaly dobře a poskytovaly důvěryhodné výsledky. Stejně jako u jakékoli softwarové aplikace, i systémy AI mohou selhat nebo mít nežádoucí výsledek. Proto je zásadní být schopen porozumět a vysvětlit chování modelu AI.
Představte si, co se může stát, když data, která používáte k vytváření těchto modelů, postrádají určité demografické údaje, jako je rasa, pohlaví, politický názor, náboženství, nebo naopak nepřiměřeně zastupují určité demografické skupiny. Co když je výstup modelu interpretován tak, že upřednostňuje určitou demografickou skupinu? Jaké to má důsledky pro aplikaci? A co se stane, když model má nepříznivý výsledek a je škodlivý pro lidi? Kdo je odpovědný za chování systému AI? To jsou některé otázky, které budeme v tomto kurzu zkoumat.
V této lekci se naučíte:
- Zvýšit povědomí o důležitosti spravedlnosti ve strojovém učení a o škodách spojených s nespravedlností.
- Seznámit se s praxí zkoumání odlehlých hodnot a neobvyklých scénářů pro zajištění spolehlivosti a bezpečnosti.
- Porozumět potřebě posilovat všechny tím, že navrhujete inkluzivní systémy.
- Prozkoumat, jak je důležité chránit soukromí a bezpečnost dat a lidí.
- Uvědomit si význam přístupu „skleněné krabice“ pro vysvětlení chování modelů AI.
- Být si vědomi toho, jak je odpovědnost klíčová pro budování důvěry v systémy AI.
Předpoklady
Jako předpoklad si projděte „Principy odpovědné AI“ na Learn Path a podívejte se na níže uvedené video na toto téma:
Zjistěte více o odpovědné AI prostřednictvím tohoto Learning Path

🎥 Klikněte na obrázek výše pro video: Přístup Microsoftu k odpovědné AI
Spravedlnost
Systémy AI by měly zacházet se všemi spravedlivě a vyhnout se tomu, aby ovlivňovaly podobné skupiny lidí různými způsoby. Například když systémy AI poskytují doporučení ohledně lékařské péče, žádostí o půjčky nebo zaměstnání, měly by dávat stejná doporučení všem s podobnými symptomy, finančními podmínkami nebo profesními kvalifikacemi. Každý z nás jako člověk má vrozené předsudky, které ovlivňují naše rozhodnutí a jednání. Tyto předsudky se mohou projevit v datech, která používáme k trénování systémů AI. Taková manipulace může někdy nastat neúmyslně. Často je obtížné vědomě rozpoznat, kdy do dat zavádíte předsudky.
„Nespravedlnost“ zahrnuje negativní dopady, nebo „škody“, na skupinu lidí, například definovanou podle rasy, pohlaví, věku nebo zdravotního postižení. Hlavní škody spojené se spravedlností lze klasifikovat jako:
- Alokace, pokud je například upřednostňováno jedno pohlaví nebo etnická skupina před jinou.
- Kvalita služby. Pokud trénujete data pro jeden konkrétní scénář, ale realita je mnohem složitější, vede to k špatně fungující službě. Například dávkovač mýdla, který nedokázal rozpoznat lidi s tmavou pletí. Reference
- Očernění. Nespravedlivé kritizování a označování něčeho nebo někoho. Například technologie označování obrázků nesprávně označila obrázky lidí s tmavou pletí jako gorily.
- Nad- nebo podreprezentace. Myšlenka, že určitá skupina není vidět v určité profesi, a jakákoli služba nebo funkce, která to nadále podporuje, přispívá ke škodě.
- Stereotypizace. Spojování určité skupiny s předem přiřazenými atributy. Například systém překladu mezi angličtinou a turečtinou může mít nepřesnosti kvůli slovům se stereotypními asociacemi k pohlaví.
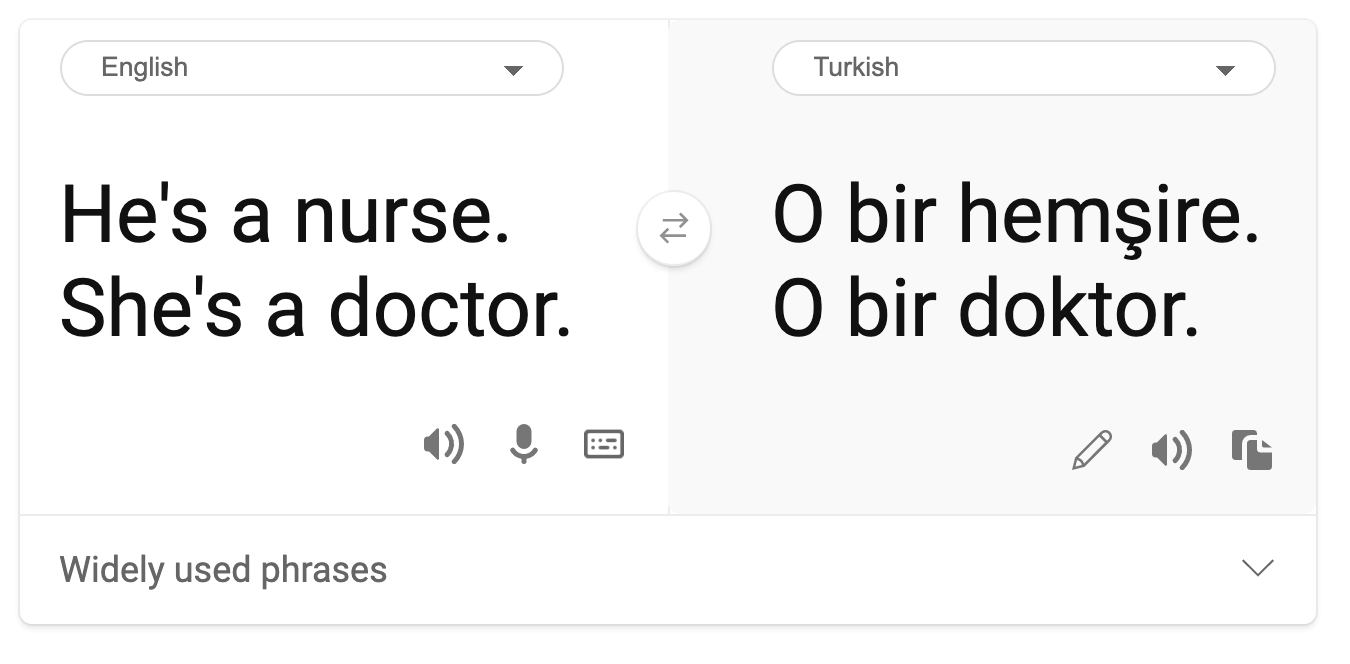
překlad do turečtiny

překlad zpět do angličtiny
Při navrhování a testování systémů AI musíme zajistit, že AI je spravedlivá a není naprogramována tak, aby činila zaujatá nebo diskriminační rozhodnutí, která jsou zakázána i lidem. Zajištění spravedlnosti v AI a strojovém učení zůstává složitou sociotechnickou výzvou.
Spolehlivost a bezpečnost
Pro budování důvěry musí být systémy AI spolehlivé, bezpečné a konzistentní za normálních i neočekávaných podmínek. Je důležité vědět, jak se systémy AI budou chovat v různých situacích, zejména když se jedná o odlehlé hodnoty. Při budování řešení AI je třeba věnovat značnou pozornost tomu, jak zvládnout širokou škálu okolností, se kterými se řešení AI může setkat. Například samořídící auto musí klást bezpečnost lidí na první místo. Výsledkem je, že AI pohánějící auto musí zohlednit všechny možné scénáře, se kterými se auto může setkat, jako je noc, bouřky nebo sněhové bouře, děti běžící přes ulici, domácí mazlíčci, silniční stavby atd. Jak dobře systém AI dokáže spolehlivě a bezpečně zvládnout širokou škálu podmínek, odráží úroveň předvídavosti, kterou datový vědec nebo vývojář AI zohlednil při návrhu nebo testování systému.
Inkluzivita
Systémy AI by měly být navrženy tak, aby zapojily a posílily všechny. Při navrhování a implementaci systémů AI datoví vědci a vývojáři AI identifikují a řeší potenciální bariéry v systému, které by mohly neúmyslně vyloučit lidi. Například na světě je 1 miliarda lidí s postižením. Díky pokroku v AI mohou snadněji přistupovat k široké škále informací a příležitostí ve svém každodenním životě. Řešením bariér vznikají příležitosti k inovacím a vývoji produktů AI s lepšími zkušenostmi, které přinášejí užitek všem.
Bezpečnost a soukromí
Systémy AI by měly být bezpečné a respektovat soukromí lidí. Lidé mají menší důvěru v systémy, které ohrožují jejich soukromí, informace nebo životy. Při trénování modelů strojového učení se spoléháme na data, abychom dosáhli co nejlepších výsledků. Při tom je třeba zohlednit původ dat a jejich integritu. Například byla data poskytnuta uživateli nebo byla veřejně dostupná? Dále je při práci s daty zásadní vyvíjet systémy AI, které dokážou chránit důvěrné informace a odolávat útokům. Jak se AI stává rozšířenější, ochrana soukromí a zabezpečení důležitých osobních a obchodních informací se stává stále důležitější a složitější. Otázky soukromí a bezpečnosti dat vyžadují zvláštní pozornost u AI, protože přístup k datům je nezbytný pro to, aby systémy AI mohly činit přesné a informované předpovědi a rozhodnutí o lidech.
- Jako průmysl jsme dosáhli významného pokroku v oblasti soukromí a bezpečnosti, výrazně podpořeného regulacemi, jako je GDPR (Obecné nařízení o ochraně osobních údajů).
- Přesto u systémů AI musíme uznat napětí mezi potřebou více osobních dat pro zlepšení personalizace a efektivity systémů – a ochranou soukromí.
- Stejně jako při vzniku propojených počítačů s internetem, vidíme také obrovský nárůst počtu bezpečnostních problémů souvisejících s AI.
- Zároveň jsme viděli, že AI je využívána ke zlepšení bezpečnosti. Například většina moderních antivirových skenerů je dnes poháněna heuristikou AI.
- Musíme zajistit, aby naše procesy datové vědy harmonicky zapadaly do nejnovějších postupů v oblasti soukromí a bezpečnosti.
Transparentnost
Systémy AI by měly být srozumitelné. Klíčovou součástí transparentnosti je vysvětlení chování systémů AI a jejich komponent. Zlepšení porozumění systémům AI vyžaduje, aby zainteresované strany pochopily, jak a proč fungují, aby mohly identifikovat potenciální problémy s výkonem, obavy o bezpečnost a soukromí, předsudky, vylučující praktiky nebo nechtěné výsledky. Věříme také, že ti, kdo používají systémy AI, by měli být upřímní a otevření ohledně toho, kdy, proč a jak se rozhodnou je nasadit. Stejně tak o omezeních systémů, které používají. Například pokud banka používá systém AI k podpoře svých rozhodnutí o spotřebitelských půjčkách, je důležité zkoumat výsledky a pochopit, která data ovlivňují doporučení systému. Vlády začínají regulovat AI napříč odvětvími, takže datoví vědci a organizace musí vysvětlit, zda systém AI splňuje regulační požadavky, zejména když dojde k nežádoucímu výsledku.
- Protože systémy AI jsou tak složité, je těžké pochopit, jak fungují a interpretovat výsledky.
- Tento nedostatek porozumění ovlivňuje způsob, jakým jsou tyto systémy spravovány, provozovány a dokumentovány.
- Tento nedostatek porozumění především ovlivňuje rozhodnutí učiněná na základě výsledků, které tyto systémy produkují.
Odpovědnost
Lidé, kteří navrhují a nasazují systémy AI, musí být odpovědní za to, jak jejich systémy fungují. Potřeba odpovědnosti je obzvláště důležitá u technologií citlivého použití, jako je rozpoznávání obličeje. V poslední době roste poptávka po technologii rozpoznávání obličeje, zejména ze strany orgánů činných v trestním řízení, které vidí potenciál této technologie například při hledání pohřešovaných dětí. Tyto technologie však mohou být potenciálně využívány vládou k ohrožení základních svobod občanů, například umožněním nepřetržitého sledování konkrétních jednotlivců. Proto musí být datoví vědci a organizace odpovědní za to, jak jejich systém AI ovlivňuje jednotlivce nebo společnost.
🎥 Klikněte na obrázek výše pro video: Varování před masovým sledováním prostřednictvím rozpoznávání obličeje
Nakonec jednou z největších otázek pro naši generaci, jako první generaci, která přináší AI do společnosti, je, jak zajistit, aby počítače zůstaly odpovědné vůči lidem a jak zajistit, aby lidé, kteří počítače navrhují, zůstali odpovědní vůči všem ostatním.
Posouzení dopadu
Před trénováním modelu strojového učení je důležité provést posouzení dopadu, abyste pochopili účel systému AI; jaké je zamýšlené použití; kde bude nasazen; a kdo bude se systémem interagovat. Tyto informace jsou užitečné pro recenzenty nebo testery, kteří hodnotí systém, aby věděli, jaké faktory je třeba vzít v úvahu při identifikaci potenciálních rizik a očekávaných důsledků.
Následující oblasti jsou klíčové při provádění posouzení dopadu:
- Nepříznivý dopad na jednotlivce. Být si vědom jakýchkoli omezení nebo požadavků, nepodporovaného použití nebo známých omezení, která brání výkonu systému, je zásadní pro zajištění toho, že systém nebude používán způsobem, který by mohl způsobit škodu jednotlivcům.
- Požadavky na data. Získání porozumění tomu, jak a kde systém bude používat data, umožňuje recenzentům prozkoumat jakékoli požadavky na data, na které byste měli být ohleduplní (např. GDPR nebo HIPPA regulace dat). Dále je třeba zkoumat, zda je zdroj nebo množství dat dostatečné pro trénování.
- Shrnutí dopadu. Sestavte seznam potenciálních škod, které by mohly vzniknout při používání systému. Během životního cyklu ML zkontrolujte, zda byly identifikované problémy zmírněny nebo vyřešeny.
- Platné cíle pro každou ze šesti základních zásad. Posuďte, zda byly cíle z každé zásady splněny a zda existují nějaké mezery.
Ladění s odpovědnou AI
Podobně jako ladění softwarové aplikace je ladění systému AI nezbytným procesem identifikace a řešení problémů v systému. Existuje mnoho faktorů, které mohou ovlivnit, že model nefunguje podle očekávání nebo odpovědně. Většina tradičních metrik výkonu modelu jsou kvantitativní agregáty výkonu modelu, které nejsou dostatečné k analýze, jak model porušuje zásady odpovědné AI. Navíc je model strojového učení černou skříňkou, což ztěžuje pochopení, co ovlivňuje jeho výstup, nebo poskytování vysvětlení, když udělá chybu. Později v tomto kurzu se naučíme, jak používat dashboard odpovědné AI k ladění systémů AI. Dashboard poskytuje komplexní nástroj pro datové vědce a vývojáře AI k provádění:
- Analýzy chyb. Identifikace rozložení chyb modelu, které mohou ovlivnit spravedlnost nebo spolehlivost systému.
- Přehledu modelu. Objevování, kde jsou rozdíly ve výkonu modelu napříč datovými kohortami.
- Analýzy dat. Porozumění rozložení dat a identifikace jakéhokoli potenciálního předsudku v datech, který by mohl vést k problémům se spravedlností Podívejte se na tento workshop, abyste se ponořili hlouběji do témat:
- V hledání odpovědné AI: Přenesení principů do praxe od Besmiry Nushi, Mehrnoosh Sameki a Amita Sharmy

🎥 Klikněte na obrázek výše pro video: RAI Toolbox: Open-source rámec pro budování odpovědné AI od Besmiry Nushi, Mehrnoosh Sameki a Amita Sharmy
Také si přečtěte:
-
Microsoftův RAI zdrojový centrum: Responsible AI Resources – Microsoft AI
-
Microsoftova výzkumná skupina FATE: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Přečtěte si o nástrojích Azure Machine Learning pro zajištění spravedlnosti:
Úkol
Prohlášení:
Tento dokument byl přeložen pomocí služby pro automatický překlad Co-op Translator. Ačkoli se snažíme o přesnost, mějte na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho původním jazyce by měl být považován za autoritativní zdroj. Pro důležité informace doporučujeme profesionální lidský překlad. Neodpovídáme za žádná nedorozumění nebo nesprávné interpretace vyplývající z použití tohoto překladu.