37 KiB
পোস্টস্ক্রিপ্ট: মডেল ডিবাগিং মেশিন লার্নিং-এ রেসপন্সিবল AI ড্যাশবোর্ড কম্পোনেন্ট ব্যবহার করে
পূর্ব-লেকচার কুইজ
ভূমিকা
মেশিন লার্নিং আমাদের দৈনন্দিন জীবনে প্রভাব ফেলে। AI এখন এমন গুরুত্বপূর্ণ সিস্টেমে প্রবেশ করছে যা আমাদের ব্যক্তিগত এবং সামাজিক জীবনে প্রভাব ফেলে, যেমন স্বাস্থ্যসেবা, অর্থনীতি, শিক্ষা এবং কর্মসংস্থান। উদাহরণস্বরূপ, সিস্টেম এবং মডেল দৈনন্দিন সিদ্ধান্ত গ্রহণের কাজে ব্যবহৃত হয়, যেমন স্বাস্থ্যসেবা নির্ণয় বা প্রতারণা সনাক্তকরণ। এর ফলে, AI-এর অগ্রগতি এবং দ্রুত গ্রহণের সঙ্গে সঙ্গে সমাজের প্রত্যাশা এবং নিয়মাবলীও পরিবর্তিত হচ্ছে। আমরা প্রায়ই দেখি যে AI সিস্টেমগুলি প্রত্যাশা পূরণ করতে ব্যর্থ হয়; তারা নতুন চ্যালেঞ্জ উন্মোচন করে; এবং সরকার AI সমাধান নিয়ন্ত্রণ করতে শুরু করেছে। তাই, এই মডেলগুলো বিশ্লেষণ করা গুরুত্বপূর্ণ যাতে সবার জন্য ন্যায্য, নির্ভরযোগ্য, অন্তর্ভুক্তিমূলক, স্বচ্ছ এবং দায়িত্বশীল ফলাফল নিশ্চিত করা যায়।
এই পাঠ্যক্রমে, আমরা ব্যবহারিক টুল নিয়ে আলোচনা করব যা মডেলের রেসপন্সিবল AI সমস্যা আছে কিনা তা মূল্যায়ন করতে সাহায্য করে। প্রচলিত মেশিন লার্নিং ডিবাগিং কৌশল সাধারণত পরিমাণগত গণনার উপর ভিত্তি করে, যেমন সামগ্রিক সঠিকতা বা গড় ত্রুটি হার। কল্পনা করুন, আপনি যে ডেটা ব্যবহার করছেন তা যদি কিছু জনসংখ্যাগত তথ্যের অভাব থাকে, যেমন জাতি, লিঙ্গ, রাজনৈতিক মতামত, ধর্ম, বা যদি এটি এই জনসংখ্যাকে অসমভাবে উপস্থাপন করে। আবার, যদি মডেলের আউটপুট কিছু জনসংখ্যাকে প্রাধান্য দেয়, তাহলে এটি সংবেদনশীল বৈশিষ্ট্য গোষ্ঠীর অতিরিক্ত বা কম প্রতিনিধিত্ব সৃষ্টি করতে পারে, যা মডেলের ন্যায্যতা, অন্তর্ভুক্তি বা নির্ভরযোগ্যতার সমস্যার কারণ হতে পারে। আরেকটি বিষয় হলো, মেশিন লার্নিং মডেলগুলোকে "ব্ল্যাক বক্স" হিসেবে বিবেচনা করা হয়, যা মডেলের পূর্বাভাসের কারণ বোঝা এবং ব্যাখ্যা করা কঠিন করে তোলে। এই সমস্ত চ্যালেঞ্জের মুখোমুখি হন ডেটা বিজ্ঞানী এবং AI ডেভেলপাররা যখন তাদের কাছে মডেলের ন্যায্যতা বা বিশ্বাসযোগ্যতা মূল্যায়নের জন্য পর্যাপ্ত টুল থাকে না।
এই পাঠে, আপনি শিখবেন কীভাবে আপনার মডেল ডিবাগ করবেন:
- ত্রুটি বিশ্লেষণ: আপনার ডেটা বিতরণে মডেলের উচ্চ ত্রুটি হার কোথায় রয়েছে তা চিহ্নিত করুন।
- মডেল ওভারভিউ: বিভিন্ন ডেটা কোহর্টের মধ্যে তুলনামূলক বিশ্লেষণ করুন যাতে মডেলের পারফরম্যান্স মেট্রিকগুলিতে বৈষম্য আবিষ্কার করা যায়।
- ডেটা বিশ্লেষণ: যেখানে আপনার ডেটার অতিরিক্ত বা কম প্রতিনিধিত্ব থাকতে পারে তা তদন্ত করুন, যা আপনার মডেলকে এক ডেটা জনসংখ্যার পক্ষে পক্ষপাতিত্ব করতে প্রভাবিত করতে পারে।
- ফিচার ইম্পরট্যান্স: বৈশ্বিক বা স্থানীয় স্তরে কোন বৈশিষ্ট্যগুলি আপনার মডেলের পূর্বাভাস চালাচ্ছে তা বুঝুন।
পূর্বশর্ত
পূর্বশর্ত হিসেবে, ডেভেলপারদের জন্য রেসপন্সিবল AI টুল পর্যালোচনা করুন।

ত্রুটি বিশ্লেষণ
প্রচলিত মডেল পারফরম্যান্স মেট্রিক, যা সঠিকতা পরিমাপের জন্য ব্যবহৃত হয়, সাধারণত সঠিক বনাম ভুল পূর্বাভাসের উপর ভিত্তি করে গণনা করা হয়। উদাহরণস্বরূপ, একটি মডেল ৮৯% সময় সঠিক এবং ত্রুটি হার ০.০০১ হলে এটি ভালো পারফরম্যান্স হিসেবে বিবেচিত হতে পারে। তবে ত্রুটি আপনার ডেটাসেটে সমানভাবে বিতরণ নাও হতে পারে। আপনি ৮৯% মডেল সঠিকতার স্কোর পেতে পারেন, কিন্তু দেখতে পারেন যে আপনার ডেটার কিছু অঞ্চলে মডেল ৪২% সময় ব্যর্থ হচ্ছে। এই ব্যর্থতার প্যাটার্নের ফলে নির্দিষ্ট ডেটা গোষ্ঠীর ক্ষেত্রে ন্যায্যতা বা নির্ভরযোগ্যতার সমস্যা দেখা দিতে পারে। মডেল কোথায় ভালো করছে বা কোথায় ব্যর্থ হচ্ছে তা বোঝা অত্যন্ত গুরুত্বপূর্ণ। ডেটার সেই অঞ্চলগুলো যেখানে মডেলের ত্রুটি বেশি, তা গুরুত্বপূর্ণ ডেটা জনসংখ্যা হতে পারে।

RAI ড্যাশবোর্ডের ত্রুটি বিশ্লেষণ কম্পোনেন্ট একটি গাছের ভিজ্যুয়ালাইজেশনের মাধ্যমে মডেলের ব্যর্থতা বিভিন্ন কোহর্টে কীভাবে বিতরণ হয়েছে তা দেখায়। এটি আপনার ডেটাসেটে উচ্চ ত্রুটি হার রয়েছে এমন বৈশিষ্ট্য বা এলাকাগুলি চিহ্নিত করতে সহায়ক। মডেলের বেশিরভাগ ত্রুটি কোথা থেকে আসছে তা দেখে আপনি মূল কারণ তদন্ত শুরু করতে পারেন। আপনি ডেটা কোহর্ট তৈরি করে বিশ্লেষণ করতে পারেন। এই ডেটা কোহর্টগুলো ডিবাগিং প্রক্রিয়ায় সাহায্য করে, কেন মডেল একটি কোহর্টে ভালো পারফর্ম করছে কিন্তু অন্যটিতে ভুল করছে তা নির্ধারণ করতে।

গাছের মানচিত্রে গাঢ় লাল রঙের ছায়া দ্রুত সমস্যার এলাকাগুলি চিহ্নিত করতে সাহায্য করে। উদাহরণস্বরূপ, একটি গাছের নোড যত গাঢ় লাল, ত্রুটি হার তত বেশি।
হিট ম্যাপ একটি অন্য ভিজ্যুয়ালাইজেশন কার্যকারিতা যা ব্যবহারকারীরা এক বা দুটি বৈশিষ্ট্য ব্যবহার করে ত্রুটি হার তদন্ত করতে ব্যবহার করতে পারেন, যা পুরো ডেটাসেট বা কোহর্টে মডেলের ত্রুটির কারণ খুঁজে বের করতে সাহায্য করে।

ত্রুটি বিশ্লেষণ ব্যবহার করুন যখন আপনি:
- মডেলের ব্যর্থতা কীভাবে ডেটাসেট এবং বিভিন্ন ইনপুট ও বৈশিষ্ট্য মাত্রায় বিতরণ হয়েছে তা গভীরভাবে বুঝতে চান।
- সামগ্রিক পারফরম্যান্স মেট্রিক ভেঙে ত্রুটিপূর্ণ কোহর্টগুলি স্বয়ংক্রিয়ভাবে আবিষ্কার করতে চান, যা আপনার লক্ষ্যযুক্ত সমাধান পদক্ষেপগুলিকে জানাতে সাহায্য করবে।
মডেল ওভারভিউ
একটি মেশিন লার্নিং মডেলের পারফরম্যান্স মূল্যায়ন করতে হলে এর আচরণের একটি সামগ্রিক ধারণা পাওয়া প্রয়োজন। এটি একাধিক মেট্রিক পর্যালোচনা করে অর্জন করা যেতে পারে, যেমন ত্রুটি হার, সঠিকতা, রিকল, প্রিসিশন, বা MAE (Mean Absolute Error) এর মধ্যে বৈষম্য খুঁজে বের করা। একটি পারফরম্যান্স মেট্রিক ভালো দেখাতে পারে, কিন্তু অন্য মেট্রিকে ত্রুটি প্রকাশিত হতে পারে। এছাড়াও, পুরো ডেটাসেট বা কোহর্টের মধ্যে মেট্রিকগুলির তুলনা পারফরম্যান্সের বৈষম্য প্রকাশ করতে সাহায্য করে। এটি বিশেষভাবে গুরুত্বপূর্ণ যখন সংবেদনশীল বনাম অসংবেদনশীল বৈশিষ্ট্যের (যেমন রোগীর জাতি, লিঙ্গ, বা বয়স) মধ্যে মডেলের পারফরম্যান্স দেখা হয়, যাতে মডেলের সম্ভাব্য অন্যায়তা প্রকাশ করা যায়। উদাহরণস্বরূপ, যদি দেখা যায় যে মডেল একটি সংবেদনশীল বৈশিষ্ট্যযুক্ত কোহর্টে বেশি ত্রুটি করছে, তাহলে এটি মডেলের সম্ভাব্য অন্যায়তা প্রকাশ করতে পারে।
RAI ড্যাশবোর্ডের মডেল ওভারভিউ কম্পোনেন্ট শুধুমাত্র ডেটা কোহর্টে পারফরম্যান্স মেট্রিক বিশ্লেষণ করতে সাহায্য করে না, এটি ব্যবহারকারীদের বিভিন্ন কোহর্টের মধ্যে মডেলের আচরণ তুলনা করার ক্ষমতা দেয়।

কম্পোনেন্টের বৈশিষ্ট্য-ভিত্তিক বিশ্লেষণ কার্যকারিতা ব্যবহারকারীদের একটি নির্দিষ্ট বৈশিষ্ট্যের মধ্যে ডেটা উপগোষ্ঠী সংকুচিত করতে এবং একটি সূক্ষ্ম স্তরে অস্বাভাবিকতা চিহ্নিত করতে সাহায্য করে। উদাহরণস্বরূপ, ড্যাশবোর্ডে একটি ব্যবহারকারী-নির্বাচিত বৈশিষ্ট্যের জন্য স্বয়ংক্রিয়ভাবে কোহর্ট তৈরি করার বিল্ট-ইন বুদ্ধিমত্তা রয়েছে (যেমন "time_in_hospital < 3" বা "time_in_hospital >= 7")। এটি ব্যবহারকারীকে একটি বড় ডেটা গোষ্ঠী থেকে একটি নির্দিষ্ট বৈশিষ্ট্য আলাদা করতে সক্ষম করে, যাতে দেখা যায় এটি মডেলের ত্রুটিপূর্ণ ফলাফলের একটি মূল প্রভাবক কিনা।

মডেল ওভারভিউ কম্পোনেন্ট দুটি শ্রেণির বৈষম্য মেট্রিক সমর্থন করে:
মডেল পারফরম্যান্সে বৈষম্য: এই সেটের মেট্রিকগুলি ডেটার উপগোষ্ঠীগুলির মধ্যে নির্বাচিত পারফরম্যান্স মেট্রিকের মানগুলির বৈষম্য (পার্থক্য) গণনা করে। এখানে কয়েকটি উদাহরণ:
- সঠিকতার হার বৈষম্য
- ত্রুটি হার বৈষম্য
- প্রিসিশন বৈষম্য
- রিকল বৈষম্য
- গড় পরম ত্রুটি (MAE) বৈষম্য
নির্বাচনের হার বৈষম্য: এই মেট্রিকটি উপগোষ্ঠীগুলির মধ্যে নির্বাচনের হার (অনুকূল পূর্বাভাস) এর পার্থক্য ধারণ করে। এর একটি উদাহরণ হলো ঋণ অনুমোদনের হার বৈষম্য। নির্বাচনের হার মানে প্রতিটি শ্রেণির ডেটা পয়েন্টের ভগ্নাংশ যা ১ হিসেবে শ্রেণীবদ্ধ (বাইনারি শ্রেণীবিভাজনে) বা পূর্বাভাসের মানগুলির বিতরণ (রিগ্রেশনে)।
ডেটা বিশ্লেষণ
"যদি আপনি ডেটাকে যথেষ্ট সময় ধরে চাপ দেন, এটি যেকোনো কিছু স্বীকার করবে" - রোনাল্ড কোস
এই বক্তব্যটি চরম শোনায়, কিন্তু এটি সত্য যে ডেটা যেকোনো সিদ্ধান্তকে সমর্থন করার জন্য প্রভাবিত করা যেতে পারে। এমন প্রভাব কখনও কখনও অনিচ্ছাকৃতভাবে ঘটতে পারে। আমরা সবাই মানুষ হিসেবে পক্ষপাতিত্ব করি, এবং ডেটায় পক্ষপাতিত্ব প্রবর্তন করছি কিনা তা সচেতনভাবে জানা প্রায়ই কঠিন। AI এবং মেশিন লার্নিং-এ ন্যায্যতা নিশ্চিত করা একটি জটিল চ্যালেঞ্জ।
ডেটা প্রচলিত মডেল পারফরম্যান্স মেট্রিকের জন্য একটি বড় অন্ধকার অঞ্চল। আপনার সঠিকতার স্কোর উচ্চ হতে পারে, কিন্তু এটি সবসময় আপনার ডেটাসেটে থাকা অন্তর্নিহিত ডেটা পক্ষপাতিত্ব প্রতিফলিত করে না। উদাহরণস্বরূপ, যদি একটি কোম্পানির নির্বাহী পদে কর্মীদের ডেটাসেটে ২৭% নারী এবং ৭৩% পুরুষ থাকে, তাহলে এই ডেটার উপর প্রশিক্ষিত একটি চাকরি বিজ্ঞাপন AI মডেল মূলত পুরুষদের লক্ষ্য করতে পারে। এই ডেটার ভারসাম্যহীনতা মডেলের পূর্বাভাসকে এক লিঙ্গের পক্ষে পক্ষপাতিত্ব করেছে। এটি একটি ন্যায্যতার সমস্যা প্রকাশ করে যেখানে AI মডেলে লিঙ্গ পক্ষপাতিত্ব রয়েছে।
RAI ড্যাশবোর্ডের ডেটা বিশ্লেষণ কম্পোনেন্ট ডেটাসেটে অতিরিক্ত এবং কম প্রতিনিধিত্বের এলাকাগুলি চিহ্নিত করতে সাহায্য করে। এটি ব্যবহারকারীদের ডেটা ভারসাম্যহীনতা বা একটি নির্দিষ্ট ডেটা গোষ্ঠীর প্রতিনিধিত্বের অভাব থেকে উদ্ভূত ত্রুটি এবং ন্যায্যতার সমস্যাগুলি নির্ণয় করতে সাহায্য করে। এটি ব্যবহারকারীদের পূর্বাভাস এবং প্রকৃত ফলাফল, ত্রুটি গোষ্ঠী এবং নির্দিষ্ট বৈশিষ্ট্যের উপর ভিত্তি করে ডেটাসেট ভিজ্যুয়ালাইজ করার ক্ষমতা দেয়। কখনও কখনও একটি কম প্রতিনিধিত্বকারী ডেটা গোষ্ঠী আবিষ্কার করা মডেলটি ভালোভাবে শিখছে না তা প্রকাশ করতে পারে, যার ফলে উচ্চ ত্রুটি দেখা দেয়। একটি মডেলে ডেটা পক্ষপাতিত্ব থাকা শুধুমাত্র একটি ন্যায্যতার সমস্যা নয়, এটি দেখায় যে মডেলটি অন্তর্ভুক্তিমূলক বা নির্ভরযোগ্য নয়।

ডেটা বিশ্লেষণ ব্যবহার করুন যখন আপনি:
- আপনার ডেটাসেটের পরিসংখ্যান অন্বেষণ করতে চান, বিভিন্ন ফিল্টার নির্বাচন করে আপনার ডেটাকে বিভিন্ন মাত্রায় (কোহর্ট নামে পরিচিত) ভাগ করতে।
- বিভিন্ন কোহর্ট এবং বৈশিষ্ট্য গোষ্ঠীর মধ্যে আপনার ডেটাসেটের বিতরণ বুঝতে চান।
- ন্যায্যতা, ত্রুটি বিশ্লেষণ এবং কারণ সম্পর্কিত আপনার অনুসন্ধানগুলি (অন্যান্য ড্যাশবোর্ড কম্পোনেন্ট থেকে প্রাপ্ত) আপনার ডেটাসেটের বিতরণের ফলাফল কিনা তা নির্ধারণ করতে চান।
- প্রতিনিধিত্বের সমস্যাগুলি থেকে উদ্ভূত ত্রুটি কমানোর জন্য আরও ডেটা সংগ্রহের এলাকাগুলি সিদ্ধান্ত নিতে চান।
মডেল ব্যাখ্যাযোগ্যতা
মেশিন লার্নিং মডেলগুলো সাধারণত "ব্ল্যাক বক্স" হিসেবে বিবেচিত হয়। একটি মডেলের পূর্বাভাস চালানোর জন্য কোন মূল ডেটা বৈশিষ্ট্যগুলি গুরুত্বপূর্ণ তা বোঝা চ্যালেঞ্জিং হতে পারে। একটি মডেল কেন একটি নির্দিষ্ট পূর্বাভাস করেছে তা বোঝার জন্য স্বচ্ছতা প্রদান করা গুরুত্বপূর্ণ। উদাহরণস্বরূপ, যদি একটি AI সিস্টেম পূর্বাভাস দেয় যে একটি ডায়াবেটিক রোগী ৩০ দিনের মধ্যে হাসপাতালে পুনরায় ভর্তি হওয়ার ঝুঁকিতে রয়েছে, তাহলে এটি তার পূর্বাভাসের জন্য প্রাসঙ্গিক ডেটা প্রদান করতে সক্ষম হওয়া উচিত। এই ধরনের ডেটা সূচক স্বচ্ছতা নিয়ে আসে, যা চিকিৎসক বা হাসপাতালকে ভালোভাবে সিদ্ধান্ত নিতে সাহায্য করে। এছাড়াও, একটি নির্দিষ্ট রোগীর জন্য একটি মডেল কেন পূর্বাভাস দিয়েছে তা ব্যাখ্যা করতে সক্ষম হওয়া স্বাস্থ্য নিয়মাবলীর সঙ্গে দায়িত্বশীলতা নিশ্চিত করে। যখন আপনি মেশিন লার্নিং মডেল ব্যবহার করছেন যা মানুষের জীবনে প্রভাব ফেলে, তখন মডেলের আচরণ কী দ্বারা প্রভাবিত হয় তা বোঝা এবং ব্যাখ্যা করা অত্যন্ত গুরুত্বপূর্ণ। মডেল ব্যাখ্যাযোগ্যতা এবং ব্যাখ্যা করার ক্ষমতা নিম্নলিখিত পরিস্থিতিতে প্রশ্নের উত্তর দিতে সাহায্য করে:
- মডেল ডিবাগিং: আমার মডেল কেন এই ভুল করেছে? আমি কীভাবে আমার মডেল উন্নত করতে পারি?
- মানব-AI সহযোগিতা: আমি কীভাবে মডেলের সিদ্ধান্ত বুঝতে এবং বিশ্বাস করতে পারি?
- নিয়ন্ত্রক সম্মতি: আমার মডেল কি আইনি প্রয়োজনীয়তা পূরণ করে?
RAI ড্যাশবোর্ডের ফিচার ইম্পরট্যান্স কম্পোনেন্ট আপনাকে ডিবাগ করতে এবং একটি মডেল কীভাবে পূর্বাভাস তৈরি করে তা ব্যাপকভাবে বুঝতে সাহায্য করে। এটি মেশিন লার্নিং পেশাদার এবং সিদ্ধান্ত গ্রহণকারীদের জন্য একটি দরকারী টুল, যা মডেলের আচরণ প্রভাবিতকারী বৈশিষ্ট্যগুলির প্রমাণ দেখাতে এবং নিয়ন্ত্রক সম্মতির জন্য ব্যাখ্যা করতে সাহায্য করে। ব্যবহারকারীরা বৈশ্বিক এবং স্থানীয় ব্যাখ্যা উভয়ই অন্বেষণ করতে পারেন, যা মডেলের পূর্বাভাস চালানোর বৈশিষ্ট্যগুলি যাচাই করতে সাহায্য করে। বৈশ্বিক ব্যাখ্যা মডেলের সামগ্রিক পূর্বাভাসকে প্রভাবিত করা শীর্ষ বৈশিষ্ট্যগুলির তালিকা দেয়। স্থানীয় ব্যাখ্যা দেখায় যে একটি নির্দিষ্ট ক্ষেত্রে মডেলের পূর্বাভাসের জন্য কোন বৈশিষ্ট্যগুলি ভূমিকা পালন করেছে। স্থানীয় ব্যাখ্যা মূল্যায়নের ক্ষমতা একটি নির্দিষ্ট ক্ষেত্রে ডিবাগিং বা অডিটিংয়ে সহায়ক, যাতে মডেল কেন সঠিক বা ভুল পূর্বাভাস দিয়েছে তা ভালোভাবে বোঝা এবং ব্যাখ্যা করা যায়।
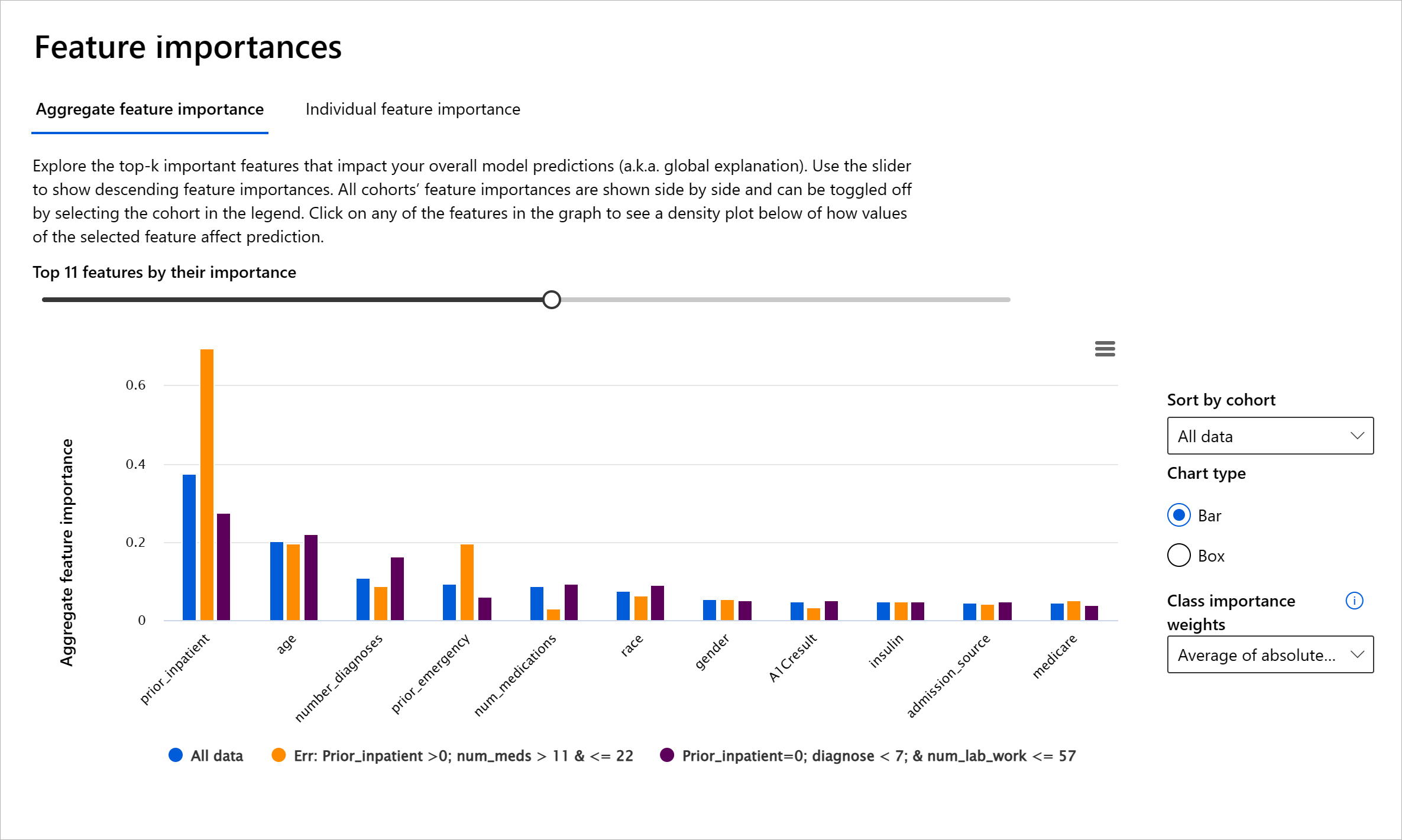
- বৈশ্বিক ব্যাখ্যা: উদাহরণস্বরূপ, ডায়াবেটিস হাসপাতাল পুনরায় ভর্তি মডেলের সামগ্রিক আচরণে কোন বৈশিষ্ট্যগুলি প্রভাব ফেলে?
- স্থানীয় ব্যাখ্যা: উদাহরণস্বরূপ, কেন ৬০ বছরের বেশি বয়সী এবং পূর্ববর্তী হাসপাতালে ভর্তি থাকা একজন ডায়াবেটিক রোগীকে ৩০ দিনের মধ্যে পুনরায় ভর্তি বা পুনরায় ভর্তি না হওয়ার
- অতিরিক্ত বা কম প্রতিনিধিত্ব। ধারণাটি হলো একটি নির্দিষ্ট গোষ্ঠীকে একটি নির্দিষ্ট পেশায় দেখা যায় না, এবং যে কোনো সেবা বা কার্যক্রম যা এটি প্রচার করে তা ক্ষতির কারণ হতে পারে।
Azure RAI ড্যাশবোর্ড
Azure RAI ড্যাশবোর্ড ওপেন-সোর্স টুলের উপর ভিত্তি করে তৈরি, যা শীর্ষস্থানীয় একাডেমিক প্রতিষ্ঠান এবং সংস্থাগুলি, Microsoft সহ, ডেটা বিজ্ঞানী এবং AI ডেভেলপারদের মডেলের আচরণ আরও ভালোভাবে বুঝতে, AI মডেল থেকে অপ্রত্যাশিত সমস্যাগুলি আবিষ্কার এবং সমাধান করতে সহায়ক।
-
RAI ড্যাশবোর্ডের বিভিন্ন উপাদান কীভাবে ব্যবহার করবেন তা শিখতে ডকুমেন্টেশন দেখুন।
-
Azure Machine Learning-এ আরও দায়িত্বশীল AI পরিস্থিতি ডিবাগ করার জন্য কিছু RAI ড্যাশবোর্ডের নমুনা নোটবুক দেখুন।
🚀 চ্যালেঞ্জ
পরিসংখ্যানগত বা ডেটা পক্ষপাত এড়ানোর জন্য আমাদের উচিত:
- সিস্টেমে কাজ করা ব্যক্তিদের মধ্যে বিভিন্ন পটভূমি এবং দৃষ্টিভঙ্গি থাকা
- এমন ডেটাসেটে বিনিয়োগ করা যা আমাদের সমাজের বৈচিত্র্যকে প্রতিফলিত করে
- পক্ষপাত সনাক্ত এবং সংশোধন করার জন্য আরও ভালো পদ্ধতি তৈরি করা
বাস্তব জীবনের পরিস্থিতি নিয়ে চিন্তা করুন যেখানে মডেল তৈরিতে এবং ব্যবহারে অন্যায় স্পষ্ট। আর কী বিবেচনা করা উচিত?
পোস্ট-লেকচার কুইজ
পর্যালোচনা ও স্ব-অধ্যয়ন
এই পাঠে, আপনি মেশিন লার্নিংয়ে দায়িত্বশীল AI অন্তর্ভুক্ত করার কিছু ব্যবহারিক টুল শিখেছেন।
এই কর্মশালাটি দেখুন বিষয়গুলো আরও গভীরভাবে বুঝতে:
- দায়িত্বশীল AI ড্যাশবোর্ড: বাস্তবে RAI পরিচালনার জন্য একক প্ল্যাটফর্ম, Besmira Nushi এবং Mehrnoosh Sameki দ্বারা

🎥 উপরের ছবিতে ক্লিক করুন ভিডিওর জন্য: দায়িত্বশীল AI ড্যাশবোর্ড: বাস্তবে RAI পরিচালনার জন্য একক প্ল্যাটফর্ম, Besmira Nushi এবং Mehrnoosh Sameki দ্বারা
দায়িত্বশীল AI এবং আরও বিশ্বাসযোগ্য মডেল তৈরি করার বিষয়ে আরও জানতে নিম্নলিখিত উপকরণগুলি দেখুন:
-
ML মডেল ডিবাগ করার জন্য Microsoft-এর RAI ড্যাশবোর্ড টুল: দায়িত্বশীল AI টুল রিসোর্স
-
দায়িত্বশীল AI টুলকিট অন্বেষণ করুন: Github
-
Microsoft-এর RAI রিসোর্স সেন্টার: দায়িত্বশীল AI রিসোর্স – Microsoft AI
-
Microsoft-এর FATE গবেষণা দল: FATE: AI-তে ন্যায্যতা, জবাবদিহিতা, স্বচ্ছতা এবং নৈতিকতা - Microsoft Research
অ্যাসাইনমেন্ট
অস্বীকৃতি:
এই নথিটি AI অনুবাদ পরিষেবা Co-op Translator ব্যবহার করে অনুবাদ করা হয়েছে। আমরা যথাসম্ভব সঠিকতার জন্য চেষ্টা করি, তবে অনুগ্রহ করে মনে রাখবেন যে স্বয়ংক্রিয় অনুবাদে ত্রুটি বা অসঙ্গতি থাকতে পারে। মূল ভাষায় থাকা নথিটিকে প্রামাণিক উৎস হিসেবে বিবেচনা করা উচিত। গুরুত্বপূর্ণ তথ্যের জন্য, পেশাদার মানব অনুবাদ সুপারিশ করা হয়। এই অনুবাদ ব্যবহারের ফলে কোনো ভুল বোঝাবুঝি বা ভুল ব্যাখ্যা হলে আমরা দায়বদ্ধ থাকব না।