25 KiB
Започнете с Python и Scikit-learn за регресионни модели

Скица от Tomomi Imura
Тест преди лекцията
Този урок е наличен и на R!
Въведение
В тези четири урока ще научите как да изграждате регресионни модели. Ще обсъдим за какво служат те след малко. Но преди да започнете, уверете се, че разполагате с правилните инструменти, за да стартирате процеса!
В този урок ще научите как да:
- Конфигурирате компютъра си за локални задачи по машинно обучение.
- Работите с Jupyter notebooks.
- Използвате Scikit-learn, включително инсталация.
- Изследвате линейна регресия чрез практическо упражнение.
Инсталации и конфигурации

🎥 Кликнете върху изображението по-горе за кратко видео за конфигуриране на компютъра за машинно обучение.
-
Инсталирайте Python. Уверете се, че Python е инсталиран на вашия компютър. Ще използвате Python за много задачи, свързани с данни и машинно обучение. Повечето компютърни системи вече включват инсталация на Python. Съществуват и полезни Python Coding Packs, които улесняват настройката за някои потребители.
Някои приложения на Python обаче изискват една версия на софтуера, докато други изискват различна версия. Поради тази причина е полезно да работите в виртуална среда.
-
Инсталирайте Visual Studio Code. Уверете се, че Visual Studio Code е инсталиран на вашия компютър. Следвайте тези инструкции за инсталиране на Visual Studio Code за основната инсталация. Ще използвате Python във Visual Studio Code в този курс, така че може да е полезно да се запознаете с конфигурирането на Visual Studio Code за разработка с Python.
Запознайте се с Python, като преминете през тази колекция от модули за обучение

🎥 Кликнете върху изображението по-горе за видео: използване на Python във VS Code.
-
Инсталирайте Scikit-learn, като следвате тези инструкции. Тъй като трябва да използвате Python 3, препоръчително е да използвате виртуална среда. Обърнете внимание, че ако инсталирате тази библиотека на Mac с M1, има специални инструкции на страницата, посочена по-горе.
-
Инсталирайте Jupyter Notebook. Ще трябва да инсталирате пакета Jupyter.
Вашата среда за авторство на машинно обучение
Ще използвате notebooks, за да разработвате своя Python код и да създавате модели за машинно обучение. Този тип файлове е често срещан инструмент за специалисти по данни и може да бъде разпознат по разширението .ipynb.
Notebooks са интерактивна среда, която позволява на разработчика както да кодира, така и да добавя бележки и документация около кода, което е доста полезно за експериментални или изследователски проекти.

🎥 Кликнете върху изображението по-горе за кратко видео за това упражнение.
Упражнение - работа с notebook
В тази папка ще намерите файла notebook.ipynb.
-
Отворете notebook.ipynb във Visual Studio Code.
Ще стартира Jupyter сървър с Python 3+. Ще намерите области в notebook-а, които могат да бъдат
изпълнени, т.е. части от код. Можете да изпълните блок с код, като изберете иконата, която изглежда като бутон за възпроизвеждане. -
Изберете иконата
mdи добавете малко markdown с текста # Добре дошли в своя notebook.След това добавете малко Python код.
-
Въведете print('hello notebook') в блока с код.
-
Изберете стрелката, за да изпълните кода.
Трябва да видите отпечатаното съобщение:
hello notebook

Можете да преплитате кода си с коментари, за да документирате сами notebook-а.
✅ Помислете за момент колко различна е работната среда на уеб разработчика в сравнение с тази на специалиста по данни.
Стартиране със Scikit-learn
Сега, когато Python е настроен във вашата локална среда и сте се запознали с Jupyter notebooks, нека се запознаем и със Scikit-learn (произнася се сай, както в наука). Scikit-learn предоставя обширен API, който ще ви помогне да изпълнявате задачи по машинно обучение.
Според техния уебсайт, "Scikit-learn е библиотека с отворен код за машинно обучение, която поддържа контролирано и неконтролирано обучение. Тя също така предоставя различни инструменти за напасване на модели, предварителна обработка на данни, избор и оценка на модели, както и много други полезности."
В този курс ще използвате Scikit-learn и други инструменти, за да изграждате модели за машинно обучение за изпълнение на това, което наричаме 'традиционни задачи по машинно обучение'. Умишлено сме избегнали невронни мрежи и дълбоко обучение, тъй като те са по-добре обхванати в предстоящата ни учебна програма 'AI за начинаещи'.
Scikit-learn прави изграждането и оценяването на модели лесно за използване. Тя е основно фокусирана върху използването на числови данни и съдържа няколко готови набора от данни за използване като учебни инструменти. Тя също така включва предварително изградени модели, които студентите могат да изпробват. Нека изследваме процеса на зареждане на предварително пакетирани данни и използване на вграден оценител за първия ML модел със Scikit-learn с някои основни данни.
Упражнение - вашият първи Scikit-learn notebook
Това ръководство е вдъхновено от примера за линейна регресия на уебсайта на Scikit-learn.

🎥 Кликнете върху изображението по-горе за кратко видео за това упражнение.
Във файла notebook.ipynb, свързан с този урок, изчистете всички клетки, като натиснете иконата 'кошче'.
В този раздел ще работите с малък набор от данни за диабет, който е вграден в Scikit-learn за учебни цели. Представете си, че искате да тествате лечение за пациенти с диабет. Моделите за машинно обучение могат да ви помогнат да определите кои пациенти биха реагирали по-добре на лечението въз основа на комбинации от променливи. Дори много основен регресионен модел, когато е визуализиран, може да покаже информация за променливи, които биха ви помогнали да организирате теоретичните си клинични изпитвания.
✅ Съществуват много видове методи за регресия, и кой ще изберете зависи от въпроса, на който искате да отговорите. Ако искате да предскажете вероятната височина на човек на дадена възраст, ще използвате линейна регресия, тъй като търсите числова стойност. Ако се интересувате дали даден вид кухня трябва да се счита за веганска или не, търсите категорийно присвояване, така че ще използвате логистична регресия. Ще научите повече за логистичната регресия по-късно. Помислете малко за въпроси, които можете да зададете на данните, и кой от тези методи би бил по-подходящ.
Нека започнем с тази задача.
Импортиране на библиотеки
За тази задача ще импортираме някои библиотеки:
- matplotlib. Това е полезен инструмент за графики, който ще използваме за създаване на линейна графика.
- numpy. numpy е полезна библиотека за работа с числови данни в Python.
- sklearn. Това е библиотеката Scikit-learn.
Импортирайте някои библиотеки, за да ви помогнат със задачите.
-
Добавете импорти, като въведете следния код:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionПо-горе импортирате
matplotlib,numpyи импортиратеdatasets,linear_modelиmodel_selectionотsklearn.model_selectionсе използва за разделяне на данни на тренировъчни и тестови набори.
Наборът от данни за диабет
Вграденият набор от данни за диабет включва 442 проби от данни за диабет с 10 характеристични променливи, някои от които включват:
- age: възраст в години
- bmi: индекс на телесна маса
- bp: средно кръвно налягане
- s1 tc: Т-клетки (вид бели кръвни клетки)
✅ Този набор от данни включва концепцията за 'пол' като характеристична променлива, важна за изследванията около диабета. Много медицински набори от данни включват този тип бинарна класификация. Помислете малко как подобни категоризации могат да изключат определени части от населението от лечения.
Сега заредете данните X и y.
🎓 Запомнете, това е контролирано обучение и ни трябва целева променлива 'y'.
В нова клетка с код заредете набора от данни за диабет, като извикате load_diabetes(). Входът return_X_y=True сигнализира, че X ще бъде матрица с данни, а y ще бъде целта на регресията.
-
Добавете някои команди за печат, за да покажете формата на матрицата с данни и първия ѝ елемент:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Това, което получавате като отговор, е кортеж. Това, което правите, е да присвоите първите две стойности на кортежа съответно на
Xиy. Научете повече за кортежите.Можете да видите, че тези данни имат 442 елемента, оформени в масиви от 10 елемента:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Помислете малко за връзката между данните и целевата променлива. Линейната регресия предсказва връзките между характеристиката X и целевата променлива y. Можете ли да намерите целта за набора от данни за диабет в документацията? Какво демонстрира този набор от данни, като се има предвид целта?
-
След това изберете част от този набор от данни за графика, като изберете третата колона от набора от данни. Можете да направите това, като използвате оператора
:за избор на всички редове и след това изберете третата колона, използвайки индекса (2). Можете също така да преформатирате данните в 2D масив - както се изисква за графиката - като използватеreshape(n_rows, n_columns). Ако един от параметрите е -1, съответното измерение се изчислява автоматично.X = X[:, 2] X = X.reshape((-1,1))✅ По всяко време отпечатвайте данните, за да проверите формата им.
-
Сега, когато имате данни, готови за графика, можете да видите дали машината може да помогне за определяне на логическо разделение между числата в този набор от данни. За да направите това, трябва да разделите както данните (X), така и целта (y) на тестови и тренировъчни набори. Scikit-learn има лесен начин за това; можете да разделите тестовите си данни в дадена точка.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Сега сте готови да обучите модела си! Заредете модела за линейна регресия и го обучете с тренировъчните си набори X и y, използвайки
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()е функция, която ще виждате в много библиотеки за машинно обучение, като TensorFlow. -
След това създайте предсказание, използвайки тестовите данни, с помощта на функцията
predict(). Това ще се използва за начертаване на линия между групите данни.y_pred = model.predict(X_test) -
Сега е време да покажете данните в графика. Matplotlib е много полезен инструмент за тази задача. Създайте разпръсната графика на всички тестови данни X и y и използвайте предсказанието, за да начертаете линия на най-подходящото място между групите данни на модела.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()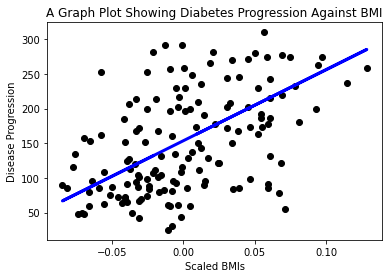 ✅ Помислете малко какво се случва тук. Една права линия минава през множество малки точки от данни, но какво точно прави тя? Можете ли да видите как бихте могли да използвате тази линия, за да предскажете къде нова, невиждана точка от данни би трябвало да се намира спрямо y оста на графиката? Опитайте се да обясните с думи практическата употреба на този модел.
✅ Помислете малко какво се случва тук. Една права линия минава през множество малки точки от данни, но какво точно прави тя? Можете ли да видите как бихте могли да използвате тази линия, за да предскажете къде нова, невиждана точка от данни би трябвало да се намира спрямо y оста на графиката? Опитайте се да обясните с думи практическата употреба на този модел.
Поздравления, създадохте първия си модел за линейна регресия, направихте предсказание с него и го визуализирахте в графика!
🚀Предизвикателство
Начертайте графика с различна променлива от този набор от данни. Подсказка: редактирайте този ред: X = X[:,2]. С оглед на целта на този набор от данни, какво можете да откриете за прогресията на диабета като заболяване?
Тест след лекцията
Преглед и самостоятелно обучение
В този урок работихте с проста линейна регресия, а не с унивариантна или множествена линейна регресия. Прочетете малко за разликите между тези методи или разгледайте това видео.
Прочетете повече за концепцията на регресията и помислете какви въпроси могат да бъдат отговорени с тази техника. Вземете този урок, за да задълбочите разбирането си.
Задача
Отказ от отговорност:
Този документ е преведен с помощта на AI услуга за превод Co-op Translator. Въпреки че се стремим към точност, моля, имайте предвид, че автоматизираните преводи може да съдържат грешки или неточности. Оригиналният документ на неговия роден език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален човешки превод. Ние не носим отговорност за недоразумения или погрешни интерпретации, произтичащи от използването на този превод.