21 KiB
История на машинното обучение
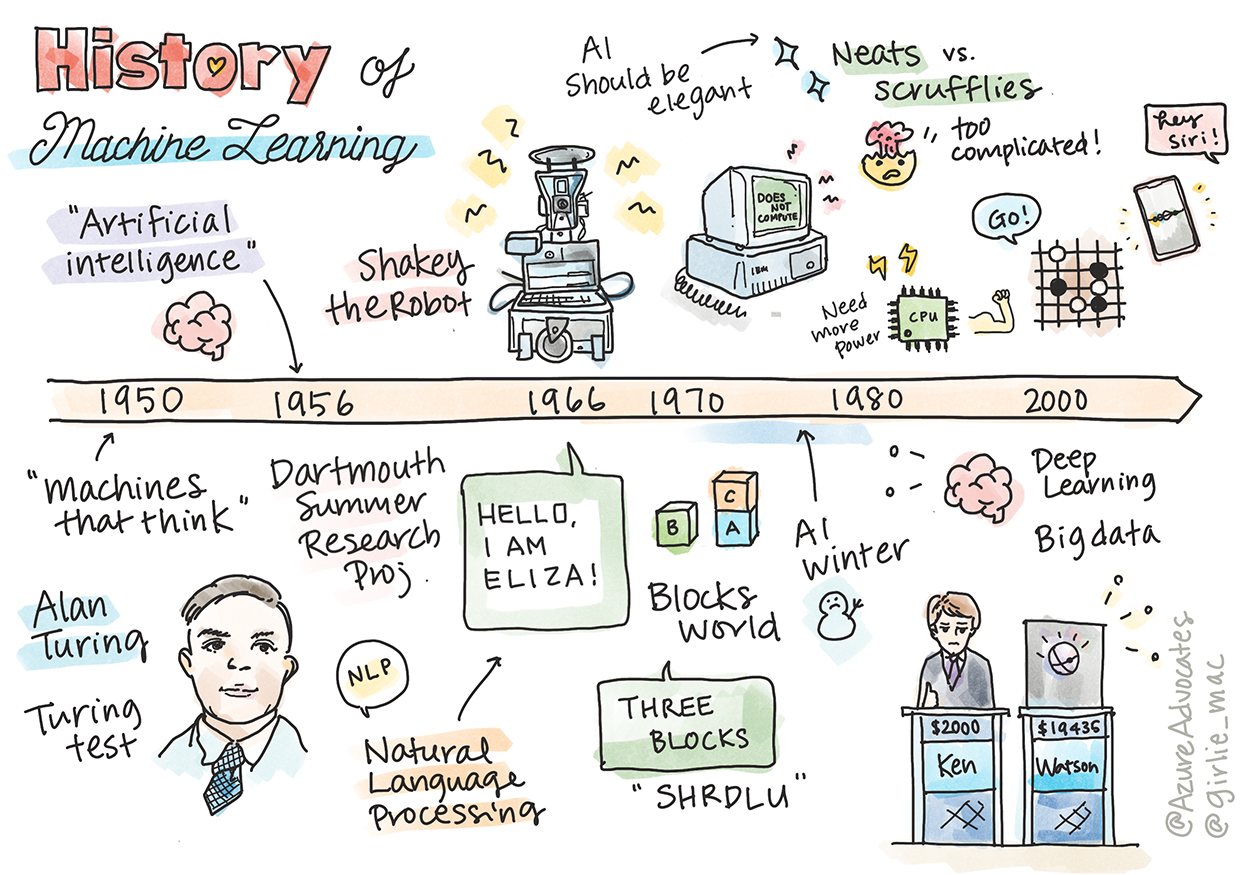
Скица от Tomomi Imura
Тест преди лекцията

🎥 Кликнете върху изображението по-горе за кратко видео, което разглежда тази лекция.
В тази лекция ще преминем през основните етапи в историята на машинното обучение и изкуствения интелект.
Историята на изкуствения интелект (AI) като област е тясно свързана с историята на машинното обучение, тъй като алгоритмите и компютърните постижения, които стоят в основата на ML, допринасят за развитието на AI. Полезно е да се помни, че макар тези области като отделни направления да започват да се оформят през 50-те години на миналия век, важни алгоритмични, статистически, математически, компютърни и технически открития предхождат и се припокриват с този период. Всъщност хората размишляват върху тези въпроси стотици години: тази статия разглежда историческите интелектуални основи на идеята за „мислеща машина“.
Значими открития
- 1763, 1812 Теорема на Байес и нейните предшественици. Тази теорема и нейните приложения са в основата на правенето на изводи, описвайки вероятността за настъпване на събитие въз основа на предварителни знания.
- 1805 Теория на най-малките квадрати от френския математик Адриен-Мари Лежандър. Тази теория, която ще изучавате в нашия модул за регресия, помага при напасването на данни.
- 1913 Марковски вериги, кръстени на руския математик Андрей Марков, се използват за описание на последователност от възможни събития въз основа на предишно състояние.
- 1957 Перцептрон е вид линеен класификатор, изобретен от американския психолог Франк Розенблат, който стои в основата на напредъка в дълбокото обучение.
- 1967 Най-близък съсед е алгоритъм, първоначално създаден за картографиране на маршрути. В контекста на ML се използва за откриване на модели.
- 1970 Обратна пропагация се използва за обучение на невронни мрежи с директно предаване.
- 1982 Рекурентни невронни мрежи са изкуствени невронни мрежи, произлезли от невронни мрежи с директно предаване, които създават времеви графики.
✅ Направете малко проучване. Кои други дати се открояват като ключови в историята на ML и AI?
1950: Машини, които мислят
Алън Тюринг, наистина забележителна личност, който беше избран от обществеността през 2019 г. за най-великия учен на 20-ти век, е признат за това, че е помогнал да се положат основите на концепцията за „машина, която може да мисли“. Той се сблъсква с критиците и собствената си нужда от емпирични доказателства за тази концепция, като създава Тюринг теста, който ще разгледате в нашите уроци за обработка на естествен език.
1956: Лятна изследователска програма в Дартмут
„Лятната изследователска програма в Дартмут за изкуствен интелект беше ключово събитие за изкуствения интелект като област“, и именно тук беше въведен терминът „изкуствен интелект“ (източник).
Всеки аспект на ученето или всяка друга характеристика на интелигентността може по принцип да бъде толкова точно описан, че да може да бъде симулиран от машина.
Водещият изследовател, професорът по математика Джон Маккарти, се надява „да продължи въз основа на предположението, че всеки аспект на ученето или всяка друга характеристика на интелигентността може по принцип да бъде толкова точно описан, че да може да бъде симулиран от машина“. Участниците включват още една изтъкната фигура в областта, Марвин Мински.
Уъркшопът е признат за това, че е инициирал и насърчил няколко дискусии, включително „възхода на символичните методи, системи, фокусирани върху ограничени области (ранни експертни системи) и дедуктивни системи срещу индуктивни системи.“ (източник).
1956 - 1974: „Златните години“
От 50-те години до средата на 70-те години оптимизмът беше висок с надеждата, че AI може да реши много проблеми. През 1967 г. Марвин Мински уверено заявява: „В рамките на едно поколение... проблемът със създаването на „изкуствен интелект“ ще бъде съществено решен.“ (Мински, Марвин (1967), Изчисление: Крайни и безкрайни машини, Енгълуд Клифс, Ню Джърси: Прентис-Хол)
Изследванията в обработката на естествен език процъфтяват, търсенето се усъвършенства и става по-мощно, а концепцията за „микро-светове“ е създадена, където прости задачи се изпълняват с помощта на инструкции на обикновен език.
Изследванията са добре финансирани от правителствени агенции, постигнат е напредък в изчисленията и алгоритмите, и са създадени прототипи на интелигентни машини. Някои от тези машини включват:
-
Шейки роботът, който може да се движи и да решава как да изпълнява задачи „интелигентно“.

Шейки през 1972 г.
-
Елиза, ранен „чатбот“, може да разговаря с хора и да действа като примитивен „терапевт“. Ще научите повече за Елиза в уроците за обработка на естествен език.
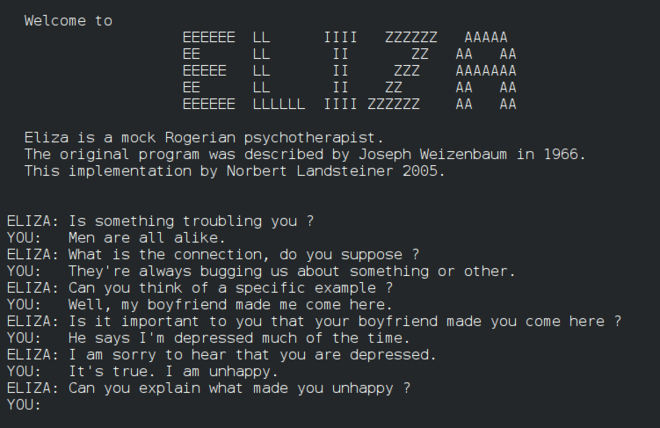
Версия на Елиза, чатбот
-
„Светът на блоковете“ беше пример за микро-свят, където блоковете можеха да се подреждат и сортират, а експерименти за обучение на машини да вземат решения можеха да се тестват. Напредъкът, постигнат с библиотеки като SHRDLU, помогна за развитието на обработката на езика.

🎥 Кликнете върху изображението по-горе за видео: Светът на блоковете с SHRDLU
1974 - 1980: „Зимата на AI“
До средата на 70-те години става ясно, че сложността на създаването на „интелигентни машини“ е била подценена и че обещанията, дадени предвид наличната изчислителна мощност, са били преувеличени. Финансирането пресъхва и доверието в областта намалява. Някои проблеми, които влияят на доверието, включват:
- Ограничения. Изчислителната мощност е твърде ограничена.
- Комбинаторен взрив. Броят на параметрите, които трябва да бъдат обучени, нараства експоненциално, докато се изисква повече от компютрите, без паралелна еволюция на изчислителната мощност и способности.
- Недостиг на данни. Имаше недостиг на данни, който възпрепятства процеса на тестване, разработване и усъвършенстване на алгоритмите.
- Задаваме ли правилните въпроси?. Самите въпроси, които се задаваха, започнаха да се поставят под въпрос. Изследователите започнаха да се сблъскват с критика относно своите подходи:
- Тюринг тестовете бяха поставени под въпрос чрез, наред с други идеи, „теорията за китайската стая“, която твърди, че „програмирането на цифров компютър може да го накара да изглежда, че разбира езика, но не може да произведе истинско разбиране.“ (източник)
- Етиката на въвеждането на изкуствени интелекти като „терапевта“ Елиза в обществото беше оспорена.
В същото време започват да се формират различни школи на мисълта за AI. Установява се дихотомия между практиките на "разхвърлян" срещу "подреден AI". Разхвърляните лаборатории настройват програми с часове, докато постигнат желаните резултати. Подредените лаборатории „се фокусират върху логиката и формалното решаване на проблеми“. Елиза и SHRDLU са добре известни разхвърляни системи. През 80-те години, когато се появява търсенето за създаване на възпроизводими ML системи, подреденият подход постепенно заема преден план, тъй като резултатите му са по-обясними.
1980-те: Експертни системи
С развитието на областта нейната полза за бизнеса става по-ясна, а през 80-те години се наблюдава и разпространението на „експертни системи“. „Експертните системи бяха сред първите наистина успешни форми на софтуер за изкуствен интелект (AI).“ (източник).
Този тип система всъщност е хибридна, състояща се частично от двигател на правила, който определя бизнес изискванията, и двигател за правене на изводи, който използва системата от правила, за да извежда нови факти.
Тази епоха също така вижда нарастващо внимание към невронните мрежи.
1987 - 1993: „Охлаждане“ на AI
Разпространението на специализирания хардуер за експертни системи има нещастния ефект да стане твърде специализирано. Възходът на персоналните компютри също конкурира тези големи, специализирани, централизирани системи. Демократизацията на изчисленията започва и в крайна сметка проправя пътя за съвременния взрив на големите данни.
1993 - 2011
Този период бележи нова ера за ML и AI, които могат да решат някои от проблемите, причинени по-рано от липсата на данни и изчислителна мощност. Количеството данни започва бързо да се увеличава и става по-достъпно, за добро и за лошо, особено с появата на смартфона около 2007 г. Изчислителната мощност се разширява експоненциално, а алгоритмите се развиват паралелно. Областта започва да придобива зрялост, тъй като свободните дни от миналото започват да се кристализират в истинска дисциплина.
Сега
Днес машинното обучение и AI докосват почти всяка част от нашия живот. Тази епоха изисква внимателно разбиране на рисковете и потенциалните ефекти на тези алгоритми върху човешкия живот. Както заявява Брад Смит от Microsoft: „Информационните технологии поставят въпроси, които засягат основните защити на човешките права като поверителност и свобода на изразяване. Тези въпроси увеличават отговорността на технологичните компании, които създават тези продукти. Според нас те също така изискват внимателно правителствено регулиране и разработване на норми за приемливи употреби“ (източник).
Остава да се види какво ще донесе бъдещето, но е важно да се разберат тези компютърни системи и софтуерът и алгоритмите, които те изпълняват. Надяваме се, че тази учебна програма ще ви помогне да придобиете по-добро разбиране, за да можете сами да решите.

🎥 Кликнете върху изображението по-горе за видео: Ян Лекун обсъжда историята на дълбокото обучение в тази лекция
🚀Предизвикателство
Разгледайте един от тези исторически моменти и научете повече за хората зад тях. Има завладяващи личности, и никое научно откритие никога не е създадено в културен вакуум. Какво откривате?
Тест след лекцията
Преглед и самостоятелно обучение
Ето елементи за гледане и слушане:
Този подкаст, в който Ейми Бойд обсъжда еволюцията на AI

Задание
Отказ от отговорност:
Този документ е преведен с помощта на AI услуга за превод Co-op Translator. Въпреки че се стремим към точност, моля, имайте предвид, че автоматизираните преводи може да съдържат грешки или неточности. Оригиналният документ на неговия роден език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален човешки превод. Ние не носим отговорност за каквито и да е недоразумения или погрешни интерпретации, произтичащи от използването на този превод.