28 KiB
ملحق: تصحيح النماذج في تعلم الآلة باستخدام مكونات لوحة القيادة للذكاء الاصطناعي المسؤول
اختبار ما قبل المحاضرة
المقدمة
يؤثر تعلم الآلة على حياتنا اليومية. الذكاء الاصطناعي يشق طريقه إلى بعض الأنظمة الأكثر أهمية التي تؤثر علينا كأفراد وعلى مجتمعنا، مثل الرعاية الصحية، والتمويل، والتعليم، والتوظيف. على سبيل المثال، يتم استخدام الأنظمة والنماذج في مهام اتخاذ القرارات اليومية، مثل تشخيصات الرعاية الصحية أو اكتشاف الاحتيال. نتيجة لذلك، يتم مواجهة التقدم في الذكاء الاصطناعي مع توقعات اجتماعية متطورة وتنظيم متزايد استجابة لذلك. نرى باستمرار مجالات حيث تستمر أنظمة الذكاء الاصطناعي في خيبة الآمال؛ حيث تكشف عن تحديات جديدة؛ وتبدأ الحكومات في تنظيم حلول الذكاء الاصطناعي. لذلك، من المهم تحليل هذه النماذج لضمان تقديم نتائج عادلة، موثوقة، شاملة، شفافة، ومسؤولة للجميع.
في هذا المنهج، سنستعرض أدوات عملية يمكن استخدامها لتقييم ما إذا كان النموذج يواجه مشكلات تتعلق بالذكاء الاصطناعي المسؤول. تقنيات تصحيح تعلم الآلة التقليدية تعتمد عادةً على حسابات كمية مثل دقة التجميع أو متوسط خسارة الخطأ. تخيل ما يمكن أن يحدث عندما تفتقر البيانات التي تستخدمها لبناء هذه النماذج إلى بعض الفئات الديموغرافية، مثل العرق، الجنس، الرؤية السياسية، الدين، أو تمثل هذه الفئات بشكل غير متناسب. ماذا عن عندما يتم تفسير نتائج النموذج لتفضيل فئة ديموغرافية معينة؟ هذا يمكن أن يؤدي إلى تمثيل زائد أو ناقص لهذه المجموعات الحساسة، مما يسبب مشكلات تتعلق بالعدالة، الشمولية، أو الموثوقية في النموذج. عامل آخر هو أن نماذج تعلم الآلة تعتبر صناديق سوداء، مما يجعل من الصعب فهم وتفسير ما يدفع توقعات النموذج. كل هذه تحديات يواجهها علماء البيانات ومطورو الذكاء الاصطناعي عندما لا تتوفر لديهم أدوات كافية لتصحيح وتقييم عدالة أو موثوقية النموذج.
في هذه الدرس، ستتعلم كيفية تصحيح نماذجك باستخدام:
- تحليل الأخطاء: تحديد المناطق في توزيع البيانات حيث يكون معدل الأخطاء في النموذج مرتفعًا.
- نظرة عامة على النموذج: إجراء تحليل مقارن عبر مجموعات بيانات مختلفة لاكتشاف التفاوتات في مقاييس أداء النموذج.
- تحليل البيانات: التحقيق في المناطق التي قد يكون فيها تمثيل زائد أو ناقص للبيانات مما قد يؤدي إلى انحياز النموذج لتفضيل فئة ديموغرافية على أخرى.
- أهمية الميزات: فهم الميزات التي تؤثر على توقعات النموذج على المستوى العالمي أو المحلي.
المتطلبات الأساسية
كشرط أساسي، يرجى مراجعة أدوات الذكاء الاصطناعي المسؤول للمطورين

تحليل الأخطاء
مقاييس أداء النموذج التقليدية المستخدمة لقياس الدقة تعتمد غالبًا على حسابات صحيحة مقابل توقعات غير صحيحة. على سبيل المثال، تحديد أن النموذج دقيق بنسبة 89% مع خسارة خطأ قدرها 0.001 يمكن اعتباره أداءً جيدًا. لكن الأخطاء غالبًا لا يتم توزيعها بشكل متساوٍ في مجموعة البيانات الأساسية. قد تحصل على درجة دقة نموذج تبلغ 89% ولكن تكتشف أن هناك مناطق مختلفة من بياناتك حيث يفشل النموذج بنسبة 42% من الوقت. عواقب هذه الأنماط الفاشلة مع مجموعات بيانات معينة يمكن أن تؤدي إلى مشكلات تتعلق بالعدالة أو الموثوقية. من الضروري فهم المناطق التي يعمل فيها النموذج بشكل جيد أو لا يعمل. المناطق في البيانات التي تحتوي على عدد كبير من الأخطاء في النموذج قد تكون مجموعة بيانات ديموغرافية مهمة.

يوضح مكون تحليل الأخطاء في لوحة القيادة للذكاء الاصطناعي المسؤول كيفية توزيع فشل النموذج عبر مجموعات مختلفة باستخدام تصور شجري. هذا مفيد في تحديد الميزات أو المناطق التي تحتوي على معدل خطأ مرتفع في مجموعة البيانات الخاصة بك. من خلال رؤية مصدر معظم الأخطاء في النموذج، يمكنك البدء في التحقيق في السبب الجذري. يمكنك أيضًا إنشاء مجموعات بيانات لإجراء التحليل عليها. تساعد هذه المجموعات في عملية التصحيح لتحديد سبب أداء النموذج الجيد في مجموعة معينة ولكنه يحتوي على أخطاء في مجموعة أخرى.

المؤشرات البصرية على خريطة الشجرة تساعد في تحديد المناطق المشكلة بسرعة. على سبيل المثال، كلما كان لون العقدة الشجرية أغمق باللون الأحمر، كان معدل الخطأ أعلى.
خريطة الحرارة هي وظيفة تصور أخرى يمكن للمستخدمين استخدامها للتحقيق في معدل الخطأ باستخدام ميزة واحدة أو اثنتين للعثور على مساهم في أخطاء النموذج عبر مجموعة البيانات بأكملها أو المجموعات.

استخدم تحليل الأخطاء عندما تحتاج إلى:
- فهم عميق لكيفية توزيع فشل النموذج عبر مجموعة البيانات وعبر عدة أبعاد للمدخلات والميزات.
- تقسيم مقاييس الأداء الإجمالية لاكتشاف مجموعات البيانات الخاطئة تلقائيًا لإبلاغ خطوات التخفيف المستهدفة.
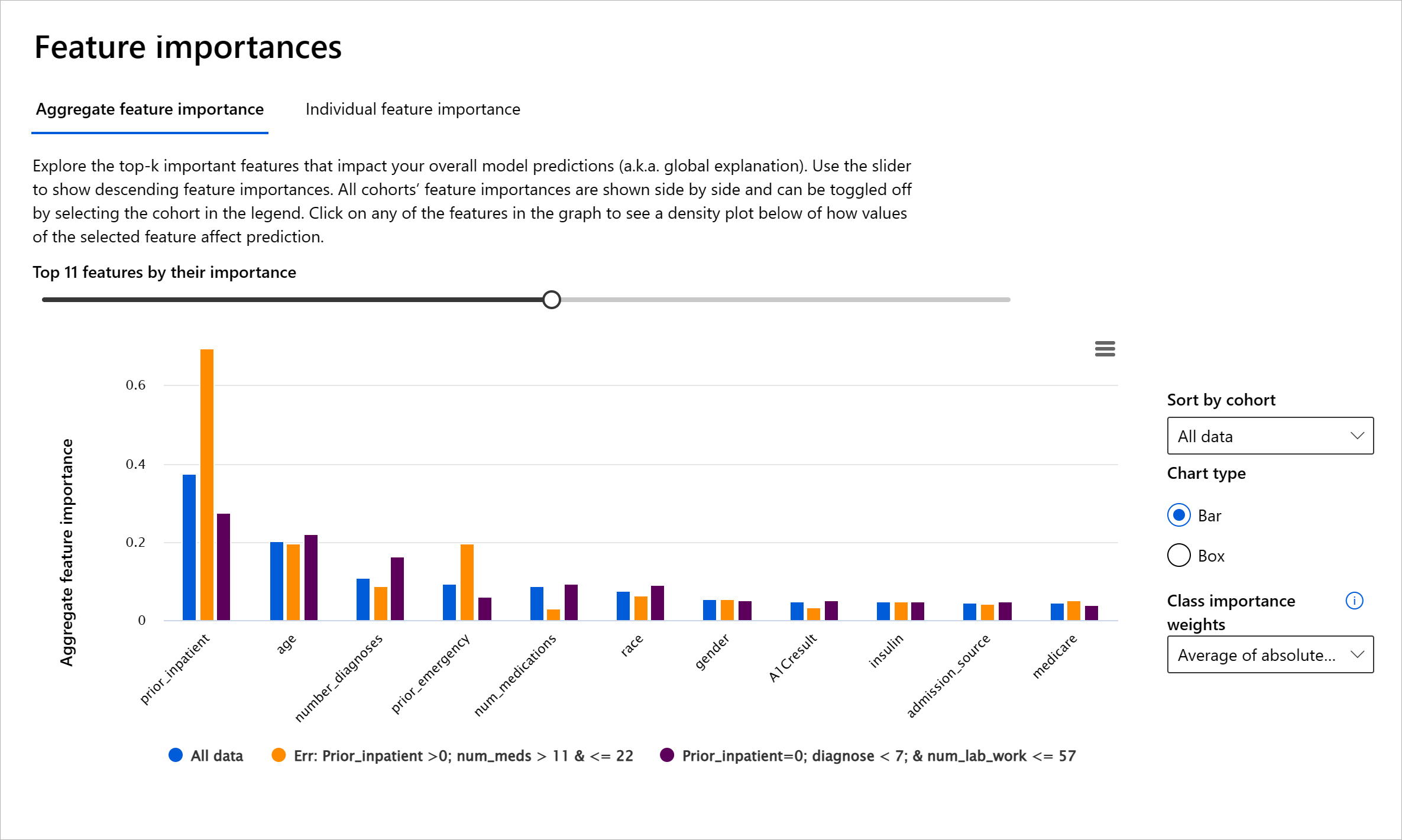
نظرة عامة على النموذج
تقييم أداء نموذج تعلم الآلة يتطلب فهمًا شاملاً لسلوكه. يمكن تحقيق ذلك من خلال مراجعة أكثر من مقياس واحد مثل معدل الخطأ، الدقة، الاستدعاء، الدقة، أو متوسط الخطأ المطلق (MAE) للكشف عن التفاوتات بين مقاييس الأداء. قد يبدو أحد مقاييس الأداء رائعًا، ولكن يمكن أن تظهر الأخطاء في مقياس آخر. بالإضافة إلى ذلك، مقارنة المقاييس للكشف عن التفاوتات عبر مجموعة البيانات بأكملها أو المجموعات يساعد في تسليط الضوء على المناطق التي يعمل فيها النموذج بشكل جيد أو لا يعمل. هذا مهم بشكل خاص لرؤية أداء النموذج بين الميزات الحساسة مقابل غير الحساسة (مثل عرق المريض، الجنس، أو العمر) للكشف عن احتمالية وجود عدم عدالة في النموذج. على سبيل المثال، اكتشاف أن النموذج أكثر خطأً في مجموعة تحتوي على ميزات حساسة يمكن أن يكشف عن احتمالية وجود عدم عدالة في النموذج.
يساعد مكون نظرة عامة على النموذج في لوحة القيادة للذكاء الاصطناعي المسؤول ليس فقط في تحليل مقاييس الأداء لتمثيل البيانات في مجموعة، ولكنه يمنح المستخدمين القدرة على مقارنة سلوك النموذج عبر مجموعات مختلفة.

وظيفة التحليل القائمة على الميزات للمكون تسمح للمستخدمين بتضييق مجموعات البيانات الفرعية داخل ميزة معينة لتحديد الشذوذ على مستوى دقيق. على سبيل المثال، تحتوي لوحة القيادة على ذكاء مدمج لتوليد مجموعات تلقائيًا لميزة يختارها المستخدم (مثل "time_in_hospital < 3" أو "time_in_hospital >= 7"). هذا يمكّن المستخدم من عزل ميزة معينة من مجموعة بيانات أكبر لرؤية ما إذا كانت مؤثرًا رئيسيًا في نتائج النموذج الخاطئة.

يدعم مكون نظرة عامة على النموذج نوعين من مقاييس التفاوت:
التفاوت في أداء النموذج: تحسب هذه المجموعة من المقاييس التفاوت (الفرق) في قيم مقياس الأداء المحدد عبر مجموعات البيانات الفرعية. إليك بعض الأمثلة:
- التفاوت في معدل الدقة
- التفاوت في معدل الخطأ
- التفاوت في الدقة
- التفاوت في الاستدعاء
- التفاوت في متوسط الخطأ المطلق (MAE)
التفاوت في معدل الاختيار: يحتوي هذا المقياس على الفرق في معدل الاختيار (التوقع المفضل) بين المجموعات الفرعية. مثال على ذلك هو التفاوت في معدلات الموافقة على القروض. معدل الاختيار يعني نسبة نقاط البيانات في كل فئة المصنفة كـ 1 (في التصنيف الثنائي) أو توزيع قيم التوقعات (في الانحدار).
تحليل البيانات
"إذا عذبت البيانات بما فيه الكفاية، ستعترف بأي شيء" - رونالد كواس
يبدو هذا البيان متطرفًا، لكنه صحيح أن البيانات يمكن التلاعب بها لدعم أي استنتاج. مثل هذا التلاعب يمكن أن يحدث أحيانًا دون قصد. كبشر، لدينا جميعًا تحيز، وغالبًا ما يكون من الصعب أن ندرك بوعي متى ندخل التحيز في البيانات. ضمان العدالة في الذكاء الاصطناعي وتعلم الآلة يبقى تحديًا معقدًا.
البيانات هي نقطة عمياء كبيرة لمقاييس أداء النموذج التقليدية. قد تكون لديك درجات دقة عالية، لكن هذا لا يعكس دائمًا التحيز الأساسي في البيانات الذي قد يكون موجودًا في مجموعة البيانات الخاصة بك. على سبيل المثال، إذا كانت مجموعة بيانات الموظفين تحتوي على 27% من النساء في المناصب التنفيذية في شركة و73% من الرجال في نفس المستوى، فإن نموذج الإعلان عن الوظائف الذي يتم تدريبه على هذه البيانات قد يستهدف جمهورًا ذكوريًا بشكل أساسي للمناصب العليا. وجود هذا التفاوت في البيانات أدى إلى انحياز توقع النموذج لتفضيل جنس واحد. هذا يكشف عن مشكلة عدالة حيث يوجد تحيز جنسي في نموذج الذكاء الاصطناعي.
يساعد مكون تحليل البيانات في لوحة القيادة للذكاء الاصطناعي المسؤول في تحديد المناطق التي يوجد فيها تمثيل زائد أو ناقص في مجموعة البيانات. يساعد المستخدمين في تشخيص السبب الجذري للأخطاء ومشكلات العدالة الناتجة عن التفاوتات في البيانات أو نقص تمثيل مجموعة بيانات معينة. يمنح المستخدمين القدرة على تصور مجموعات البيانات بناءً على النتائج المتوقعة والفعلية، مجموعات الأخطاء، والميزات المحددة. أحيانًا يمكن أن يكشف اكتشاف مجموعة بيانات غير ممثلة عن أن النموذج لا يتعلم بشكل جيد، مما يؤدي إلى ارتفاع الأخطاء. وجود نموذج يحتوي على تحيز في البيانات ليس فقط مشكلة عدالة ولكنه يظهر أن النموذج غير شامل أو موثوق.

استخدم تحليل البيانات عندما تحتاج إلى:
- استكشاف إحصائيات مجموعة البيانات الخاصة بك عن طريق اختيار عوامل تصفية مختلفة لتقسيم البيانات إلى أبعاد مختلفة (المعروفة أيضًا بالمجموعات).
- فهم توزيع مجموعة البيانات الخاصة بك عبر مجموعات مختلفة ومجموعات الميزات.
- تحديد ما إذا كانت النتائج المتعلقة بالعدالة، تحليل الأخطاء، والسببية (المستمدة من مكونات لوحة القيادة الأخرى) هي نتيجة توزيع مجموعة البيانات الخاصة بك.
- اتخاذ قرار بشأن المناطق التي يجب جمع المزيد من البيانات فيها لتخفيف الأخطاء الناتجة عن مشكلات التمثيل، ضوضاء العلامات، ضوضاء الميزات، تحيز العلامات، وعوامل مشابهة.
تفسير النموذج
نماذج تعلم الآلة تميل إلى أن تكون صناديق سوداء. فهم الميزات الرئيسية للبيانات التي تؤثر على توقعات النموذج يمكن أن يكون تحديًا. من المهم توفير الشفافية حول سبب قيام النموذج بتوقع معين. على سبيل المثال، إذا توقع نظام ذكاء اصطناعي أن مريضًا مصابًا بالسكري معرض لخطر العودة إلى المستشفى في أقل من 30 يومًا، يجب أن يكون قادرًا على تقديم بيانات داعمة أدت إلى توقعه. وجود مؤشرات بيانات داعمة يجلب الشفافية لمساعدة الأطباء أو المستشفيات على اتخاذ قرارات مستنيرة. بالإضافة إلى ذلك، القدرة على تفسير سبب قيام النموذج بتوقع لفرد معين تمكن من المساءلة مع اللوائح الصحية. عندما تستخدم نماذج تعلم الآلة بطرق تؤثر على حياة الناس، من الضروري فهم وتفسير ما يؤثر على سلوك النموذج. تفسير النموذج يساعد في الإجابة على أسئلة في سيناريوهات مثل:
- تصحيح النموذج: لماذا ارتكب النموذج هذا الخطأ؟ كيف يمكنني تحسين النموذج؟
- التعاون بين الإنسان والذكاء الاصطناعي: كيف يمكنني فهم وثقة قرارات النموذج؟
- الامتثال التنظيمي: هل يلبي النموذج متطلبات قانونية؟
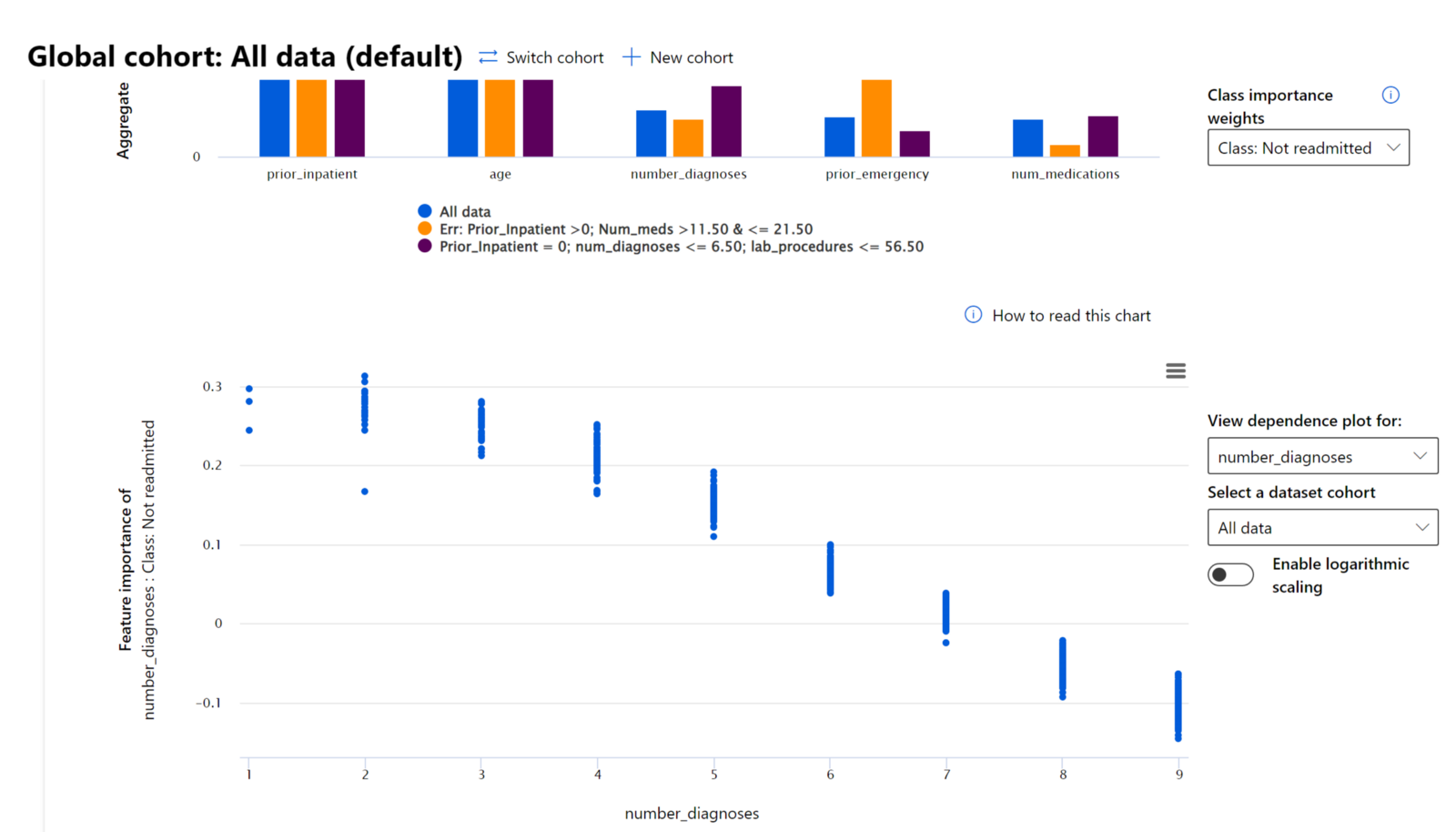
يساعد مكون أهمية الميزات في لوحة القيادة للذكاء الاصطناعي المسؤول في تصحيح وفهم شامل لكيفية قيام النموذج بتوقعاته. كما أنه أداة مفيدة لمهنيي تعلم الآلة وصناع القرار لتفسير وإظهار الأدلة على الميزات التي تؤثر على سلوك النموذج للامتثال التنظيمي. بعد ذلك، يمكن للمستخدمين استكشاف التفسيرات العالمية والمحلية للتحقق من الميزات التي تؤثر على توقعات النموذج. التفسيرات العالمية تسرد الميزات الرئيسية التي أثرت على توقعات النموذج بشكل عام. التفسيرات المحلية تعرض الميزات التي أدت إلى توقع النموذج لحالة فردية. القدرة على تقييم التفسيرات المحلية مفيدة أيضًا في تصحيح أو تدقيق حالة معينة لفهم وتفسير سبب قيام النموذج بتوقع صحيح أو خاطئ.
- التفسيرات العالمية: على سبيل المثال، ما الميزات التي تؤثر على السلوك العام لنموذج إعادة دخول المستشفى لمرضى السكري؟
- التفسيرات المحلية: على سبيل المثال، لماذا تم توقع أن مريضًا مصابًا بالسكري يزيد عمره عن 60 عامًا وله دخول سابق إلى المستشفى سيتم إعادة دخوله أو عدم إعادة دخوله خلال 30 يومًا إلى المستشفى؟
في عملية تصحيح أداء النموذج عبر مجموعات مختلفة، تظهر أهمية الميزات مستوى تأثير الميزة عبر المجموعات. يساعد ذلك في الكشف عن الشذوذ عند مقارنة مستوى تأثير الميزة في قيادة توقعات النموذج الخاطئة. يمكن لمكون أهمية الميزات أن يظهر القيم في ميزة ما التي أثرت إيجابيًا أو سلبيًا على نتيجة النموذج. على سبيل المثال، إذا قام النموذج بتوقع خاطئ، يمنحك المكون القدرة على التعمق وتحديد الميزات أو قيم الميزات التي دفعت التوقع. هذا المستوى من التفاصيل يساعد ليس فقط في التصحيح ولكن يوفر الشفافية والمساءلة في حالات التدقيق. أخيرًا، يمكن للمكون أن يساعدك في تحديد مشكلات العدالة. لتوضيح ذلك، إذا كانت ميزة حساسة مثل العرق أو الجنس مؤثرة بشكل كبير في قيادة توقعات النموذج، فقد يكون هذا علامة على وجود تحيز عرقي أو جنسي في النموذج.
استخدم التفسير عندما تحتاج إلى:
- تحديد مدى موثوقية توقعات نظام الذكاء الاصطناعي الخاص بك من خلال فهم الميزات الأكثر أهمية للتوقعات.
- الاقتراب من تصحيح النموذج من خلال فهمه أولاً وتحديد ما إذا كان النموذج يستخدم ميزات صحية أو مجرد ارتباطات خاطئة.
- الكشف عن مصادر محتملة لعدم العدالة من خلال فهم ما إذا كان النموذج يعتمد في توقعاته على ميزات حساسة أو ميزات مرتبطة بها بشكل كبير.
- بناء ثقة المستخدم في قرارات النموذج من خلال توليد تفسيرات محلية لتوضيح نتائجها.
- إكمال تدقيق تنظيمي لنظام الذكاء الاصطناعي للتحقق من صحة النماذج ومراقبة تأثير قرارات النموذج على البشر.
الخاتمة
جميع مكونات لوحة القيادة للذكاء الاصطناعي المسؤول هي أدوات عملية تساعدك في بناء نماذج تعلم الآلة التي تكون أقل ضررًا وأكثر موثوقية للمجتمع. إنها تحسن الوقاية من التهديدات لحقوق الإنسان؛ التمييز أو استبعاد مجموعات معينة من فرص الحياة؛ وخطر الإصابة الجسدية أو النفسية. كما أنها تساعد في بناء الثقة في قرارات النموذج من خلال توليد تفسيرات محلية لتوضيح نتائجها. بعض الأضرار المحتملة يمكن تصنيفها كالتالي:
- التخصيص، إذا تم تفضيل جنس أو عرق على آخر.
- جودة الخدمة. إذا قمت بتدريب البيانات على سيناريو معين ولكن الواقع أكثر تعقيدًا، يؤدي ذلك إلى خدمة ضعيفة الأداء.
- التصنيف النمطي. ربط مجموعة معينة بصفات محددة مسبقًا.
- التقليل من القيمة. النقد غير العادل ووضع علامات سلبية على شيء أو شخص معين.
- التمثيل الزائد أو الناقص. الفكرة هي أن مجموعة معينة لا تُرى في مهنة معينة، وأي خدمة أو وظيفة تستمر في تعزيز ذلك تساهم في الضرر.
لوحة معلومات Azure RAI
لوحة معلومات Azure RAI مبنية على أدوات مفتوحة المصدر طورتها مؤسسات أكاديمية ومنظمات رائدة، بما في ذلك Microsoft، وهي أدوات أساسية لمساعدة علماء البيانات ومطوري الذكاء الاصطناعي على فهم سلوك النماذج بشكل أفضل، واكتشاف ومعالجة المشكلات غير المرغوب فيها في نماذج الذكاء الاصطناعي.
-
تعلم كيفية استخدام المكونات المختلفة من خلال الاطلاع على وثائق لوحة معلومات RAI.
-
استعرض بعض دفاتر الملاحظات التجريبية للوحة معلومات RAI لتصحيح سيناريوهات الذكاء الاصطناعي الأكثر مسؤولية في Azure Machine Learning.
🚀 التحدي
لمنع إدخال التحيزات الإحصائية أو البيانات من البداية، يجب علينا:
- ضمان تنوع الخلفيات ووجهات النظر بين الأشخاص الذين يعملون على الأنظمة
- الاستثمار في مجموعات بيانات تعكس تنوع مجتمعنا
- تطوير طرق أفضل للكشف عن التحيز وتصحيحه عند حدوثه
فكر في سيناريوهات واقعية حيث يكون الظلم واضحًا في بناء النماذج واستخدامها. ما الذي يجب أن نأخذه بعين الاعتبار أيضًا؟
اختبار ما بعد المحاضرة
المراجعة والدراسة الذاتية
في هذه الدرس، تعلمت بعض الأدوات العملية لتضمين الذكاء الاصطناعي المسؤول في تعلم الآلة.
شاهد هذه الورشة للتعمق أكثر في المواضيع:
- لوحة معلومات الذكاء الاصطناعي المسؤول: منصة شاملة لتطبيق الذكاء الاصطناعي المسؤول عمليًا بواسطة بسميرة نوشي ومهرنوش ساميكي

🎥 انقر على الصورة أعلاه لمشاهدة الفيديو: لوحة معلومات الذكاء الاصطناعي المسؤول: منصة شاملة لتطبيق الذكاء الاصطناعي المسؤول عمليًا بواسطة بسميرة نوشي ومهرنوش ساميكي
راجع المواد التالية لتتعلم المزيد عن الذكاء الاصطناعي المسؤول وكيفية بناء نماذج أكثر موثوقية:
-
أدوات لوحة معلومات Microsoft RAI لتصحيح نماذج تعلم الآلة: موارد أدوات الذكاء الاصطناعي المسؤول
-
استكشف مجموعة أدوات الذكاء الاصطناعي المسؤول: Github
-
مركز موارد Microsoft RAI: موارد الذكاء الاصطناعي المسؤول – Microsoft AI
-
مجموعة أبحاث FATE التابعة لـ Microsoft: FATE: العدالة، المساءلة، الشفافية، والأخلاقيات في الذكاء الاصطناعي - أبحاث Microsoft
الواجب
إخلاء المسؤولية:
تم ترجمة هذا المستند باستخدام خدمة الترجمة بالذكاء الاصطناعي Co-op Translator. بينما نسعى لتحقيق الدقة، يرجى العلم أن الترجمات الآلية قد تحتوي على أخطاء أو معلومات غير دقيقة. يجب اعتبار المستند الأصلي بلغته الأصلية هو المصدر الموثوق. للحصول على معلومات حاسمة، يُوصى بالاستعانة بترجمة بشرية احترافية. نحن غير مسؤولين عن أي سوء فهم أو تفسيرات خاطئة ناتجة عن استخدام هذه الترجمة.