2.9 KiB
Entrena el carrito de montaña
OpenAI Gym ha sido diseñado de tal forma que todos los ambientes proveen la misma API - esto es, los mismos métodos reset, step y render, y las mismas abstracciones de action space y observation space. Así sería posible adaptar los mismos algoritmos de aprendizaje reforzado a diferentes ambientes con mínimos cambios al código.
Un ambiente de carrito de montaña
El ambiente de carrito de montaña contiene un carrito atrapado en un valle:
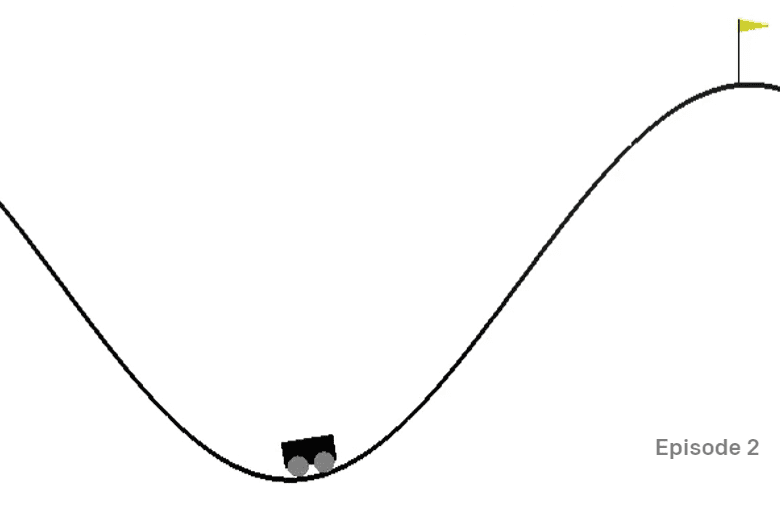
El objetivo es salir del valle y capturar la bandera, al hacer a cada paso una de las siguientes acciones:
| Valor | Significado |
|---|---|
| 0 | Acelerar a la izquierda |
| 1 | No acelerar |
| 2 | Acelerar a la derecha |
El truco principal de este problema es, no obstante, que el motor del carrito no es lo suficientemente potente para escalar la montaña en una sola pasada. Por lo tanto, la única forma de lograrlo es conducir hacia atrás y adelante para generar impulso.
El espacio de observación consiste de sólo dos valores:
| Num | Observación | Min | Max |
|---|---|---|---|
| 0 | Posición del carrito | -1.2 | 0.6 |
| 1 | Velocidad del carrito | -0.07 | 0.07 |
El sistema de recompensas para el carrito de montaña es engañoso:
- La recompensa de 0 es otorgada si el agente alcanzó la bandera (posición = 0.5) en la cima de la montaña.
- La recompensa de -1 es otorgada si la posición del agente es menos de 0.5.
El episodio termina si la posición del carrito es más de 0.5, o la longitud del episodio es mayor que 200.
Instrucciones
Adapta nuestro algoritmo de aprendizaje reforzado para resolver el problema del carrito de montaña. Comienza con el código existente en notebook.ipynb, substituye el nuevo ambiente, cambia las funciones de discretización de estado, e intenta hacer que el algoritmo existente entrene con mínimas modificaciones al código. Optimiza el resultado al ajustar los hiperparámetros.
Nota: Es probable que ajustar los hiperparámetros sea necesario para hacer que el algoritmo converja.
Rúbrica
| Criterio | Ejemplar | Adecuado | Necesita mejorar |
|---|---|---|---|
| El algoritmo Q-Learning se adaptó de forma exitosa a partir del ejemplo CartPole, con mínimas modificaciones al código, el cual es capaz de resolver el problema al capturar la bandera con menos de 200 pasos. | Se adoptó un nuevo algoritmo Q-Learning de internet, pero está bien documentado; o se adoptó el algoritmo existente, pero no cumple los resultados deseados | El estudiante no fue capaz de adoptar ningún algoritmo de forma exitosa, pero ha hecho pasos substanciales hacia la solución (implementó la discretización de estado, la estructura de datos de Q-Table, etc.) |