11 KiB
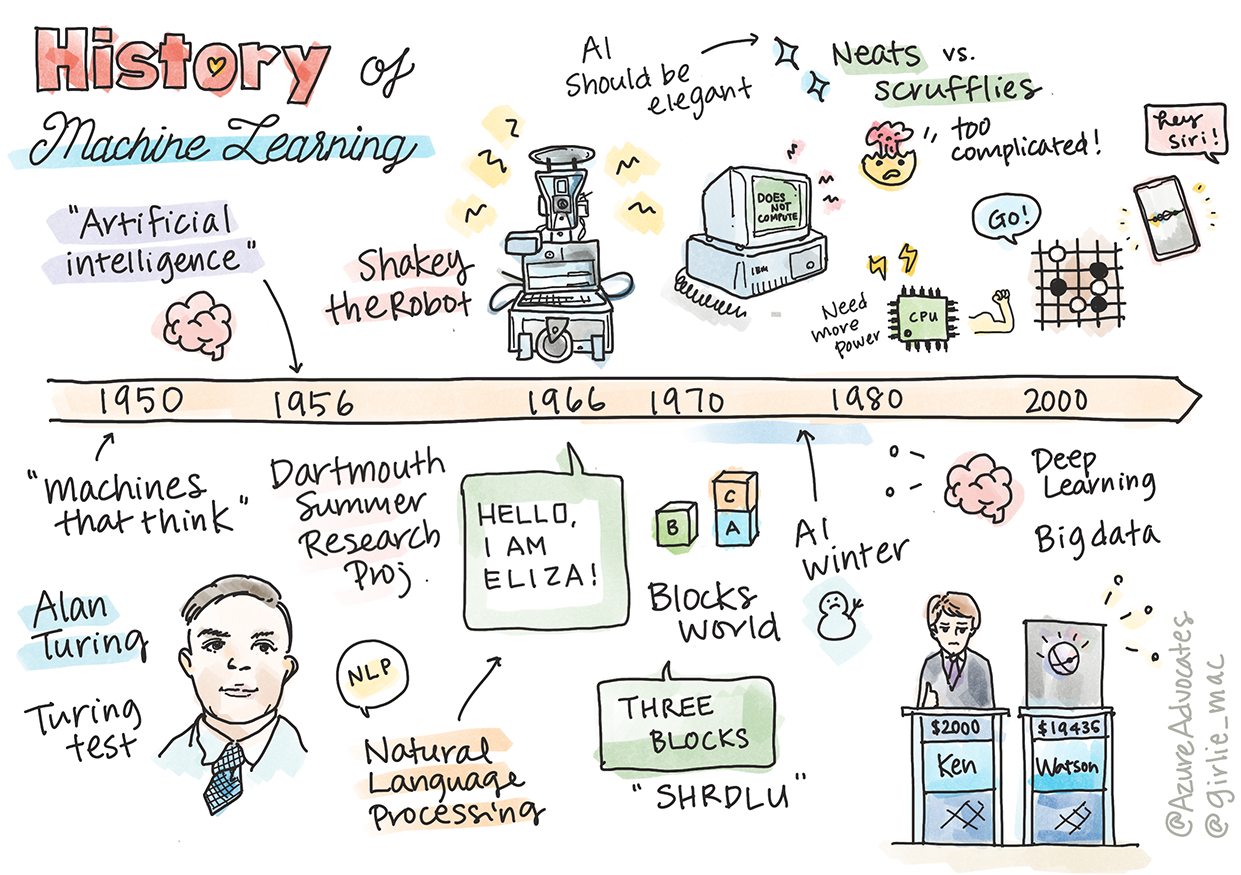
머신러닝의 역사
Sketchnote by Tomomi Imura
강의 전 퀴즈
이 강의에서, 머신러닝과 인공 지능의 역사에서 주요 마일스톤을 살펴보려 합니다.
인공 지능, AI의 역사는 머신러닝의 역사와 서로 엮여 있으며, ML을 받쳐주는 알고리즘과 계산 기술이 AI의 개발에 기여했습니다. 독특한 탐구 영역으로 이런 분야는 1950년에 구체적으로 시작했지만, 중요한 algorithmical, statistical, mathematical, computational and technical discoveries로 이 시대를 오버랩했다고 생각하는 게 유용합니다. 실제로, 사람들은 hundreds of years동안 이 질문을 생각해왔습니다: 이 아티클은 'thinking machine'라는 개념의 역사적 지적 토대에 대하여 이야기 합니다.
주목할 발견
- 1763, 1812 Bayes Theorem과 전임자. 이 정리와 적용은 사전지식 기반으로 이벤트가 발생할 확률을 설명할 추론의 기초가 됩니다.
- 1805 Least Square Theory by 프랑스 수학자 Adrien-Marie Legendre. Regression 단위에서 배울 이 이론은, 데이터 피팅에 도움이 됩니다.
- 1913 러시아 수학자 Andrey Markov의 이름에서 유래된 Markov Chains는 이전 상태를 기반으로 가능한 이벤트의 시퀀스를 설명하는 데 사용됩니다.
- 1957 Perceptron은 미국 심리학자 Frank Rosenblatt이 개발한 linear classifier의 한 타입으로 딥러닝 발전을 뒷받칩니다.
- 1967 Nearest Neighbor는 원래 경로를 맵핑하기 위한 알고리즘입니다. ML context에서 패턴을 감지할 때 사용합니다.
- 1970 Backpropagation은 feedforward neural networks를 학습할 때 사용합니다.
- 1982 Recurrent Neural Networks는 시간 그래프를 생성하는 feedforward neural networks에서 파생한 인공 신경망입니다.
✅ 조금 조사해보세요. ML과 AI의 역사에서 중요한 다른 날짜는 언제인가요?
1950: 생각하는 기계
20세기의 최고 과학자로 by the public in 2019에 선택된, Alan Turing은, 'machine that can think.'라는 개념의 기반을 구축하는 데에 기여한 것으로 평가되고 있습니다. NLP 강의에서 살필 Turing Test를 만들어서 부분적으로 이 개념에 대한 경험적인 반대하는 사람들과 대립했습니다.
1956: Dartmouth 여름 연구 프로젝트
"The Dartmouth Summer Research Project on artificial intelligence was a seminal event for artificial intelligence as a field," (source)에서 "인공 지능"이라는 용어가 만들어졌습니다.
학습의 모든 측면이나 지능의 다른 기능은 원칙적으로 정확하게 서술할 수 있어서 이를 따라 할 기계를 만들 수 있습니다.
수석 연구원인, 수학 교수 John McCarthy는, "to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it."이라고 희망했습니다. 참가한 사람들 중에서는 Marvin Minsky도 있었습니다.
이 워크숍은 "the rise of symbolic methods, systems focussed on limited domains (early expert systems), and deductive systems versus inductive systems." (source)을 포함해서 여러 토론을 시작하고 장려한 것으로 평가됩니다.
1956 - 1974: "The golden years"
1950년대부터 70년대 중순까지 AI로 많은 문제를 해결할 수 있다고 믿은 낙관주의가 커졌습니다. 1967년 Marvin Minsky는 "Within a generation ... the problem of creating 'artificial intelligence' will substantially be solved." (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)이라고 자신있게 말했습니다.
natural language processing 연구가 발전하고, 검색이 개선되어 더 강력해졌으며, 단순한 언어 지침으로 간단한 작업을 완료하는 'micro-worlds'라는 개념이 생겼습니다.
정부 지원을 받으며 연구했으며, 계산과 알고리즘이 발전하면서, 지능적 기계의 프로토 타입이 만들어졌습니다. 이런 기계 중에 일부는 아래와 같습니다:
-
Shakey the robot, '지능적'으로 작업하는 방법을 조종하고 결정할 수 있습니다.

Shakey in 1972
-
초기 'chatterbot'인, Eliza는, 사람들과 이야기하고 원시적 '치료사' 역할을 할 수 있었습니다. NLP 강의에서 Eliza에 대하여 자세히 알아봅시다.
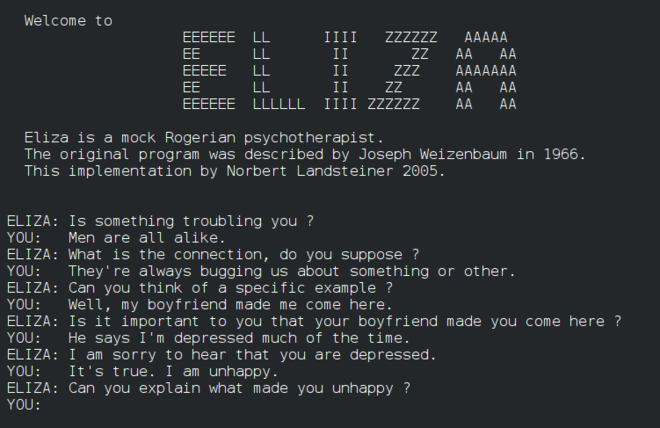
A version of Eliza, a chatbot
-
"Blocks world"는 블록을 쌓고 분류할 수 있는 마이크로-월드의 예시이며, 결정하는 기계를 가르칠 실험을 테스트할 수 있었습니다. SHRDLU와 같은 라이브러리로 만들어진 발명은 language processing를 발전시키는 데 도움이 되었습니다.

🎥 영상을 보려면 이미지 클릭: Blocks world with SHRDLU
1974 - 1980: "AI Winter"
1970년 중순에, '인공 기계'를 만드는 복잡도가 과소 평가되면서, 주어진 컴퓨터 파워를 고려해보니, 그 약속은 과장된 것이 분명해졌습니다. 자금이 고갈되고 현장에 대한 자신감도 느려졌습니다. 신뢰에 영향을 준 이슈는 아래에 있습니다:
- 제한. 컴퓨터 성능이 너무 제한되었습니다.
- 결합 파열. 훈련에 필요한 파라미터의 양이 컴퓨터 성능, 기능과 별개로 컴퓨터의 요청에 따라 늘어났습니다.
- 데이터 부족. 알고리즘을 테스트, 개발, 그리고 개선할 수 없게 데이터가 부족했습니다.
- 올바른 질문인가요?. 질문받은 그 질문에 바로 물었습니다. 연구원들은 그 접근 방식에 비판했습니다:
- 튜링 테스트는 "programming a digital computer may make it appear to understand language but could not produce real understanding." (source)하다고 가정한, 'chinese room theory'의 다른 아이디어에 의해 의문이 생겼습니다.
- "치료사" ELIZA와 같은 인공 지능을 사회에 도입하며 윤리에 도전했습니다.
동 시간대에, 다양한 AI 학교가 형성되기 시작했습니다. "scruffy" vs. "neat AI" 사이에 이분법이 확립되었습니다. Scruffy 연구실은 원하는 결과를 얻을 때까지 몇 시간 동안 프로그램을 트윅했습니다. Neat 연구실은 논리와 공식적 문제를 해결하는 데에 초점을 맞추었습니다. ELIZA와 SHRDLU는 잘 알려진 scruffy 시스템입니다. 1980년대에, ML 시스템을 재현할 수 있어야 된다는 요구사항이 생겼고, neat 방식이 더 결과를 설명할 수 있어서 점차 선두를 차지했습니다.
1980s 전문가 시스템
이 분야가 성장하며, 비즈니스에 대한 이점이 명확해졌고, 1980년대에 '전문가 시스템'이 확산되었습니다. "Expert systems were among the first truly successful forms of artificial intelligence (AI) software." (source).
이 시스템의 타입은, 실제로 비즈니스 요구사항을 정의하는 룰 엔진과 새로운 사실 추론하는 룰 시스템을 활용한 추론 엔진으로 부분적 구성된 hybrid 입니다.
이런 시대에도 neural networks에 대한 관심이 늘어났습니다.
1987 - 1993: AI 'Chill'
전문화된 전문가 시스템 하드웨어의 확산은 너무나도 고차원되는 불운한 결과를 가져왔습니다. 개인용 컴퓨터의 부상은 크고, 전문화된, 중앙화 시스템과 경쟁했습니다. 컴퓨팅의 민주화가 시작되었고, 결국 현대의 빅 데이터 폭발을 위한 길을 열었습니다.
1993 - 2011
이 시대에는 ML과 AI가 과거 데이터와 컴퓨터 파워 부족으로 인해 발생했던 문제 중 일부 해결할 수 있는 새로운 시대가 열렸습니다. 데이터의 양은 급격히 늘어나기 시작했고, 2007년에 스마트폰이 나오면서 좋든 나쁘든 더 넓게 사용할 수 있게 되었습니다. 컴퓨터 파워는 크게 확장되었고, 알고리즘도 함께 발전했습니다. 과거 자유롭던 시대에서 진정한 규율로 이 분야는 성숙해지기 시작했습니다.
현재
오늘 날, 머신러닝과 AI는 인생의 대부분에 영향을 미칩니다. 이 시대에는 이러한 알고리즘이 인간의 인생에 미치는 위험과 잠재적인 영향에 대한 주의깊은 이해도가 요구됩니다. Microsoft의 Brad Smith가 언급합니다 "Information technology raises issues that go to the heart of fundamental human-rights protections like privacy and freedom of expression. These issues heighten responsibility for tech companies that create these products. In our view, they also call for thoughtful government regulation and for the development of norms around acceptable uses" (source).
미래가 어떻게 변할지 알 수 없지만, 컴퓨터 시스템과 이를 실행하는 소프트웨어와 알고리즘을 이해하는 것은 중요합니다. 이 커리큘럼으로 더 잘 이해하고 스스로 결정할 수 있게 되기를 바랍니다.

🎥 영상 보려면 위 이미지 클릭: Yann LeCun이 강의에서 딥러닝의 역사를 이야기 합니다.
🚀 도전
역사적인 순간에 사람들 뒤에서 한 가지를 집중적으로 파고 있는 자를 자세히 알아보세요. 매력있는 캐릭터가 있으며, 문화가 사라진 곳에서는 과학적인 발견을 하지 못합니다. 당신은 어떤 발견을 해보았나요?
강의 후 퀴즈
검토 & 자기주도 학습
보고 들을 수 있는 항목은 아래와 같습니다:
This podcast where Amy Boyd discusses the evolution of AI
