15 KiB
Techniques de l'apprentissage automatique
Le processus de construction, d'utilisation et de maintenance des modèles d'apprentissage automatique et des données qu'ils utilisent est très différent de nombreux autres flux de travail de développement. Dans cette leçon, nous allons démystifier le processus et décrire les principales techniques que vous devez connaître. Vous allez :
- Comprendre les processus sous-jacents à l'apprentissage automatique à un niveau élevé.
- Explorer des concepts de base tels que les 'modèles', les 'prédictions' et les 'données d'entraînement'.
Quiz pré-conférence

🎥 Cliquez sur l'image ci-dessus pour une courte vidéo sur cette leçon.
Introduction
À un niveau élevé, l'art de créer des processus d'apprentissage automatique (ML) est composé de plusieurs étapes :
- Décidez de la question. La plupart des processus ML commencent par poser une question qui ne peut pas être répondue par un simple programme conditionnel ou un moteur basé sur des règles. Ces questions tournent souvent autour des prédictions basées sur une collection de données.
- Collectez et préparez les données. Pour pouvoir répondre à votre question, vous avez besoin de données. La qualité et, parfois, la quantité de vos données détermineront la manière dont vous pouvez répondre à votre question initiale. La visualisation des données est un aspect important de cette phase. Cette phase comprend également la division des données en un groupe d'entraînement et un groupe de test pour construire un modèle.
- Choisissez une méthode d'entraînement. En fonction de votre question et de la nature de vos données, vous devez choisir comment vous souhaitez entraîner un modèle pour refléter au mieux vos données et faire des prédictions précises. C'est la partie de votre processus ML qui nécessite une expertise spécifique et, souvent, une quantité considérable d'expérimentation.
- Entraînez le modèle. En utilisant vos données d'entraînement, vous utiliserez divers algorithmes pour entraîner un modèle à reconnaître des motifs dans les données. Le modèle pourrait tirer parti de poids internes qui peuvent être ajustés pour privilégier certaines parties des données par rapport à d'autres afin de construire un meilleur modèle.
- Évaluez le modèle. Vous utilisez des données jamais vues auparavant (vos données de test) de votre ensemble collecté pour voir comment le modèle fonctionne.
- Réglage des paramètres. En fonction de la performance de votre modèle, vous pouvez reprendre le processus en utilisant différents paramètres, ou variables, qui contrôlent le comportement des algorithmes utilisés pour entraîner le modèle.
- Prédire. Utilisez de nouvelles entrées pour tester la précision de votre modèle.
Quelle question poser
Les ordinateurs sont particulièrement doués pour découvrir des motifs cachés dans les données. Cette utilité est très utile pour les chercheurs qui ont des questions sur un domaine donné qui ne peuvent pas être facilement répondues en créant un moteur de règles basé sur des conditions. Par exemple, dans une tâche actuarielle, un data scientist pourrait être en mesure de construire des règles élaborées autour de la mortalité des fumeurs par rapport aux non-fumeurs.
Cependant, lorsque de nombreuses autres variables sont introduites dans l'équation, un modèle ML pourrait s'avérer plus efficace pour prédire les taux de mortalité futurs basés sur l'historique de santé passé. Un exemple plus joyeux pourrait être de faire des prévisions météorologiques pour le mois d'avril dans un endroit donné en fonction de données incluant la latitude, la longitude, le changement climatique, la proximité de l'océan, les motifs du jet stream, et plus encore.
✅ Ce diaporama sur les modèles météorologiques offre une perspective historique sur l'utilisation de ML dans l'analyse météorologique.
Tâches pré-construction
Avant de commencer à construire votre modèle, plusieurs tâches doivent être accomplies. Pour tester votre question et formuler une hypothèse basée sur les prédictions d'un modèle, vous devez identifier et configurer plusieurs éléments.
Données
Pour pouvoir répondre à votre question avec une certaine certitude, vous avez besoin d'une bonne quantité de données du bon type. Il y a deux choses que vous devez faire à ce stade :
- Collecter des données. En gardant à l'esprit la leçon précédente sur l'équité dans l'analyse des données, collectez vos données avec soin. Soyez conscient des sources de ces données, de tout biais inhérent qu'elles pourraient avoir, et documentez leur origine.
- Préparer les données. Il y a plusieurs étapes dans le processus de préparation des données. Vous devrez peut-être rassembler les données et les normaliser si elles proviennent de sources diverses. Vous pouvez améliorer la qualité et la quantité des données par divers moyens, comme convertir des chaînes en nombres (comme nous le faisons dans Clustering). Vous pourriez également générer de nouvelles données, basées sur les originales (comme nous le faisons dans Classification). Vous pouvez nettoyer et modifier les données (comme nous le ferons avant la leçon sur Web App). Enfin, vous pourriez également avoir besoin de les randomiser et de les mélanger, en fonction de vos techniques d'entraînement.
✅ Après avoir collecté et traité vos données, prenez un moment pour voir si leur forme vous permettra de répondre à votre question prévue. Il se peut que les données ne fonctionnent pas bien pour votre tâche donnée, comme nous le découvrons dans nos leçons sur Clustering !
Caractéristiques et Cible
Une caractéristique est une propriété mesurable de vos données. Dans de nombreux ensembles de données, elle est exprimée sous forme de titre de colonne comme 'date', 'taille' ou 'couleur'. Votre variable de caractéristique, généralement représentée par X dans le code, représente la variable d'entrée qui sera utilisée pour entraîner le modèle.
Une cible est une chose que vous essayez de prédire. La cible est généralement représentée par y dans le code, et représente la réponse à la question que vous essayez de poser à vos données : en décembre, quelle couleur de citrouilles sera la moins chère ? à San Francisco, quels quartiers auront le meilleur prix immobilier ? Parfois, la cible est également appelée attribut étiquette.
Sélectionner votre variable de caractéristique
🎓 Sélection de caractéristiques et extraction de caractéristiques Comment savez-vous quelle variable choisir lors de la construction d'un modèle ? Vous allez probablement passer par un processus de sélection de caractéristiques ou d'extraction de caractéristiques pour choisir les bonnes variables pour le modèle le plus performant. Ce ne sont cependant pas la même chose : "L'extraction de caractéristiques crée de nouvelles caractéristiques à partir de fonctions des caractéristiques originales, tandis que la sélection de caractéristiques retourne un sous-ensemble des caractéristiques." (source)
Visualisez vos données
Un aspect important de la boîte à outils du data scientist est la capacité de visualiser les données à l'aide de plusieurs bibliothèques excellentes telles que Seaborn ou MatPlotLib. Représenter vos données visuellement pourrait vous permettre de découvrir des corrélations cachées que vous pouvez exploiter. Vos visualisations pourraient également vous aider à découvrir des biais ou des données déséquilibrées (comme nous le découvrons dans Classification).
Divisez votre ensemble de données
Avant l'entraînement, vous devez diviser votre ensemble de données en deux ou plusieurs parties de taille inégale qui représentent néanmoins bien les données.
- Entraînement. Cette partie de l'ensemble de données est ajustée à votre modèle pour l'entraîner. Cet ensemble constitue la majorité de l'ensemble de données original.
- Test. Un ensemble de données de test est un groupe indépendant de données, souvent recueilli à partir des données originales, que vous utilisez pour confirmer la performance du modèle construit.
- Validation. Un ensemble de validation est un plus petit groupe indépendant d'exemples que vous utilisez pour ajuster les hyperparamètres du modèle, ou son architecture, afin d'améliorer le modèle. En fonction de la taille de vos données et de la question que vous posez, vous pourriez ne pas avoir besoin de construire cet ensemble supplémentaire (comme nous le notons dans Prévisions de séries temporelles).
Construction d'un modèle
En utilisant vos données d'entraînement, votre objectif est de construire un modèle, ou une représentation statistique de vos données, en utilisant divers algorithmes pour l'entraîner. Entraîner un modèle l'expose aux données et lui permet de faire des hypothèses sur les motifs perçus qu'il découvre, valide et accepte ou rejette.
Décidez d'une méthode d'entraînement
En fonction de votre question et de la nature de vos données, vous choisirez une méthode pour l'entraîner. En parcourant la documentation de Scikit-learn - que nous utilisons dans ce cours - vous pouvez explorer de nombreuses façons d'entraîner un modèle. Selon votre expérience, vous devrez peut-être essayer plusieurs méthodes différentes pour construire le meilleur modèle. Vous êtes susceptible de passer par un processus où les data scientists évaluent la performance d'un modèle en lui fournissant des données non vues, vérifiant la précision, les biais et d'autres problèmes dégradants de qualité, et sélectionnant la méthode d'entraînement la plus appropriée pour la tâche à accomplir.
Entraînez un modèle
Armé de vos données d'entraînement, vous êtes prêt à 'ajuster' pour créer un modèle. Vous remarquerez que dans de nombreuses bibliothèques ML, vous trouverez le code 'model.fit' - c'est à ce moment que vous envoyez votre variable de caractéristique sous forme de tableau de valeurs (généralement 'X') et une variable cible (généralement 'y').
Évaluez le modèle
Une fois le processus d'entraînement terminé (cela peut prendre de nombreuses itérations, ou 'époques', pour entraîner un grand modèle), vous pourrez évaluer la qualité du modèle en utilisant des données de test pour évaluer sa performance. Ces données constituent un sous-ensemble des données originales que le modèle n'a pas analysées auparavant. Vous pouvez imprimer un tableau de métriques sur la qualité de votre modèle.
🎓 Ajustement du modèle
Dans le contexte de l'apprentissage automatique, l'ajustement du modèle fait référence à la précision de la fonction sous-jacente du modèle alors qu'il tente d'analyser des données avec lesquelles il n'est pas familier.
🎓 Sous-ajustement et surajustement sont des problèmes courants qui dégradent la qualité du modèle, car le modèle s'ajuste soit pas assez bien, soit trop bien. Cela fait que le modèle fait des prédictions soit trop étroitement alignées, soit trop librement alignées avec ses données d'entraînement. Un modèle surajusté prédit trop bien les données d'entraînement parce qu'il a appris les détails et le bruit des données trop bien. Un modèle sous-ajusté n'est pas précis car il ne peut ni analyser correctement ses données d'entraînement ni les données qu'il n'a pas encore 'vues'.
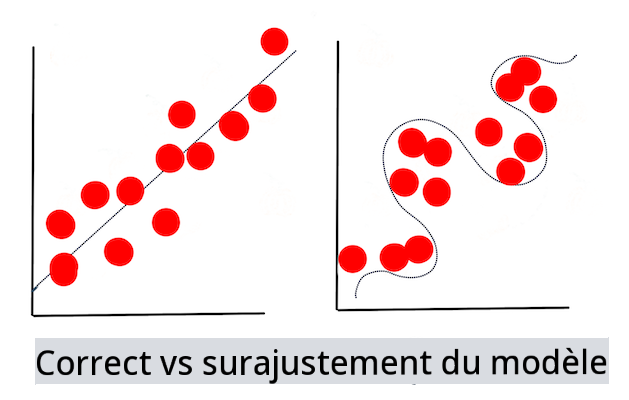
Infographie par Jen Looper
Réglage des paramètres
Une fois votre entraînement initial terminé, observez la qualité du modèle et envisagez de l'améliorer en ajustant ses 'hyperparamètres'. Lisez-en plus sur le processus dans la documentation.
Prédiction
C'est le moment où vous pouvez utiliser des données complètement nouvelles pour tester la précision de votre modèle. Dans un cadre ML 'appliqué', où vous construisez des actifs web pour utiliser le modèle en production, ce processus pourrait impliquer de recueillir des entrées utilisateur (une pression sur un bouton, par exemple) pour définir une variable et l'envoyer au modèle pour inférence, ou évaluation.
Dans ces leçons, vous découvrirez comment utiliser ces étapes pour préparer, construire, tester, évaluer et prédire - tous les gestes d'un data scientist et plus encore, à mesure que vous progressez dans votre parcours pour devenir un ingénieur ML 'full stack'.
🚀Défi
Dessinez un organigramme reflétant les étapes d'un praticien ML. Où vous voyez-vous actuellement dans le processus ? Où prévoyez-vous de rencontrer des difficultés ? Qu'est-ce qui vous semble facile ?
Quiz post-conférence
Révision et auto-apprentissage
Recherchez en ligne des interviews avec des data scientists qui discutent de leur travail quotidien. Voici une.
Devoir
Avertissement :
Ce document a été traduit à l'aide de services de traduction automatique basés sur l'IA. Bien que nous nous efforçons d'assurer l'exactitude, veuillez noter que les traductions automatiques peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue natale doit être considéré comme la source faisant autorité. Pour des informations critiques, une traduction professionnelle effectuée par un humain est recommandée. Nous ne sommes pas responsables des malentendus ou des interprétations erronées résultant de l'utilisation de cette traduction.