16 KiB
Python ve Scikit-learn ile Regresyon Modellerine Başlayın
Sketchnote Tomomi Imura tarafından
Ders Öncesi Quiz
Bu ders R dilinde de mevcut!
Giriş
Bu dört derste, regresyon modellerinin nasıl oluşturulacağını keşfedeceksiniz. Bunların ne işe yaradığını kısa süre içinde tartışacağız. Ancak herhangi bir şey yapmadan önce, süreci başlatmak için doğru araçlara sahip olduğunuzdan emin olun!
Bu derste şunları öğreneceksiniz:
- Bilgisayarınızı yerel makine öğrenimi görevleri için yapılandırma.
- Jupyter defterleri ile çalışma.
- Scikit-learn kullanımı, kurulum dahil.
- Uygulamalı bir egzersiz ile doğrusal regresyonu keşfetme.
Kurulumlar ve yapılandırmalar

🎥 Bilgisayarınızı ML için yapılandırma konusunda kısa bir video için yukarıdaki resme tıklayın.
-
Python'u yükleyin. Bilgisayarınızda Python yüklü olduğundan emin olun. Python'u birçok veri bilimi ve makine öğrenimi görevi için kullanacaksınız. Çoğu bilgisayar sistemi zaten bir Python kurulumu içerir. Ayrıca bazı kullanıcılar için kurulumu kolaylaştırmak adına kullanışlı Python Kod Paketleri de mevcuttur.
Ancak, Python'un bazı kullanımları yazılımın bir sürümünü gerektirirken, diğerleri farklı bir sürüm gerektirir. Bu nedenle, bir sanal ortam içinde çalışmak faydalıdır.
-
Visual Studio Code'u yükleyin. Bilgisayarınızda Visual Studio Code'un yüklü olduğundan emin olun. Temel kurulum için Visual Studio Code'u yükleme talimatlarını izleyin. Bu kursta Python'u Visual Studio Code'da kullanacağınız için, Python geliştirme için Visual Studio Code'u yapılandırma konusunda bilgi edinmek isteyebilirsiniz.
Python ile rahat çalışmak için bu Öğrenme modülleri koleksiyonunu inceleyin

🎥 Yukarıdaki resme tıklayarak VS Code içinde Python kullanımı hakkında bir video izleyin.
-
Scikit-learn'ü yükleyin, bu talimatları izleyerek. Python 3 kullanmanız gerektiğinden, bir sanal ortam kullanmanız önerilir. Not: Bu kütüphaneyi bir M1 Mac'e yüklüyorsanız, yukarıdaki sayfada özel talimatlar bulunmaktadır.
-
Jupyter Notebook'u yükleyin. Jupyter paketini yüklemeniz gerekecek.
Makine Öğrenimi Yazma Ortamınız
Python kodunuzu geliştirmek ve makine öğrenimi modelleri oluşturmak için defterler kullanacaksınız. Bu dosya türü veri bilimciler için yaygın bir araçtır ve uzantıları .ipynb ile tanımlanabilir.
Defterler, geliştiricinin hem kod yazmasına hem de kodun etrafında notlar ve dokümantasyon yazmasına olanak tanıyan etkileşimli bir ortamdır, bu da deneysel veya araştırma odaklı projeler için oldukça faydalıdır.

🎥 Bu egzersizi çalışırken kısa bir video için yukarıdaki resme tıklayın.
Egzersiz - bir defterle çalışma
Bu klasörde, notebook.ipynb dosyasını bulacaksınız.
-
notebook.ipynb dosyasını Visual Studio Code'da açın.
Python 3+ ile bir Jupyter sunucusu başlatılacak. Defterin bazı alanlarında
run, kod parçaları bulacaksınız. Bir kod bloğunu çalıştırmak için, oynat düğmesi gibi görünen simgeyi seçebilirsiniz. -
mdsimgesini seçin ve biraz markdown ve şu metni ekleyin # Defterinize hoş geldiniz.Sonra biraz Python kodu ekleyin.
-
Kod bloğuna print('hello notebook') yazın.
-
Kodu çalıştırmak için oku seçin.
Yazdırılan ifadeyi görmelisiniz:
hello notebook
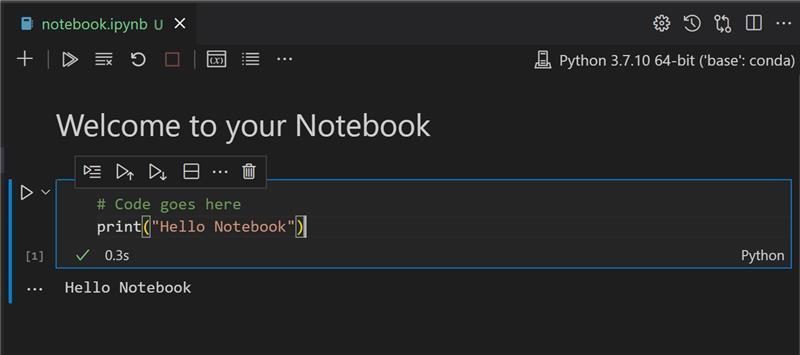
Kodunuzu yorumlarla birlikte ekleyerek defteri kendiliğinden belgelendirebilirsiniz.
✅ Bir web geliştiricisinin çalışma ortamının veri bilimcinin çalışma ortamından ne kadar farklı olduğunu bir düşünün.
Scikit-learn ile Başlamak
Artık Python yerel ortamınızda ayarlandı ve Jupyter defterleriyle rahatça çalışıyorsunuz, hadi Scikit-learn ile de aynı rahatlığı sağlayalım (bunu sci as in science olarak telaffuz edin). Scikit-learn, ML görevlerini gerçekleştirmenize yardımcı olacak geniş bir API sunar.
Web sitelerine göre (website), "Scikit-learn, denetimli ve denetimsiz öğrenmeyi destekleyen açık kaynaklı bir makine öğrenimi kütüphanesidir. Ayrıca model uyarlama, veri ön işleme, model seçimi ve değerlendirme ve birçok diğer yardımcı araçlar sağlar."
Bu derste, Scikit-learn ve diğer araçları kullanarak 'geleneksel makine öğrenimi' görevlerini gerçekleştirmek için makine öğrenimi modelleri oluşturacaksınız. Sinir ağları ve derin öğrenmeden özellikle kaçındık, çünkü bunlar yakında çıkacak olan 'Yeni Başlayanlar için AI' müfredatımızda daha iyi ele alınmaktadır.
Scikit-learn, modelleri oluşturmayı ve kullanmak üzere değerlendirmeyi kolaylaştırır. Öncelikle sayısal verilerle çalışmaya odaklanır ve öğrenme araçları olarak kullanılabilecek birkaç hazır veri seti içerir. Ayrıca öğrencilerin denemesi için önceden oluşturulmuş modeller de içerir. Hazır paketlenmiş verileri yükleme sürecini ve bazı temel verilerle ilk ML modelimizi Scikit-learn ile kullanma sürecini keşfedelim.
Egzersiz - ilk Scikit-learn defteriniz
Bu eğitim, Scikit-learn'ün web sitesindeki doğrusal regresyon örneğinden esinlenmiştir.

🎥 Bu egzersizi çalışırken kısa bir video için yukarıdaki resme tıklayın.
Bu derse bağlı notebook.ipynb dosyasında, tüm hücreleri 'çöp kutusu' simgesine basarak temizleyin.
Bu bölümde, öğrenme amacıyla Scikit-learn'e dahil edilen diyabet hakkında küçük bir veri seti ile çalışacaksınız. Diyabet hastaları için bir tedaviyi test etmek istediğinizi hayal edin. Makine Öğrenimi modelleri, değişkenlerin kombinasyonlarına dayalı olarak hangi hastaların tedaviye daha iyi yanıt vereceğini belirlemenize yardımcı olabilir. Çok basit bir regresyon modeli bile, görselleştirildiğinde, teorik klinik denemelerinizi düzenlemenize yardımcı olacak değişkenler hakkında bilgi gösterebilir.
✅ Birçok türde regresyon yöntemi vardır ve hangisini seçeceğiniz, aradığınız cevaba bağlıdır. Belirli bir yaşta bir kişinin muhtemel boyunu tahmin etmek istiyorsanız, doğrusal regresyon kullanırsınız, çünkü sayısal bir değer arıyorsunuzdur. Bir tür mutfağın vegan olup olmadığını keşfetmekle ilgileniyorsanız, kategori ataması arıyorsunuzdur, bu yüzden lojistik regresyon kullanırsınız. Lojistik regresyon hakkında daha fazla bilgi edineceksiniz. Verilere sorabileceğiniz bazı soruları ve bu yöntemlerden hangisinin daha uygun olacağını düşünün.
Hadi bu göreve başlayalım.
Kütüphaneleri İçe Aktarma
Bu görev için bazı kütüphaneleri içe aktaracağız:
- matplotlib. grafik aracı ve bir çizgi grafiği oluşturmak için kullanacağız.
- numpy. numpy Python'da sayısal verileri işlemek için kullanışlı bir kütüphanedir.
- sklearn. Bu, Scikit-learn kütüphanesidir.
Görevlerinizde yardımcı olması için bazı kütüphaneleri içe aktarın.
-
Aşağıdaki kodu yazarak içe aktarmaları ekleyin:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionYukarıda
matplotlib,numpyand you are importingdatasets,linear_modelandmodel_selectionfromsklearn.model_selectionis used for splitting data into training and test sets.
The diabetes dataset
The built-in diabetes dataset includes 442 samples of data around diabetes, with 10 feature variables, some of which include:
- age: age in years
- bmi: body mass index
- bp: average blood pressure
- s1 tc: T-Cells (a type of white blood cells)
✅ This dataset includes the concept of 'sex' as a feature variable important to research around diabetes. Many medical datasets include this type of binary classification. Think a bit about how categorizations such as this might exclude certain parts of a population from treatments.
Now, load up the X and y data.
🎓 Remember, this is supervised learning, and we need a named 'y' target.
In a new code cell, load the diabetes dataset by calling load_diabetes(). The input return_X_y=True signals that X will be a data matrix, and y olacak şekilde içe aktarıyorsunuz.
-
Veri matrisinin şeklini ve ilk öğesini göstermek için bazı yazdırma komutları ekleyin:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Geri aldığınız yanıt bir demettir. Demetin ilk iki değerini
Xandyolarak atıyorsunuz. Daha fazla bilgi için demetler hakkında bilgi edinin.Bu verinin 10 elemanlı diziler halinde şekillendirilmiş 442 öğeye sahip olduğunu görebilirsiniz:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Veri ve regresyon hedefi arasındaki ilişkiyi biraz düşünün. Doğrusal regresyon, X özelliği ile y hedef değişkeni arasındaki ilişkileri tahmin eder. Diyabet veri seti için hedefi dokümantasyonda bulabilir misiniz? Bu veri seti, hedefi göz önünde bulundurarak neyi gösteriyor?
-
Sonraki adım olarak, veri setinin 3. sütununu seçerek bir bölümünü çizmek için seçin. Bunu
:operator to select all rows, and then selecting the 3rd column using the index (2). You can also reshape the data to be a 2D array - as required for plotting - by usingreshape(n_rows, n_columns)kullanarak yapabilirsiniz. Parametrelerden biri -1 ise, ilgili boyut otomatik olarak hesaplanır.X = X[:, 2] X = X.reshape((-1,1))✅ Her zaman, verilerin şeklini kontrol etmek için yazdırabilirsiniz.
-
Artık çizilmeye hazır verileriniz olduğuna göre, bir makinenin bu veri setindeki sayılar arasında mantıklı bir ayrım yapıp yapamayacağını görebilirsiniz. Bunu yapmak için, hem verileri (X) hem de hedefi (y) test ve eğitim setlerine ayırmanız gerekir. Scikit-learn bunu yapmanın basit bir yolunu sunar; test verilerinizi belirli bir noktada bölebilirsiniz.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Artık modelinizi eğitmeye hazırsınız! Doğrusal regresyon modelini yükleyin ve
model.fit()kullanarak X ve y eğitim setlerinizle eğitin:model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()is a function you'll see in many ML libraries such as TensorFlow -
Then, create a prediction using test data, using the function
predict(). Bu, veri grupları arasındaki çizgiyi çizmek için kullanılacaktıry_pred = model.predict(X_test) -
Şimdi verileri bir grafikte göstermenin zamanı geldi. Matplotlib bu görev için çok kullanışlı bir araçtır. Tüm X ve y test verilerinin bir dağılım grafiğini oluşturun ve tahmini kullanarak modelin veri grupları arasındaki en uygun yere bir çizgi çizin.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()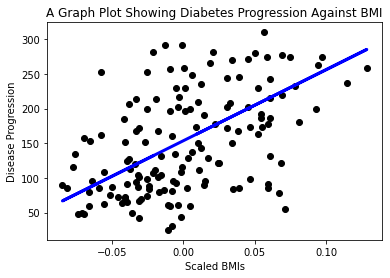
✅ Burada ne olduğunu biraz düşünün. Bir düz çizgi, birçok küçük veri noktası arasında geçiyor, ancak tam olarak ne yapıyor? Bu çizgiyi kullanarak yeni, görülmemiş bir veri noktasının grafiğin y ekseni ile ilişkili olarak nereye oturması gerektiğini tahmin edebilmeniz gerektiğini görebiliyor musunuz? Bu modelin pratik kullanımını kelimelerle ifade etmeye çalışın.
Tebrikler, ilk doğrusal regresyon modelinizi oluşturdunuz, onunla bir tahmin yaptınız ve bunu bir grafikte gösterdiniz!
🚀Meydan Okuma
Bu veri setinden farklı bir değişkeni çizin. İpucu: bu satırı düzenleyin: X = X[:,2]. Bu veri setinin hedefi göz önüne alındığında, diyabetin bir hastalık olarak ilerlemesi hakkında ne keşfedebiliyorsunuz?
Ders Sonrası Quiz
Gözden Geçirme ve Kendi Kendine Çalışma
Bu derste, basit doğrusal regresyon ile çalıştınız, tek değişkenli veya çok değişkenli regresyon yerine. Bu yöntemler arasındaki farklar hakkında biraz okuyun veya bu videoyu izleyin.
Regresyon kavramı hakkında daha fazla bilgi edinin ve bu teknikle hangi tür soruların yanıtlanabileceğini düşünün. Bu eğitimi alarak bilginizi derinleştirin.
Ödev
Feragatname: Bu belge, makine tabanlı AI çeviri hizmetleri kullanılarak çevrilmiştir. Doğruluğu sağlamak için çaba göstersek de, otomatik çevirilerin hata veya yanlışlıklar içerebileceğini lütfen unutmayın. Orijinal belgenin kendi dilindeki hali yetkili kaynak olarak kabul edilmelidir. Kritik bilgiler için profesyonel insan çevirisi önerilir. Bu çevirinin kullanımından kaynaklanan herhangi bir yanlış anlama veya yanlış yorumlamadan sorumlu değiliz.