|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Ustvarite detektor kakovosti sadja
Sketchnote avtorja Nitya Narasimhan. Kliknite sliko za večjo različico.
Ta video ponuja pregled storitve Azure Custom Vision, ki bo obravnavana v tej lekciji.

🎥 Kliknite zgornjo sliko za ogled videa
Kviz pred predavanjem
Uvod
Nedavni vzpon umetne inteligence (AI) in strojnega učenja (ML) razvijalcem danes ponuja širok spekter zmogljivosti. ML modeli se lahko naučijo prepoznavati različne stvari na slikah, vključno z nezrelim sadjem, kar se lahko uporablja v IoT napravah za pomoč pri sortiranju pridelkov bodisi med žetvijo bodisi med obdelavo v tovarnah ali skladiščih.
V tej lekciji se boste naučili o razvrščanju slik – uporabi ML modelov za razlikovanje med slikami različnih stvari. Naučili se boste, kako usposobiti klasifikator slik za razlikovanje med dobrim in slabim sadjem, bodisi nezrelim, prezrelim, poškodovanim ali gnijočim.
V tej lekciji bomo obravnavali:
- Uporaba AI in ML za sortiranje hrane
- Razvrščanje slik s pomočjo strojnega učenja
- Usposabljanje klasifikatorja slik
- Testiranje vašega klasifikatorja slik
- Ponovno usposabljanje vašega klasifikatorja slik
Uporaba AI in ML za sortiranje hrane
Prehranjevanje svetovnega prebivalstva je zahtevno, še posebej po ceni, ki omogoča dostopnost hrane za vse. Eden največjih stroškov je delo, zato se kmetje vse bolj obračajo k avtomatizaciji in orodjem, kot je IoT, za zmanjšanje stroškov dela. Ročna žetev je delovno intenzivna (in pogosto zelo naporna), zato jo v bogatejših državah vse bolj nadomeščajo stroji. Kljub prihrankom pri stroških uporabe strojev za žetev pa obstaja pomanjkljivost – sposobnost sortiranja hrane med žetvijo.
Vsi pridelki ne dozorijo enakomerno. Paradižniki, na primer, lahko še vedno vsebujejo nekaj zelenih plodov na trti, ko je večina že pripravljena za žetev. Čeprav je škoda, da se ti nezreli plodovi poberejo prezgodaj, je za kmeta ceneje in lažje pobrati vse s stroji in kasneje odstraniti nezrele pridelke.
✅ Oglejte si različne vrste sadja ali zelenjave, bodisi na bližnjih kmetijah, v vašem vrtu ali v trgovinah. Ali so vsi enako zreli, ali opazite razlike?
Vzpon avtomatizirane žetve je premaknil sortiranje pridelkov z žetve v tovarne. Hrana je potovala po dolgih tekočih trakovih, kjer so ekipe ljudi pregledovale pridelke in odstranjevale vse, kar ni ustrezalo zahtevanim standardom kakovosti. Žetev je bila cenejša zaradi strojev, vendar je še vedno obstajal strošek ročnega sortiranja hrane.
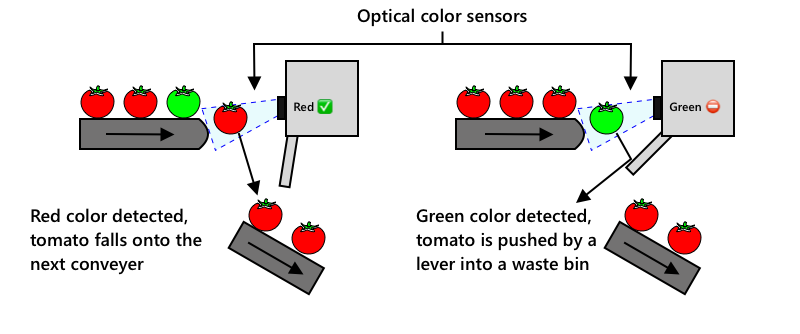
Naslednja evolucija je bila uporaba strojev za sortiranje, bodisi vgrajenih v kombajne ali v obratih za predelavo. Prva generacija teh strojev je uporabljala optične senzorje za zaznavanje barv, ki so upravljali aktuatorje za preusmerjanje zelenih paradižnikov v koš za odpadke z uporabo ročic ali zračnih sunkov, medtem ko so rdeči paradižniki nadaljevali svojo pot po mreži tekočih trakov.
V tem videu, ko paradižniki padajo z enega tekočega traku na drugega, so zeleni paradižniki zaznani in preusmerjeni v koš z uporabo ročic.
✅ Kakšne pogoje bi potrebovali v tovarni ali na polju, da bi ti optični senzorji pravilno delovali?
Najbolj napredni stroji za sortiranje zdaj izkoriščajo AI in ML, pri čemer uporabljajo modele, usposobljene za razlikovanje dobrih pridelkov od slabih, ne le na podlagi očitnih barvnih razlik, kot so zeleni paradižniki proti rdečim, temveč tudi na podlagi bolj subtilnih razlik v videzu, ki lahko kažejo na bolezni ali poškodbe.
Razvrščanje slik s pomočjo strojnega učenja
Tradicionalno programiranje vključuje uporabo podatkov in algoritma za pridobitev rezultata. Na primer, v zadnjem projektu ste uporabili GPS koordinate in geografsko ograjo, uporabili algoritem, ki ga je zagotovil Azure Maps, in dobili rezultat, ali je točka znotraj ali zunaj geografske ograje. Vnesete več podatkov, dobite več rezultatov.
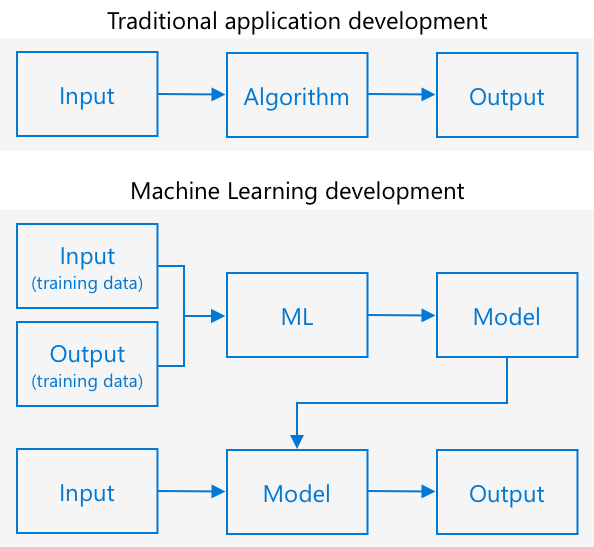
Strojno učenje to obrne – začnete s podatki in znanimi izhodi, algoritem strojnega učenja pa se uči iz podatkov. Nato lahko uporabite ta usposobljeni algoritem, imenovan model strojnega učenja ali model, in vnesete nove podatke za pridobitev novih rezultatov.
🎓 Proces, pri katerem se algoritem strojnega učenja uči iz podatkov, se imenuje usposabljanje. Vhodni podatki in znani izhodi se imenujejo podatki za usposabljanje.
Na primer, modelu bi lahko dali milijone slik nezrelih banan kot vhodne podatke za usposabljanje, z izhodom za usposabljanje nastavljenim na nezrelo, in milijone slik zrelih banan kot podatke za usposabljanje z izhodom nastavljenim na zrelo. Algoritem ML bi nato ustvaril model na podlagi teh podatkov. Nato bi temu modelu dali novo sliko banane, in napovedal bi, ali je nova slika zrela ali nezrela banana.
🎓 Rezultati ML modelov se imenujejo napovedi.

ML modeli ne dajejo binarnih odgovorov, temveč verjetnosti. Na primer, modelu bi lahko dali sliko banane, ki bi napovedal zrela z 99,7 % in nezrela z 0,3 %. Vaša koda bi nato izbrala najboljšo napoved in odločila, da je banana zrela.
Model ML, uporabljen za zaznavanje slik, kot je ta, se imenuje klasifikator slik – dobi označene slike in nato razvršča nove slike na podlagi teh oznak.
💁 To je poenostavitev, obstajajo pa tudi drugi načini za usposabljanje modelov, ki ne potrebujejo vedno označenih izhodov, kot je nenadzorovano učenje. Če želite izvedeti več o ML, si oglejte ML za začetnike, 24-lekcijski učni načrt o strojnem učenju.
Usposabljanje klasifikatorja slik
Za uspešno usposabljanje klasifikatorja slik potrebujete milijone slik. Kot se izkaže, ko imate enkrat klasifikator slik, usposobljen na milijonih ali milijardah različnih slik, ga lahko ponovno uporabite in ponovno usposobite z majhnim naborom slik ter dosežete odlične rezultate, s postopkom, imenovanim prenosno učenje.
🎓 Prenosno učenje je proces prenosa znanja iz obstoječega ML modela na nov model, ki temelji na novih podatkih.
Ko je klasifikator slik usposobljen za širok spekter slik, so njegove notranje funkcije odlične pri prepoznavanju oblik, barv in vzorcev. Prenosno učenje omogoča modelu, da uporabi to, kar se je že naučil pri prepoznavanju delov slik, za prepoznavanje novih slik.
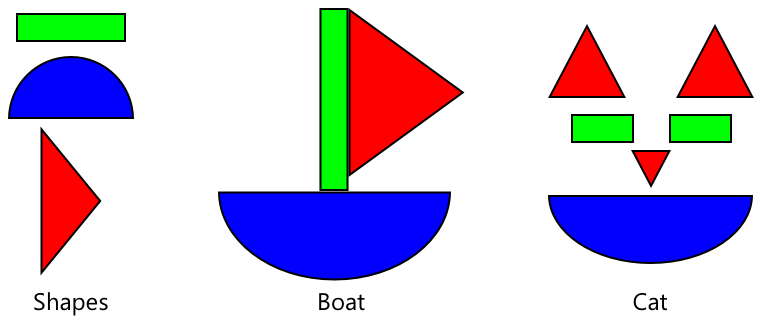
To si lahko predstavljate kot otroške knjige z oblikami, kjer lahko, ko prepoznate polkrog, pravokotnik in trikotnik, prepoznate jadrnico ali mačko, odvisno od konfiguracije teh oblik. Klasifikator slik lahko prepozna oblike, prenosno učenje pa ga nauči, katera kombinacija predstavlja ladjo ali mačko – ali zrelo banano.
Na voljo je širok spekter orodij, ki vam lahko pri tem pomagajo, vključno s storitvami v oblaku, ki vam omogočajo usposabljanje modela in njegovo uporabo prek spletnih API-jev.
💁 Usposabljanje teh modelov zahteva veliko računalniške moči, običajno prek grafičnih procesnih enot (GPU). Ista specializirana strojna oprema, zaradi katere igre na vašem Xboxu izgledajo neverjetno, se lahko uporablja tudi za usposabljanje modelov strojnega učenja. Z uporabo oblaka lahko najamete čas na zmogljivih računalnikih z GPU-ji za usposabljanje teh modelov, kar vam omogoča dostop do potrebne računalniške moči le za čas, ko jo potrebujete.
Custom Vision
Custom Vision je orodje v oblaku za usposabljanje klasifikatorjev slik. Omogoča vam usposabljanje klasifikatorja z uporabo le majhnega števila slik. Slike lahko naložite prek spletnega portala, spletnega API-ja ali SDK-ja, pri čemer vsaki sliki dodelite oznako, ki predstavlja klasifikacijo te slike. Nato usposobite model in ga preizkusite, da vidite, kako dobro deluje. Ko ste zadovoljni z modelom, lahko objavite njegove različice, ki so dostopne prek spletnega API-ja ali SDK-ja.
![]()
💁 Model Custom Vision lahko usposobite že s 5 slikami na klasifikacijo, vendar je več bolje. Boljše rezultate lahko dosežete z vsaj 30 slikami.
Custom Vision je del nabora AI orodij Microsofta, imenovanih Cognitive Services. To so AI orodja, ki jih je mogoče uporabljati bodisi brez usposabljanja bodisi z majhno količino usposabljanja. Vključujejo prepoznavanje in prevajanje govora, razumevanje jezika in analizo slik. Na voljo so z brezplačno stopnjo kot storitve v Azure.
💁 Brezplačna stopnja je več kot dovolj za ustvarjanje modela, njegovo usposabljanje in uporabo za razvoj. Več o omejitvah brezplačne stopnje si lahko preberete na strani z omejitvami in kvotami za Custom Vision na Microsoft Docs.
Naloga – ustvarite vir za kognitivne storitve
Za uporabo Custom Vision morate najprej ustvariti dva vira za kognitivne storitve v Azure z uporabo Azure CLI, enega za usposabljanje in enega za napovedovanje.
-
Ustvarite skupino virov za ta projekt z imenom
fruit-quality-detector. -
Uporabite naslednji ukaz za ustvarjanje brezplačnega vira za usposabljanje Custom Vision:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location>Zamenjajte
<location>z lokacijo, ki ste jo uporabili pri ustvarjanju skupine virov.To bo ustvarilo vir za usposabljanje Custom Vision v vaši skupini virov. Imenoval se bo
fruit-quality-detector-trainingin uporabljalF0sku, kar je brezplačna stopnja. Možnost--yespomeni, da se strinjate s pogoji in določili kognitivnih storitev.
💁 Uporabite
S0sku, če že imate brezplačen račun, ki uporablja katero koli od kognitivnih storitev.
-
Uporabite naslednji ukaz za ustvarjanje brezplačnega vira za napovedovanje Custom Vision:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location>Zamenjajte
<location>z lokacijo, ki ste jo uporabili pri ustvarjanju skupine virov.To bo ustvarilo vir za napovedovanje Custom Vision v vaši skupini virov. Imenoval se bo
fruit-quality-detector-predictionin uporabljalF0sku, kar je brezplačna stopnja. Možnost--yespomeni, da se strinjate s pogoji in določili kognitivnih storitev.
Naloga – ustvarite projekt klasifikatorja slik
-
Zaženite portal Custom Vision na CustomVision.ai in se prijavite z Microsoftovim računom, ki ste ga uporabili za svoj Azure račun.
-
Sledite oddelku za ustvarjanje novega projekta v hitrem začetku gradnje klasifikatorja na Microsoft Docs, da ustvarite nov projekt Custom Vision. Uporabniški vmesnik se lahko spremeni, zato so ti dokumenti vedno najbolj ažuren vir.
Poimenujte svoj projekt
fruit-quality-detector.Ko ustvarite svoj projekt, se prepričajte, da uporabljate vir
fruit-quality-detector-training, ki ste ga ustvarili prej. Uporabite vrsto projekta Classification, vrsto klasifikacije Multiclass in domeno Food.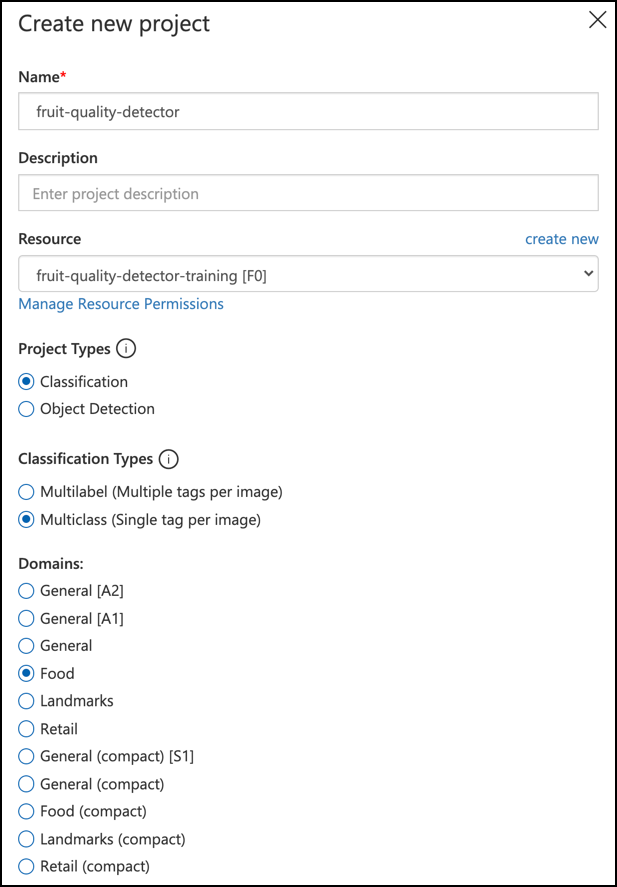
✅ Vzemite si čas za raziskovanje uporabniškega vmesnika Custom Vision za vaš klasifikator slik.
Naloga – usposobite svoj projekt klasifikatorja slik
Za usposabljanje klasifikatorja slik boste potrebovali več slik sadja, tako dobrega kot slabega, da jih označite kot dobre ali slabe, na primer zrele in prezrele banane. 💁 Ti klasifikatorji lahko razvrščajo slike česarkoli, zato, če nimate sadja različne kakovosti pri roki, lahko uporabite dve različni vrsti sadja ali mačke in pse! Vsaka slika naj prikazuje samo sadež, bodisi z enotnim ozadjem ali z raznolikimi ozadji. Poskrbite, da v ozadju ne bo ničesar, kar bi nakazovalo na zrelost ali nezrelost sadeža.
💁 Pomembno je, da ozadja niso specifična ali da ni predmetov, ki niso povezani z razvrščanjem oznak, saj bi lahko klasifikator razvrščal na podlagi ozadja. Obstajal je klasifikator za kožnega raka, ki je bil treniran na znamenjih, tako normalnih kot rakavih, pri čemer so bila rakava znamenja vedno fotografirana z ravnilom za merjenje velikosti. Izkazalo se je, da je bil klasifikator skoraj 100 % natančen pri prepoznavanju ravnil na slikah, ne pa rakavih znamenj.
Klasifikatorji slik delujejo pri zelo nizki ločljivosti. Na primer, Custom Vision lahko sprejme slike za treniranje in napovedovanje do velikosti 10240x10240, vendar model trenira in izvaja na slikah velikosti 227x227. Večje slike se zmanjšajo na to velikost, zato poskrbite, da predmet, ki ga klasificirate, zavzame velik del slike, sicer bo premajhen na manjši sliki, ki jo uporablja klasifikator.
-
Zberite slike za svoj klasifikator. Za treniranje klasifikatorja boste potrebovali vsaj 5 slik za vsako oznako, vendar več je bolje. Potrebovali boste tudi nekaj dodatnih slik za testiranje klasifikatorja. Te slike naj bodo različne slike istega predmeta. Na primer:
-
Uporabite 2 zrela banan in posnemite nekaj slik vsake iz različnih kotov, pri čemer posnemite vsaj 7 slik (5 za treniranje, 2 za testiranje), vendar idealno več.

-
Ponovite isti postopek z 2 nezrelimi bananami.
Imeti bi morali vsaj 10 slik za treniranje, z vsaj 5 zrelimi in 5 nezrelimi, ter 4 slike za testiranje, 2 zreli in 2 nezreli. Vaše slike naj bodo v formatu png ali jpeg, manjše od 6 MB. Če jih na primer ustvarite z iPhonom, so lahko slike visoke ločljivosti HEIC, zato jih bo treba pretvoriti in morda zmanjšati. Več slik je bolje, pri čemer naj bo število zrelih in nezrelih podobno.
Če nimate tako zrelih kot nezrelih sadežev, lahko uporabite različne sadeže ali katera koli dva predmeta, ki jih imate na voljo. Prav tako lahko najdete nekaj primerov slik v mapi images z zrelimi in nezrelimi bananami, ki jih lahko uporabite.
-
-
Sledite oddelku za nalaganje in označevanje slik v hitrem začetku za izdelavo klasifikatorja na Microsoftovi dokumentaciji, da naložite svoje slike za treniranje. Zrele sadeže označite kot
ripe, nezrele pa kotunripe.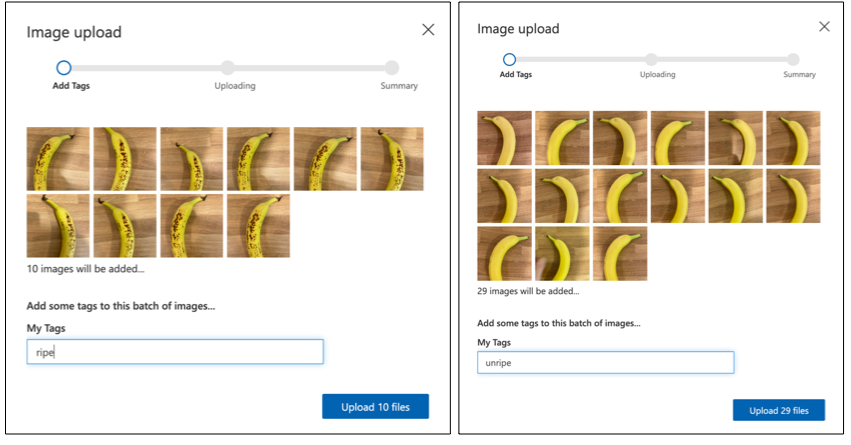
-
Sledite oddelku za treniranje klasifikatorja v hitrem začetku za izdelavo klasifikatorja na Microsoftovi dokumentaciji, da trenirate klasifikator slik na svojih naloženih slikah.
Ponujena vam bo izbira vrste treniranja. Izberite Quick Training.
Klasifikator se bo nato treniral. Treniranje bo trajalo nekaj minut.
🍌 Če se odločite pojesti svoje sadeže med treniranjem klasifikatorja, poskrbite, da imate najprej dovolj slik za testiranje!
Testirajte svoj klasifikator slik
Ko je vaš klasifikator treniran, ga lahko testirate tako, da mu podate novo sliko za klasifikacijo.
Naloga - testirajte svoj klasifikator slik
-
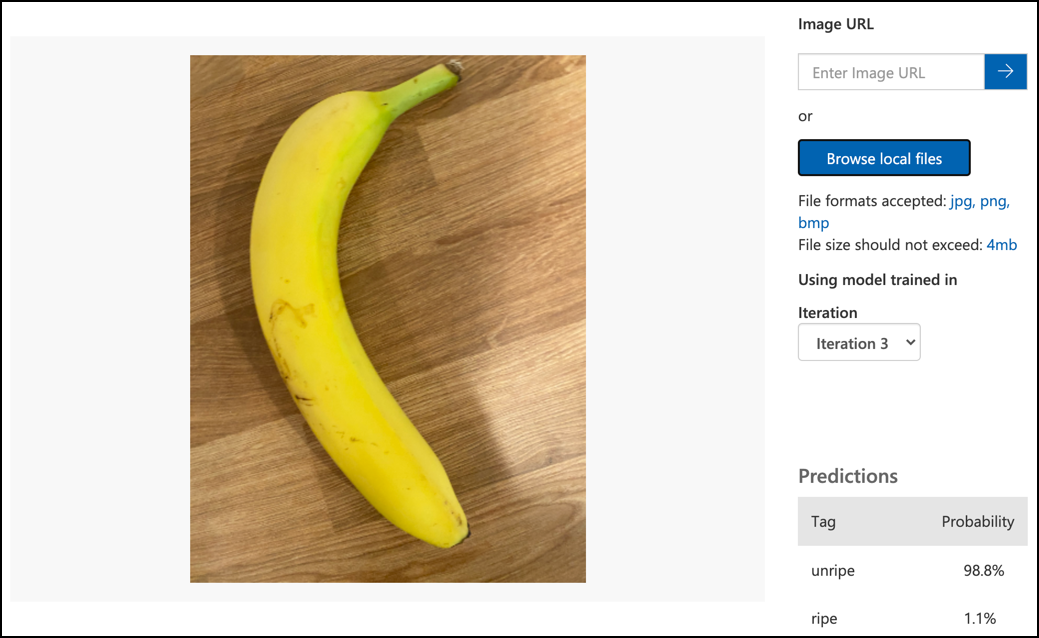
Sledite dokumentaciji za testiranje modela na Microsoftovi dokumentaciji, da testirate svoj klasifikator slik. Uporabite slike za testiranje, ki ste jih ustvarili prej, ne pa slik, ki ste jih uporabili za treniranje.
-
Preizkusite vse slike za testiranje, ki jih imate na voljo, in opazujte verjetnosti.
Ponovno trenirajte svoj klasifikator slik
Ko testirate svoj klasifikator, morda ne bo dal pričakovanih rezultatov. Klasifikatorji slik uporabljajo strojno učenje za napovedovanje, kaj je na sliki, na podlagi verjetnosti, da določene značilnosti slike pomenijo, da ustreza določeni oznaki. Ne razume, kaj je na sliki - ne ve, kaj je banana ali kaj naredi banano banano namesto čolna. Svoj klasifikator lahko izboljšate tako, da ga ponovno trenirate s slikami, pri katerih se zmoti.
Vsakič, ko naredite napoved z možnostjo hitrega testiranja, se slika in rezultati shranijo. Te slike lahko uporabite za ponovno treniranje svojega modela.
Naloga - ponovno trenirajte svoj klasifikator slik
-
Sledite dokumentaciji za uporabo napovedane slike za treniranje na Microsoftovi dokumentaciji, da ponovno trenirate svoj model, pri čemer uporabite pravilno oznako za vsako sliko.
-
Ko je vaš model ponovno treniran, ga testirajte na novih slikah.
🚀 Izziv
Kaj mislite, da bi se zgodilo, če bi uporabili sliko jagode z modelom, treniranim na bananah, ali sliko napihljive banane, ali osebo v kostumu banane, ali celo rumenega risanega lika, kot je nekdo iz Simpsonov?
Preizkusite in si oglejte napovedi. Slike za preizkus lahko najdete z uporabo iskanja slik Bing.
Kviz po predavanju
Pregled in samostojno učenje
- Ko ste trenirali svoj klasifikator, ste videli vrednosti za Precision, Recall in AP, ki ocenjujejo model, ki je bil ustvarjen. Preberite, kaj te vrednosti pomenijo, z uporabo oddelka za ocenjevanje klasifikatorja v hitrem začetku za izdelavo klasifikatorja na Microsoftovi dokumentaciji.
- Preberite, kako izboljšati svoj klasifikator z uporabo dokumentacije o izboljšanju modela Custom Vision na Microsoftovi dokumentaciji.
Naloga
Trenirajte svoj klasifikator za več vrst sadja in zelenjave
Omejitev odgovornosti:
Ta dokument je bil preveden z uporabo storitve za prevajanje z umetno inteligenco Co-op Translator. Čeprav si prizadevamo za natančnost, vas prosimo, da upoštevate, da lahko avtomatizirani prevodi vsebujejo napake ali netočnosti. Izvirni dokument v njegovem izvirnem jeziku je treba obravnavati kot avtoritativni vir. Za ključne informacije priporočamo profesionalni človeški prevod. Ne prevzemamo odgovornosti za morebitna napačna razumevanja ali napačne interpretacije, ki bi nastale zaradi uporabe tega prevoda.