16 KiB
Установите таймер и предоставьте голосовую обратную связь
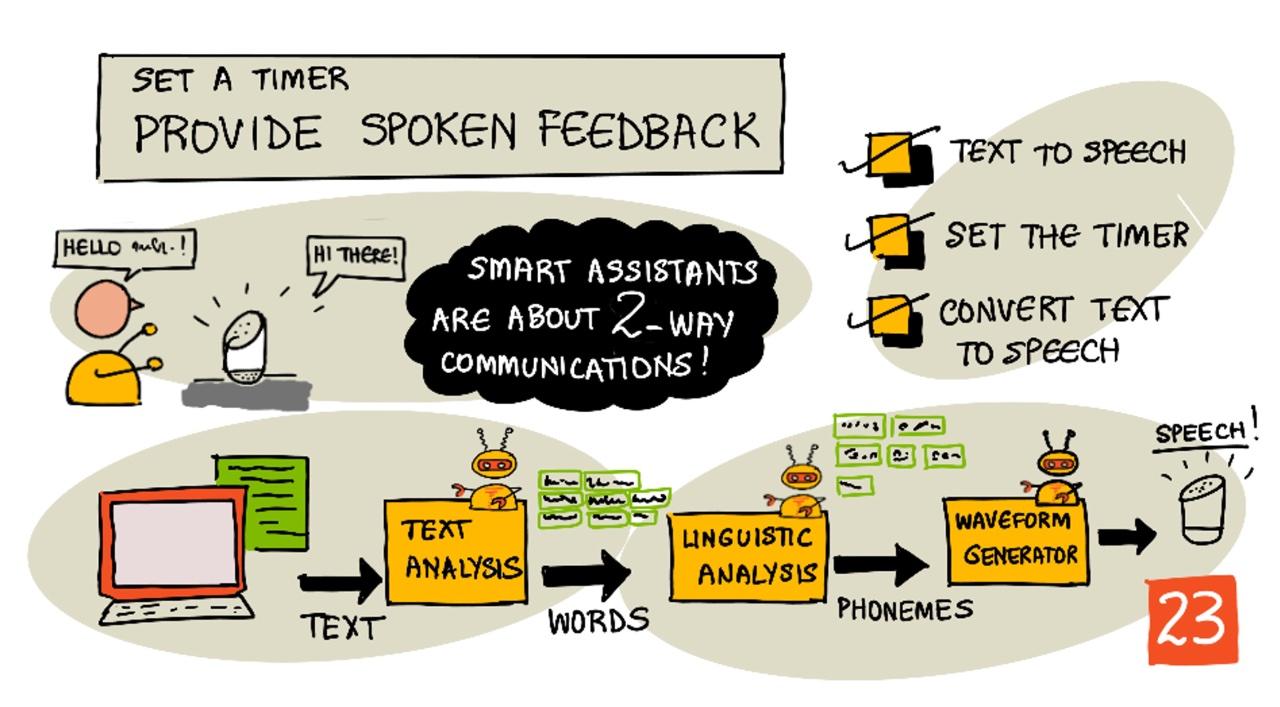
Скетчноут от Nitya Narasimhan. Нажмите на изображение, чтобы увидеть его в большем размере.
Викторина перед лекцией
Введение
Умные ассистенты — это не устройства для односторонней коммуникации. Вы говорите с ними, и они отвечают:
"Alexa, установи таймер на 3 минуты"
"Хорошо, ваш таймер установлен на 3 минуты"
В последних двух уроках вы узнали, как преобразовать речь в текст, а затем извлечь запрос на установку таймера из этого текста. В этом уроке вы научитесь устанавливать таймер на IoT-устройстве, отвечать пользователю голосом с подтверждением установки таймера и уведомлять его, когда таймер завершится.
В этом уроке мы рассмотрим:
Преобразование текста в речь
Преобразование текста в речь, как следует из названия, — это процесс преобразования текста в аудио, содержащее текст в виде произнесенных слов. Основной принцип заключается в разбиении слов текста на их составляющие звуки (называемые фонемами) и объединении аудио для этих звуков, либо с использованием заранее записанного аудио, либо с использованием аудио, сгенерированного моделями ИИ.

Системы преобразования текста в речь обычно включают 3 этапа:
- Анализ текста
- Лингвистический анализ
- Генерация звуковой волны
Анализ текста
Анализ текста включает в себя обработку предоставленного текста и преобразование его в слова, которые можно использовать для генерации речи. Например, если вы преобразуете "Hello world", анализ текста не требуется, эти два слова можно сразу преобразовать в речь. Однако, если у вас есть "1234", это может потребовать преобразования либо в слова "Одна тысяча двести тридцать четыре", либо "Один, два, три, четыре" в зависимости от контекста. Для "У меня 1234 яблока" это будет "Одна тысяча двести тридцать четыре", а для "Ребенок посчитал 1234" это будет "Один, два, три, четыре".
Слова, которые создаются, зависят не только от языка, но и от локали этого языка. Например, в американском английском 120 будет "One hundred twenty", а в британском английском — "One hundred and twenty", с использованием "and" после сотен.
✅ Некоторые другие примеры, требующие анализа текста, включают "in" как сокращение от дюйма и "st" как сокращение от святого или улицы. Можете ли вы придумать другие примеры в вашем языке, где слова неоднозначны без контекста?
После определения слов они отправляются на лингвистический анализ.
Лингвистический анализ
Лингвистический анализ разбивает слова на фонемы. Фонемы зависят не только от используемых букв, но и от других букв в слове. Например, в английском языке звук 'a' в словах 'car' и 'care' различается. В английском языке 44 различных фонемы для 26 букв алфавита, некоторые из которых используются разными буквами, например, одна и та же фонема используется в начале слов 'circle' и 'serpent'.
✅ Проведите исследование: Какие фонемы существуют в вашем языке?
После преобразования слов в фонемы этим фонемам требуется дополнительная информация для поддержки интонации, изменения тона или длительности в зависимости от контекста. Один из примеров — в английском языке повышение тона может использоваться для преобразования предложения в вопрос, повышение тона на последнем слове подразумевает вопрос.
Например, предложение "You have an apple" является утверждением, что у вас есть яблоко. Если тон повышается в конце, увеличиваясь на слове apple, это становится вопросом "You have an apple?", спрашивая, есть ли у вас яблоко. Лингвистический анализ должен использовать вопросительный знак в конце, чтобы решить, повышать ли тон.
После генерации фонем они отправляются на этап генерации звуковой волны для создания аудиовыхода.
Генерация звуковой волны
Первые электронные системы преобразования текста в речь использовали отдельные аудиозаписи для каждой фонемы, что приводило к очень монотонным, роботизированным голосам. Лингвистический анализ создавал фонемы, которые загружались из базы данных звуков и объединялись для создания аудио.
✅ Проведите исследование: Найдите аудиозаписи из ранних систем синтеза речи. Сравните их с современным синтезом речи, таким как тот, что используется в умных ассистентах.
Современная генерация звуковой волны использует модели машинного обучения, построенные с использованием глубокого обучения (очень большие нейронные сети, которые работают аналогично нейронам в мозге), чтобы создавать более естественные голоса, которые могут быть неотличимы от человеческих.
💁 Некоторые из этих моделей машинного обучения могут быть дообучены с использованием переноса обучения, чтобы звучать как реальные люди. Это означает, что использование голоса в качестве системы безопасности, что банки все чаще пытаются делать, больше не является хорошей идеей, так как любой, у кого есть запись вашего голоса длиной в несколько минут, может вас подделать.
Эти крупные модели машинного обучения обучаются объединять все три этапа в единые системы синтеза речи.
Установка таймера
Чтобы установить таймер, вашему IoT-устройству нужно вызвать REST-эндпоинт, который вы создали с использованием серверного кода, а затем использовать полученное количество секунд для установки таймера.
Задача — вызов серверной функции для получения времени таймера
Следуйте соответствующему руководству, чтобы вызвать REST-эндпоинт с вашего IoT-устройства и установить таймер на необходимое время:
Преобразование текста в речь
Тот же сервис преобразования речи, который вы использовали для преобразования речи в текст, можно использовать для преобразования текста обратно в речь, и это можно воспроизвести через динамик на вашем IoT-устройстве. Текст для преобразования отправляется в сервис преобразования речи вместе с типом требуемого аудио (например, частотой дискретизации), и возвращаются бинарные данные, содержащие аудио.
При отправке этого запроса вы используете Speech Synthesis Markup Language (SSML), основанный на XML язык разметки для приложений синтеза речи. Он определяет не только текст для преобразования, но и язык текста, голос для использования, а также может использоваться для определения скорости, громкости и тона для некоторых или всех слов в тексте.
Например, этот SSML определяет запрос на преобразование текста "Ваш таймер на 3 минуты и 5 секунд установлен" в речь с использованием британского английского голоса en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Большинство систем преобразования текста в речь имеют несколько голосов для разных языков с соответствующими акцентами, например, британский английский голос с английским акцентом и новозеландский английский голос с новозеландским акцентом.
Задача — преобразование текста в речь
Пройдите соответствующее руководство, чтобы преобразовать текст в речь с использованием вашего IoT-устройства:
- Arduino - Wio Terminal
- Одноплатный компьютер - Raspberry Pi
- Одноплатный компьютер - Виртуальное устройство
🚀 Задание
SSML позволяет изменять, как произносятся слова, например, добавлять акцент на определенные слова, добавлять паузы или изменять тон. Попробуйте использовать эти возможности, отправляя разные SSML с вашего IoT-устройства и сравнивая результаты. Вы можете узнать больше о SSML, включая способы изменения произношения слов, в спецификации Speech Synthesis Markup Language (SSML) Version 1.1 от World Wide Web Consortium.
Викторина после лекции
Обзор и самостоятельное изучение
- Узнайте больше о синтезе речи на странице о синтезе речи в Википедии
- Узнайте больше о способах, которыми преступники используют синтез речи для кражи, в статье BBC о фальшивых голосах, помогающих киберпреступникам красть деньги
- Узнайте больше о рисках для актеров озвучивания из-за синтезированных версий их голосов в статье Vice о судебном иске TikTok, подчеркивающем, как ИИ вредит актерам озвучивания
Задание
Отказ от ответственности:
Этот документ был переведен с помощью сервиса автоматического перевода Co-op Translator. Несмотря на наши усилия обеспечить точность, автоматические переводы могут содержать ошибки или неточности. Оригинальный документ на его родном языке следует считать авторитетным источником. Для получения критически важной информации рекомендуется профессиональный перевод человеком. Мы не несем ответственности за любые недоразумения или неправильные интерпретации, возникающие в результате использования данного перевода.