|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
| pi-audio.md | 3 weeks ago | |
| pi-microphone.md | 3 weeks ago | |
| pi-speech-to-text.md | 3 weeks ago | |
| virtual-device-audio.md | 3 weeks ago | |
| virtual-device-microphone.md | 3 weeks ago | |
| virtual-device-speech-to-text.md | 3 weeks ago | |
| wio-terminal-audio.md | 3 weeks ago | |
| wio-terminal-microphone.md | 3 weeks ago | |
| wio-terminal-speech-to-text.md | 3 weeks ago | |
README.md
Atpažinkite kalbą su IoT įrenginiu
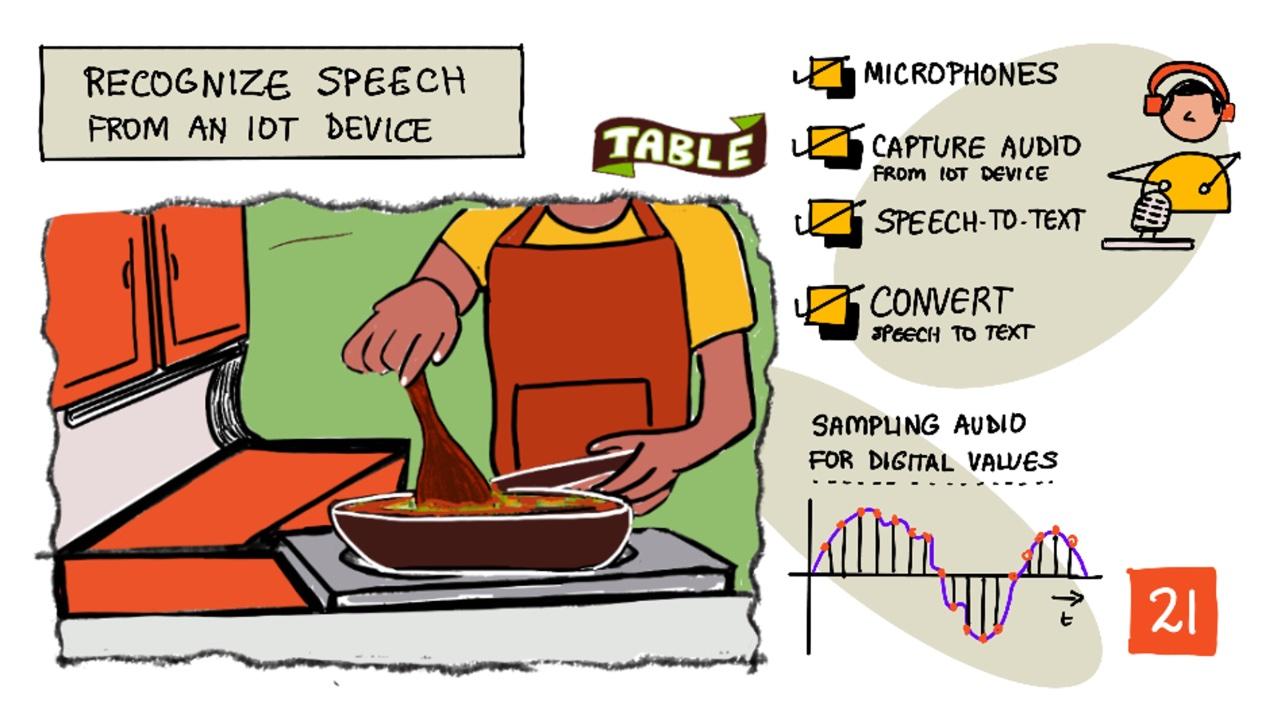
Sketchnote sukūrė Nitya Narasimhan. Spustelėkite paveikslėlį, kad pamatytumėte didesnę versiją.
Šiame vaizdo įraše pateikiama „Azure“ kalbos paslaugos apžvalga – tema, kuri bus aptarta šioje pamokoje:

🎥 Spustelėkite paveikslėlį aukščiau, kad peržiūrėtumėte vaizdo įrašą
Klausimynas prieš paskaitą
Įvadas
„Alexa, nustatyk 12 minučių laikmatį.“
„Alexa, koks laikmačio statusas?“
„Alexa, nustatyk 8 minučių laikmatį, pavadintą garinti brokolius.“
Išmanieji įrenginiai tampa vis labiau paplitę. Ne tik kaip išmanieji garsiakalbiai, tokie kaip „HomePods“, „Echos“ ir „Google Homes“, bet ir integruoti į mūsų telefonus, laikrodžius, netgi šviestuvus ir termostatus.
💁 Mano namuose yra bent 19 įrenginių su balso asistentais, ir tai tik tie, apie kuriuos žinau!
Balso valdymas padidina prieinamumą, leidžiant žmonėms su ribotu judėjimu sąveikauti su įrenginiais. Nesvarbu, ar tai yra nuolatinė negalia, pavyzdžiui, gimimas be rankų, laikina negalia, pavyzdžiui, sulaužytos rankos, ar tiesiog užimtos rankos dėl apsipirkimo ar mažų vaikų, galimybė valdyti namus balsu, o ne rankomis, atveria naujas prieigos galimybes. Šaukti „Ei, Siri, uždaryk garažo duris“, kai keičiate kūdikį ir tvarkotės su nepaklusniu mažyliu, gali būti nedidelis, bet efektyvus gyvenimo patobulinimas.
Viena iš populiariausių balso asistentų naudojimo sričių yra laikmačių nustatymas, ypač virtuvės laikmačių. Galimybė nustatyti kelis laikmačius vien balsu yra didelė pagalba virtuvėje – nereikia sustoti minkant tešlą, maišant sriubą ar valyti rankas nuo koldūnų įdaro, kad galėtumėte naudoti fizinį laikmatį.
Šioje pamokoje sužinosite, kaip įdiegti balso atpažinimą į IoT įrenginius. Sužinosite apie mikrofonus kaip jutiklius, kaip užfiksuoti garsą iš mikrofono, prijungto prie IoT įrenginio, ir kaip naudoti dirbtinį intelektą, kad konvertuotumėte girdimą garsą į tekstą. Visame projekte sukursite išmanų virtuvės laikmatį, galintį nustatyti laikmačius balsu keliomis kalbomis.
Šioje pamokoje aptarsime:
- Mikrofonai
- Garso fiksavimas iš jūsų IoT įrenginio
- Kalbos konvertavimas į tekstą
- Kalbos konvertavimo į tekstą procesas
Mikrofonai
Mikrofonai yra analoginiai jutikliai, kurie garso bangas paverčia elektros signalais. Oro vibracijos sukelia mikrofono komponentų judėjimą, kuris sukelia nedidelius elektros signalų pokyčius. Šie pokyčiai sustiprinami, kad būtų sukurtas elektros išėjimas.
Mikrofonų tipai
Mikrofonai būna įvairių tipų:
-
Dinaminiai – Dinaminiai mikrofonai turi magnetą, pritvirtintą prie judančios diafragmos, kuri juda vielos ritėje, sukurdama elektros srovę. Tai yra priešingybė daugumai garsiakalbių, kurie naudoja elektros srovę, kad judintų magnetą vielos ritėje, judindami diafragmą, kad sukurtų garsą. Tai reiškia, kad garsiakalbiai gali būti naudojami kaip dinaminiai mikrofonai, o dinaminiai mikrofonai – kaip garsiakalbiai. Įrenginiuose, tokiuose kaip interkomai, kur vartotojas arba klausosi, arba kalba, bet ne abu, vienas įrenginys gali veikti kaip garsiakalbis ir mikrofonas.
Dinaminiai mikrofonai nereikalauja energijos, elektros signalas sukuriamas vien tik mikrofono.

-
Juostiniai – Juostiniai mikrofonai yra panašūs į dinaminius mikrofonus, išskyrus tai, kad vietoj diafragmos jie turi metalinę juostelę. Ši juostelė juda magnetiniame lauke, generuodama elektros srovę. Kaip ir dinaminiai mikrofonai, juostiniai mikrofonai nereikalauja energijos.

-
Kondensatoriniai – Kondensatoriniai mikrofonai turi ploną metalinę diafragmą ir fiksuotą metalinę plokštelę. Elektrinė energija taikoma abiem, ir kai diafragma vibruoja, statinis krūvis tarp plokštelių keičiasi, generuodamas signalą. Kondensatoriniai mikrofonai reikalauja energijos – vadinamos fantomine energija.
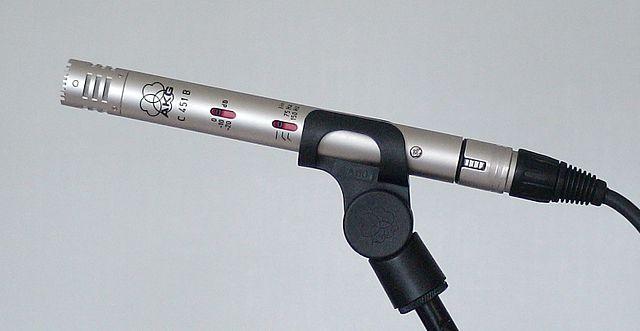
-
MEMS – Mikroelektromechaninės sistemos mikrofonai, arba MEMS, yra mikrofonai ant mikroschemos. Jie turi slėgiui jautrią diafragmą, išgraviruotą ant silicio mikroschemos, ir veikia panašiai kaip kondensatoriniai mikrofonai. Šie mikrofonai gali būti labai maži ir integruoti į grandines.

Aukščiau esančiame paveikslėlyje mikroschema, pažymėta LEFT, yra MEMS mikrofonas su mažyte diafragma, mažesne nei milimetras.
✅ Atlikite tyrimą: Kokius mikrofonus turite aplink save – kompiuteryje, telefone, ausinėse ar kituose įrenginiuose? Kokio tipo mikrofonai jie yra?
Skaitmeninis garsas
Garsas yra analoginis signalas, turintis labai smulkią informaciją. Norint konvertuoti šį signalą į skaitmeninį, garsas turi būti mėginiuojamas tūkstančius kartų per sekundę.
🎓 Mėginiuojimas – tai garso signalo konvertavimas į skaitmeninę vertę, kuri atspindi signalą tam tikru momentu.
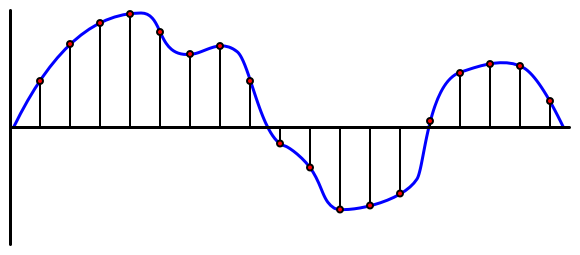
Skaitmeninis garsas mėginiuojamas naudojant impulsų kodavimo moduliaciją (PCM). PCM apima signalo įtampos nuskaitymą ir artimiausios diskretinės vertės pasirinkimą pagal apibrėžtą dydį.
💁 PCM galite laikyti jutiklio versija impulsų pločio moduliacijai (PWM). PWM buvo aptarta 3 pamokoje pradedančiųjų projekte. PCM apima analoginio signalo konvertavimą į skaitmeninį, PWM apima skaitmeninio signalo konvertavimą į analoginį.
Pavyzdžiui, dauguma muzikos transliavimo paslaugų siūlo 16 bitų arba 24 bitų garsą. Tai reiškia, kad jie konvertuoja įtampą į vertę, kuri telpa į 16 bitų arba 24 bitų sveikąjį skaičių. 16 bitų garsas telpa į skaičių diapazoną nuo -32,768 iki 32,767, 24 bitų – nuo −8,388,608 iki 8,388,607. Kuo daugiau bitų, tuo mėginys artimesnis tam, ką iš tikrųjų girdi mūsų ausys.
💁 Galbūt girdėjote apie 8 bitų garsą, dažnai vadinamą LoFi. Tai garsas, mėginiuojamas naudojant tik 8 bitus, taigi -128 iki 127. Pirmasis kompiuterinis garsas buvo apribotas iki 8 bitų dėl techninės įrangos apribojimų, todėl tai dažnai matoma retro žaidimuose.
Šie mėginiai imami tūkstančius kartų per sekundę, naudojant gerai apibrėžtus mėginių ėmimo dažnius, matuojamus KHz (tūkstančiai nuskaitymų per sekundę). Muzikos transliavimo paslaugos naudoja 48KHz daugumai garso, tačiau kai kurie „be nuostolių“ garsai naudoja iki 96KHz ar net 192KHz. Kuo didesnis mėginių ėmimo dažnis, tuo artimesnis originalui garsas, iki tam tikro taško. Yra diskusijų, ar žmonės gali atskirti skirtumą virš 48KHz.
✅ Atlikite tyrimą: Jei naudojate muzikos transliavimo paslaugą, kokį mėginių ėmimo dažnį ir dydį ji naudoja? Jei naudojate CD, koks yra CD garso mėginių ėmimo dažnis ir dydis?
Yra daugybė skirtingų garso duomenų formatų. Tikriausiai girdėjote apie mp3 failus – garso duomenis, kurie yra suspausti, kad būtų mažesni, neprarandant kokybės. Nesuspaustas garsas dažnai saugomas kaip WAV failas – tai failas su 44 baitų antraštės informacija, po kurios eina neapdoroti garso duomenys. Antraštėje yra informacija, tokia kaip mėginių ėmimo dažnis (pvz., 16000 16KHz) ir mėginių dydis (16 16 bitų), bei kanalų skaičius. Po antraštės WAV faile yra neapdoroti garso duomenys.
🎓 Kanalai reiškia, kiek skirtingų garso srautų sudaro garsą. Pavyzdžiui, stereo garsui su kairiuoju ir dešiniuoju kanalais būtų 2 kanalai. Namų kino sistemos 7.1 erdvinio garso atveju tai būtų 8 kanalai.
Garso duomenų dydis
Garso duomenys yra gana dideli. Pavyzdžiui, fiksuojant nesuspaustą 16 bitų garsą 16KHz dažniu (pakankamas dažnis naudojimui su kalbos į tekstą modeliu), reikia 32KB duomenų kiekvienai garso sekundei:
- 16 bitų reiškia 2 baitus kiekvienam mėginiui (1 baitas yra 8 bitai).
- 16KHz yra 16,000 mėginių per sekundę.
- 16,000 x 2 baitai = 32,000 baitų per sekundę.
Tai atrodo kaip nedidelis duomenų kiekis, tačiau jei naudojate mikrovaldiklį su ribota atmintimi, tai gali būti daug. Pavyzdžiui, „Wio Terminal“ turi 192KB atminties, ir ji turi saugoti programos kodą ir kintamuosius. Net jei jūsų programos kodas būtų labai mažas, negalėtumėte užfiksuoti daugiau nei 5 sekundžių garso.
Mikrovaldikliai gali pasiekti papildomą saugyklą, pvz., SD korteles ar „flash“ atmintį. Kurdami IoT įrenginį, kuris fiksuoja garsą, turėsite užtikrinti, kad ne tik turite papildomą saugyklą, bet ir jūsų kodas rašo užfiksuotą garsą tiesiai į saugyklą, o siunčiant jį į debesį, srautu perduodate iš saugyklos į interneto užklausą. Tokiu būdu galite išvengti atminties išsekimo, bandydami laikyti visą garso duomenų bloką atmintyje vienu metu.
Garso fiksavimas iš jūsų IoT įrenginio
Jūsų IoT įrenginys gali būti prijungtas prie mikrofono, kad užfiksuotų garsą, paruoštą konvertavimui į tekstą. Jis taip pat gali būti prijungtas prie garsiakalbių, kad atkurtų garsą. Vėlesnėse pamokose tai bus naudojama garso grįžtamajam ryšiui, tačiau dabar naudinga nustatyti garsiakalbius, kad išbandytumėte mikrofoną.
Užduotis – konfigūruokite mikrofoną ir garsiakalbius
Atlikite atitinkamą vadovą, kad sukonfigūruotumėte mikrofoną ir garsiakalbius savo IoT įrenginiui:
- Arduino – Wio Terminal
- Vieno plokštės kompiuteris – Raspberry Pi
- Vieno plokštės kompiuteris – Virtualus įrenginys
Užduotis – fiksuokite garsą
Atlikite atitinkamą vadovą, kad užfiksuotumėte garsą savo IoT įrenginyje:
- Arduino – Wio Terminal
- Vieno plokštės kompiuteris – Raspberry Pi
- Vieno plokštės kompiuteris – Virtualus įrenginys
Kalbos konvertavimas į tekstą
Kalbos konvertavimas į tekstą, arba kalbos atpažinimas, apima dirbtinio intelekto naudojimą, kad garso signale esančius žodžius paverstų tekstu.
Kalbos atpažinimo modeliai
Norint konvertuoti kalbą į tekstą, garso signalo mėginiai grupuojami ir perduodami mašininio mokymosi modeliui, pagrįstam pasikartojančiu neuroniniu tinklu (RNN). Tai yra mašininio mokymosi modelio tipas, kuris gali naudoti ankstesnius duomenis, kad priimtų sprendimą apie gaunamus duomenis. Pavyzdžiui, RNN galėtų aptikti vieną garso mėginių bloką kaip garsą „Hel“, o kai gauna kitą, kuris, jo manymu, yra garsas „lo“, jis gali sujungti tai su ankstesniu garsu, nustatyti, kad „Hello“ yra galiojantis žodis, ir pasirinkti jį kaip rezultatą.
ML modeliai visada priima vienodo dydžio duomenis kiekvieną kartą. Vaizdo klasifikatorius, kurį sukūrėte ankstesnėje pamokoje, keičia vaizdų dydį į fiksuotą dydį ir apdoroja juos. Tas pats su kalbos modeliais – jie turi apdoroti fiksuoto dydžio garso fragmentus. Kalbos modeliai turi sugebėti sujungti kelių prognozių rezultatus, kad gautų atsakymą, leidžiantį atskirti „Hi“ nuo „Highway“ arba „flock“ nuo „floccinaucinihilipilification“.
Kalbos modeliai taip pat yra pakankamai pažangūs, kad suprastų kontekstą ir galėtų taisyti aptiktus žodžius, kai apdorojama daugiau garsų. Pavyzdžiui, jei sakote „Aš nuėjau į parduotuvę nusipirkti dviejų bananų ir obuolio taip pat“, jūs naudotumėte tris žodžius, kurie skamba vienodai, bet yra rašomi skirtingai – „to“, „two“ ir „too“. Kalbos modeliai gali suprasti kontekstą ir naudoti tinkamą žodžio rašybą. 💁 Kai kurios kalbos paslaugos leidžia pritaikyti nustatymus, kad jos geriau veiktų triukšmingoje aplinkoje, pavyzdžiui, gamyklose, arba su specifiniais pramonės žodžiais, tokiais kaip cheminių medžiagų pavadinimai. Šie pritaikymai yra mokomi pateikiant pavyzdinį garsą ir jo transkripciją, o jų veikimas grindžiamas perkėlimo mokymusi – taip pat, kaip ankstesnėje pamokoje mokėte vaizdų klasifikatorių naudodami tik kelis vaizdus.
Privatumas
Naudojant kalbos atpažinimą vartotojų IoT įrenginiuose, privatumas yra nepaprastai svarbus. Šie įrenginiai nuolat klausosi garso, todėl kaip vartotojas nenorite, kad viskas, ką sakote, būtų siunčiama į debesį ir paverčiama tekstu. Tai ne tik sunaudoja daug interneto pralaidumo, bet ir turi didelių privatumo pasekmių, ypač kai kai kurie išmaniųjų įrenginių gamintojai atsitiktinai pasirenka garso įrašus, kad žmonės galėtų patikrinti sugeneruotą tekstą ir padėti tobulinti jų modelį.
Jūs norite, kad jūsų išmanusis įrenginys siųstų garsą į debesį apdorojimui tik tada, kai jį naudojate, o ne kai jis girdi garsą jūsų namuose, garsą, kuris gali apimti privačius susitikimus ar intymias sąveikas. Dauguma išmaniųjų įrenginių veikia su aktyvavimo žodžiu, pagrindine fraze, tokia kaip „Alexa“, „Hey Siri“ arba „OK Google“, kuri priverčia įrenginį „atsibusti“ ir klausytis, ką sakote, kol aptinka pauzę jūsų kalboje, nurodydama, kad baigėte kalbėti su įrenginiu.
🎓 Aktyvavimo žodžio aptikimas taip pat vadinamas raktažodžio aptikimu arba raktažodžio atpažinimu.
Šie aktyvavimo žodžiai aptinkami pačiame įrenginyje, o ne debesyje. Šie išmanieji įrenginiai turi mažus AI modelius, kurie veikia įrenginyje ir klausosi aktyvavimo žodžio, o kai jis aptinkamas, pradeda transliuoti garsą į debesį atpažinimui. Šie modeliai yra labai specializuoti ir tiesiog klausosi aktyvavimo žodžio.
💁 Kai kurios technologijų kompanijos prideda daugiau privatumo savo įrenginiams ir dalį kalbos į tekstą konvertavimo atlieka pačiame įrenginyje. Apple paskelbė, kad kaip dalis jų 2021 m. iOS ir macOS atnaujinimų jie palaikys kalbos į tekstą konvertavimą įrenginyje ir galės apdoroti daugelį užklausų be debesies naudojimo. Tai įmanoma dėl galingų procesorių jų įrenginiuose, kurie gali vykdyti ML modelius.
✅ Kokios, jūsų manymu, yra privatumo ir etikos pasekmės, susijusios su garso, siunčiamo į debesį, saugojimu? Ar šis garsas turėtų būti saugomas, ir jei taip, kaip? Ar manote, kad įrašų naudojimas teisėsaugai yra geras privatumo praradimo kompromisas?
Aktyvavimo žodžio aptikimas paprastai naudoja techniką, vadinamą TinyML, tai yra ML modelių konvertavimas, kad jie galėtų veikti mikrovaldikliuose. Šie modeliai yra mažo dydžio ir sunaudoja labai mažai energijos.
Kad išvengtumėte aktyvavimo žodžio modelio mokymo ir naudojimo sudėtingumo, išmanusis laikmatis, kurį kuriate šioje pamokoje, naudos mygtuką kalbos atpažinimui įjungti.
💁 Jei norite pabandyti sukurti aktyvavimo žodžio aptikimo modelį, kuris veiktų Wio Terminal arba Raspberry Pi, peržiūrėkite šį pamoką apie atsakymą į jūsų balsą iš Edge Impulse. Jei norite tai atlikti savo kompiuteryje, galite išbandyti pradžios vadovą apie pasirinktinius raktažodžius Microsoft dokumentacijoje.
Kalbos konvertavimas į tekstą
![]()
Kaip ir vaizdų klasifikavime ankstesniame projekte, yra iš anksto sukurtų AI paslaugų, kurios gali paimti kalbą kaip garso failą ir paversti ją tekstu. Viena iš tokių paslaugų yra Kalbos Paslauga, dalis Cognitive Services, iš anksto sukurtų AI paslaugų, kurias galite naudoti savo programose.
Užduotis - sukonfigūruoti kalbos AI resursą
-
Sukurkite resursų grupę šiam projektui, pavadintą
smart-timer. -
Naudokite šią komandą, kad sukurtumėte nemokamą kalbos resursą:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Pakeiskite
<location>vieta, kurią naudojote kurdami resursų grupę. -
Jums reikės API rakto, kad galėtumėte pasiekti kalbos resursą iš savo kodo. Paleiskite šią komandą, kad gautumėte raktą:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableNukopijuokite vieną iš raktų.
Užduotis - konvertuoti kalbą į tekstą
Sekite atitinkamą vadovą, kad konvertuotumėte kalbą į tekstą savo IoT įrenginyje:
- Arduino - Wio Terminal
- Vieno plokštės kompiuteris - Raspberry Pi
- Vieno plokštės kompiuteris - virtualus įrenginys
🚀 Iššūkis
Kalbos atpažinimas egzistuoja jau ilgą laiką ir nuolat tobulėja. Ištirkite dabartines galimybes ir palyginkite, kaip jos evoliucionavo laikui bėgant, įskaitant tai, kaip tiksliai mašininės transkripcijos lyginamos su žmogaus.
Ką, jūsų manymu, ateitis žada kalbos atpažinimui?
Po paskaitos testas
Apžvalga ir savarankiškas mokymasis
- Perskaitykite apie skirtingus mikrofonų tipus ir kaip jie veikia straipsnyje koks skirtumas tarp dinaminio ir kondensatoriaus mikrofonų Musician's HQ.
- Skaitykite daugiau apie Cognitive Services kalbos paslaugą kalbos paslaugos dokumentacijoje Microsoft Docs.
- Skaitykite apie raktažodžių aptikimą raktažodžių atpažinimo dokumentacijoje Microsoft Docs.
Užduotis
Atsakomybės apribojimas:
Šis dokumentas buvo išverstas naudojant AI vertimo paslaugą Co-op Translator. Nors siekiame tikslumo, prašome atkreipti dėmesį, kad automatiniai vertimai gali turėti klaidų ar netikslumų. Originalus dokumentas jo gimtąja kalba turėtų būti laikomas autoritetingu šaltiniu. Kritinei informacijai rekomenduojama naudoti profesionalų žmogaus vertimą. Mes neprisiimame atsakomybės už nesusipratimus ar klaidingus interpretavimus, atsiradusius dėl šio vertimo naudojimo.