9.7 KiB
Imposta un timer e fornisci feedback vocale
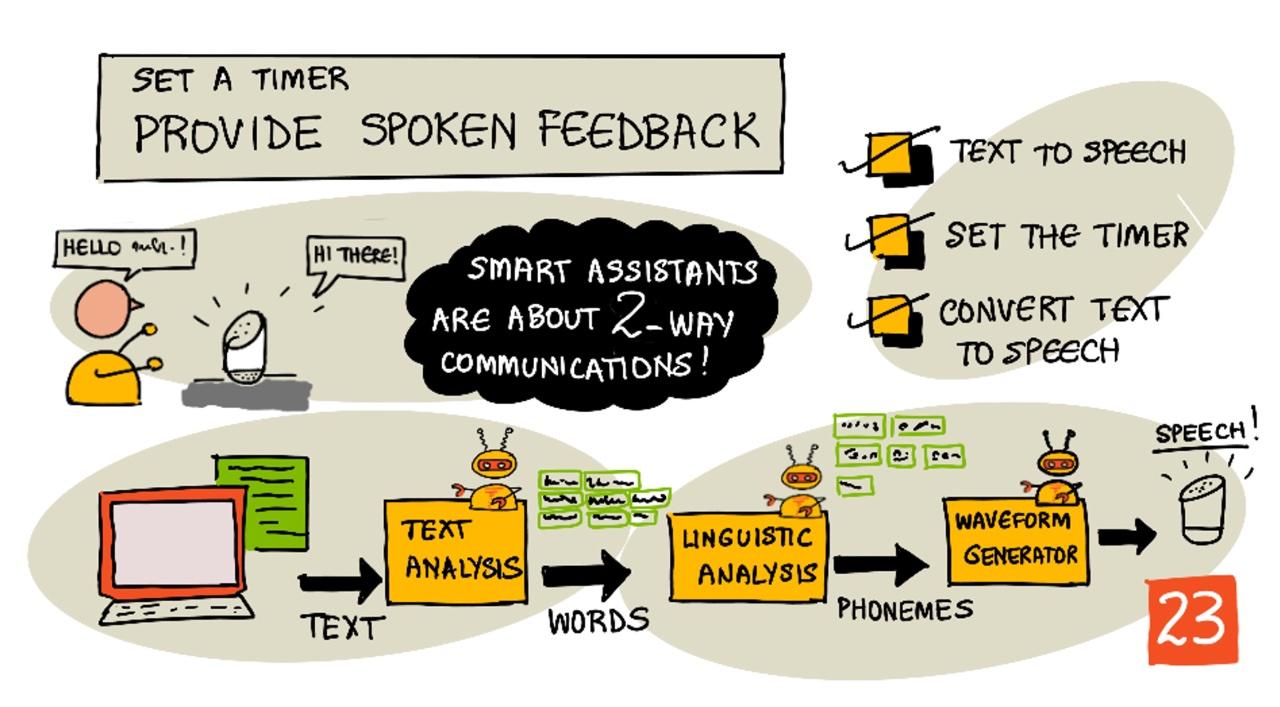
Illustrazione di Nitya Narasimhan. Clicca sull'immagine per una versione più grande.
Quiz preliminare alla lezione
Introduzione
Gli assistenti intelligenti non sono dispositivi di comunicazione unidirezionale. Parli con loro e loro rispondono:
"Alexa, imposta un timer di 3 minuti"
"Ok, il tuo timer è impostato per 3 minuti"
Nelle ultime 2 lezioni hai imparato come trasformare il parlato in testo e poi estrarre una richiesta di impostazione del timer da quel testo. In questa lezione imparerai come impostare il timer sul dispositivo IoT, rispondendo all'utente con parole pronunciate che confermano il timer e avvisandolo quando il timer è terminato.
In questa lezione tratteremo:
Da testo a parlato
La conversione da testo a parlato, come suggerisce il nome, è il processo di trasformazione del testo in audio che contiene le parole pronunciate. Il principio di base è suddividere le parole del testo nei loro suoni costituenti (noti come fonemi) e assemblare l'audio per quei suoni, utilizzando audio pre-registrato o generato da modelli di intelligenza artificiale.

I sistemi di conversione da testo a parlato generalmente hanno 3 fasi:
- Analisi del testo
- Analisi linguistica
- Generazione della forma d'onda
Analisi del testo
L'analisi del testo consiste nel prendere il testo fornito e convertirlo in parole che possono essere utilizzate per generare il parlato. Ad esempio, se converti "Ciao mondo", non è necessaria alcuna analisi del testo, le due parole possono essere trasformate in parlato. Se hai "1234", tuttavia, potrebbe essere necessario convertirlo in "Mille duecentotrentaquattro" o "Uno, due, tre, quattro" a seconda del contesto. Per "Ho 1234 mele", sarebbe "Mille duecentotrentaquattro", ma per "Il bambino ha contato 1234" sarebbe "Uno, due, tre, quattro".
Le parole create variano non solo per la lingua, ma anche per il contesto culturale di quella lingua. Ad esempio, in inglese americano, 120 sarebbe "One hundred twenty", mentre in inglese britannico sarebbe "One hundred and twenty", con l'uso di "and" dopo le centinaia.
✅ Alcuni altri esempi che richiedono analisi del testo includono "in" come abbreviazione di pollice e "st" come abbreviazione di santo o strada. Riesci a pensare ad altri esempi nella tua lingua di parole che sono ambigue senza contesto?
Una volta definite le parole, vengono inviate per l'analisi linguistica.
Analisi linguistica
L'analisi linguistica suddivide le parole in fonemi. I fonemi si basano non solo sulle lettere utilizzate, ma anche sulle altre lettere nella parola. Ad esempio, in italiano il suono della 'e' in "bene" e "perché" è diverso.
✅ Fai una ricerca: Quali sono i fonemi della tua lingua?
Una volta che le parole sono state convertite in fonemi, questi fonemi necessitano di dati aggiuntivi per supportare l'intonazione, regolando il tono o la durata a seconda del contesto. Un esempio è l'italiano, dove l'intonazione può cambiare il significato di una frase. Ad esempio, "Hai un libro" è una dichiarazione, mentre "Hai un libro?" con un tono crescente alla fine diventa una domanda.
Una volta generati i fonemi, vengono inviati per la generazione della forma d'onda per produrre l'output audio.
Generazione della forma d'onda
I primi sistemi elettronici di conversione da testo a parlato utilizzavano singole registrazioni audio per ogni fonema, portando a voci molto monotone e robotiche. L'analisi linguistica produceva fonemi, che venivano caricati da un database di suoni e assemblati per creare l'audio.
✅ Fai una ricerca: Trova alcune registrazioni audio dei primi sistemi di sintesi vocale. Confrontale con la sintesi vocale moderna, come quella utilizzata dagli assistenti intelligenti.
La generazione della forma d'onda più moderna utilizza modelli di apprendimento automatico costruiti con deep learning (reti neurali molto grandi che funzionano in modo simile ai neuroni nel cervello) per produrre voci più naturali che possono essere indistinguibili da quelle umane.
💁 Alcuni di questi modelli di apprendimento automatico possono essere riaddestrati utilizzando il trasferimento di apprendimento per imitare persone reali. Questo significa che utilizzare la voce come sistema di sicurezza, qualcosa che le banche stanno cercando sempre più di fare, non è più una buona idea, poiché chiunque abbia una registrazione di pochi minuti della tua voce può impersonarti.
Questi grandi modelli di apprendimento automatico vengono addestrati per combinare tutti e tre i passaggi in sintetizzatori vocali end-to-end.
Imposta il timer
Per impostare il timer, il tuo dispositivo IoT deve chiamare l'endpoint REST che hai creato utilizzando codice serverless, quindi utilizzare il numero di secondi risultante per impostare un timer.
Attività - chiama la funzione serverless per ottenere il tempo del timer
Segui la guida pertinente per chiamare l'endpoint REST dal tuo dispositivo IoT e impostare un timer per il tempo richiesto:
Converti testo in parlato
Lo stesso servizio vocale che hai utilizzato per convertire il parlato in testo può essere utilizzato per convertire il testo in parlato, e questo può essere riprodotto tramite un altoparlante sul tuo dispositivo IoT. Il testo da convertire viene inviato al servizio vocale, insieme al tipo di audio richiesto (come la frequenza di campionamento), e vengono restituiti dati binari contenenti l'audio.
Quando invii questa richiesta, lo fai utilizzando il Speech Synthesis Markup Language (SSML), un linguaggio di markup basato su XML per applicazioni di sintesi vocale. Questo definisce non solo il testo da convertire, ma anche la lingua del testo, la voce da utilizzare, e può persino essere utilizzato per definire velocità, volume e tono per alcune o tutte le parole nel testo.
Ad esempio, questo SSML definisce una richiesta per convertire il testo "Il tuo timer di 3 minuti e 5 secondi è stato impostato" in parlato utilizzando una voce inglese britannica chiamata en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 La maggior parte dei sistemi di conversione da testo a parlato ha più voci per diverse lingue, con accenti pertinenti come una voce inglese britannica con accento inglese e una voce inglese neozelandese con accento neozelandese.
Attività - converti testo in parlato
Segui la guida pertinente per convertire il testo in parlato utilizzando il tuo dispositivo IoT:
- Arduino - Wio Terminal
- Computer a scheda singola - Raspberry Pi
- Computer a scheda singola - Dispositivo virtuale
🚀 Sfida
SSML offre modi per modificare il modo in cui le parole vengono pronunciate, come aggiungere enfasi a determinate parole, aggiungere pause o cambiare il tono. Prova alcune di queste opzioni, inviando diversi SSML dal tuo dispositivo IoT e confrontando i risultati. Puoi leggere di più su SSML, incluso come modificare il modo in cui le parole vengono pronunciate, nella specifica Speech Synthesis Markup Language (SSML) Version 1.1 del World Wide Web Consortium.
Quiz post-lezione
Revisione e studio autonomo
- Leggi di più sulla sintesi vocale nella pagina sulla sintesi vocale su Wikipedia
- Leggi di più sui modi in cui i criminali utilizzano la sintesi vocale per rubare nella notizia "voci false aiutano i criminali informatici a rubare denaro" su BBC News
- Scopri di più sui rischi per gli attori vocali derivanti dalle versioni sintetizzate delle loro voci nell'articolo "questa causa su TikTok evidenzia come l'IA stia danneggiando gli attori vocali" su Vice
Compito
Disclaimer:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica Co-op Translator. Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale effettuata da un traduttore umano. Non siamo responsabili per eventuali fraintendimenti o interpretazioni errate derivanti dall'uso di questa traduzione.