25 KiB
זיהוי דיבור עם מכשיר IoT
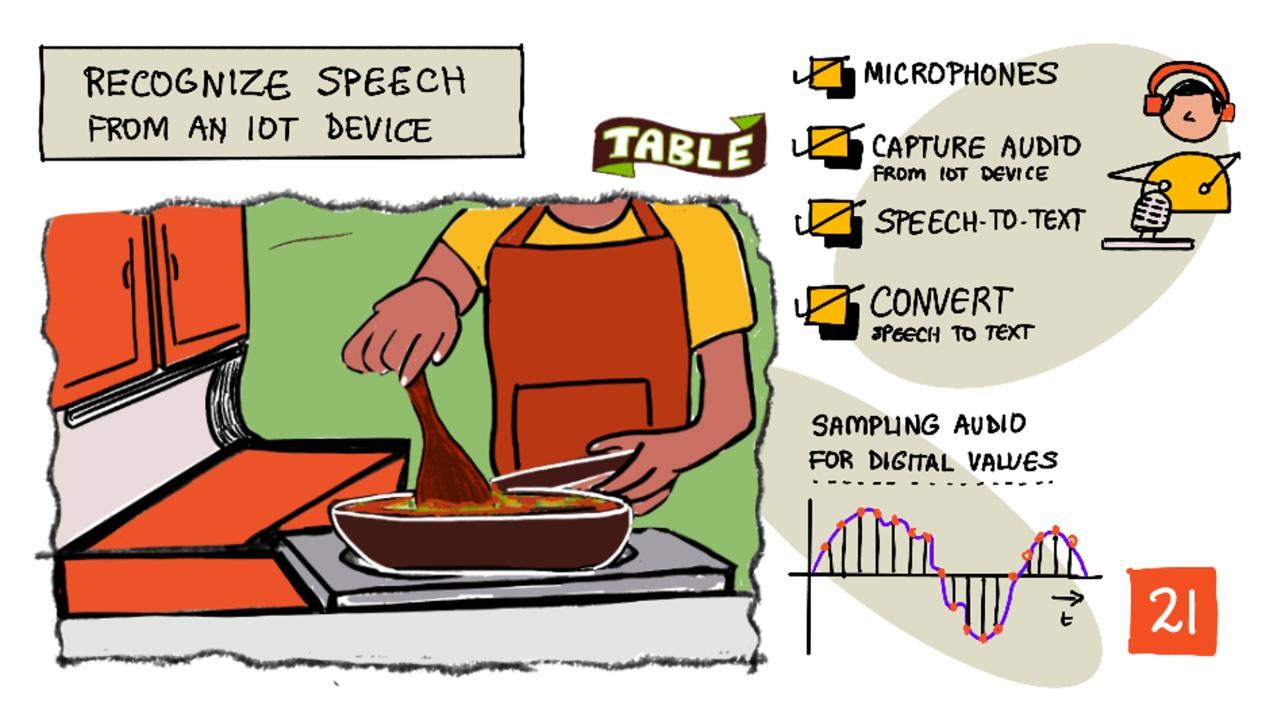
סקיצה מאת ניטיה נאראסימהן. לחצו על התמונה לגרסה גדולה יותר.
הווידאו הבא מספק סקירה על שירות הדיבור של Azure, נושא שיידון בשיעור זה:

🎥 לחצו על התמונה למעלה לצפייה בווידאו
שאלון לפני השיעור
מבוא
'אלכסה, הגדרי טיימר ל-12 דקות'
'אלכסה, מה מצב הטיימר?'
'אלכסה, הגדרי טיימר ל-8 דקות בשם "אידוי ברוקולי"'
מכשירים חכמים הופכים ליותר ויותר נפוצים. לא רק כרמקולים חכמים כמו HomePods, Echos ו-Google Homes, אלא גם כחלק מהטלפונים שלנו, השעונים, ואפילו גופי תאורה ותרמוסטטים.
💁 יש לי לפחות 19 מכשירים בבית עם עוזרות קוליות, וזה רק מה שאני יודע עליו!
שליטה קולית משפרת נגישות בכך שהיא מאפשרת לאנשים עם מגבלות תנועה לתקשר עם מכשירים. בין אם מדובר בנכות קבועה כמו היעדר זרועות, נכות זמנית כמו יד שבורה, או פשוט ידיים מלאות בקניות או ילדים קטנים, היכולת לשלוט בבית באמצעות קול במקום ידיים פותחת עולם שלם של אפשרויות. לצעוק "היי סירי, סגרי את דלת המוסך" בזמן שמטפלים בתינוק ובפעוט שובב יכול להיות שיפור קטן אך משמעותי בחיים.
אחת השימושים הפופולריים ביותר לעוזרות קוליות היא הגדרת טיימרים, במיוחד במטבח. היכולת להגדיר טיימרים מרובים באמצעות קול בלבד היא עזרה גדולה במטבח - אין צורך להפסיק ללוש בצק, לערבב מרק, או לנקות ידיים מלוכלכות כדי להשתמש בטיימר פיזי.
בשיעור זה תלמדו כיצד לשלב זיהוי קול במכשירי IoT. תלמדו על מיקרופונים כחיישנים, כיצד ללכוד אודיו ממיקרופון המחובר למכשיר IoT, וכיצד להשתמש בבינה מלאכותית כדי להמיר את מה שנשמע לטקסט. במהלך הפרויקט תלמדו לבנות טיימר מטבח חכם, המסוגל להגדיר טיימרים באמצעות קול במספר שפות.
בשיעור זה נעסוק בנושאים הבאים:
מיקרופונים
מיקרופונים הם חיישנים אנלוגיים שממירים גלי קול לאותות חשמליים. תנודות באוויר גורמות לרכיבים במיקרופון לנוע בכמויות זעירות, ואלו גורמות לשינויים קטנים באותות החשמליים. שינויים אלו מוגברים ליצירת פלט חשמלי.
סוגי מיקרופונים
מיקרופונים מגיעים במגוון סוגים:
-
דינמי - מיקרופונים דינמיים כוללים מגנט המחובר לדיאפרגמה נעה, שנעה בתוך סליל חוטים ויוצרת זרם חשמלי. זהו ההיפך מרמקולים, שמשתמשים בזרם חשמלי כדי להזיז מגנט בתוך סליל חוטים וליצור קול. המשמעות היא שמיקרופונים דינמיים יכולים לשמש כרמקולים, ולהיפך. במכשירים כמו אינטרקום, שבהם משתמשים או מקשיבים או מדברים, ניתן להשתמש במכשיר אחד גם כרמקול וגם כמיקרופון.
מיקרופונים דינמיים אינם זקוקים לחשמל כדי לפעול; האות החשמלי נוצר כולו מהמיקרופון.

-
סרט - מיקרופונים מסוג סרט דומים למיקרופונים דינמיים, אך במקום דיאפרגמה יש בהם סרט מתכת. הסרט נע בשדה מגנטי ויוצר זרם חשמלי. כמו מיקרופונים דינמיים, גם מיקרופונים מסוג סרט אינם זקוקים לחשמל כדי לפעול.

-
קונדנסר - מיקרופונים מסוג קונדנסר כוללים דיאפרגמה מתכתית דקה ולוח אחורי מתכתי קבוע. זרם חשמלי מוחל על שניהם, וכאשר הדיאפרגמה רוטטת, המטען הסטטי בין הלוחות משתנה ויוצר אות. מיקרופונים מסוג קונדנסר זקוקים לחשמל כדי לפעול - הנקרא Phantom power.
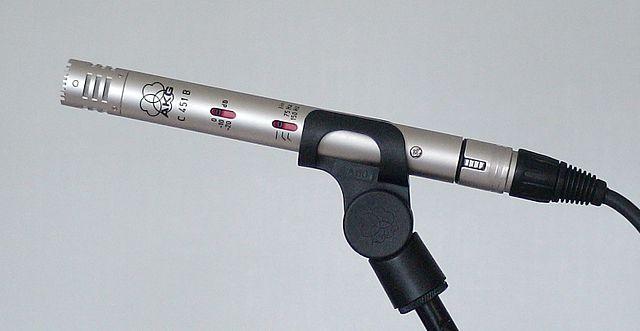
-
MEMS - מיקרופונים מסוג מערכות מיקרואלקטרומכניות, או MEMS, הם מיקרופונים על שבב. יש להם דיאפרגמה רגישה ללחץ המוטבעת על שבב סיליקון, והם פועלים בדומה למיקרופון קונדנסר. מיקרופונים אלו יכולים להיות זעירים ומשולבים במעגלים חשמליים.

בתמונה למעלה, השבב המסומן LEFT הוא מיקרופון MEMS, עם דיאפרגמה זעירה ברוחב של פחות ממילימטר.
✅ בצעו מחקר: אילו מיקרופונים יש סביבכם - במחשב, בטלפון, באוזניות או במכשירים אחרים? איזה סוג מיקרופונים הם?
אודיו דיגיטלי
אודיו הוא אות אנלוגי הנושא מידע עדין מאוד. כדי להמיר אות זה לדיגיטלי, יש לדגום את האודיו אלפי פעמים בשנייה.
🎓 דגימה היא המרה של אות האודיו לערך דיגיטלי המייצג את האות בנקודת זמן מסוימת.
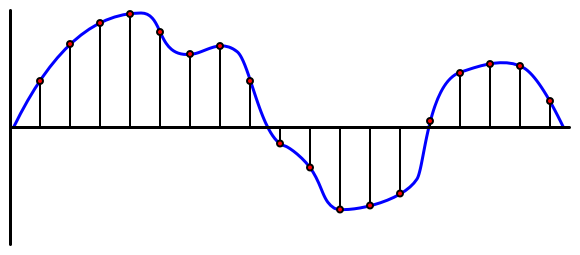
אודיו דיגיטלי נדגם באמצעות שיטת Pulse Code Modulation, או PCM. PCM כוללת קריאת המתח של האות ובחירת הערך הדיסקרטי הקרוב ביותר למתח זה באמצעות גודל מוגדר.
💁 אפשר לחשוב על PCM כגרסה של חיישנים ל-PWM (PWM נלמד בשיעור 3 של פרויקט ההתחלה). PCM ממיר אות אנלוגי לדיגיטלי, בעוד PWM ממיר אות דיגיטלי לאנלוגי.
לדוגמה, רוב שירותי המוזיקה בסטרימינג מציעים אודיו של 16 ביט או 24 ביט. המשמעות היא שהם ממירים את המתח לערך שמתאים למספר של 16 ביט או 24 ביט. אודיו של 16 ביט מתאים לערכים בטווח של -32,768 עד 32,767, בעוד 24 ביט מתאים לטווח של −8,388,608 עד 8,388,607. ככל שיש יותר ביטים, כך הדגימה קרובה יותר למה שאוזנינו שומעות בפועל.
💁 אולי שמעתם על אודיו של 8 ביט, המכונה לעיתים LoFi. זהו אודיו שנדגם באמצעות 8 ביט בלבד, כלומר בטווח של -128 עד 127. האודיו הראשון במחשבים היה מוגבל ל-8 ביט בשל מגבלות חומרה, ולכן הוא נפוץ במשחקים רטרו.
דגימות אלו נלקחות אלפי פעמים בשנייה, באמצעות קצבי דגימה מוגדרים היטב הנמדדים בקילוהרץ (אלפי קריאות בשנייה). שירותי מוזיקה בסטרימינג משתמשים ב-48 קילוהרץ עבור רוב האודיו, אך חלק מהאודיו ה'לוסלס' משתמש ב-96 קילוהרץ או אפילו 192 קילוהרץ. ככל שקצב הדגימה גבוה יותר, כך האודיו קרוב יותר למקור, עד לנקודה מסוימת. יש ויכוח האם בני אדם יכולים להבחין בהבדל מעל 48 קילוהרץ.
✅ בצעו מחקר: אם אתם משתמשים בשירות מוזיקה בסטרימינג, מהו קצב הדגימה והגודל שהוא משתמש בהם? אם אתם משתמשים בדיסקים, מהו קצב הדגימה והגודל של אודיו בדיסקים?
ישנם מספר פורמטים שונים לנתוני אודיו. סביר להניח ששמעתם על קבצי mp3 - נתוני אודיו שנדחסו כדי להיות קטנים יותר מבלי לאבד איכות. אודיו לא דחוס נשמר לעיתים קרובות כקובץ WAV - זהו קובץ עם 44 בתים של מידע כותרת, ואחריהם נתוני אודיו גולמיים. הכותרת מכילה מידע כמו קצב הדגימה (למשל 16000 עבור 16 קילוהרץ), גודל הדגימה (16 עבור 16 ביט), ומספר הערוצים. לאחר הכותרת, קובץ ה-WAV מכיל את נתוני האודיו הגולמיים.
🎓 ערוצים מתייחסים לכמה זרמי אודיו שונים מרכיבים את האודיו. לדוגמה, עבור אודיו סטריאו עם שמאל וימין, יהיו 2 ערוצים. עבור סראונד 7.1 למערכת קולנוע ביתי יהיו 8 ערוצים.
גודל נתוני אודיו
נתוני אודיו הם יחסית גדולים. לדוגמה, לכידת אודיו לא דחוס של 16 ביט ב-16 קילוהרץ (קצב מספיק טוב לשימוש עם מודל דיבור לטקסט) דורשת 32KB של נתונים עבור כל שנייה של אודיו:
- 16 ביט משמעו 2 בתים לכל דגימה (בית אחד הוא 8 ביטים).
- 16 קילוהרץ הם 16,000 דגימות בשנייה.
- 16,000 x 2 בתים = 32,000 בתים בשנייה.
זה אולי נשמע כמו כמות קטנה של נתונים, אבל אם אתם משתמשים במיקרובקר עם זיכרון מוגבל, זה יכול להיות הרבה. לדוגמה, ל-Wio Terminal יש 192KB של זיכרון, וזה צריך לאחסן קוד תוכנה ומשתנים. גם אם קוד התוכנה שלכם קטן מאוד, לא תוכלו ללכוד יותר מ-5 שניות של אודיו.
מיקרובקרים יכולים לגשת לאחסון נוסף, כמו כרטיסי SD או זיכרון פלאש. כאשר בונים מכשיר IoT שלוכד אודיו, תצטרכו לוודא שלא רק שיש לכם אחסון נוסף, אלא שהקוד שלכם כותב את האודיו שנלכד מהמיקרופון ישירות לאחסון, וכאשר שולחים אותו לענן, אתם זורמים מהאחסון לבקשת הרשת. כך תוכלו להימנע ממחסור בזיכרון על ידי ניסיון להחזיק את כל בלוק נתוני האודיו בזיכרון בבת אחת.
לכידת אודיו ממכשיר ה-IoT שלכם
מכשיר ה-IoT שלכם יכול להיות מחובר למיקרופון כדי ללכוד אודיו, מוכן להמרה לטקסט. הוא גם יכול להיות מחובר לרמקולים כדי להוציא אודיו. בשיעורים הבאים זה ישמש למתן משוב קולי, אך כדאי להגדיר רמקולים כבר עכשיו כדי לבדוק את המיקרופון.
משימה - הגדרת המיקרופון והרמקולים
עברו על המדריך הרלוונטי כדי להגדיר את המיקרופון והרמקולים עבור מכשיר ה-IoT שלכם:
משימה - לכידת אודיו
עברו על המדריך הרלוונטי כדי ללכוד אודיו במכשיר ה-IoT שלכם:
דיבור לטקסט
דיבור לטקסט, או זיהוי דיבור, כולל שימוש בבינה מלאכותית כדי להמיר מילים באות אודיו לטקסט.
מודלים לזיהוי דיבור
כדי להמיר דיבור לטקסט, דגימות מאות האודיו מקובצות יחד ומוזנות למודל למידת מכונה המבוסס על רשת עצבית חוזרת (RNN). זהו סוג של מודל למידת מכונה שיכול להשתמש בנתונים קודמים כדי לקבל החלטה על נתונים נכנסים. לדוגמה, ה-RNN יכול לזהות בלוק אחד של דגימות אודיו כצליל 'Hel', וכאשר הוא מקבל בלוק נוסף שהוא חושב שהוא הצליל 'lo', הוא יכול לשלב זאת עם הצליל הקודם, למצוא ש-'Hello' היא מילה תקפה ולבחור בה כתוצאה.
מודלים של למידת מכונה תמיד מקבלים נתונים באותו גודל בכל פעם. מסווג התמונות שבניתם בשיעור קודם משנה את גודל התמונות לגודל קבוע ומעבד אותן. כך גם עם מודלים של דיבור, הם חייבים לעבד בלוקים בגודל קבוע של אודיו. המודלים צריכים להיות מסוגלים לשלב את התוצאות של תחזיות מרובות כדי לקבל תשובה, כדי לאפשר להם להבדיל בין 'Hi' ל-'Highway', או 'flock' ל-'floccinaucinihilipilification'.
מודלים של דיבור מתקדמים מספיק כדי להבין הקשר, ויכולים לתקן את המילים שהם מזהים ככל שמעבדים יותר צלילים. לדוגמה, אם תגידו "הלכתי לחנות לקנות שני בננות ותפוח גם", תשתמשו בשלוש מילים שנשמעות אותו דבר אך נכתבות אחרת - to, two ו-too. מודלים של דיבור מסוגלים להבין את ההקשר ולהשתמש באיות המתאים של המילה. 💁 חלק משירותי הדיבור מאפשרים התאמה אישית כדי לשפר את הביצועים שלהם בסביבות רועשות כמו מפעלים, או עם מילים ייחודיות לתעשייה כמו שמות כימיקלים. התאמות אישיות אלו מאומנות על ידי מתן דוגמאות של אודיו ותמלול, ועובדות באמצעות למידת העברה, בדיוק כמו שאימנתם מסווג תמונות באמצעות מספר קטן של תמונות בשיעור קודם.
פרטיות
כאשר משתמשים בהמרת דיבור לטקסט במכשיר IoT לצרכנים, פרטיות היא נושא חשוב ביותר. מכשירים אלו מאזינים לאודיו באופן רציף, ולכן כצרכן אינך רוצה שכל מה שאתה אומר יישלח לענן ויומר לטקסט. לא רק שזה יצרוך הרבה רוחב פס באינטרנט, אלא שזה גם מעלה שאלות פרטיות משמעותיות, במיוחד כאשר יצרני מכשירים חכמים מסוימים בוחרים באופן אקראי אודיו כדי שבני אדם יאמתו אותו מול הטקסט שנוצר כדי לשפר את המודל שלהם.
אתה רוצה שהמכשיר החכם שלך ישלח אודיו לענן לעיבוד רק כאשר אתה משתמש בו, ולא כאשר הוא שומע אודיו בביתך, אודיו שיכול לכלול פגישות פרטיות או אינטראקציות אינטימיות. הדרך שבה רוב המכשירים החכמים פועלים היא באמצעות מילת התעוררות, ביטוי מפתח כמו "אלכסה", "היי סירי" או "אוקיי גוגל", שגורם למכשיר 'להתעורר' ולהאזין למה שאתה אומר עד שהוא מזהה הפסקה בדיבור שלך, מה שמצביע על כך שסיימת לדבר עם המכשיר.
🎓 זיהוי מילת התעוררות נקרא גם זיהוי מילות מפתח או איתור מילות מפתח.
מילות התעוררות הללו מזוהות על גבי המכשיר עצמו, ולא בענן. למכשירים החכמים הללו יש מודלים קטנים של בינה מלאכותית שפועלים על המכשיר ומאזינים למילת ההתעוררות, וכאשר היא מזוהה, מתחילים להזרים את האודיו לענן לצורך זיהוי. מודלים אלו מאוד ממוקדים, ומאזינים רק למילת ההתעוררות.
💁 חלק מחברות הטכנולוגיה מוסיפות יותר פרטיות למכשירים שלהן ומבצעות חלק מהמרת הדיבור לטקסט על גבי המכשיר עצמו. אפל הודיעה שבמסגרת עדכוני iOS ו-macOS לשנת 2021, היא תתמוך בהמרת דיבור לטקסט על המכשיר, ותוכל לטפל בבקשות רבות מבלי להזדקק לשימוש בענן. זאת הודות למעבדים החזקים במכשירים שלה שיכולים להריץ מודלים של למידת מכונה.
✅ מה לדעתך ההשלכות הפרטיות והאתיות של אחסון האודיו שנשלח לענן? האם יש לאחסן אודיו זה, ואם כן, כיצד? האם לדעתך השימוש בהקלטות לצורכי אכיפת חוק הוא פשרה טובה על חשבון הפרטיות?
זיהוי מילת התעוררות בדרך כלל משתמש בטכניקה שנקראת TinyML, שהיא התאמת מודלים של למידת מכונה כך שיוכלו לפעול על מיקרו-בקרים. מודלים אלו קטנים בגודלם וצורכים מעט מאוד אנרגיה להפעלה.
כדי להימנע מהמורכבות של אימון ושימוש במודל לזיהוי מילת התעוררות, הטיימר החכם שאתה בונה בשיעור זה ישתמש בכפתור כדי להפעיל את זיהוי הדיבור.
💁 אם אתה רוצה לנסות ליצור מודל לזיהוי מילת התעוררות שיפעל על Wio Terminal או Raspberry Pi, עיין במדריך responding to your voice של Edge Impulse. אם אתה רוצה להשתמש במחשב שלך לשם כך, תוכל לנסות את המדריך המהיר להתחלת עבודה עם מילות מפתח מותאמות אישית ב-Microsoft Docs.
המרת דיבור לטקסט
![]()
בדומה לסיווג תמונות בפרויקט קודם, קיימים שירותי בינה מלאכותית מוכנים מראש שיכולים לקחת דיבור כקובץ אודיו ולהמיר אותו לטקסט. אחד משירותים אלו הוא Speech Service, חלק משירותי Cognitive Services, שירותי בינה מלאכותית מוכנים לשימוש באפליקציות שלך.
משימה - הגדרת משאב AI לדיבור
-
צור קבוצת משאבים לפרויקט זה בשם
smart-timer. -
השתמש בפקודה הבאה כדי ליצור משאב דיבור חינמי:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>החלף
<location>במיקום שבו יצרת את קבוצת המשאבים. -
תצטרך מפתח API כדי לגשת למשאב הדיבור מהקוד שלך. הרץ את הפקודה הבאה כדי לקבל את המפתח:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableשמור עותק של אחד המפתחות.
משימה - המרת דיבור לטקסט
עבוד דרך המדריך הרלוונטי להמרת דיבור לטקסט על מכשיר ה-IoT שלך:
🚀 אתגר
זיהוי דיבור קיים כבר זמן רב, והוא משתפר באופן מתמיד. חקור את היכולות הנוכחיות והשווה כיצד הן התפתחו לאורך זמן, כולל כמה מדויקות התמלולים של מכונות בהשוואה לבני אדם.
מה לדעתך צופן העתיד לזיהוי דיבור?
חידון לאחר ההרצאה
סקירה ולימוד עצמי
- קרא על סוגי מיקרופונים שונים וכיצד הם פועלים במאמר מה ההבדל בין מיקרופונים דינמיים וקונדנסר באתר Musician's HQ.
- קרא עוד על שירות הדיבור של Cognitive Services בתיעוד שירות הדיבור ב-Microsoft Docs.
- קרא על זיהוי מילות מפתח בתיעוד זיהוי מילות מפתח ב-Microsoft Docs.
משימה
כתב ויתור:
מסמך זה תורגם באמצעות שירות תרגום מבוסס בינה מלאכותית Co-op Translator. בעוד שאנו שואפים לדיוק, יש להיות מודעים לכך שתרגומים אוטומטיים עשויים להכיל שגיאות או אי דיוקים. המסמך המקורי בשפתו המקורית צריך להיחשב כמקור הסמכותי. עבור מידע קריטי, מומלץ להשתמש בתרגום מקצועי על ידי אדם. איננו נושאים באחריות לאי הבנות או לפרשנויות שגויות הנובעות משימוש בתרגום זה.