11 KiB
Régler un minuteur et fournir un retour vocal
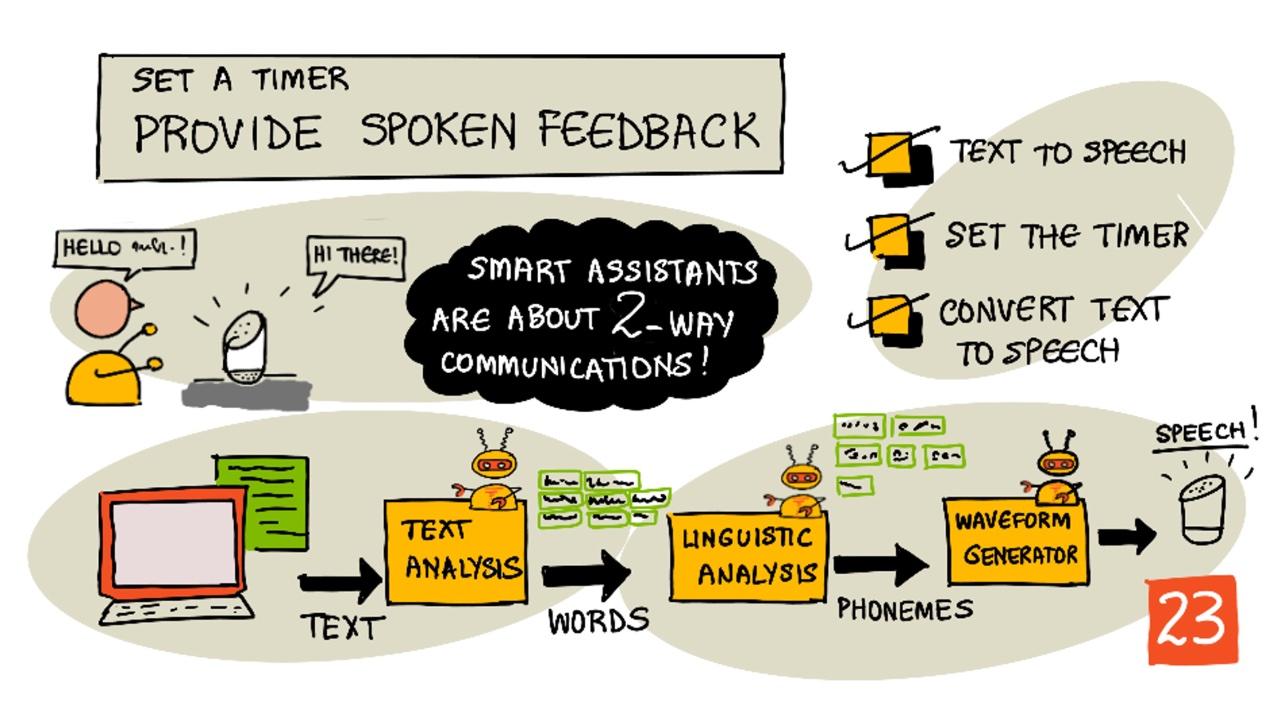
Illustration par Nitya Narasimhan. Cliquez sur l'image pour une version agrandie.
Quiz avant le cours
Introduction
Les assistants intelligents ne sont pas des dispositifs de communication à sens unique. Vous leur parlez, et ils répondent :
"Alexa, règle un minuteur de 3 minutes"
"Ok, votre minuteur est réglé pour 3 minutes"
Dans les deux dernières leçons, vous avez appris à transformer la parole en texte, puis à extraire une demande de minuteur à partir de ce texte. Dans cette leçon, vous apprendrez à régler le minuteur sur l'appareil IoT, à répondre à l'utilisateur avec des mots parlés confirmant son minuteur, et à l'alerter lorsque le minuteur est terminé.
Dans cette leçon, nous aborderons :
La synthèse vocale
La synthèse vocale, comme son nom l'indique, est le processus de conversion de texte en audio contenant les mots prononcés. Le principe de base consiste à décomposer les mots du texte en leurs sons constitutifs (appelés phonèmes) et à assembler des fichiers audio pour ces sons, soit en utilisant des enregistrements préexistants, soit en générant l'audio à l'aide de modèles d'IA.

Les systèmes de synthèse vocale comportent généralement 3 étapes :
- Analyse du texte
- Analyse linguistique
- Génération de forme d'onde
Analyse du texte
L'analyse du texte consiste à prendre le texte fourni et à le convertir en mots utilisables pour générer de la parole. Par exemple, si vous convertissez "Bonjour le monde", aucune analyse textuelle n'est nécessaire, les deux mots peuvent être directement transformés en parole. En revanche, pour "1234", il peut être nécessaire de le convertir en "Mille deux cent trente-quatre" ou "Un, deux, trois, quatre" selon le contexte. Pour "J'ai 1234 pommes", ce serait "Mille deux cent trente-quatre", mais pour "L'enfant a compté 1234", ce serait "Un, deux, trois, quatre".
Les mots générés varient non seulement selon la langue, mais aussi selon la région où cette langue est parlée. Par exemple, en anglais américain, 120 se dit "One hundred twenty", tandis qu'en anglais britannique, ce serait "One hundred and twenty", avec l'utilisation de "and" après les centaines.
✅ D'autres exemples nécessitant une analyse textuelle incluent "in" comme abréviation de pouce (inch), et "st" comme abréviation de saint ou de rue (street). Pouvez-vous penser à d'autres exemples dans votre langue où des mots sont ambigus sans contexte ?
Une fois les mots définis, ils sont envoyés pour une analyse linguistique.
Analyse linguistique
L'analyse linguistique décompose les mots en phonèmes. Les phonèmes dépendent non seulement des lettres utilisées, mais aussi des autres lettres dans le mot. Par exemple, en anglais, le son 'a' dans 'car' et 'care' est différent. La langue anglaise possède 44 phonèmes différents pour les 26 lettres de l'alphabet, certains étant partagés par différentes lettres, comme le même phonème utilisé au début de 'circle' et 'serpent'.
✅ Faites des recherches : Quels sont les phonèmes de votre langue ?
Une fois les mots convertis en phonèmes, ces phonèmes nécessitent des données supplémentaires pour gérer l'intonation, en ajustant le ton ou la durée selon le contexte. Par exemple, en anglais, une augmentation de la hauteur du ton peut transformer une phrase en question, une hauteur plus élevée pour le dernier mot impliquant une question.
Par exemple - la phrase "You have an apple" est une affirmation indiquant que vous avez une pomme. Si le ton monte à la fin, augmentant pour le mot "apple", cela devient la question "You have an apple?", demandant si vous avez une pomme. L'analyse linguistique doit utiliser le point d'interrogation à la fin pour décider d'augmenter la hauteur du ton.
Une fois les phonèmes générés, ils peuvent être envoyés pour la génération de forme d'onde afin de produire la sortie audio.
Génération de forme d'onde
Les premiers systèmes électroniques de synthèse vocale utilisaient des enregistrements audio uniques pour chaque phonème, ce qui donnait des voix très monotones et robotiques. L'analyse linguistique produisait des phonèmes, ceux-ci étaient chargés à partir d'une base de données de sons et assemblés pour créer l'audio.
✅ Faites des recherches : Trouvez des enregistrements audio des premiers systèmes de synthèse vocale. Comparez-les à la synthèse vocale moderne, comme celle utilisée dans les assistants intelligents.
Les systèmes modernes de génération de forme d'onde utilisent des modèles d'apprentissage automatique (ML) construits à l'aide de l'apprentissage profond (des réseaux neuronaux très larges qui fonctionnent de manière similaire aux neurones du cerveau) pour produire des voix plus naturelles, parfois indiscernables de celles des humains.
💁 Certains de ces modèles d'apprentissage automatique peuvent être re-entraînés à l'aide de l'apprentissage par transfert pour imiter des voix réelles. Cela signifie que l'utilisation de la voix comme système de sécurité, une méthode que les banques tentent de plus en plus d'adopter, n'est plus une bonne idée, car toute personne disposant d'un enregistrement de quelques minutes de votre voix peut vous imiter.
Ces grands modèles d'apprentissage automatique sont en cours de formation pour combiner les trois étapes en synthétiseurs vocaux de bout en bout.
Régler le minuteur
Pour régler le minuteur, votre appareil IoT doit appeler le point de terminaison REST que vous avez créé à l'aide de code sans serveur, puis utiliser le nombre de secondes obtenu pour régler un minuteur.
Tâche - appeler la fonction sans serveur pour obtenir la durée du minuteur
Suivez le guide correspondant pour appeler le point de terminaison REST depuis votre appareil IoT et régler un minuteur pour la durée requise :
Convertir du texte en parole
Le même service vocal que vous avez utilisé pour convertir la parole en texte peut être utilisé pour convertir du texte en parole, et cela peut être diffusé via un haut-parleur sur votre appareil IoT. Le texte à convertir est envoyé au service vocal, accompagné du type d'audio requis (comme la fréquence d'échantillonnage), et des données binaires contenant l'audio sont renvoyées.
Lorsque vous envoyez cette requête, vous utilisez le Speech Synthesis Markup Language (SSML), un langage de balisage basé sur XML pour les applications de synthèse vocale. Cela définit non seulement le texte à convertir, mais aussi la langue du texte, la voix à utiliser, et peut même être utilisé pour définir la vitesse, le volume et la hauteur pour certains ou tous les mots du texte.
Par exemple, ce SSML définit une requête pour convertir le texte "Votre minuteur de 3 minutes et 5 secondes a été réglé" en parole en utilisant une voix anglaise britannique appelée en-GB-MiaNeural.
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 La plupart des systèmes de synthèse vocale disposent de plusieurs voix pour différentes langues, avec des accents pertinents tels qu'une voix anglaise britannique avec un accent anglais et une voix anglaise néo-zélandaise avec un accent néo-zélandais.
Tâche - convertir du texte en parole
Suivez le guide correspondant pour convertir du texte en parole à l'aide de votre appareil IoT :
🚀 Défi
Le SSML permet de modifier la manière dont les mots sont prononcés, comme ajouter de l'emphase sur certains mots, insérer des pauses ou changer la hauteur du ton. Essayez certaines de ces options en envoyant différents SSML depuis votre appareil IoT et comparez les résultats. Vous pouvez en apprendre davantage sur le SSML, y compris comment modifier la prononciation des mots, dans la spécification Speech Synthesis Markup Language (SSML) Version 1.1 du World Wide Web Consortium.
Quiz après le cours
Révision et auto-apprentissage
- Lisez-en davantage sur la synthèse vocale sur la page Wikipédia dédiée à la synthèse vocale
- Découvrez comment les criminels utilisent la synthèse vocale pour voler dans l'article Des voix factices "aident les cybercriminels à voler de l'argent" sur BBC News
- Apprenez-en plus sur les risques pour les acteurs de voix liés aux versions synthétisées de leurs voix dans l'article Ce procès TikTok met en lumière comment l'IA nuit aux acteurs de voix sur Vice
Devoir
Avertissement :
Ce document a été traduit à l'aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d'assurer l'exactitude, veuillez noter que les traductions automatisées peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d'origine doit être considéré comme la source faisant autorité. Pour des informations critiques, il est recommandé de faire appel à une traduction humaine professionnelle. Nous déclinons toute responsabilité en cas de malentendus ou d'interprétations erronées résultant de l'utilisation de cette traduction.