|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
Aseta ajastin ja anna puhepalautetta
Luonnoskuva: Nitya Narasimhan. Klikkaa kuvaa nähdäksesi suuremman version.
Ennakkokysely
Johdanto
Älykkäät avustajat eivät ole yksisuuntaisia viestintälaitteita. Puhut niille, ja ne vastaavat:
"Alexa, aseta 3 minuutin ajastin"
"Ok, ajastimesi on asetettu 3 minuutiksi"
Viimeisten kahden oppitunnin aikana opit, kuinka puhe muutetaan tekstiksi ja kuinka tekstistä voidaan tunnistaa ajastimen asettamista koskeva pyyntö. Tässä oppitunnissa opit, kuinka ajastin asetetaan IoT-laitteessa, käyttäjälle vastataan puheella vahvistaen ajastimen asettaminen ja ilmoitetaan, kun ajastin on päättynyt.
Tässä oppitunnissa käsitellään:
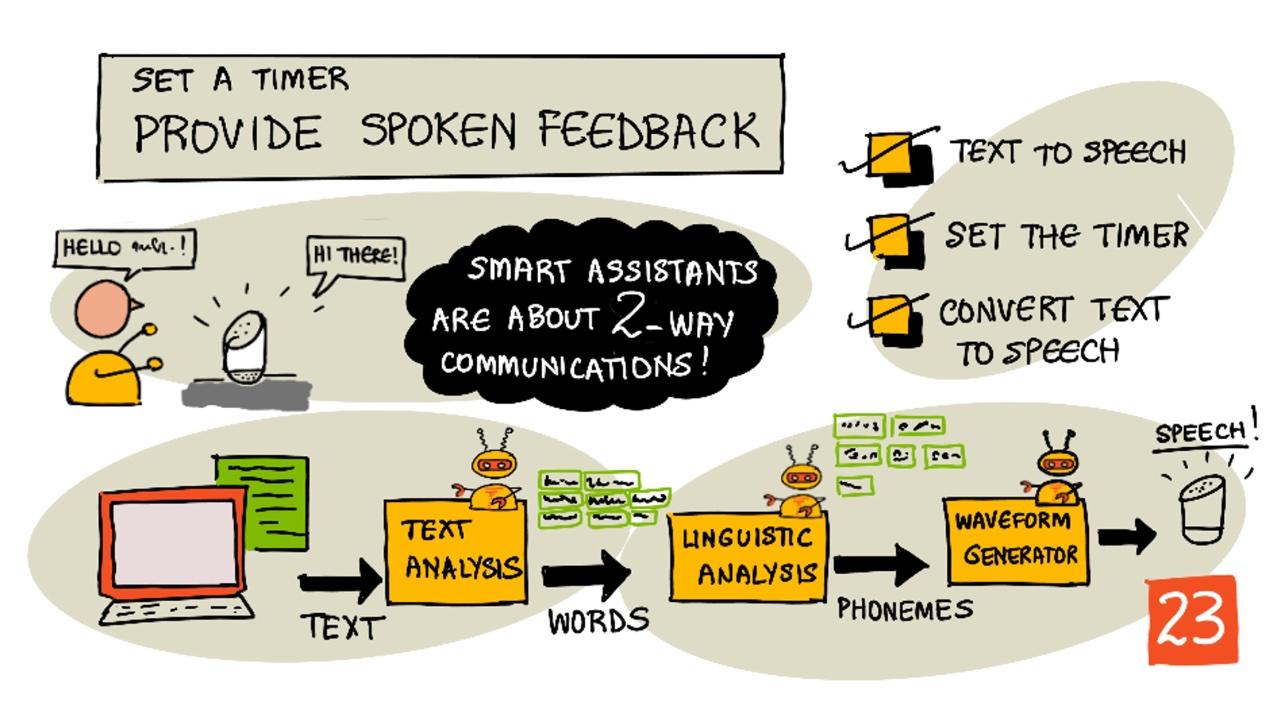
Teksti puheeksi
Teksti puheeksi -prosessi tarkoittaa tekstin muuntamista ääneksi, joka sisältää tekstin puhuttuna. Perusperiaate on jakaa tekstin sanat niiden osasävelmiin (fonemeihin) ja yhdistää näiden äänien audiot joko ennalta nauhoitetuista äänistä tai tekoälymallien tuottamasta audiosta.

Teksti puheeksi -järjestelmät koostuvat yleensä kolmesta vaiheesta:
- Tekstin analysointi
- Kielellinen analyysi
- Aaltomuodon luominen
Tekstin analysointi
Tekstin analysointi tarkoittaa annetun tekstin muuntamista sanoiksi, jotka voidaan käyttää puheen tuottamiseen. Esimerkiksi "Hello world" ei vaadi tekstin analysointia, koska sanat voidaan suoraan muuntaa puheeksi. Jos tekstinä on "1234", se täytyy muuntaa joko sanoiksi "Tuhat kaksisataa kolmekymmentäneljä" tai "Yksi, kaksi, kolme, neljä" kontekstista riippuen. Esimerkiksi "Minulla on 1234 omenaa" muuntuu "Tuhat kaksisataa kolmekymmentäneljä", mutta "Lapsi laski 1234" muuntuu "Yksi, kaksi, kolme, neljä".
Sanat vaihtelevat paitsi kielen myös sen murteen mukaan. Esimerkiksi amerikkalaisessa englannissa 120 on "One hundred twenty", kun taas brittiläisessä englannissa se on "One hundred and twenty", sisältäen "and"-sanan sadan jälkeen.
✅ Jotkut muut esimerkit, jotka vaativat tekstin analysointia, ovat "in" tuumien lyhenteenä ja "st" pyhimyksen tai kadun lyhenteenä. Voitko keksiä muita esimerkkejä omassa kielessäsi, joissa sanat ovat epäselviä ilman kontekstia?
Kun sanat on määritelty, ne lähetetään kielelliseen analyysiin.
Kielellinen analyysi
Kielellinen analyysi jakaa sanat fonemeiksi. Fonemit perustuvat paitsi kirjaimiin myös muihin sanan kirjaimiin. Esimerkiksi englannissa 'a'-ääni sanassa 'car' ja 'care' on erilainen. Englannin kielessä on 44 erilaista fonemia 26 kirjaimelle, joista jotkut jakavat saman fonemin, kuten 'circle' ja 'serpent' alkavat samalla fonemilla.
✅ Tee tutkimusta: Mitkä ovat fonemit omassa kielessäsi?
Kun sanat on muunnettu fonemeiksi, nämä fonemit tarvitsevat lisätietoa intonaation tukemiseksi, sävyn tai keston säätämiseksi kontekstin mukaan. Esimerkiksi englannissa sävelkorkeuden nousua voidaan käyttää muuttamaan lause kysymykseksi, jolloin viimeisen sanan korotettu sävelkorkeus viittaa kysymykseen.
Esimerkiksi lause "You have an apple" on väite, joka kertoo, että sinulla on omena. Jos sävelkorkeus nousee lopussa, erityisesti sanassa "apple", siitä tulee kysymys "You have an apple?", kysyen, onko sinulla omena. Kielellinen analyysi käyttää kysymysmerkkiä lopussa päättääkseen sävelkorkeuden nostamisesta.
Kun fonemit on luotu, ne lähetetään aaltomuodon luomiseen tuottamaan audio.
Aaltomuodon luominen
Ensimmäiset elektroniset teksti puheeksi -järjestelmät käyttivät yksittäisiä äänitallenteita jokaiselle fonemille, mikä johti hyvin monotonisiin, robottimaisiin ääniin. Kielellinen analyysi tuotti fonemeja, jotka ladattiin äänitietokannasta ja yhdistettiin audioksi.
✅ Tee tutkimusta: Etsi äänitallenteita varhaisista puhesynteesijärjestelmistä. Vertaa niitä nykyaikaisiin puhesynteeseihin, kuten älykkäiden avustajien käyttämiin.
Nykyaikaisempi aaltomuodon luominen käyttää koneoppimismalleja, jotka on rakennettu syväoppimisen avulla (hyvin suuria hermoverkkoja, jotka toimivat samankaltaisesti kuin aivojen neuronit) tuottamaan luonnollisemman kuuloisia ääniä, jotka voivat olla erottamattomia ihmisen äänestä.
💁 Jotkut näistä koneoppimismalleista voidaan uudelleenkouluttaa siirto-oppimisen avulla kuulostamaan oikeilta ihmisiltä. Tämä tarkoittaa, että äänen käyttäminen turvajärjestelmänä, kuten pankkien yhä enemmän yrittämä tapa, ei ole enää hyvä idea, koska kuka tahansa, jolla on muutaman minuutin tallenne äänestäsi, voi jäljitellä sinua.
Nämä suuret koneoppimismallit koulutetaan yhdistämään kaikki kolme vaihetta end-to-end-puhesynteesijärjestelmiin.
Ajastimen asettaminen
Ajastimen asettamiseksi IoT-laitteesi täytyy kutsua palvelimettoman koodin avulla luomasi REST-päätepiste ja käyttää tuloksena saatua sekuntimäärää ajastimen asettamiseen.
Tehtävä - kutsu palvelimetonta funktiota saadaksesi ajastimen ajan
Seuraa asiaankuuluvaa opasta kutsuaksesi REST-päätepistettä IoT-laitteestasi ja asettaaksesi ajastimen vaaditulle ajalle:
Tekstin muuntaminen puheeksi
Sama puhepalvelu, jota käytit puheen muuntamiseen tekstiksi, voidaan käyttää tekstin muuntamiseen takaisin puheeksi, ja tämä voidaan toistaa IoT-laitteen kaiuttimen kautta. Muunnettava teksti lähetetään puhepalveluun yhdessä tarvittavan audion tyypin (kuten näytteenottotaajuuden) kanssa, ja binaaridata, joka sisältää audion, palautetaan.
Kun lähetät tämän pyynnön, käytät Speech Synthesis Markup Language (SSML) -merkintäkieltä, joka perustuu XML:ään ja on tarkoitettu puhesynteesisovelluksiin. Tämä määrittää paitsi muunnettavan tekstin myös tekstin kielen, käytettävän äänen ja voi jopa määrittää nopeuden, äänenvoimakkuuden ja sävelkorkeuden joillekin tai kaikille tekstin sanoille.
Esimerkiksi tämä SSML määrittää pyynnön muuntaa teksti "Your 3 minute 5 second time has been set" puheeksi käyttäen brittiläistä englannin ääntä nimeltä en-GB-MiaNeural.
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Useimmilla teksti puheeksi -järjestelmillä on useita ääniä eri kielille, joilla on asiaankuuluvat aksentit, kuten brittiläisen englannin ääni englantilaisella aksentilla ja uusiseelantilaisen englannin ääni uusiseelantilaisella aksentilla.
Tehtävä - muunna teksti puheeksi
Käy läpi asiaankuuluva opas muuntaaksesi teksti puheeksi IoT-laitteellasi:
🚀 Haaste
SSML tarjoaa tapoja muuttaa, miten sanat lausutaan, kuten korostamalla tiettyjä sanoja, lisäämällä taukoja tai muuttamalla sävelkorkeutta. Kokeile näitä lähettämällä erilaisia SSML-tiedostoja IoT-laitteestasi ja vertaamalla tuloksia. Voit lukea lisää SSML:stä, mukaan lukien miten muuttaa sanojen lausumistapaa, Speech Synthesis Markup Language (SSML) Version 1.1 -spesifikaatiosta World Wide Web -konsortiosta.
Jälkikysely
Kertaus ja itseopiskelu
- Lue lisää puhesynteesistä puhesynteesin Wikipedia-sivulta
- Lue lisää tavoista, joilla rikolliset käyttävät puhesynteesiä varastamiseen BBC:n uutisartikkelista "fake voices 'help cyber crooks steal cash'"
- Opi lisää riskeistä, joita äänenäyttelijöille aiheutuu heidän ääniensä synteettisistä versioista Vice-artikkelista "this TikTok lawsuit is highlighting how AI is screwing over voice actors"
Tehtävä
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa väärinkäsityksistä tai virhetulkinnoista, jotka johtuvat tämän käännöksen käytöstä.