31 KiB
تشخیص گفتار با یک دستگاه IoT
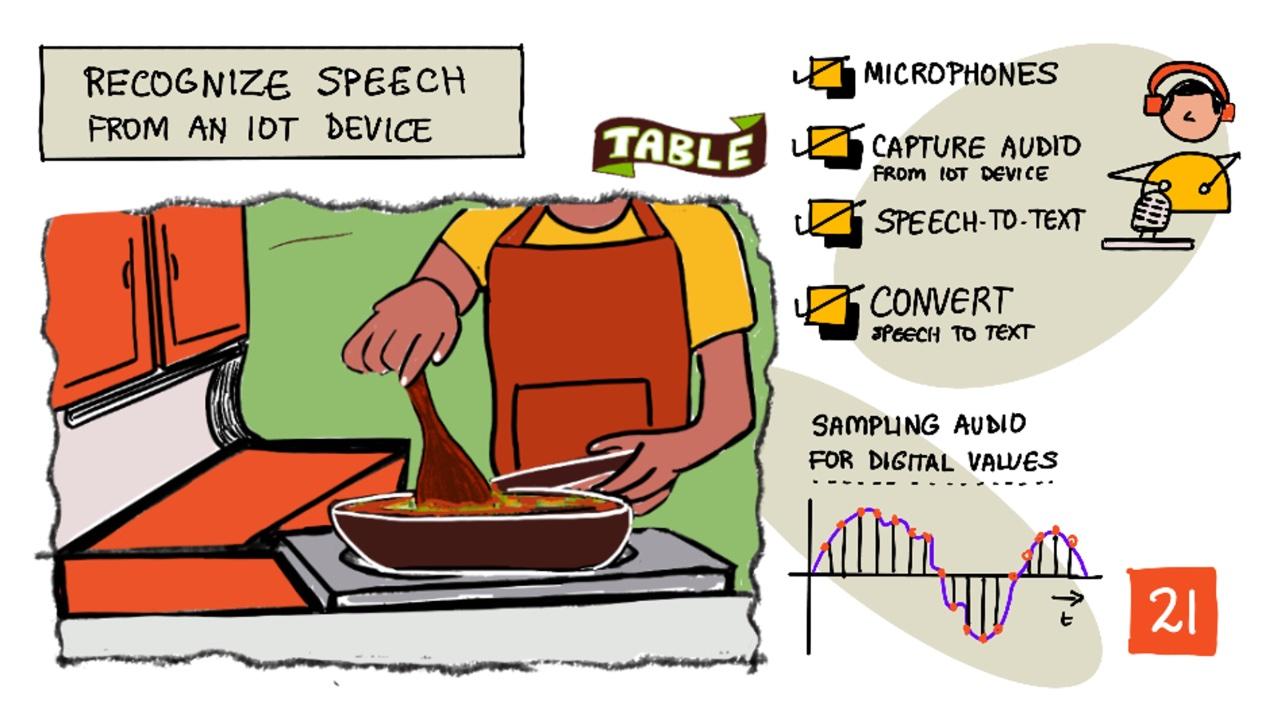
اسکچنوت توسط نیتیا ناراسیمهان. برای مشاهده نسخه بزرگتر روی تصویر کلیک کنید.
این ویدیو نمای کلی از سرویس گفتار Azure را ارائه میدهد، موضوعی که در این درس پوشش داده خواهد شد:

🎥 برای مشاهده ویدیو روی تصویر بالا کلیک کنید
آزمون پیش از درس
مقدمه
«الکسا، یک تایمر ۱۲ دقیقهای تنظیم کن»
«الکسا، وضعیت تایمر»
«الکسا، یک تایمر ۸ دقیقهای به نام بخار کردن بروکلی تنظیم کن»
دستگاههای هوشمند روز به روز فراگیرتر میشوند. نه فقط به عنوان بلندگوهای هوشمند مانند HomePods، Echos و Google Homes، بلکه در تلفنها، ساعتها، و حتی چراغها و ترموستاتها نیز تعبیه شدهاند.
💁 من حداقل ۱۹ دستگاه در خانه دارم که دستیار صوتی دارند، و این فقط دستگاههایی است که از آنها اطلاع دارم!
کنترل صوتی دسترسی را افزایش میدهد و به افراد با محدودیتهای حرکتی اجازه میدهد با دستگاهها تعامل داشته باشند. چه این محدودیت دائمی باشد، مانند نداشتن دست از بدو تولد، یا موقتی باشد، مانند دست شکسته، یا حتی زمانی که دستانتان پر از خرید یا کودکان کوچک است، توانایی کنترل خانه با صدا به جای دستها دنیایی از دسترسی را باز میکند. فریاد زدن «هی سیری، درب گاراژم را ببند» در حالی که با تعویض پوشک کودک و یک کودک نوپا سرکش دست و پنجه نرم میکنید، میتواند یک بهبود کوچک اما مؤثر در زندگی باشد.
یکی از کاربردهای محبوب دستیارهای صوتی تنظیم تایمرها است، به خصوص تایمرهای آشپزخانه. توانایی تنظیم چندین تایمر فقط با صدای شما کمک بزرگی در آشپزخانه است - نیازی نیست که ورز دادن خمیر، هم زدن سوپ، یا پاک کردن مواد پر کردن دامپلینگ از دستانتان را متوقف کنید تا از تایمر فیزیکی استفاده کنید.
در این درس، شما یاد خواهید گرفت که چگونه تشخیص گفتار را در دستگاههای IoT پیادهسازی کنید. شما درباره میکروفونها به عنوان حسگرها، نحوه ضبط صدا از میکروفون متصل به دستگاه IoT، و نحوه استفاده از هوش مصنوعی برای تبدیل آنچه شنیده میشود به متن یاد خواهید گرفت. در طول این پروژه، شما یک تایمر هوشمند آشپزخانه خواهید ساخت که قادر به تنظیم تایمرها با استفاده از صدای شما و در چندین زبان است.
در این درس، موارد زیر را پوشش خواهیم داد:
میکروفونها
میکروفونها حسگرهای آنالوگ هستند که امواج صوتی را به سیگنالهای الکتریکی تبدیل میکنند. ارتعاشات در هوا باعث حرکت اجزای میکروفون به مقدار بسیار کم میشود و این تغییرات کوچک در سیگنالهای الکتریکی ایجاد میشود. این تغییرات سپس تقویت میشوند تا خروجی الکتریکی تولید شود.
انواع میکروفونها
میکروفونها در انواع مختلفی عرضه میشوند:
-
داینامیک - میکروفونهای داینامیک دارای یک آهنربا هستند که به یک دیافراگم متحرک متصل شده و در یک سیمپیچ حرکت میکند و جریان الکتریکی ایجاد میکند. این برعکس اکثر بلندگوها است که از جریان الکتریکی برای حرکت دادن یک آهنربا در سیمپیچ استفاده میکنند و دیافراگم را برای ایجاد صدا حرکت میدهند. این بدان معناست که بلندگوها میتوانند به عنوان میکروفونهای داینامیک استفاده شوند و میکروفونهای داینامیک میتوانند به عنوان بلندگوها استفاده شوند. در دستگاههایی مانند اینترکامها که کاربر یا گوش میدهد یا صحبت میکند، اما نه هر دو، یک دستگاه میتواند به عنوان بلندگو و میکروفون عمل کند.
میکروفونهای داینامیک برای کار کردن به برق نیاز ندارند، سیگنال الکتریکی کاملاً توسط میکروفون ایجاد میشود.

-
ریبون - میکروفونهای ریبون مشابه میکروفونهای داینامیک هستند، با این تفاوت که به جای دیافراگم یک نوار فلزی دارند. این نوار در یک میدان مغناطیسی حرکت میکند و جریان الکتریکی ایجاد میکند. مانند میکروفونهای داینامیک، میکروفونهای ریبون برای کار کردن به برق نیاز ندارند.

-
کندانسور - میکروفونهای کندانسور دارای یک دیافراگم فلزی نازک و یک صفحه پشتی فلزی ثابت هستند. برق به هر دوی اینها اعمال میشود و با ارتعاش دیافراگم، بار استاتیک بین صفحات تغییر میکند و سیگنال تولید میشود. میکروفونهای کندانسور برای کار کردن به برق نیاز دارند - که به آن Phantom power گفته میشود.
-
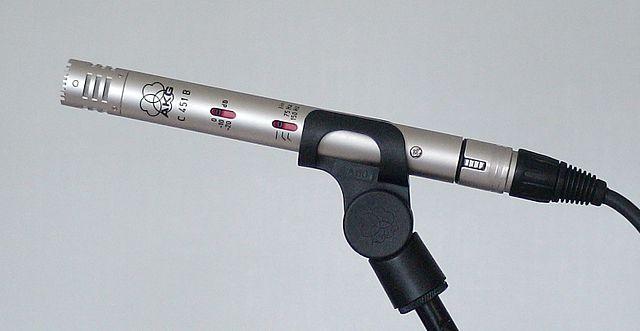
MEMS - میکروفونهای سیستمهای میکروالکترومکانیکی، یا MEMS، میکروفونهایی روی یک تراشه هستند. آنها دارای یک دیافراگم حساس به فشار هستند که روی یک تراشه سیلیکونی حک شده و مشابه یک میکروفون کندانسور کار میکنند. این میکروفونها میتوانند بسیار کوچک باشند و در مدارها ادغام شوند.

در تصویر بالا، تراشهای که با LEFT برچسبگذاری شده است یک میکروفون MEMS است، با یک دیافراگم کوچک که کمتر از یک میلیمتر عرض دارد.
✅ تحقیق کنید: چه میکروفونهایی در اطراف شما وجود دارند - چه در کامپیوتر، تلفن، هدست یا دستگاههای دیگر. این میکروفونها از چه نوعی هستند؟
صدای دیجیتال
صدا یک سیگنال آنالوگ است که اطلاعات بسیار دقیق و جزئی را حمل میکند. برای تبدیل این سیگنال به دیجیتال، صدا باید هزاران بار در ثانیه نمونهبرداری شود.
🎓 نمونهبرداری به معنای تبدیل سیگنال صوتی به یک مقدار دیجیتال است که نمایانگر سیگنال در آن لحظه زمانی است.
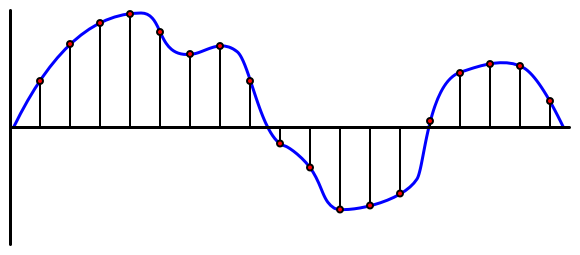
صدای دیجیتال با استفاده از مدولاسیون کد پالس، یا PCM، نمونهبرداری میشود. PCM شامل خواندن ولتاژ سیگنال و انتخاب نزدیکترین مقدار گسسته به آن ولتاژ با استفاده از یک اندازه تعریفشده است.
💁 میتوانید PCM را به عنوان نسخه حسگر مدولاسیون عرض پالس، یا PWM تصور کنید (PWM در درس ۳ پروژه شروع به کار پوشش داده شد). PCM شامل تبدیل یک سیگنال آنالوگ به دیجیتال است، PWM شامل تبدیل یک سیگنال دیجیتال به آنالوگ است.
برای مثال، اکثر سرویسهای پخش موسیقی صوتی ۱۶ بیتی یا ۲۴ بیتی ارائه میدهند. این بدان معناست که آنها ولتاژ را به مقداری تبدیل میکنند که در یک عدد صحیح ۱۶ بیتی یا ۲۴ بیتی جا میگیرد. صوت ۱۶ بیتی مقدار را در یک عدد در محدوده -۳۲,۷۶۸ تا ۳۲,۷۶۷ جا میدهد، صوت ۲۴ بیتی در محدوده −۸,۳۸۸,۶۰۸ تا ۸,۳۸۸,۶۰۷ قرار دارد. هرچه تعداد بیتها بیشتر باشد، نمونه به آنچه گوشهای ما واقعاً میشنوند نزدیکتر است.
💁 ممکن است درباره صوت ۸ بیتی شنیده باشید، که اغلب به عنوان LoFi شناخته میشود. این صوتی است که فقط با ۸ بیت نمونهبرداری شده است، بنابراین -۱۲۸ تا ۱۲۷. اولین صوت کامپیوتری به دلیل محدودیتهای سختافزاری به ۸ بیت محدود بود، بنابراین این اغلب در بازیهای قدیمی دیده میشود.
این نمونهها هزاران بار در ثانیه گرفته میشوند، با استفاده از نرخهای نمونهبرداری تعریفشده که بر حسب کیلوهرتز (هزاران خوانش در ثانیه) اندازهگیری میشوند. سرویسهای پخش موسیقی از ۴۸ کیلوهرتز برای اکثر صوتها استفاده میکنند، اما برخی صوتهای 'بدون افت کیفیت' تا ۹۶ کیلوهرتز یا حتی ۱۹۲ کیلوهرتز استفاده میکنند. هرچه نرخ نمونهبرداری بالاتر باشد، صوت به اصل خود نزدیکتر خواهد بود، تا حدی. بحثهایی وجود دارد که آیا انسانها میتوانند تفاوت بالای ۴۸ کیلوهرتز را تشخیص دهند یا خیر.
✅ تحقیق کنید: اگر از یک سرویس پخش موسیقی استفاده میکنید، نرخ نمونهبرداری و اندازه آن چیست؟ اگر از CD استفاده میکنید، نرخ نمونهبرداری و اندازه صوت CD چیست؟
فرمتهای مختلفی برای دادههای صوتی وجود دارد. احتمالاً درباره فایلهای mp3 شنیدهاید - دادههای صوتی که فشرده شدهاند تا کوچکتر شوند بدون از دست دادن کیفیت. صوت بدون فشردهسازی اغلب به صورت فایل WAV ذخیره میشود - این یک فایل با ۴۴ بایت اطلاعات هدر است، و پس از آن دادههای صوتی خام. هدر شامل اطلاعاتی مانند نرخ نمونهبرداری (برای مثال ۱۶۰۰۰ برای ۱۶ کیلوهرتز) و اندازه نمونه (۱۶ برای ۱۶ بیت)، و تعداد کانالها است. پس از هدر، فایل WAV دادههای صوتی خام را شامل میشود.
🎓 کانالها به تعداد جریانهای صوتی مختلفی که صوت را تشکیل میدهند اشاره دارد. برای مثال، برای صوت استریو با چپ و راست، ۲ کانال وجود خواهد داشت. برای صدای فراگیر ۷.۱ برای یک سیستم سینمای خانگی، این عدد ۸ خواهد بود.
اندازه دادههای صوتی
دادههای صوتی نسبتاً بزرگ هستند. برای مثال، ضبط صوت بدون فشردهسازی ۱۶ بیتی با نرخ ۱۶ کیلوهرتز (نرخی که برای استفاده با مدل تبدیل گفتار به متن کافی است)، برای هر ثانیه صوت ۳۲ کیلوبایت داده نیاز دارد:
- ۱۶ بیت به معنای ۲ بایت برای هر نمونه است (۱ بایت برابر با ۸ بیت است).
- ۱۶ کیلوهرتز برابر با ۱۶,۰۰۰ نمونه در ثانیه است.
- ۱۶,۰۰۰ x 2 بایت = ۳۲,۰۰۰ بایت در ثانیه.
این ممکن است مقدار کمی داده به نظر برسد، اما اگر از یک میکروکنترلر با حافظه محدود استفاده کنید، این میتواند زیاد باشد. برای مثال، Wio Terminal دارای ۱۹۲ کیلوبایت حافظه است، و این حافظه باید کد برنامه و متغیرها را ذخیره کند. حتی اگر کد برنامه شما کوچک باشد، نمیتوانید بیش از ۵ ثانیه صوت ضبط کنید.
میکروکنترلرها میتوانند به حافظه اضافی مانند کارتهای SD یا حافظه فلش دسترسی داشته باشند. هنگام ساخت یک دستگاه IoT که صوت ضبط میکند، باید اطمینان حاصل کنید که نه تنها حافظه اضافی دارید، بلکه کد شما صوت ضبطشده از میکروفون را مستقیماً به آن حافظه مینویسد، و هنگام ارسال آن به ابر، از حافظه به درخواست وب جریان میدهد. به این ترتیب میتوانید از تمام شدن حافظه با تلاش برای نگه داشتن کل بلوک دادههای صوتی در حافظه به طور همزمان جلوگیری کنید.
ضبط صوت از دستگاه IoT شما
دستگاه IoT شما میتواند به یک میکروفون متصل شود تا صوت ضبط کند، آماده برای تبدیل به متن. همچنین میتواند به بلندگوها متصل شود تا صوت خروجی تولید کند. در درسهای بعدی از این قابلیت برای ارائه بازخورد صوتی استفاده خواهد شد، اما اکنون تنظیم بلندگوها برای آزمایش میکروفون مفید است.
وظیفه - تنظیم میکروفون و بلندگوها
راهنمای مربوطه را دنبال کنید تا میکروفون و بلندگوها را برای دستگاه IoT خود تنظیم کنید:
وظیفه - ضبط صوت
راهنمای مربوطه را دنبال کنید تا صوت را روی دستگاه IoT خود ضبط کنید:
گفتار به متن
گفتار به متن، یا تشخیص گفتار، شامل استفاده از هوش مصنوعی برای تبدیل کلمات در یک سیگنال صوتی به متن است.
مدلهای تشخیص گفتار
برای تبدیل گفتار به متن، نمونههای سیگنال صوتی گروهبندی شده و به یک مدل یادگیری ماشین مبتنی بر شبکه عصبی بازگشتی (RNN) تغذیه میشوند. این نوعی مدل یادگیری ماشین است که میتواند از دادههای قبلی برای تصمیمگیری درباره دادههای ورودی استفاده کند. برای مثال، RNN میتواند یک بلوک از نمونههای صوتی را به عنوان صدای «Hel» تشخیص دهد، و وقتی بلوک دیگری را دریافت کند که فکر میکند صدای «lo» است، میتواند این را با صدای قبلی ترکیب کند، متوجه شود که «Hello» یک کلمه معتبر است و آن را به عنوان نتیجه انتخاب کند.
مدلهای یادگیری ماشین همیشه دادههایی با اندازه ثابت را هر بار میپذیرند. طبقهبندیکننده تصویری که در درس قبلی ساختید تصاویر را به اندازه ثابت تغییر اندازه میدهد و آنها را پردازش میکند. همین امر در مورد مدلهای گفتار نیز صدق میکند، آنها باید بلوکهای صوتی با اندازه ثابت را پردازش کنند. مدلهای گفتار باید بتوانند خروجیهای چندین پیشبینی را ترکیب کنند تا پاسخ را دریافت کنند، تا بتوانند بین «Hi» و «Highway»، یا «flock» و «floccinaucinihilipilification» تمایز قائل شوند.
مدلهای گفتار همچنین به اندازه کافی پیشرفته هستند که بتوانند زمینه را درک کنند و کلمات تشخیص دادهشده را با پردازش صداهای بیشتر اصلاح کنند. برای مثال، اگر بگویید «من به مغازهها رفتم تا دو موز بخرم و یک سیب هم»، شما سه کلمه را استفاده میکنید که صدای مشابهی دارند اما به صورت متفاوتی نوشته میشوند - to، two و too. مدلهای گفتار قادرند زمینه را درک کنند و از املای مناسب کلمه استفاده کنند. 💁 برخی از خدمات گفتار امکان سفارشیسازی را فراهم میکنند تا در محیطهای پر سر و صدا مانند کارخانهها یا با کلمات خاص صنعتی مانند نامهای شیمیایی بهتر عمل کنند. این سفارشیسازیها با ارائه نمونههای صوتی و متن مربوطه آموزش داده میشوند و از یادگیری انتقالی استفاده میکنند، مشابه روشی که در درس قبلی یک طبقهبند تصویر را تنها با چند تصویر آموزش دادید.
حریم خصوصی
هنگام استفاده از تبدیل گفتار به متن در یک دستگاه مصرفی اینترنت اشیا، حریم خصوصی اهمیت بسیار زیادی دارد. این دستگاهها به طور مداوم به صدا گوش میدهند، بنابراین به عنوان یک مصرفکننده نمیخواهید هر چیزی که میگویید به فضای ابری ارسال شده و به متن تبدیل شود. این نه تنها پهنای باند اینترنت زیادی مصرف میکند، بلکه پیامدهای بزرگی برای حریم خصوصی دارد، به خصوص زمانی که برخی سازندگان دستگاههای هوشمند به طور تصادفی صداها را برای بررسی توسط انسانها و تطبیق با متن تولید شده برای بهبود مدل خود انتخاب میکنند.
شما فقط میخواهید دستگاه هوشمندتان زمانی که از آن استفاده میکنید، صدا را برای پردازش به فضای ابری ارسال کند، نه زمانی که صدایی در خانه شما میشنود، صدایی که ممکن است شامل جلسات خصوصی یا تعاملات صمیمانه باشد. روش کار اکثر دستگاههای هوشمند با یک کلمه بیدارکننده است، یک عبارت کلیدی مانند "الکسا"، "هی سیری"، یا "اوکی گوگل" که باعث میشود دستگاه 'بیدار شود' و به آنچه میگویید گوش دهد تا زمانی که وقفهای در گفتار شما تشخیص دهد، که نشان میدهد صحبت شما با دستگاه تمام شده است.
🎓 تشخیص کلمه بیدارکننده همچنین به عنوان شناسایی کلمه کلیدی یا تشخیص کلمه کلیدی شناخته میشود.
این کلمات بیدارکننده در خود دستگاه تشخیص داده میشوند، نه در فضای ابری. این دستگاههای هوشمند مدلهای کوچک هوش مصنوعی دارند که روی دستگاه اجرا میشوند و به کلمه بیدارکننده گوش میدهند، و زمانی که تشخیص داده شد، شروع به ارسال صدا به فضای ابری برای شناسایی میکنند. این مدلها بسیار تخصصی هستند و فقط به کلمه بیدارکننده گوش میدهند.
💁 برخی شرکتهای فناوری در حال افزودن حریم خصوصی بیشتر به دستگاههای خود هستند و بخشی از تبدیل گفتار به متن را روی دستگاه انجام میدهند. اپل اعلام کرده است که به عنوان بخشی از بهروزرسانیهای iOS و macOS در سال 2021، از تبدیل گفتار به متن روی دستگاه پشتیبانی خواهد کرد و قادر خواهد بود بسیاری از درخواستها را بدون نیاز به استفاده از فضای ابری مدیریت کند. این به لطف داشتن پردازندههای قدرتمند در دستگاههایشان است که میتوانند مدلهای یادگیری ماشین را اجرا کنند.
✅ به نظر شما پیامدهای حریم خصوصی و اخلاقی ذخیره صداهایی که به فضای ابری ارسال میشوند چیست؟ آیا این صداها باید ذخیره شوند، و اگر بله، چگونه؟ آیا استفاده از ضبطها برای اجرای قانون معامله خوبی برای از دست دادن حریم خصوصی است؟
تشخیص کلمه بیدارکننده معمولاً از تکنیکی به نام TinyML استفاده میکند، که تبدیل مدلهای یادگیری ماشین به گونهای است که بتوانند روی میکروکنترلرها اجرا شوند. این مدلها کوچک هستند و مصرف انرژی بسیار کمی دارند.
برای جلوگیری از پیچیدگی آموزش و استفاده از مدل کلمه بیدارکننده، تایمر هوشمندی که در این درس میسازید از یک دکمه برای فعال کردن تشخیص گفتار استفاده خواهد کرد.
💁 اگر میخواهید یک مدل تشخیص کلمه بیدارکننده ایجاد کنید که روی Wio Terminal یا Raspberry Pi اجرا شود، این آموزش پاسخ به صدای شما توسط Edge Impulse را بررسی کنید. اگر میخواهید این کار را با کامپیوتر خود انجام دهید، میتوانید شروع سریع با کلمه کلیدی سفارشی در مستندات مایکروسافت را امتحان کنید.
تبدیل گفتار به متن
![]()
مانند طبقهبندی تصویر در پروژه قبلی، خدمات هوش مصنوعی از پیش ساختهای وجود دارند که میتوانند گفتار را به عنوان یک فایل صوتی دریافت کرده و به متن تبدیل کنند. یکی از این خدمات، سرویس گفتار است که بخشی از خدمات شناختی، خدمات هوش مصنوعی از پیش ساختهای است که میتوانید در برنامههای خود استفاده کنید.
وظیفه - پیکربندی یک منبع هوش مصنوعی گفتار
-
یک گروه منابع برای این پروژه با نام
smart-timerایجاد کنید. -
از دستور زیر برای ایجاد یک منبع گفتار رایگان استفاده کنید:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location><location>را با مکانی که هنگام ایجاد گروه منابع استفاده کردید جایگزین کنید. -
برای دسترسی به منبع گفتار از کد خود، به یک کلید API نیاز دارید. دستور زیر را اجرا کنید تا کلید را دریافت کنید:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableیکی از کلیدها را کپی کنید.
وظیفه - تبدیل گفتار به متن
راهنمای مربوطه را برای تبدیل گفتار به متن روی دستگاه اینترنت اشیای خود دنبال کنید:
🚀 چالش
تشخیص گفتار مدتهاست که وجود دارد و به طور مداوم در حال بهبود است. قابلیتهای فعلی را بررسی کنید و مقایسه کنید که چگونه این قابلیتها در طول زمان تکامل یافتهاند، از جمله اینکه دقت تبدیلهای ماشینی در مقایسه با انسانها چگونه است.
به نظر شما آینده تشخیص گفتار چگونه خواهد بود؟
آزمون پس از درس
مرور و مطالعه شخصی
- درباره انواع مختلف میکروفونها و نحوه کار آنها در مقاله تفاوت بین میکروفونهای دینامیک و کندانسور در Musician's HQ بخوانید.
- اطلاعات بیشتری درباره سرویس گفتار خدمات شناختی در مستندات سرویس گفتار در Microsoft Docs بخوانید.
- درباره شناسایی کلمه کلیدی در مستندات شناسایی کلمه کلیدی در Microsoft Docs بخوانید.
تکلیف
سلب مسئولیت:
این سند با استفاده از سرویس ترجمه هوش مصنوعی Co-op Translator ترجمه شده است. در حالی که ما تلاش میکنیم دقت را حفظ کنیم، لطفاً توجه داشته باشید که ترجمههای خودکار ممکن است شامل خطاها یا نادرستیها باشند. سند اصلی به زبان اصلی آن باید به عنوان منبع معتبر در نظر گرفته شود. برای اطلاعات حیاتی، ترجمه حرفهای انسانی توصیه میشود. ما مسئولیتی در قبال سوء تفاهمها یا تفسیرهای نادرست ناشی از استفاده از این ترجمه نداریم.