|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
Настройте таймер и предоставете гласова обратна връзка
Скица от Nitya Narasimhan. Кликнете върху изображението за по-голяма версия.
Тест преди лекцията
Въведение
Умните асистенти не са устройства за еднопосочна комуникация. Вие говорите с тях, а те отговарят:
"Alexa, настрой таймер за 3 минути"
"Добре, вашият таймер е настроен за 3 минути"
В последните два урока научихте как да преобразувате реч в текст и след това да извлечете заявка за настройка на таймер от този текст. В този урок ще научите как да настроите таймера на IoT устройството, като отговорите на потребителя с гласови думи, потвърждаващи техния таймер, и го уведомите, когато таймерът изтече.
В този урок ще разгледаме:
Текст към реч
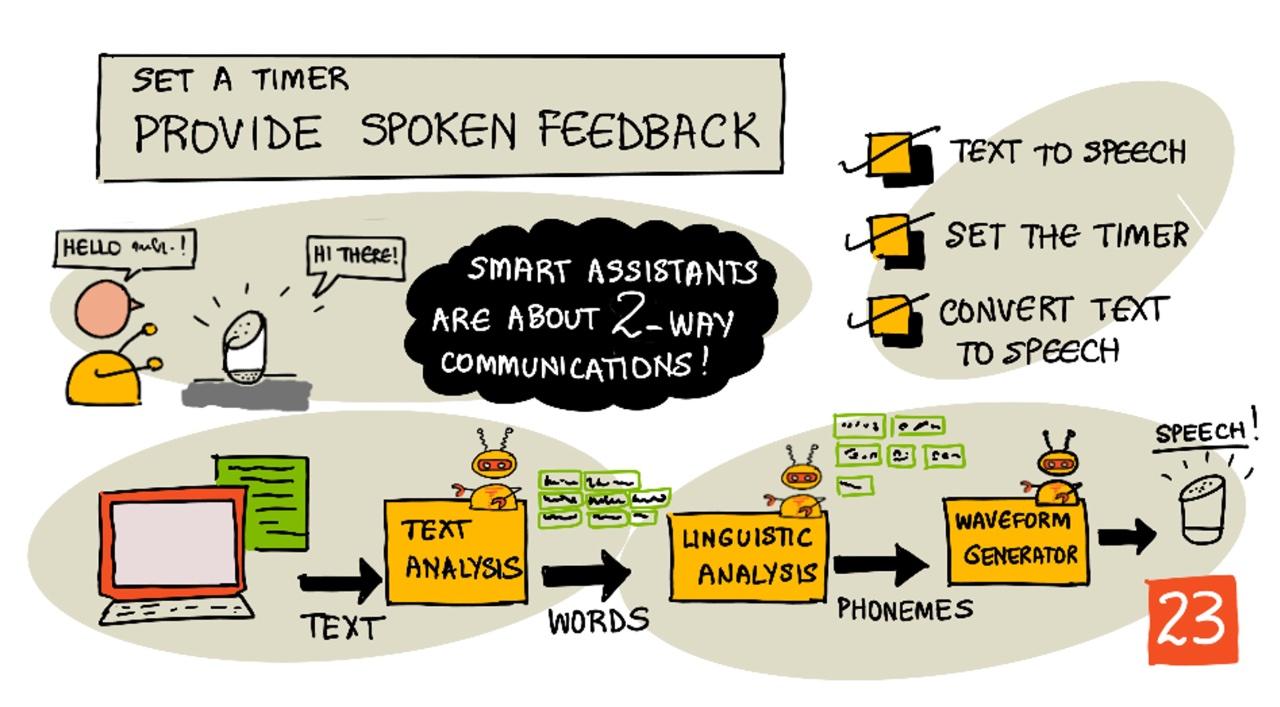
Текст към реч, както подсказва името, е процесът на преобразуване на текст в аудио, което съдържа текста като изговорени думи. Основният принцип е да се разбият думите в текста на техните съставни звуци (известни като фонеми) и да се съединят аудио записи за тези звуци, използвайки предварително записано аудио или аудио, генерирано от AI модели.

Системите за текст към реч обикновено имат 3 етапа:
- Анализ на текста
- Лингвистичен анализ
- Генериране на звукова вълна
Анализ на текста
Анализът на текста включва вземане на предоставения текст и преобразуването му в думи, които могат да се използват за генериране на реч. Например, ако преобразувате "Hello world", не е необходим анализ на текста, двете думи могат директно да се преобразуват в реч. Ако обаче имате "1234", това може да се наложи да бъде преобразувано или в думите "Хиляда двеста тридесет и четири", или "Едно, две, три, четири" в зависимост от контекста. За "Имам 1234 ябълки" ще бъде "Хиляда двеста тридесет и четири", но за "Детето преброи 1234" ще бъде "Едно, две, три, четири".
Думите, които се създават, варират не само за езика, но и за локалния диалект на този език. Например, в американския английски 120 би било "One hundred twenty", докато в британския английски би било "One hundred and twenty", с използване на "and" след стотиците.
✅ Някои други примери, които изискват анализ на текста, включват "in" като съкращение за инч и "st" като съкращение за светец или улица. Можете ли да измислите други примери на вашия език за думи, които са двусмислени без контекст?
След като думите са дефинирани, те се изпращат за лингвистичен анализ.
Лингвистичен анализ
Лингвистичният анализ разбива думите на фонеми. Фонемите се базират не само на използваните букви, но и на другите букви в думата. Например, в английския звукът на 'a' в 'car' и 'care' е различен. Английският език има 44 различни фонеми за 26-те букви в азбуката, някои от които се споделят от различни букви, като например същият фонем, използван в началото на 'circle' и 'serpent'.
✅ Направете проучване: Какви са фонемите за вашия език?
След като думите са преобразувани във фонеми, тези фонеми се нуждаят от допълнителни данни за интонация, като се коригира тонът или продължителността в зависимост от контекста. Един пример е, че в английския език повишаването на тона може да се използва за превръщане на изречение във въпрос, като повишеният тон на последната дума предполага въпрос.
Например - изречението "You have an apple" е твърдение, че имате ябълка. Ако тонът се повиши в края, увеличавайки се за думата apple, то става въпрос "You have an apple?", питащ дали имате ябълка. Лингвистичният анализ трябва да използва въпросителния знак в края, за да реши да повиши тона.
След като фонемите са генерирани, те могат да бъдат изпратени за генериране на звукова вълна, за да се произведе аудио изходът.
Генериране на звукова вълна
Първите електронни системи за текст към реч използваха единични аудио записи за всеки фонем, което водеше до много монотонни, роботизирани гласове. Лингвистичният анализ произвеждаше фонеми, които се зареждаха от база данни със звуци и се съединяваха, за да създадат аудио.
✅ Направете проучване: Намерете някои аудио записи от ранни системи за синтез на реч. Сравнете ги със съвременния синтез на реч, като този, използван в умните асистенти.
По-модерното генериране на звукова вълна използва ML модели, изградени с дълбоко обучение (много големи невронни мрежи, които действат по подобен начин на невроните в мозъка), за да произведе по-естествено звучащи гласове, които могат да бъдат неразличими от човешките.
💁 Някои от тези ML модели могат да бъдат пренастроени с помощта на трансферно обучение, за да звучат като реални хора. Това означава, че използването на глас като система за сигурност, нещо, което банките все повече се опитват да направят, вече не е добра идея, тъй като всеки с няколко минути запис на вашия глас може да ви имитира.
Тези големи ML модели се обучават да комбинират и трите стъпки в крайни синтезатори на реч.
Настройка на таймера
За да настроите таймера, вашето IoT устройство трябва да извика REST крайна точка, която сте създали с помощта на сървърлес код, след което да използва получения брой секунди, за да настрои таймер.
Задача - извикване на сървърлес функция за получаване на време за таймера
Следвайте съответното ръководство, за да извикате REST крайна точка от вашето IoT устройство и да настроите таймер за необходимото време:
Преобразуване на текст в реч
Същата услуга за реч, която използвахте за преобразуване на реч в текст, може да се използва за преобразуване на текст обратно в реч, която може да се възпроизведе през високоговорител на вашето IoT устройство. Текстът за преобразуване се изпраща до услугата за реч, заедно с типа на необходимото аудио (като честота на семплиране), и се връщат двоични данни, съдържащи аудиото.
Когато изпращате тази заявка, използвате Speech Synthesis Markup Language (SSML), XML-базиран език за маркиране за приложения за синтез на реч. Това определя не само текста, който да бъде преобразуван, но и езика на текста, гласа, който да се използва, и дори може да се използва за определяне на скорост, сила на звука и тон за някои или всички думи в текста.
Например, този SSML определя заявка за преобразуване на текста "Вашият таймер за 3 минути и 5 секунди е настроен" в реч, използвайки британски английски глас, наречен en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Повечето системи за текст към реч имат множество гласове за различни езици, с подходящи акценти, като британски английски глас с английски акцент и новозеландски английски глас с новозеландски акцент.
Задача - преобразуване на текст в реч
Работете по съответното ръководство, за да преобразувате текст в реч, използвайки вашето IoT устройство:
- Arduino - Wio Terminal
- Едноплатков компютър - Raspberry Pi
- Едноплатков компютър - Виртуално устройство
🚀 Предизвикателство
SSML има начини да променя начина, по който думите се произнасят, като добавяне на акцент върху определени думи, добавяне на паузи или промяна на тона. Опитайте някои от тези възможности, като изпратите различни SSML от вашето IoT устройство и сравните резултатите. Можете да прочетете повече за SSML, включително как да промените начина, по който думите се произнасят, в Speech Synthesis Markup Language (SSML) Version 1.1 specification от World Wide Web Consortium.
Тест след лекцията
Преглед и самостоятелно обучение
- Прочетете повече за синтеза на реч на страницата за синтез на реч в Wikipedia
- Прочетете повече за начините, по които престъпниците използват синтез на реч, за да крадат, в статията на BBC за фалшиви гласове
- Научете повече за рисковете за гласовите актьори от синтезирани версии на техните гласове в статията на Vice за TikTok и AI
Задание
Отказ от отговорност:
Този документ е преведен с помощта на AI услуга за превод Co-op Translator. Въпреки че се стремим към точност, моля, имайте предвид, че автоматичните преводи може да съдържат грешки или неточности. Оригиналният документ на неговия изходен език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален превод от човек. Ние не носим отговорност за каквито и да било недоразумения или погрешни интерпретации, произтичащи от използването на този превод.