18 KiB
डेटा का अवलोकन
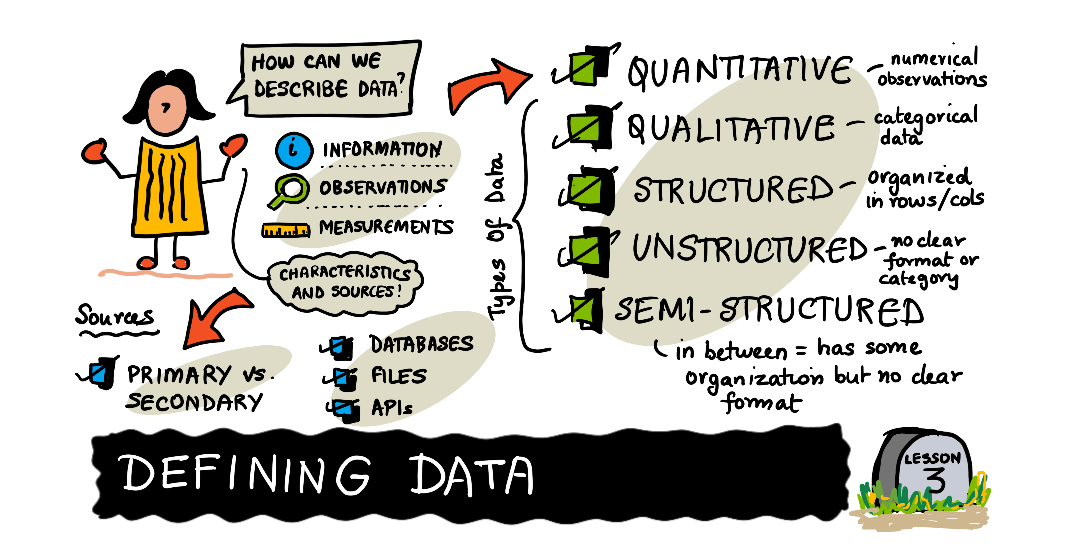 |
|---|
| डेटा का अवलोकन - Sketchnote by @nitya |
डेटा मतलब तथ्य, ज्ञान और अनुभव है जिनका इस्तेमाल करके नए खोज और सूचित निर्णयोंका समर्थन किया जाता है।
डेटा पॉइंट यह डेटासेट का सबसे छोटा प्रमाण है। डेटासेट यह एक डेटा पॉइंट्स का बड़ा संग्रह होता है। डेटासेट बहुत सारे अलगअलग प्रकार और संरचनाका होता है, और बहुत बार किसी स्त्रोत पे आधारित होता है। उदाहरण के लिए, किसी कम्पनी की कमाई स्प्रेडशीट मैं जतन की हो सकती है मगर प्रति घंटे के दिल की धकड़न की गति JSON रूप मैं हो सकती है। डेटा वैज्ञानिकों केलिए अलग अलग प्रकार के डेटा और डेटासेट के साथ काम करना आम बात होती है।
यह पाठ डेटा को उसके स्त्रोत के हिसाब से पहचानने और वर्गीकृत करने पर केंद्रित है।
पाठ के पूर्व की परीक्षा
डेटा का वर्णन कैसे किया जाता है
अपरीपक्व डेटा ऐसे प्रकार का डेटा होता जो उसके स्त्रोत से आते वक्त जिस अवस्था में था वैसे ही है और उसका विश्लेषण या वर्गीकरण नहीं किया गया है। ऐसे डेटासेट से जरूरी जानकारी निकलने के लिए उसे ऐसे प्रकार मे लाना आवश्यक है जो इंसान समझ सके और जिस तंत्रज्ञान का उपयोग डेटा के विश्लेषण में किया जाएगा उसको भी समझ आये। डेटाबेस की संरचना हमें बताती है कि डेटा किस प्रकार से वर्गीकृत किया गया है और उसका संरचित, मिश्र संरचित और असंरचित प्रकार में वर्गीकरण कैसे किया जाता है। संरचना के प्रकार डेटा के स्त्रोत के अनुसार बदल सकते हैं मगर आखिर में इन तीनों में से एक प्रकार के हो सकते हैं।
परिमाणात्मक डेटा
परिमाणात्मक डेटा मतलब डेटासेट में उपलब्ध होने वाला ऐसा संख्यात्मक डेटा जिसका उपयोग विश्लेषण, मापन और गणितीय चीजों के लिए हो सकता है। परिमाणात्मक डेटा के यह कुछ उदाहरण हैं: देश की जनसंख्या, इंसान की कद या कंपनी की तिमाही कमाई। थोडे अधिक विश्लेषण बाद डेटा की परिस्थिति के अनुसार वायुगुणवत्ता सूचकांक का बदलाव पता करना या फिर किसी सामान्य दिन पर व्यस्त ट्रैफिक की संभावना का अनुमान लगाना मुमकिन है।
गुणात्मक डेटा
गुणात्मक डेटा, जिसे वर्गीकृत डेटा भी कहा जाता है, यह एक डेटा का ऐसा प्रकार है जिसे परिमाणात्मक डेटा की तरह वस्तुनिष्ठ तरह से नापा नहीं जा सकता। यह आम तौर पर अलग अलग प्रकार का आत्मनिष्ठ डेटा होता है जैसे से किसी उत्पादन या प्रक्रिया की गुणवत्ता। कभी कभी गुणात्मक डेटा सांख्यिक स्वरुप में हो के भी गणितीय कारणों के लिए इस्तेमाल नहीं किया जा सकता, जैसे की फोन नंबर या समय। गुणात्मक डेटा के यह कुछ उदाहरण हो सकते है: विडियो की टिप्पणियाँ, किसी गाड़ी का मॉडल या आपके प्रीय दोस्त का पसंदिदा रंग। गुणात्मक डेटा का इस्तेमाल करके ग्राहकौं को कोनसा उत्पादन सबसे ज्यादा पसंद आता है या फिर नौकरी आवेदन के रिज्यूमे में सबसे ज्यादा इस्तेमाल होने वाले शब्द ढूंढ़ना।
संरचित डेटा
संरचित डेटा वह डेटा है जो पंक्तियों और स्तंभों में संगठित होता है, जिसके हर पंक्ति में समान स्तंभ होते है। हर स्तंभ एक विशिष्ट प्रकार के मूल्य को बताता है और उस मूल्य को दर्शाने वाले नाम के साथ जाना जाता है। जबकि पंक्तियौं में वास्तविक मूल्य होते है। हर मूल्य सही स्तंभ का प्रतिनिधित्व करते हैं कि नहीं ये निश्चित करने के लिए स्तंभ में अक्सर मूल्यों पर नियमों का प्रतिबन्ध लगा रहता है। उदाहरणार्थ कल्पना कीजिये ग्राहकों की जानकारी होने वाला एक स्प्रेडशीट फ़ाइल जिसके हर पंक्ति में फोन नंबर होना जरुरी है और फोन नंबर में कभी भी अक्षर नहीं रहते। तो फिर फोन नंबर के स्तंभ पर ऐसा नियम लगा होना चाहिए जिससे यह निश्चित हो कि वह कभी भी खाली नहीं रहता है और उसमें सिर्फ आँकडे ही है ।
सरंचित डेटा का यह फायदा है की उसे स्तंभ और पंक्तियों में संयोजित किया जा सकता है। तथापि, डेटा को एक विशिष्ट प्रकार में संयोजित करने के लिए आयोजित किये जाने के वजह से पुरे संरचना में बदल करना बहुत मुश्किल काम होता है। जैसे की ग्राहकों के जानकारी वाले स्प्रेडशीट फ़ाइलमें अगर हमें ईमेल आयडी खाली ना होने वाला नया स्तंभ जोड़ना हो, तो हमे ये पता करना होगा की पहिले से जो मूल्य इस डेटासेट में है उनका क्या होगा?
संरचित डेटा के यह कुछ उदाहरण हैं: स्प्रेडशीट, रिलेशनल डेटाबेस, फोन नंबर एवं बैंक स्टेटमेंट ।
असंरचित डेटा
असंरचित डेटा आम तौर पर स्तंभ और पंक्तियों में वर्गीकृत नहीं किया जा सकता और किसी नियमों से बंधित भी नहीं रहता। संरचित डेटा के तुलना में असंरचित डेटा में कम नियम होने के कारण उसमे नया डेटा जोडना बहुत आसान होता है। अगर कोई सेंसर जो बैरोमीटर के दबाव को हर दो मिनट के बाद दर्ज करता है, जिसकी वजह से वह दाब को माप के दर्ज कर सकता है, तो उसे असंरचित डेटा होने के कारण डेटाबेस में पहलेसे उपलब्ध डेटा को बदलने की आवश्यकता नहीं है। तथापि, ऐसे डेटा का विश्लेषण और जाँच करने में ज्यादा समय लग सकता है।
जैसे की, एक वैज्ञानिक जिसे सेंसर के डेटा से पिछले महीने के तापमान का औसत ढूंढ़ना हो, मगर वो देखता है की सेंसर ने कुछ जगह आधे अधूरे डेटा को दर्ज करने के लिए आम क्रमांक के विपरीत 'e' दर्ज किया है, जिसका मतलब है की डेटा अपूर्ण है।
असंरचित डेटा के उदाहरण: टेक्स्ट फ़ाइलें, टेक्स्ट मेसेजेस, विडियो फ़ाइलें।
मिश्र संरचित डेटा
मिश्र संरचित डेटा के ऐसे कुछ गुण है जिसकी वजह से उसे संरचित और असंरचित डेटा का मिश्रण कहा जा सकता हैं। वह हमेशा स्तंभ और पंक्तियों के अनुरूप नहीं रहता मगर ऐसे तरह संयोजित किया गया होता है कि उसे संरचित कहा जा सकता है और शायद अन्य निर्धारित नियमों का पालन भी करता है। डेटा की संरचना उसके स्त्रोत के ऊपर निर्भर होती है जैसे की स्पष्ट अनुक्रम या फिर थोडा परिवर्तनशील होता है जिसमे नया डेटा जोड़ना आसान हो। मेटाडेटा ऐसे संकेतांक होते हैं जिससे डेटा का संयोजन और संग्रह करना आसान होता है, और उन्हें डेटा के प्रकार के अनुरूप नाम भी दिए जा सकते हैं । मेटाडेटा के आम उदाहरण है: टैग्स, एलिमेंट्स, एंटिटीज और एट्रीब्यूट्स.
उदाहरणार्थ: एक सामान्य ईमेल को उसका विषय, मायना, और प्राप्तकर्ताओं की सूची होगी और किससे कब भेजना है उसके प्रमाण से संयोजित किया जा सकता है।
मिश्र संरचित डेटा के उदाहरण: एचटीएमएल, सीइसवी फाइलें, जेसन(JSON)
डेटा के स्त्रोत
डेटा का स्त्रोत, अर्थात वो जगह जहाँ डेटा सबसे पहिली बार निर्माण हुआ था, और हमेशा कहाँ और कब जमा किया था इसपर आधारित होगा। उपयोगकर्ता के द्वारा निर्माण किये हुए डेटा को प्राथमिक डेटा के नाम से पहचाना जाता है जबकि गौण डेटा ऐसे स्त्रोत से आता है जिसने सामान्य कार्य के लिए डेटा जमा किया था। उदाहरण के लिए, वैज्ञानिकों का समूह वर्षावन में टिप्पणियों और सूचि जमा कर रहे है तो वो प्राथमिक डेटा होगा और यदि उन्होंने उस डेटा को बाकि के वैज्ञनिको के साथ बाँटना चाहा तो वो वह गौण डेटा कहलाया जायेगा।
डेटाबेस यह एक सामान्य स्त्रोत है और वह होस्टिंग और डेटाबेस मेंटेनन्स सिस्टिम पर निर्भर होता है। डेटाबेस मेंटेनन्स सिस्टिम में उपयोगकर्ता कमांड्स, जिन्हें ‘क्वेरीज़’ कहा जाता है इस्तेमाल करके डेटाबेस का डेटा ढूंढ सकते हैं। डेटा स्त्रोत फ़ाइल स्वरुप में हो, तो आवाज, चित्र, वीडियो, स्प्रेडशीट ऐसे प्रकार में हो सकता है। अंतरजाल के स्त्रोत डेटा होस्ट करने का बहुत आम तरीका है। यहाँ डेटाबेस तथा फाइलें ढूंढी जा सकती है। एप्लीकेशन प्रोग्रामिंग इंटरफेस, जिन्हे 'एपीआय'(API) के नाम से जाना जाता है, उसकी मदद से प्रोग्रामर्स डेटा को बाहर के उपयोगकर्ताओं को अंतरजाल द्वारा इस्तेमाल करने के लिए भेज सकते हैं। जबकि वेब स्क्रैपिंग नामक प्रक्रिया से अंतरजाल के वेब पेज का डेटा अलग किया जा सकता है। डेटा के साथ काम करना यह पाठ अलग अलग डेटा का इस्तेमाल करने पर ध्यान देता है।
निष्कर्ष
यह पाठ में हमने पढ़ा कि:
- डेटा क्या होता है
- डेटा का वर्णन कैसे किया जाता है
- डेटा का वर्गीकरण कैसे किया जाता है
- डेटा कहा मिलता है
🚀 चुनौती
Kaggle यह के मुक्त डेटाबेस का बहुत अच्छा स्त्रोत है। सर्च टूल का इस्तेमाल करके कुछ मजेदार डेटासेट ढूंढे और उनमे से तीन-चार डेटाबेस को ऐसे वर्गीकृत करे:
- डेटा परिमाणात्मक है या गुणात्मक है?
- डेटा संरचित, असंरचित या फिर मिश्र संरचित है?
पाठ के पश्चात परीक्षा
समीक्षा और स्वअध्ययन
- माइक्रोसॉफ्ट लर्न का Classify your data पाठ संरचित, असंरचित और मिश्र संरचित डेटा के बारे में और अच्छे से बताता है।