8.8 KiB
데이터 정의
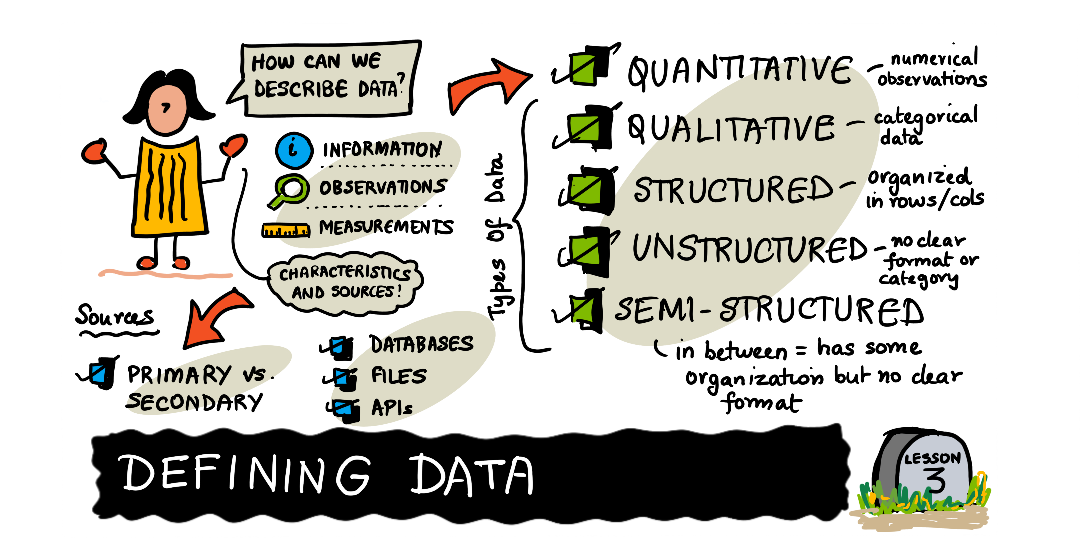 |
|---|
| 데이터 정의 - Sketchnote 작성자 @nitya |
데이터는 발견을 하고 정보에 입각한 결정을 지원하는 데 사용되는 사실, 정보, 관찰 및 측정입니다. 데이터 포인트는 데이터 포인트의 모음인 데이터셋(Data Set)에 있는 단일 데이터 단위입니다. 데이터셋은 다양한 형식과 구조로 제공될 수 있으며 일반적으로 소스 또는 데이터의 출처를 기반으로 합니다. 예를 들어 회사의 월별 수입은 스프레드시트에 있지만 스마트워치의 시간당 심박수 데이터는 JSON 형식일 수 있습니다. 데이터 과학자는 데이터셋 내에서 다양한 유형의 데이터로 작업하는 것이 일반적입니다.
이 단원에서는 데이터의 특성과 소스를 기준으로 데이터를 식별하고 분류하는 데 중점을 둡니다.
강의 전 퀴즈
데이터 설명 방법
원시 데이터는 초기 상태의 소스에서 가져온, 분석이나 구조화되지 않은 데이터입니다. 데이터셋에서 무슨 일이 일어나고 있는지 이해하기 위해서는 데이터셋를 인간이 이해할 수 있는 형식과 추가 분석에 사용할 수 있는 기술로 구성해야 합니다. 데이터셋의 구조는 구성 방법을 설명하고 구조화, 비구조화 및 반구조화로 분류할 수 있습니다. 이러한 유형의 구조는 출처에 따라 다르지만 궁극적으로 이 세 가지 범주에 맞습니다.
정량적 데이터
정량적 데이터는 데이터셋 내의 수치적 관찰이며 일반적으로 수학적인 분석, 측정 및 사용할 수 있습니다. 정량적 데이터의 몇 가지 예는 다음과 같습니다: 국가의 인구, 개인의 키 또는 회사의 분기별 수입. 몇 가지 추가 분석을 통해 정량적 데이터에서 AQI(대기 질 지수)의 계절적 추세를 발견하거나 일반적인 근무일의 러시아워 교통량 확률을 추정할 수 있습니다.
정성 데이터
범주형 데이터라고도 하는 정성적 데이터는 정량적 데이터의 관찰과 같이 객관적으로 측정할 수 없는 데이터입니다. 일반적으로 제품이나 프로세스와 같은 무언가의 품질을 나타내는 주관적 데이터의 다양한 형식입니다. 경우에 따라 정성적 데이터는 숫자이며 일반적으로 전화번호나 타임스탬프와 같이 수학적으로 사용되지 않습니다. 정성적 데이터의 몇 가지 예는 다음과 같습니다: 비디오 댓글, 자동차 제조사 및 모델 또는 가장 친한 친구가 가장 좋아하는 색상. 정성적 데이터는 소비자가 가장 좋아하는 제품을 이해하거나 입사 지원 이력서에서 인기 있는 키워드를 식별하는 데 사용할 수 있습니다.
구조화된 데이터
구조화된 데이터는 행과 열로 구성된 데이터로, 각 행에는 동일한 열 집합이 있습니다. 열은 특정 유형의 값을 나타내며 값이 나타내는 것을 설명하는 이름으로 식별되는 반면 행에는 실제 값이 포함됩니다. 열에는 값이 열을 정확하게 나타내도록 하기 위해 값에 대한 특정 규칙 또는 제한 사항이 있는 경우가 많습니다. 예를 들어, 각 행에 전화번호가 있어야 하고 전화번호에는 알파벳 문자가 포함되지 않는 고객 스프레드시트를 상상해 보십시오. 전화번호 열이 비어 있지 않고 숫자만 포함되도록 하는 규칙이 적용될 수 있습니다.
구조화된 데이터의 이점은 다른 구조화된 데이터와 관련될 수 있는 방식으로 구성될 수 있다는 것입니다. 그러나 데이터가 특정 방식으로 구성되도록 설계되었기 때문에 전체 구조를 변경하려면 많은 노력이 필요할 수 있습니다. 예를 들어 비워둘 수 없는 이메일 열을 고객 스프레드시트에 추가한다는 것은 이러한 값을 데이터세트의 기존 고객 행에 추가하는 방법을 파악해야 함을 의미합니다.
구조화된 데이터의 예: 스프레드시트, 관계형 데이터베이스, 전화번호, 은행 거래 내역
비정형 데이터
비정형 데이터는 일반적으로 행이나 열로 분류할 수 없으며 따라야 할 형식이나 규칙 집합을 포함하지 않습니다. 구조화되지 않은 데이터는 구조에 대한 제한이 적기 때문에 구조화된 데이터세트에 비해 새로운 정보를 추가하는 것이 더 쉽습니다. 2분마다 기압 데이터를 캡처하는 센서가 이제 온도를 측정하고 기록할 수 있는 업데이트를 수신한 경우 구조화되지 않은 기존 데이터를 변경할 필요가 없습니다. 그러나 이렇게 하면 이러한 유형의 데이터를 분석하거나 조사하는 데 시간이 더 오래 걸릴 수 있습니다. 예를 들어, 센서 데이터에서 전월 평균 온도를 찾고자 하는 과학자가 센서가 기록된 데이터 중 일부에 "e"를 기록하여 일반적인 숫자가 아닌 파손된 것을 확인하는 것을 발견했습니다. 데이터가 불완전하다는 것을 의미합니다.
비정형 데이터의 예: 텍스트 파일, 문자 메시지, 비디오 파일
반구조화
반정형 데이터에는 정형 데이터와 비정형 데이터가 결합된 기능이 있습니다. 일반적으로 행과 열의 형식을 따르지 않지만 구조화된 것으로 간주되고 고정 형식이나 일련의 규칙을 따를 수 있는 방식으로 구성됩니다. 구조는 소스에 따라 다양해지는데, 잘 정의된 계층에서 새로운 정보를 쉽게 통합할 수 있는 보다 유연한 형태같은 것이 있습니다. 메타데이터는 데이터가 구성되고 저장되는 방식을 결정하는 데 도움이 되는 지표이며 데이터 유형에 따라 다양한 이름을 갖게 됩니다. 메타데이터의 일반적인 이름에는 태그, 요소(elements), 엔터티(entity) 및 속성(attribute)이 있습니다. 예를 들어 일반적인 전자 메일 메시지에는 제목, 본문 및 수신자 집합이 있으며 보낸 사람 또는 보낸 시간을 구성할 수 있습니다.
반구조화된 데이터의 예: HTML, CSV 파일, JSON(JavaScript Object Notation)
데이터 소스
데이터 소스는 데이터가 생성된 초기 위치 또는 데이터가 "살아 있는" 위치이며 수집 방법과 시기에 따라 달라집니다. 사용자가 생성한 데이터를 1차 데이터라고 하고 2차 데이터는 일반 사용을 위해 데이터를 수집한 소스에서 가져옵니다. 예를 들어, 열대 우림에서 관찰을 수집하는 과학자 그룹은 기본으로 간주되며 다른 과학자와 공유하기로 결정한 경우 이를 사용하는 과학자 그룹에 대해 보조로 간주됩니다.
데이터베이스는 공통 소스이며 사용자가 쿼리라는 명령을 사용하여 데이터를 탐색하는 데이터를 호스팅하고 유지 관리하기 위해 데이터베이스 관리 시스템에 의존합니다. 데이터 소스로서의 파일은 오디오, 이미지 및 비디오 파일과 Excel과 같은 스프레드시트가 될 수 있습니다. 인터넷 소스는 데이터베이스와 파일을 찾을 수 있는 데이터 호스팅을 위한 일반적인 위치입니다. API라고도 하는 응용 프로그래밍 인터페이스를 사용하면 프로그래머가 인터넷을 통해 외부 사용자와 데이터를 공유하는 방법을 만들 수 있으며 웹 스크래핑 프로세스는 웹 페이지에서 데이터를 추출합니다. 데이터 작업 강의에서는 다양한 데이터 소스를 사용하는 방법에대해 알아봅니다.
결론
이 단원에서 우리는 다음을 배웠습니다.
- 어떤 데이터인가
- 데이터 설명 방법
- 데이터 분류 및 분류 방법
- 데이터를 찾을 수 있는 곳
🚀 도전
Kaggle은 공개 데이터셋의 훌륭한 소스입니다. 데이터셋 검색 도구를 사용하여 흥미로운 데이터셋을 찾고 다음 기준에 따라 3~5개의 데이터셋을 분류합니다.
- 데이터는 양적입니까, 질적입니까?
- 데이터가 정형, 비정형 또는 반정형입니까?
강의 후 퀴즈
복습 및 독학
- 데이터 분류라는 제목의 이 Microsoft Learn 단원에는 정형, 반정형 및 비정형 데이터의 분류할 것입니다.