11 KiB
데이터 처리: 관계형 데이터베이스
 |
|---|
| 데이터 처리: 관계형 데이터베이스 - Sketchnote by @nitya |
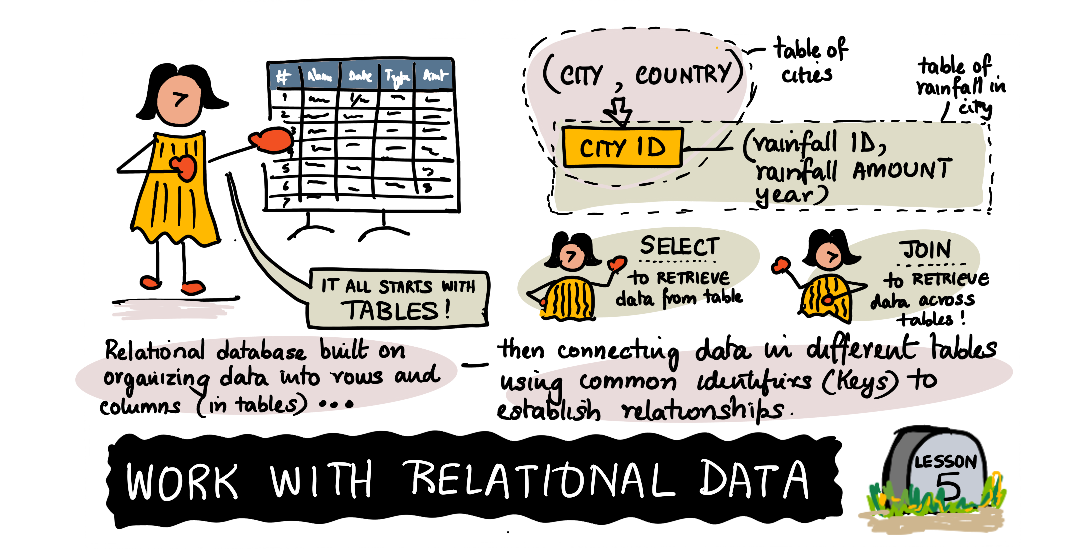
과거에 스프레드 시트를 통해 정보를 저장한 경험이 있을 것입니다. 이는 행(rows)과 열(columns)을 가지고 있으며, 행(rows)에는 정보(혹은 데이터)를 나타내고 열(columns)에는 해당 정보(또는 메타데이터)를 정의합니다. 관계형 데이터베이스는 테이블의 행과 열의 핵심 원리를 기반으로 구축되며 여러 테이블에 정보를 분산시킬 수 있습니다. 이를 통해 더 복잡한 데이터를 다룰 수 있을 뿐만 아니라 중복을 방지하고, 데이터 탐색 방식에서 유연성을 가질 수 있습니다. 관계형 데이터베이스의 개념을 좀 더 살펴보겠습니다.
강의 전 퀴즈
모든 것의 시작 : 테이블(table)
관계형 데이터베이스는 테이블을 가지며, 스프레드 시트와 마찬가지로 열과 행으로 이루어져 있습니다. 행에는 도시 이름이나 강우량등의 작업하고자 하는 데이터나 정보를 나타냅니다. 열에는 저장된 데이터에 대한 설명을 나타냅니다.
그렇다면 이제 실습을 시작해보겠습니다. 우선 도시 정보를 저장하는 테이블을 생성해 보도록 하겠습니다. 아래와 같이 나라와 도시 이름을 저장할 수 있을 것입니다.:
| City | Country |
|---|---|
| Tokyo | Japan |
| Atlanta | United States |
| Auckland | New Zealand |
city, country 및 population의 열 이름은 저장 중인 데이터를 가리키며, 각 행에는 도시에 대한 정보가 저장되어 있습니다.
단일 테이블의 단점
위의 테이블은 비교적 친숙해 보일 수도 있습니다. 이제 데이터베이스에 급증하는 연간 강우량(밀리미터 단위)에 대한 몇가지 데이터를 추가해 보겠습니다. 만약 우리가 2018,2018 그리고 2020년의 데이터를 추가한다면, 다음과 같을 것입니다.:
| City | Country | Year | Amount |
|---|---|---|---|
| Tokyo | Japan | 2020 | 1690 |
| Tokyo | Japan | 2019 | 1874 |
| Tokyo | Japan | 2018 | 1445 |
테이블에서 뭔가 알아차리셨나요? 도시의 이름과 국가를 계속해서 중복적으로 사용하고 있는 것을 발견했을 것입니다. 이러한 경우 불필요한 복사본을 저장함에 따라 저장소 낭비가 발생하게 됩니다. 결국, Tokyo는 하나만 존재해야 합니다.
그렇다면 다른 방식으로 접근해 보겠습니다. 각 연도에 대한 새 열을 추가하겠습니다.:
| City | Country | 2018 | 2019 | 2020 |
|---|---|---|---|---|
| Tokyo | Japan | 1445 | 1874 | 1690 |
| Atlanta | United States | 1779 | 1111 | 1683 |
| Auckland | New Zealand | 1386 | 942 | 1176 |
이러한 방식은 행에 대한 중복을 피할수는 있지만, 몇 가지 해결해야할 과제가 존재합니다. 우선, 새로운 연도가 추가될 때마다 테이블의 구조를 수정해야만 합니다. 또한, 데이터가 증가함에 따라 값을 검색하고 계산하는 것이 더 어려워집니다.
이것이 여러 테이블의 관계가 필요한 이유입니다. 데이터를 분리함으로써 중복을 방지하고, 데이터를 보다 유연하게 사용할 수 있습니다.
관계의 개념
다시 데이터를 보며 어떻게 데이터를 분할할 것인지 결정해 보겠습니다. 이미 우리는 City의 Name과 Country를 저장하는 것이 최선의 방법인 것을 알고 있고, 실제로 가장 잘 동작할 것입니다.
| City | Country |
|---|---|
| Tokyo | Japan |
| Atlanta | United States |
| Auckland | New Zealand |
하지만 우리가 다음 테이블을 생성하기 이전에, 우리는 각각의 도시를 어떻게 참조할 것인지 생각해 봐야합니다. 구분 지을 수 있는 여러 형태의 식별자,ID 또는 기본키(Primary key)가 필요합니다. 기본키(Primary key)는 테이블에서 특정 행을 식별하는데 사용되는 값입니다. 기본키로 값 자체(ex. 도시 이름)를 사용할 수도 있지만, 대부분 숫자 또는 다른 식별자가 사용됩니다. ID 값이 바뀌면서 관계를 깨뜨릴 수 있기 때문에 대부분 기본키 또는 자동 생성된 번호를 사용합니다.
✅ 기본키(Primary key)는 주로 PK라고 약칭 됩니다.
도시
| city_id | City | Country |
|---|---|---|
| 1 | Tokyo | Japan |
| 2 | Atlanta | United States |
| 3 | Auckland | New Zealand |
✅ 이번 강의에서 우리는 "id"와 "기본키(Primary key)"를 혼용해서 사용하고 있습니다. 이에 대한 자세한 개념은 나중에 살펴볼 데이터 프레임(DataFrames)에 적용됩니다. 데이터 프레임(DataFrames)이 "기본 키"라는 용어를 사용하지는 않지만, 동일한 방식인 것을 알 수 있습니다.
도시 테이블이 생성되었으니, 강우량 테이블을 만들어 보겠습니다. 도시에 대한 전체 정보를 가져오는 대신, 이제 우리는 id를 사용할 수 있습니다. 모든 테이블은 id 또는 기본 키를 가져야 하므로, 새로 생성되는 테이블도 id 열을 가져야 합니다.
강수량
| rainfall_id | city_id | Year | Amount |
|---|---|---|---|
| 1 | 1 | 2018 | 1445 |
| 2 | 1 | 2019 | 1874 |
| 3 | 1 | 2020 | 1690 |
| 4 | 2 | 2018 | 1779 |
| 5 | 2 | 2019 | 1111 |
| 6 | 2 | 2020 | 1683 |
| 7 | 3 | 2018 | 1386 |
| 8 | 3 | 2019 | 942 |
| 9 | 3 | 2020 | 1176 |
새롭게 생성된 강수량 테이블의 city_id 열이 추가 되었습니다. 이 열은 cities 테이블의 참조 값(reference id)을 나타냅니다. 기술적 용어로 이것을, 외래키(foreign key)라고 부릅니다; 이는 다른 테이블의 기본키입니다. 참조나 포인터의 개념이라고 생각할 수 있습니다. city_id 1은 Tokyo를 참조합니다.
✅ 외래키(Foreign key)는 주로 FK라고 약칭합니다.
데이터 조회
데이터가 두개의 테이블로 분리되어 있을때는, 어떻게 데이터를 검색할까요?. 만약 우리가 MYSQL, SQL Server, Oracle과 같은 관계형 데이터베이스를 사용하는 경우, 우리는 구조화된 질의언어 혹은 SQL을 사용할 수 있습니다 . SQL("에스큐엘"이라고 발음된다.)은 관계형 데이터베이스에서 데이터를 검색하고 수정하는 데 사용되는 표준 언어입니다.
데이터를 검색할 때는 SELECT 명령어를 사용합니다. 핵심은 데이터가 담긴 테이블에서(from) 찾고자 하는 열을 검색(select)하는 것입니다. 만약 도시의 이름만 보이고 싶다면, 다음 내용을 따라하세요:
SELECT city
FROM cities;
-- Output:
-- Tokyo
-- Atlanta
-- Auckland
SELECT는 열의 집합이라면, FROM은 테이블의 집합이라고 할 수 있습니다.
[주의] SQL 문법은 대소문자를 구분하지 않으며,
select와SELECT는 서로 같습니다. 그러나, 데이터베이스의 타입에 따라 열과 테이블은 대소문자를 구분할 수도 있습니다. 따라서, 대소문자를 구분해 프로그래밍하는 것이 좋습니다. SQL 쿼리를 작성할 때 키워드를 대문자로 적는 것이 원칙입니다.
위의 예시 쿼리는 모든 도시를 나타냅니다. 여기서 뉴질랜드(New Zealand)의 도시만 보여주고 싶다면 어떻게 할까요? 사용할 키워드는 WHERE, 혹은 "where something is true" 입니다.
SELECT city
FROM cities
WHERE country = 'New Zealand';
-- Output:
-- Auckland
데이터 조인
우리는 이전까지 단일 테이블에서 데이터를 검색했습니다. 이제 도시(city)와 강수량(rainfall)의 데이터를 하나로 통합해 보여주려 합니다. 이것은 데이터 조인을 통해서 할 수 있습니다. 데이터 조인은 두개의 다른 테이블의 열을 일치시킴으로써 효과적으로 이어줍니다.
예를들어, 강수량(rainfall) 테이블의 city_id 열과 도시(city) 테이블의 city_id 열을 매칭할 수 있습니다. 조인을 통해 각 도시들과 그에 맞는 강수량을 매칭할 것입니다. 여러 조인의 종류 중에서 먼저 다룰 것은 inner 조인입니다. inner 조인은 테이블간의 행이 정확하게 일치하지 않으면 표시되지 않습니다. 위의 예시의 경우 모든 도시에 비가 내리므로, 모든 행이 표시될 것입니다.
그렇다면 모든 도시의 2019년 강수량을 보겠습니다.
첫번째로 이전에 강조했던 city_id 열을 매칭해 데이터를 결합하겠습니다.
SELECT cities.city
rainfall.amount
FROM cities
INNER JOIN rainfall ON cities.city_id = rainfall.city_id
같은 city_id값과 함께 테이블 명을 명시함으로써, 테이블 조인에 핵심적인 열을 강조했습니다. 이제 WHERE 구문을 추가해 2019년만 검색해 보겠습니다.
SELECT cities.city
rainfall.amount
FROM cities
INNER JOIN rainfall ON cities.city_id = rainfall.city_id
WHERE rainfall.year = 2019
-- Output
-- city | amount
-- -------- | ------
-- Tokyo | 1874
-- Atlanta | 1111
-- Auckland | 942
요약
관계형 데이터 베이스는 여러 테이블 간에 정보를 분산시키며, 데이터 분석과 검색을 위해 결합됩니다. 계산을 수행할때나 조작할때 높은 유연성을 보장하는 것이 장점입니다. 지금까지 관계형 데이터베이스의 핵심 개념과 두 테이블 간의 조인을 수행하는 방법을 살펴보았습니다.
🚀 챌린지
인터넷에는 수많은 관계형 데이터베이스가 있습니다. 위에서 배운 내용과 기술을 토대로 이제 데이터를 자유롭게 다룰 수 있습니다.
강의 후 퀴즈
강의 후 퀴즈
리뷰 & 복습
Microsoft 학습에 SQL 및 관계형 데이터베이스 개념에 대한 학습을 계속할 수 있는 자료들이 있습니다.
- 관계형 데이터의 개념 설명
- Transact-SQL로 시작하는 쿼리 (Transact-SQL SQL의 버전이다.)
- Microsoft 학습의 SQL 콘텐츠