23 KiB
کلاؤڈ میں ڈیٹا سائنس: "Azure ML SDK" کا طریقہ
 |
|---|
| کلاؤڈ میں ڈیٹا سائنس: Azure ML SDK - @nitya کی اسکیچ نوٹ |
فہرستِ مضامین:
- کلاؤڈ میں ڈیٹا سائنس: "Azure ML SDK" کا طریقہ
لیکچر سے پہلے کا کوئز
1. تعارف
1.1 Azure ML SDK کیا ہے؟
ڈیٹا سائنسدان اور AI ڈویلپرز Azure Machine Learning SDK کا استعمال کرتے ہیں تاکہ Azure Machine Learning سروس کے ساتھ مشین لرننگ ورک فلو بنائیں اور چلائیں۔ آپ کسی بھی Python ماحول میں اس سروس کے ساتھ تعامل کر سکتے ہیں، جیسے Jupyter Notebooks، Visual Studio Code، یا آپ کا پسندیدہ Python IDE۔
SDK کے اہم پہلو شامل ہیں:
- مشین لرننگ تجربات میں استعمال ہونے والے ڈیٹاسیٹس کی دریافت، تیاری اور لائف سائیکل کا انتظام۔
- مشین لرننگ تجربات کی نگرانی، لاگنگ، اور تنظیم کے لیے کلاؤڈ وسائل کا انتظام۔
- ماڈلز کو مقامی طور پر یا کلاؤڈ وسائل کے ذریعے تربیت دینا، بشمول GPU-تیز ماڈل تربیت۔
- آٹومیٹڈ مشین لرننگ کا استعمال، جو کنفیگریشن پیرامیٹرز اور تربیتی ڈیٹا قبول کرتا ہے۔ یہ خودکار طور پر الگورتھمز اور ہائپرپیرامیٹر سیٹنگز کے ذریعے بہترین ماڈل تلاش کرتا ہے۔
- ویب سروسز کو تعینات کرنا تاکہ آپ کے تربیت یافتہ ماڈلز کو RESTful سروسز میں تبدیل کیا جا سکے، جو کسی بھی ایپلیکیشن میں استعمال ہو سکیں۔
Azure Machine Learning SDK کے بارے میں مزید جانیں
پچھلے سبق میں، ہم نے دیکھا کہ کس طرح کم کوڈ/نو کوڈ طریقے سے ماڈل کو تربیت دینا، تعینات کرنا اور استعمال کرنا ہے۔ ہم نے ہارٹ فیل ڈیٹاسیٹ کا استعمال کرتے ہوئے ہارٹ فیل کی پیش گوئی کا ماڈل بنایا۔ اس سبق میں، ہم بالکل وہی کام کریں گے لیکن Azure Machine Learning SDK کا استعمال کرتے ہوئے۔
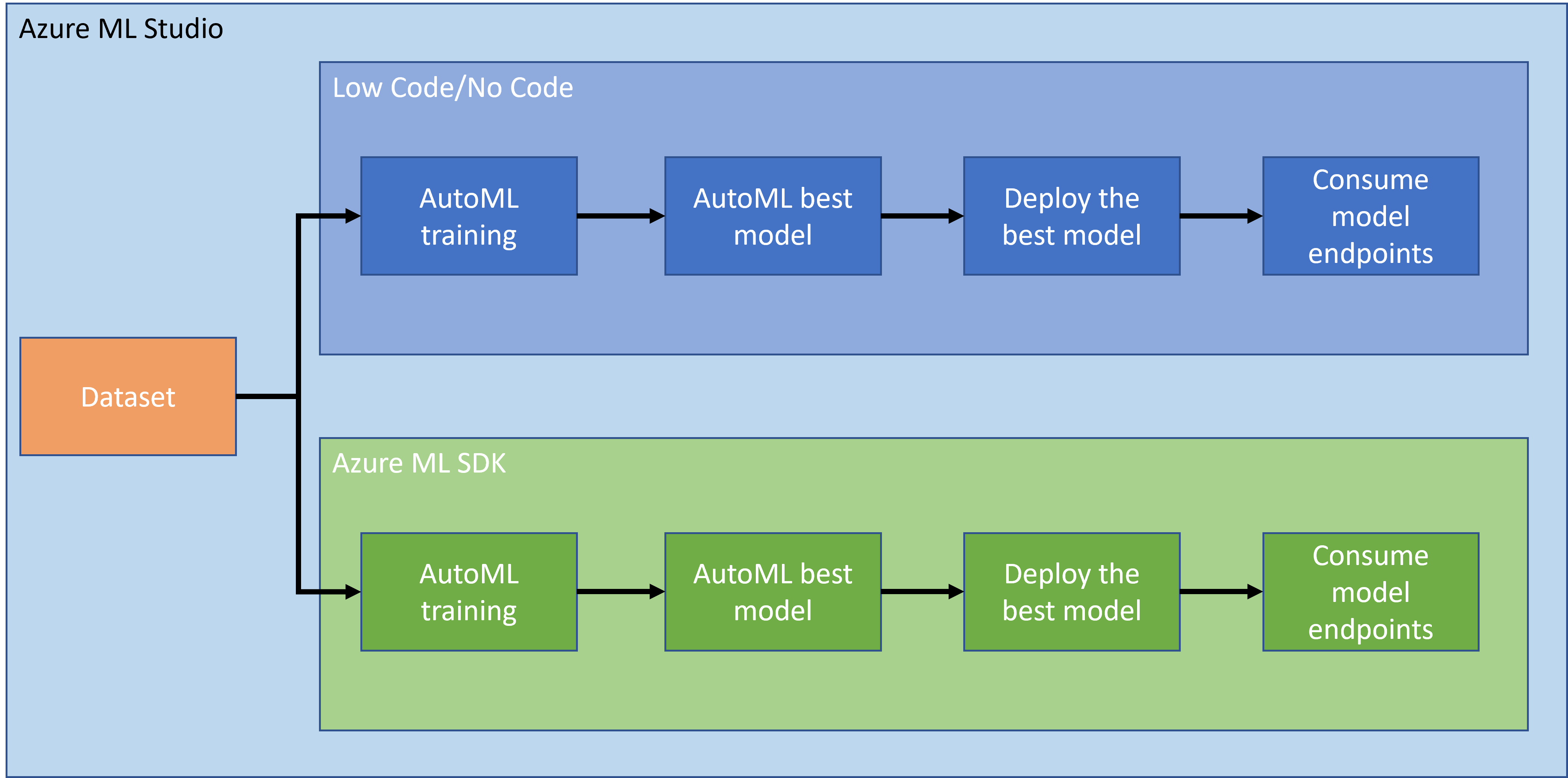
1.2 ہارٹ فیل کی پیش گوئی کے پروجیکٹ اور ڈیٹاسیٹ کا تعارف
ہارٹ فیل کی پیش گوئی کے پروجیکٹ اور ڈیٹاسیٹ کے تعارف کے لیے یہاں دیکھیں۔
2. Azure ML SDK کے ساتھ ماڈل کی تربیت
2.1 Azure ML ورک اسپیس بنائیں
آسانی کے لیے، ہم جیوپیٹر نوٹ بک پر کام کریں گے۔ اس کا مطلب ہے کہ آپ کے پاس پہلے سے ہی ایک ورک اسپیس اور کمپیوٹ انسٹینس موجود ہے۔ اگر آپ کے پاس پہلے سے ورک اسپیس موجود ہے، تو آپ براہ راست سیکشن 2.3 نوٹ بک تخلیق پر جا سکتے ہیں۔
اگر نہیں، تو براہ کرم پچھلے سبق کے سیکشن 2.1 Azure ML ورک اسپیس بنائیں میں دی گئی ہدایات پر عمل کریں۔
2.2 کمپیوٹ انسٹینس بنائیں
Azure ML ورک اسپیس میں جائیں جو ہم نے پہلے بنایا تھا، کمپیوٹ مینو پر جائیں اور آپ کو دستیاب مختلف کمپیوٹ وسائل نظر آئیں گے۔

آئیے جیوپیٹر نوٹ بک کے لیے ایک کمپیوٹ انسٹینس بناتے ہیں۔
-
- New بٹن پر کلک کریں۔
- اپنے کمپیوٹ انسٹینس کو ایک نام دیں۔
- اپنی اختیارات منتخب کریں: CPU یا GPU، VM سائز اور کور نمبر۔
- Create بٹن پر کلک کریں۔
مبارک ہو، آپ نے ایک کمپیوٹ انسٹینس بنا لیا ہے! ہم اس کمپیوٹ انسٹینس کو نوٹ بک بنانے کے لیے استعمال کریں گے نوٹ بکس بنانے کے سیکشن میں۔
2.3 ڈیٹاسیٹ لوڈ کرنا
اگر آپ نے ابھی تک ڈیٹاسیٹ اپلوڈ نہیں کیا ہے، تو پچھلے سبق کے سیکشن 2.3 ڈیٹاسیٹ لوڈ کرنا کا حوالہ دیں۔
2.4 نوٹ بکس بنانا
نوٹ: اگلے مرحلے کے لیے آپ یا تو ایک نیا نوٹ بک شروع سے بنا سکتے ہیں، یا آپ ہم نے بنایا ہوا نوٹ بک Azure ML اسٹوڈیو میں اپلوڈ کر سکتے ہیں۔ اپلوڈ کرنے کے لیے، بس "Notebook" مینو پر کلک کریں اور نوٹ بک اپلوڈ کریں۔
نوٹ بکس ڈیٹا سائنس کے عمل کا ایک اہم حصہ ہیں۔ ان کا استعمال Exploratory Data Analysis (EDA) کرنے، کمپیوٹ کلسٹر کو ماڈل تربیت دینے کے لیے کال کرنے، یا اینڈ پوائنٹ تعینات کرنے کے لیے کیا جا سکتا ہے۔
نوٹ بک بنانے کے لیے، ہمیں ایک کمپیوٹ نوڈ کی ضرورت ہے جو جیوپیٹر نوٹ بک انسٹینس فراہم کر رہا ہو۔ Azure ML ورک اسپیس پر واپس جائیں اور کمپیوٹ انسٹینسز پر کلک کریں۔ کمپیوٹ انسٹینسز کی فہرست میں آپ کو ہم نے پہلے بنایا ہوا کمپیوٹ انسٹینس نظر آنا چاہیے۔
- Applications سیکشن میں، Jupyter آپشن پر کلک کریں۔
- "Yes, I understand" باکس کو ٹک کریں اور Continue بٹن پر کلک کریں۔

- یہ آپ کے جیوپیٹر نوٹ بک انسٹینس کے ساتھ ایک نیا براؤزر ٹیب کھولے گا۔ "New" بٹن پر کلک کریں تاکہ نوٹ بک بنائی جا سکے۔

اب جب کہ ہمارے پاس ایک نوٹ بک ہے، ہم Azure ML SDK کے ساتھ ماڈل کی تربیت شروع کر سکتے ہیں۔
2.5 ماڈل کی تربیت
سب سے پہلے، اگر آپ کو کبھی شک ہو، تو Azure ML SDK دستاویزات کا حوالہ دیں۔ اس میں ان تمام ماڈیولز کی ضروری معلومات موجود ہیں جو ہم اس سبق میں دیکھیں گے۔
2.5.1 ورک اسپیس، تجربہ، کمپیوٹ کلسٹر اور ڈیٹاسیٹ سیٹ اپ کریں
آپ کو کنفیگریشن فائل سے workspace لوڈ کرنے کی ضرورت ہے، درج ذیل کوڈ کا استعمال کریں:
from azureml.core import Workspace
ws = Workspace.from_config()
یہ Workspace قسم کا ایک آبجیکٹ واپس کرتا ہے جو ورک اسپیس کی نمائندگی کرتا ہے۔ پھر آپ کو درج ذیل کوڈ کا استعمال کرتے ہوئے ایک experiment بنانا ہوگا:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
ورک اسپیس سے تجربہ حاصل کرنے یا بنانے کے لیے، آپ تجربہ کا نام استعمال کرتے ہوئے اسے درخواست کرتے ہیں۔ تجربہ کا نام 3-36 حروف پر مشتمل ہونا چاہیے، ایک حرف یا نمبر سے شروع ہونا چاہیے، اور صرف حروف، نمبر، انڈر اسکورز، اور ڈیشز پر مشتمل ہو سکتا ہے۔ اگر ورک اسپیس میں تجربہ نہیں ملا، تو ایک نیا تجربہ بنایا جاتا ہے۔
اب آپ کو تربیت کے لیے کمپیوٹ کلسٹر بنانا ہوگا، درج ذیل کوڈ کا استعمال کریں۔ نوٹ کریں کہ یہ مرحلہ چند منٹ لے سکتا ہے۔
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
آپ ورک اسپیس سے ڈیٹاسیٹ کو ڈیٹاسیٹ کے نام کا استعمال کرتے ہوئے درج ذیل طریقے سے حاصل کر سکتے ہیں:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 آٹو ایم ایل کنفیگریشن اور تربیت
آٹو ایم ایل کنفیگریشن سیٹ کرنے کے لیے، AutoMLConfig کلاس کا استعمال کریں۔
جیسا کہ دستاویز میں بیان کیا گیا ہے، آپ بہت سے پیرامیٹرز کے ساتھ کھیل سکتے ہیں۔ اس پروجیکٹ کے لیے، ہم درج ذیل پیرامیٹرز استعمال کریں گے:
experiment_timeout_minutes: وہ زیادہ سے زیادہ وقت (منٹوں میں) جو تجربہ کو چلنے کی اجازت ہے۔max_concurrent_iterations: تجربہ کے لیے اجازت شدہ زیادہ سے زیادہ متوازی تربیتی تکرار۔primary_metric: تجربہ کی حیثیت کا تعین کرنے کے لیے استعمال ہونے والا بنیادی میٹرک۔compute_target: Azure Machine Learning کمپیوٹ ہدف جس پر آٹومیٹڈ مشین لرننگ تجربہ چلایا جائے گا۔task: چلانے کے لیے کام کی قسم۔ اقدار 'classification'، 'regression'، یا 'forecasting' ہو سکتی ہیں۔training_data: تجربہ کے اندر استعمال ہونے والا تربیتی ڈیٹا۔label_column_name: لیبل کالم کا نام۔path: Azure Machine Learning پروجیکٹ فولڈر کا مکمل راستہ۔enable_early_stopping: اگر اسکور مختصر مدت میں بہتر نہیں ہو رہا تو ابتدائی اختتام کو فعال کریں۔featurization: خودکار فیچرزائزیشن یا حسب ضرورت فیچرزائزیشن کا استعمال۔debug_log: ڈیبگ معلومات لکھنے کے لیے لاگ فائل۔
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
اب جب کہ آپ کی کنفیگریشن سیٹ ہو گئی ہے، آپ درج ذیل کوڈ کا استعمال کرتے ہوئے ماڈل کو تربیت دے سکتے ہیں۔ یہ مرحلہ آپ کے کلسٹر کے سائز پر منحصر ہو کر ایک گھنٹہ تک لے سکتا ہے۔
remote_run = experiment.submit(automl_config)
آپ RunDetails ویجیٹ چلا سکتے ہیں تاکہ مختلف تجربات دکھائے جا سکیں۔
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Azure ML SDK کے ساتھ ماڈل کی تعیناتی اور اینڈ پوائنٹ کا استعمال
3.1 بہترین ماڈل کو محفوظ کرنا
remote_run AutoMLRun قسم کا ایک آبجیکٹ ہے۔ اس آبجیکٹ میں get_output() طریقہ موجود ہے جو بہترین رن اور اس کے مطابق فٹ کیے گئے ماڈل کو واپس کرتا ہے۔
best_run, fitted_model = remote_run.get_output()
آپ بہترین ماڈل کے لیے استعمال کیے گئے پیرامیٹرز کو صرف فٹ کیے گئے ماڈل کو پرنٹ کر کے دیکھ سکتے ہیں اور بہترین ماڈل کی خصوصیات کو get_properties() طریقہ استعمال کر کے دیکھ سکتے ہیں۔
best_run.get_properties()
اب ماڈل کو register_model طریقہ کے ساتھ رجسٹر کریں۔
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 ماڈل کی تعیناتی
ایک بار بہترین ماڈل محفوظ ہو جانے کے بعد، ہم اسے InferenceConfig کلاس کے ساتھ تعینات کر سکتے ہیں۔ InferenceConfig تعیناتی کے لیے استعمال ہونے والے کسٹم ماحول کی کنفیگریشن سیٹنگز کی نمائندگی کرتا ہے۔ AciWebservice کلاس Azure Container Instances پر ایک ویب سروس اینڈ پوائنٹ کے طور پر تعینات کیے گئے مشین لرننگ ماڈل کی نمائندگی کرتا ہے۔ تعینات شدہ سروس ایک لوڈ بیلنسڈ، HTTP اینڈ پوائنٹ کے ساتھ ایک REST API ہے۔ آپ اس API کو ڈیٹا بھیج سکتے ہیں اور ماڈل کے ذریعے واپس کی گئی پیش گوئی حاصل کر سکتے ہیں۔
ماڈل کو deploy طریقہ کے ساتھ تعینات کیا جاتا ہے۔
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
یہ مرحلہ چند منٹ لے سکتا ہے۔
3.3 اینڈ پوائنٹ کا استعمال
آپ اپنے اینڈ پوائنٹ کو ایک نمونہ ان پٹ بنا کر استعمال کر سکتے ہیں:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
اور پھر آپ اس ان پٹ کو پیش گوئی کے لیے اپنے ماڈل کو بھیج سکتے ہیں:
response = aci_service.run(input_data=test_sample)
response
یہ '{"result": [false]}' کا نتیجہ دے گا۔ اس کا مطلب یہ ہے کہ جو مریض کا ڈیٹا ہم نے اینڈ پوائنٹ کو بھیجا، اس نے پیش گوئی false دی، یعنی یہ شخص دل کے دورے کا شکار ہونے کا امکان نہیں رکھتا۔
مبارک ہو! آپ نے Azure ML SDK کے ساتھ Azure ML پر تربیت یافتہ اور تعینات ماڈل کو کامیابی سے استعمال کر لیا ہے!
نوٹ: جب آپ پروجیکٹ مکمل کر لیں، تو تمام وسائل کو حذف کرنا نہ بھولیں۔
🚀 چیلنج
SDK کے ذریعے آپ بہت سی دیگر چیزیں بھی کر سکتے ہیں، بدقسمتی سے ہم اس سبق میں سب کچھ نہیں دیکھ سکتے۔ لیکن اچھی خبر یہ ہے کہ SDK کی دستاویزات کو سمجھنے کا طریقہ سیکھنا آپ کو خود سے بہت آگے لے جا سکتا ہے۔ Azure ML SDK کی دستاویزات دیکھیں اور Pipeline کلاس تلاش کریں جو آپ کو پائپ لائنز بنانے کی اجازت دیتی ہے۔ پائپ لائن مختلف مراحل کا مجموعہ ہے جو ورک فلو کے طور پر چلائے جا سکتے ہیں۔
اشارہ: SDK کی دستاویزات پر جائیں اور سرچ بار میں "Pipeline" جیسے کلیدی الفاظ ٹائپ کریں۔ آپ کو تلاش کے نتائج میں azureml.pipeline.core.Pipeline کلاس ملنی چاہیے۔
لیکچر کے بعد کا کوئز
جائزہ اور خود مطالعہ
اس سبق میں، آپ نے سیکھا کہ Azure ML SDK کے ساتھ کلاؤڈ میں دل کی ناکامی کے خطرے کی پیش گوئی کے لیے ماڈل کو تربیت دینا، تعینات کرنا اور استعمال کرنا۔ مزید معلومات کے لیے اس دستاویزات کو دیکھیں۔ Azure ML SDK کے ساتھ اپنا ماڈل بنانے کی کوشش کریں۔
اسائنمنٹ
Azure ML SDK کا استعمال کرتے ہوئے ڈیٹا سائنس پروجیکٹ
ڈسکلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا غیر درستیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ ہم اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے ذمہ دار نہیں ہیں۔