|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 2 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.ipynb | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 2 weeks ago | |
README.md
Isang Maikling Panimula sa Estadistika at Probabilidad
 |
|---|
| Estadistika at Probabilidad - Sketchnote ni @nitya |
Ang Estadistika at Teorya ng Probabilidad ay dalawang malapit na kaugnay na larangan ng Matematika na mahalaga sa Data Science. Posibleng magtrabaho gamit ang datos nang hindi masyadong malalim ang kaalaman sa matematika, ngunit mas mainam pa rin na malaman ang ilang pangunahing konsepto. Dito, magbibigay kami ng maikling panimula na makakatulong sa iyong magsimula.

Pre-lecture quiz
Probabilidad at Random Variables
Probabilidad ay isang numero sa pagitan ng 0 at 1 na nagpapahayag kung gaano ka-posible ang isang pangyayari. Ito ay tinutukoy bilang bilang ng positibong resulta (na humahantong sa pangyayari), hinati sa kabuuang bilang ng mga resulta, kung saan ang lahat ng resulta ay pantay na posible. Halimbawa, kapag nag-roll tayo ng dice, ang probabilidad na makakuha tayo ng even number ay 3/6 = 0.5.
Kapag pinag-uusapan ang mga pangyayari, gumagamit tayo ng random variables. Halimbawa, ang random variable na kumakatawan sa numero na nakuha kapag nag-roll ng dice ay magkakaroon ng mga halaga mula 1 hanggang 6. Ang set ng mga numero mula 1 hanggang 6 ay tinatawag na sample space. Maaari nating pag-usapan ang probabilidad ng isang random variable na magkaroon ng tiyak na halaga, halimbawa P(X=3)=1/6.
Ang random variable sa nakaraang halimbawa ay tinatawag na discrete, dahil mayroon itong bilang na sample space, ibig sabihin, may mga hiwalay na halaga na maaaring bilangin. May mga pagkakataon na ang sample space ay isang saklaw ng mga real numbers, o ang buong set ng real numbers. Ang ganitong mga variable ay tinatawag na continuous. Isang magandang halimbawa ay ang oras ng pagdating ng bus.
Probability Distribution
Sa kaso ng discrete random variables, madali itong ilarawan ang probabilidad ng bawat pangyayari gamit ang isang function na P(X). Para sa bawat halaga s mula sa sample space S, magbibigay ito ng numero mula 0 hanggang 1, kung saan ang kabuuan ng lahat ng halaga ng P(X=s) para sa lahat ng pangyayari ay magiging 1.
Ang pinakakilalang discrete distribution ay ang uniform distribution, kung saan may sample space na N elements, na may pantay na probabilidad na 1/N para sa bawat isa.
Mas mahirap ilarawan ang probability distribution ng isang continuous variable, na may mga halaga na mula sa isang interval [a,b], o ang buong set ng real numbers ℝ. Isaalang-alang ang kaso ng oras ng pagdating ng bus. Sa katunayan, para sa bawat eksaktong oras ng pagdating t, ang probabilidad na dumating ang bus sa eksaktong oras na iyon ay 0!
Ngayon alam mo na ang mga pangyayari na may probabilidad na 0 ay nangyayari, at madalas pa! Lalo na tuwing dumadating ang bus!
Maaari lamang nating pag-usapan ang probabilidad ng isang variable na nasa loob ng isang ibinigay na interval ng mga halaga, halimbawa P(t1≤X<t2). Sa kasong ito, ang probability distribution ay inilalarawan ng isang probability density function p(x), kung saan:
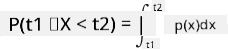
Ang continuous analog ng uniform distribution ay tinatawag na continuous uniform, na tinutukoy sa isang finite interval. Ang probabilidad na ang halaga X ay nasa loob ng isang interval na may haba l ay proporsyonal sa l, at tumataas hanggang 1.
Isa pang mahalagang distribution ay ang normal distribution, na tatalakayin natin nang mas detalyado sa ibaba.
Mean, Variance at Standard Deviation
Ipagpalagay na kumuha tayo ng isang sequence ng n samples ng isang random variable X: x1, x2, ..., xn. Maaari nating tukuyin ang mean (o arithmetic average) na halaga ng sequence sa tradisyunal na paraan bilang (x1+x2+xn)/n. Habang lumalaki ang laki ng sample (ibig sabihin, kunin ang limitasyon na n→∞), makukuha natin ang mean (tinatawag ding expectation) ng distribution. Ipapakita natin ang expectation bilang E(x).
Maipapakita na para sa anumang discrete distribution na may mga halaga {x1, x2, ..., xN} at mga kaukulang probabilidad p1, p2, ..., pN, ang expectation ay magiging E(X)=x1p1+x2p2+...+xNpN.
Upang matukoy kung gaano kalayo ang mga halaga, maaari nating kalkulahin ang variance σ2 = ∑(xi - μ)2/n, kung saan ang μ ay ang mean ng sequence. Ang halaga σ ay tinatawag na standard deviation, at ang σ2 ay tinatawag na variance.
Mode, Median at Quartiles
Minsan, ang mean ay hindi sapat na kumakatawan sa "karaniwang" halaga para sa datos. Halimbawa, kapag may ilang extreme values na lubos na labas sa saklaw, maaari nitong maapektuhan ang mean. Isa pang magandang indikasyon ay ang median, isang halaga kung saan kalahati ng mga data points ay mas mababa rito, at ang kalahati naman ay mas mataas.
Upang matulungan tayong maunawaan ang distribution ng datos, kapaki-pakinabang na pag-usapan ang quartiles:
- Ang unang quartile, o Q1, ay isang halaga kung saan 25% ng datos ay mas mababa rito
- Ang ikatlong quartile, o Q3, ay isang halaga kung saan 75% ng datos ay mas mababa rito
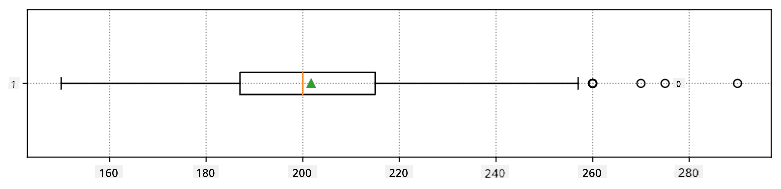
Graphically, maaari nating ipakita ang relasyon sa pagitan ng median at quartiles sa isang diagram na tinatawag na box plot:

Dito, kinakalkula rin natin ang inter-quartile range IQR=Q3-Q1, at ang tinatawag na outliers - mga halaga na nasa labas ng mga hangganan [Q1-1.5IQR,Q3+1.5IQR].
Para sa finite distribution na naglalaman ng maliit na bilang ng posibleng mga halaga, ang isang magandang "karaniwang" halaga ay ang madalas na lumalabas, na tinatawag na mode. Madalas itong ginagamit sa categorical data, tulad ng mga kulay. Isaalang-alang ang sitwasyon kung saan may dalawang grupo ng tao - ang ilan ay mas gustong pula, at ang iba naman ay mas gustong asul. Kung iko-code natin ang mga kulay sa pamamagitan ng mga numero, ang mean value para sa paboritong kulay ay maaaring nasa orange-green spectrum, na hindi nagpapakita ng aktwal na kagustuhan ng alinmang grupo. Gayunpaman, ang mode ay maaaring isa sa mga kulay, o parehong kulay, kung ang bilang ng mga tao na bumoto para sa kanila ay magkapantay (sa kasong ito tinatawag natin ang sample na multimodal).
Real-world Data
Kapag sinusuri natin ang datos mula sa totoong buhay, madalas na hindi sila random variables sa ganap na kahulugan, sa diwa na hindi tayo nagsasagawa ng mga eksperimento na may hindi tiyak na resulta. Halimbawa, isaalang-alang ang isang koponan ng mga baseball players, at ang kanilang mga datos sa katawan, tulad ng taas, timbang, at edad. Ang mga numerong ito ay hindi eksaktong random, ngunit maaari pa rin nating gamitin ang parehong mga konsepto ng matematika. Halimbawa, ang isang sequence ng mga timbang ng tao ay maaaring ituring na isang sequence ng mga halaga na nakuha mula sa isang random variable. Narito ang sequence ng mga timbang ng aktwal na baseball players mula sa Major League Baseball, na kinuha mula sa dataset na ito (para sa iyong kaginhawaan, ang unang 20 halaga lamang ang ipinakita):
[180.0, 215.0, 210.0, 210.0, 188.0, 176.0, 209.0, 200.0, 231.0, 180.0, 188.0, 180.0, 185.0, 160.0, 180.0, 185.0, 197.0, 189.0, 185.0, 219.0]
Note: Upang makita ang halimbawa ng paggamit ng dataset na ito, tingnan ang kasamang notebook. Mayroon ding ilang mga hamon sa buong aralin, at maaari mong kumpletuhin ang mga ito sa pamamagitan ng pagdaragdag ng ilang code sa notebook na iyon. Kung hindi ka sigurado kung paano mag-operate sa datos, huwag mag-alala - babalikan natin ang paggamit ng datos gamit ang Python sa susunod. Kung hindi mo alam kung paano magpatakbo ng code sa Jupyter Notebook, tingnan ang artikulong ito.
Narito ang box plot na nagpapakita ng mean, median, at quartiles para sa ating datos:
Dahil ang ating datos ay naglalaman ng impormasyon tungkol sa iba't ibang roles ng player, maaari rin tayong gumawa ng box plot ayon sa role - magbibigay ito sa atin ng ideya kung paano nagkakaiba ang mga halaga ng parameter sa bawat role. Sa pagkakataong ito, isasaalang-alang natin ang taas:
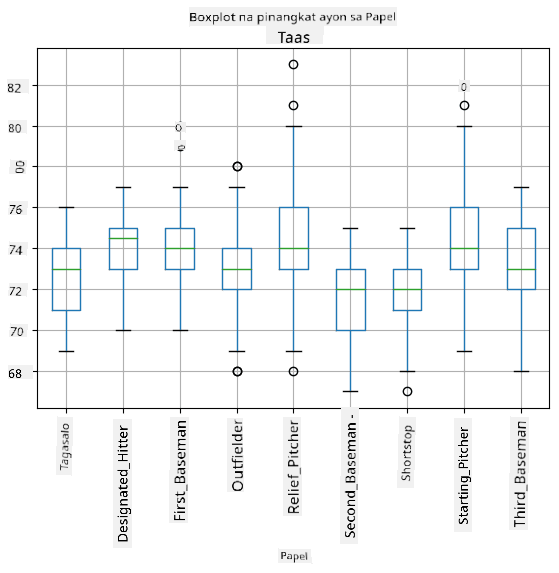
Ipinapakita ng diagram na ito na, sa karaniwan, ang taas ng mga first basemen ay mas mataas kaysa sa taas ng mga second basemen. Sa susunod na bahagi ng aralin, matututunan natin kung paano mas pormal na masusubok ang hypothesis na ito, at kung paano ipakita na ang ating datos ay statistically significant upang patunayan ito.
Kapag nagtatrabaho sa totoong datos, ipinapalagay natin na ang lahat ng data points ay mga samples na nakuha mula sa isang probability distribution. Ang assumption na ito ay nagbibigay-daan sa atin na mag-apply ng mga machine learning techniques at bumuo ng mga gumaganang predictive models.
Upang makita kung ano ang distribution ng ating datos, maaari tayong mag-plot ng graph na tinatawag na histogram. Ang X-axis ay maglalaman ng bilang ng iba't ibang weight intervals (tinatawag na bins), at ang vertical axis ay magpapakita ng bilang ng beses na ang sample ng ating random variable ay nasa loob ng isang ibinigay na interval.
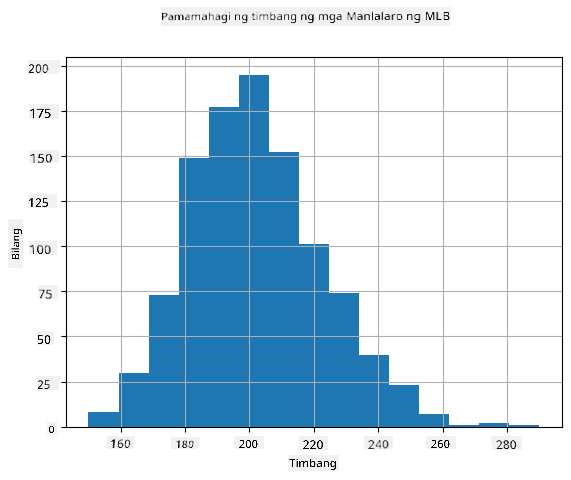
Mula sa histogram na ito, makikita mo na ang lahat ng mga halaga ay nakasentro sa paligid ng tiyak na mean weight, at habang lumalayo tayo mula sa mean weight - mas kaunti ang mga timbang na may ganitong halaga ang nakikita. Ibig sabihin, napaka-improbable na ang timbang ng isang baseball player ay malayo sa mean weight. Ang variance ng mga timbang ay nagpapakita kung gaano kalaki ang posibilidad na magkaiba ang mga timbang mula sa mean.
Kung kukunin natin ang mga timbang ng ibang tao, hindi mula sa baseball league, malamang na iba ang distribution. Gayunpaman, ang hugis ng distribution ay mananatiling pareho, ngunit magbabago ang mean at variance. Kaya, kung itetrain natin ang ating model sa mga baseball players, malamang na magbigay ito ng maling resulta kapag ginamit sa mga estudyante ng unibersidad, dahil iba ang underlying distribution.
Normal Distribution
Ang distribution ng mga timbang na nakita natin sa itaas ay napaka-karaniwan, at maraming sukat mula sa totoong mundo ang sumusunod sa parehong uri ng distribution, ngunit may iba't ibang mean at variance. Ang distribution na ito ay tinatawag na normal distribution, at ito ay may mahalagang papel sa estadistika.
Ang paggamit ng normal distribution ay tamang paraan upang makabuo ng random weights ng mga potensyal na baseball players. Kapag alam na natin ang mean weight mean at standard deviation std, maaari tayong bumuo ng 1000 weight samples sa sumusunod na paraan:
samples = np.random.normal(mean,std,1000)
Kung ipo-plot natin ang histogram ng mga nabuong samples, makikita natin ang larawan na halos katulad ng ipinakita sa itaas. At kung dadagdagan natin ang bilang ng samples at ang bilang ng bins, maaari tayong makabuo ng larawan ng normal distribution na mas malapit sa ideal:
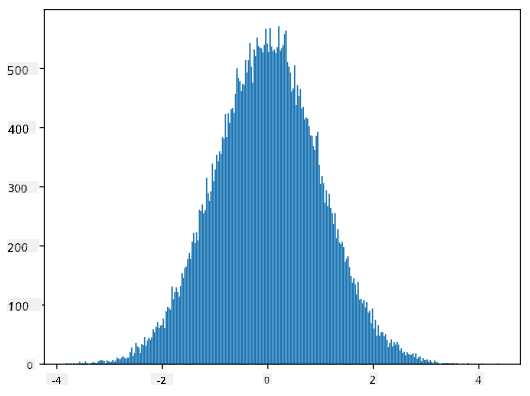
Normal Distribution na may mean=0 at std.dev=1
Confidence Intervals
Kapag pinag-uusapan natin ang mga timbang ng baseball players, ipinapalagay natin na mayroong tiyak na random variable W na tumutugma sa ideal probability distribution ng mga timbang ng lahat ng baseball players (tinatawag na population). Ang ating sequence ng mga timbang ay tumutugma sa subset ng lahat ng baseball players na tinatawag nating sample. Isang kawili-wiling tanong ay, maaari ba nating malaman ang mga parameter ng distribution ng W, ibig sabihin, mean at variance ng population?
Ang pinakamadaling sagot ay kalkulahin ang mean at variance ng ating sample. Gayunpaman, maaaring mangyari na ang ating random sample ay hindi tumpak na kumakatawan sa buong population. Kaya't makatuwiran na pag-usapan ang confidence interval.
Confidence interval ay ang pagtatantiya ng tunay na mean ng population batay sa ating sample, na tumpak sa isang tiyak na probabilidad (o level of confidence).
Ipagpalagay na mayroon tayong sample X
1, ..., Xn mula sa ating distribusyon. Sa tuwing kukuha tayo ng sample mula sa ating distribusyon, magkakaroon tayo ng iba't ibang mean value μ. Kaya't ang μ ay maituturing na isang random variable. Ang confidence interval na may confidence p ay isang pares ng mga halaga (Lp,Rp), kung saan P(Lp≤μ≤Rp) = p, ibig sabihin ang probabilidad na ang nasukat na mean value ay nasa loob ng interval ay katumbas ng p.
Hindi saklaw ng maikling intro na ito ang detalyadong talakayan kung paano kinakalkula ang mga confidence interval. Ang ilang detalye ay matatagpuan sa Wikipedia. Sa madaling salita, tinutukoy natin ang distribusyon ng computed sample mean kaugnay ng tunay na mean ng populasyon, na tinatawag na student distribution.
Kawili-wiling Katotohanan: Ang Student distribution ay ipinangalan sa matematikong si William Sealy Gosset, na naglathala ng kanyang papel sa ilalim ng pseudonym na "Student". Siya ay nagtrabaho sa Guinness brewery, at, ayon sa isa sa mga bersyon, ayaw ng kanyang employer na malaman ng publiko na gumagamit sila ng mga statistical test upang matukoy ang kalidad ng mga raw materials.
Kung nais nating tantiyahin ang mean μ ng ating populasyon na may confidence p, kailangan nating kunin ang (1-p)/2-th percentile ng Student distribution A, na maaaring makuha mula sa mga talahanayan, o kalkulahin gamit ang mga built-in na function ng statistical software (hal. Python, R, atbp.). Pagkatapos, ang interval para sa μ ay ibibigay ng X±A*D/√n, kung saan ang X ay ang nakuha na mean ng sample, at ang D ay ang standard deviation.
Tandaan: Hindi rin natin tatalakayin ang mahalagang konsepto ng degrees of freedom, na mahalaga kaugnay ng Student distribution. Maaari kang sumangguni sa mas kumpletong mga aklat sa statistics upang mas maunawaan ang konseptong ito.
Ang isang halimbawa ng pagkalkula ng confidence interval para sa timbang at taas ay ibinigay sa kasamang notebook.
| p | Mean ng Timbang |
|---|---|
| 0.85 | 201.73±0.94 |
| 0.90 | 201.73±1.08 |
| 0.95 | 201.73±1.28 |
Pansinin na habang tumataas ang confidence probability, mas lumalawak ang confidence interval.
Hypothesis Testing
Sa ating dataset ng mga baseball players, may iba't ibang role ang mga manlalaro, na maaaring ibuod sa ibaba (tingnan ang kasamang notebook upang makita kung paano makalkula ang talahanayan na ito):
| Role | Taas | Timbang | Bilang |
|---|---|---|---|
| Catcher | 72.723684 | 204.328947 | 76 |
| Designated_Hitter | 74.222222 | 220.888889 | 18 |
| First_Baseman | 74.000000 | 213.109091 | 55 |
| Outfielder | 73.010309 | 199.113402 | 194 |
| Relief_Pitcher | 74.374603 | 203.517460 | 315 |
| Second_Baseman | 71.362069 | 184.344828 | 58 |
| Shortstop | 71.903846 | 182.923077 | 52 |
| Starting_Pitcher | 74.719457 | 205.163636 | 221 |
| Third_Baseman | 73.044444 | 200.955556 | 45 |
Mapapansin natin na ang mean height ng mga first basemen ay mas mataas kaysa sa mga second basemen. Kaya't maaari tayong matukso na magkonklusyon na mas matangkad ang mga first basemen kaysa sa mga second basemen.
Ang pahayag na ito ay tinatawag na hypothesis, dahil hindi natin alam kung ang katotohanan ay talagang totoo o hindi.
Gayunpaman, hindi laging halata kung maaari nating gawin ang konklusyon na ito. Mula sa talakayan sa itaas, alam natin na ang bawat mean ay may kaugnay na confidence interval, at kaya't ang pagkakaiba na ito ay maaaring isang statistical error lamang. Kailangan natin ng mas pormal na paraan upang subukan ang ating hypothesis.
Kalkulahin natin ang confidence intervals nang hiwalay para sa taas ng mga first at second basemen:
| Confidence | First Basemen | Second Basemen |
|---|---|---|
| 0.85 | 73.62..74.38 | 71.04..71.69 |
| 0.90 | 73.56..74.44 | 70.99..71.73 |
| 0.95 | 73.47..74.53 | 70.92..71.81 |
Makikita natin na sa anumang confidence level, hindi nag-o-overlap ang mga interval. Pinapatunayan nito ang ating hypothesis na mas matangkad ang mga first basemen kaysa sa mga second basemen.
Mas pormal, ang problemang ating nilulutas ay upang makita kung pareho ang dalawang probability distributions, o kahit man lang ay may parehong parameters. Depende sa distribusyon, kailangan nating gumamit ng iba't ibang tests para dito. Kung alam natin na ang ating mga distribusyon ay normal, maaari nating gamitin ang Student t-test.
Sa Student t-test, kinakalkula natin ang tinatawag na t-value, na nagpapahiwatig ng pagkakaiba sa pagitan ng mga mean, isinasaalang-alang ang variance. Ipinapakita na ang t-value ay sumusunod sa student distribution, na nagbibigay-daan sa atin upang makuha ang threshold value para sa isang ibinigay na confidence level p (maaaring kalkulahin, o tingnan sa numerical tables). Pagkatapos, ikukumpara natin ang t-value sa threshold upang aprubahan o tanggihan ang hypothesis.
Sa Python, maaari nating gamitin ang SciPy package, na may kasamang ttest_ind function (bukod sa maraming iba pang kapaki-pakinabang na statistical functions!). Kinakalkula nito ang t-value para sa atin, at ginagawa rin ang reverse lookup ng confidence p-value, kaya't maaari na lang nating tingnan ang confidence upang gumawa ng konklusyon.
Halimbawa, ang ating paghahambing sa taas ng mga first at second basemen ay nagbibigay sa atin ng mga sumusunod na resulta:
from scipy.stats import ttest_ind
tval, pval = ttest_ind(df.loc[df['Role']=='First_Baseman',['Height']], df.loc[df['Role']=='Designated_Hitter',['Height']],equal_var=False)
print(f"T-value = {tval[0]:.2f}\nP-value: {pval[0]}")
T-value = 7.65
P-value: 9.137321189738925e-12
Sa ating kaso, ang p-value ay napakababa, na nangangahulugang may malakas na ebidensiya na sumusuporta sa ideya na mas matangkad ang mga first basemen.
Mayroon ding iba't ibang uri ng hypothesis na maaaring gusto nating subukan, halimbawa:
- Upang patunayan na ang isang sample ay sumusunod sa isang distribusyon. Sa ating kaso, ipinapalagay natin na ang mga taas ay normal na distribusyon, ngunit kailangan nito ng pormal na statistical verification.
- Upang patunayan na ang mean value ng isang sample ay tumutugma sa isang paunang natukoy na halaga
- Upang ihambing ang mga mean ng ilang sample (hal. ano ang pagkakaiba sa antas ng kasiyahan sa iba't ibang age groups)
Law of Large Numbers at Central Limit Theorem
Isa sa mga dahilan kung bakit mahalaga ang normal distribution ay ang tinatawag na central limit theorem. Halimbawa, mayroon tayong malaking sample ng independent N values X1, ..., XN, na kinuha mula sa anumang distribusyon na may mean μ at variance σ2. Pagkatapos, para sa sapat na malaking N (sa madaling salita, kapag N→∞), ang mean ΣiXi ay magiging normal na distribusyon, na may mean μ at variance σ2/N.
Ang isa pang paraan upang maunawaan ang central limit theorem ay ang pagsasabi na anuman ang distribusyon, kapag kinalkula mo ang mean ng kabuuan ng anumang random variable values, magtatapos ka sa normal na distribusyon.
Mula sa central limit theorem, nalalaman din na, kapag N→∞, ang probabilidad na ang sample mean ay maging katumbas ng μ ay nagiging 1. Ito ay kilala bilang the law of large numbers.
Covariance at Correlation
Isa sa mga ginagawa ng Data Science ay ang paghahanap ng relasyon sa pagitan ng data. Sinasabi natin na ang dalawang sequence ay correlate kapag nagpapakita sila ng magkatulad na pag-uugali sa parehong oras, hal. sabay silang tumataas/bumababa, o ang isang sequence ay tumataas kapag ang isa ay bumababa, at vice versa. Sa madaling salita, tila may relasyon sa pagitan ng dalawang sequence.
Ang correlation ay hindi nangangahulugang may causal relationship sa pagitan ng dalawang sequence; minsan ang parehong variable ay maaaring nakadepende sa isang external na sanhi, o maaaring nagkataon lamang na ang dalawang sequence ay nagkakaroon ng correlation. Gayunpaman, ang malakas na mathematical correlation ay isang magandang indikasyon na ang dalawang variable ay may koneksyon.
Matematikal, ang pangunahing konsepto na nagpapakita ng relasyon sa pagitan ng dalawang random variables ay ang covariance, na kinakalkula tulad nito: Cov(X,Y) = E[(X-E(X))(Y-E(Y))]. Kinakalkula natin ang deviation ng parehong variable mula sa kanilang mean values, at pagkatapos ay ang produkto ng mga deviation na iyon. Kung ang parehong variable ay nagde-deviate nang sabay, ang produkto ay palaging magiging positibo, na magdadagdag sa positibong covariance. Kung ang parehong variable ay nagde-deviate nang hindi sabay (hal. ang isa ay bumababa sa average kapag ang isa ay tumataas sa average), palagi tayong makakakuha ng negatibong numero, na magdadagdag sa negatibong covariance. Kung ang mga deviation ay hindi nakadepende, magdadagdag ang mga ito sa halos zero.
Ang absolute value ng covariance ay hindi nagsasabi ng marami tungkol sa kung gaano kalaki ang correlation, dahil ito ay nakadepende sa magnitude ng aktwal na values. Upang i-normalize ito, maaari nating hatiin ang covariance sa standard deviation ng parehong variable, upang makuha ang correlation. Ang maganda dito ay ang correlation ay palaging nasa saklaw ng [-1,1], kung saan ang 1 ay nagpapahiwatig ng malakas na positibong correlation sa pagitan ng values, -1 - malakas na negatibong correlation, at 0 - walang correlation (independent ang mga variable).
Halimbawa: Maaari nating kalkulahin ang correlation sa pagitan ng timbang at taas ng mga baseball players mula sa dataset na nabanggit sa itaas:
print(np.corrcoef(weights,heights))
Bilang resulta, makakakuha tayo ng correlation matrix tulad nito:
array([[1. , 0.52959196],
[0.52959196, 1. ]])
Ang correlation matrix C ay maaaring kalkulahin para sa anumang bilang ng input sequences S1, ..., Sn. Ang halaga ng Cij ay ang correlation sa pagitan ng Si at Sj, at ang diagonal elements ay palaging 1 (na siyang self-correlation ng Si).
Sa ating kaso, ang halaga na 0.53 ay nagpapahiwatig na mayroong correlation sa pagitan ng timbang at taas ng isang tao. Maaari rin tayong gumawa ng scatter plot ng isang value laban sa isa pa upang makita ang relasyon nang biswal:
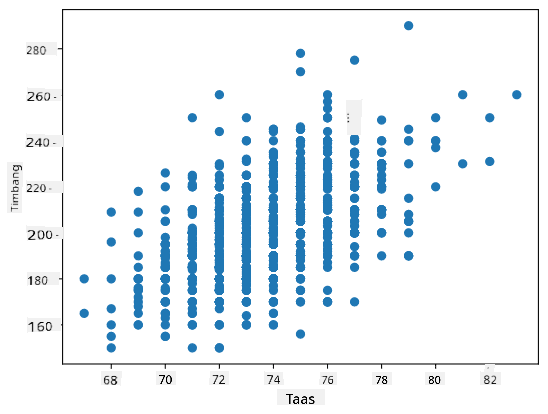
Mas maraming halimbawa ng correlation at covariance ang matatagpuan sa kasamang notebook.
Konklusyon
Sa seksyong ito, natutunan natin:
- ang mga pangunahing statistical properties ng data, tulad ng mean, variance, mode, at quartiles
- iba't ibang distribusyon ng random variables, kabilang ang normal distribution
- kung paano hanapin ang correlation sa pagitan ng iba't ibang properties
- kung paano gamitin ang maayos na apparatus ng math at statistics upang patunayan ang ilang hypotheses
- kung paano kalkulahin ang confidence intervals para sa random variable gamit ang data sample
Bagama't hindi ito kumpletong listahan ng mga paksa na umiiral sa probability at statistics, sapat na ito upang bigyan ka ng magandang simula sa kursong ito.
🚀 Hamon
Gamitin ang sample code sa notebook upang subukan ang iba pang hypothesis na:
- Mas matanda ang mga first basemen kaysa sa mga second basemen
- Mas matangkad ang mga first basemen kaysa sa mga third basemen
- Mas matangkad ang mga shortstops kaysa sa mga second basemen
Post-lecture quiz
Review at Pag-aaral sa Sarili
Ang probability at statistics ay napakalawak na paksa na nararapat sa sarili nitong kurso. Kung interesado kang mas lumalim sa teorya, maaaring gusto mong magpatuloy sa pagbabasa ng ilan sa mga sumusunod na aklat:
- Carlos Fernandez-Granda mula sa New York University ay may mahusay na lecture notes Probability and Statistics for Data Science (available online)
- Peter and Andrew Bruce. Practical Statistics for Data Scientists. [sample code in R].
- James D. Miller. Statistics for Data Science [sample code in R]
Assignment
Credits
Ang araling ito ay isinulat nang may ♥️ ni Dmitry Soshnikov
Paunawa:
Ang dokumentong ito ay isinalin gamit ang AI translation service na Co-op Translator. Bagama't sinisikap naming maging tumpak, tandaan na ang mga awtomatikong pagsasalin ay maaaring maglaman ng mga pagkakamali o hindi pagkakatugma. Ang orihinal na dokumento sa kanyang katutubong wika ang dapat ituring na opisyal na sanggunian. Para sa mahalagang impormasyon, inirerekomenda ang propesyonal na pagsasalin ng tao. Hindi kami mananagot sa anumang hindi pagkakaunawaan o maling interpretasyon na maaaring magmula sa paggamit ng pagsasaling ito.