16 KiB
Увод у животни циклус науке о подацима
 |
|---|
| Увод у животни циклус науке о подацима - Скетч од @nitya |
Квиз пре предавања
До сада сте вероватно схватили да је наука о подацима процес. Овај процес може се поделити на 5 фаза:
- Прикупљање
- Обрада
- Анализа
- Комуникација
- Одржавање
Ова лекција се фокусира на 3 дела животног циклуса: прикупљање, обрада и одржавање.
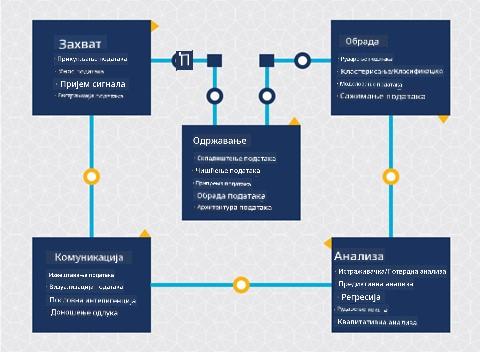
Фотографија од Berkeley School of Information
Прикупљање
Прва фаза животног циклуса је веома важна јер су наредне фазе зависне од ње. Практично, ова фаза обухвата два корака: прикупљање података и дефинисање сврхе и проблема који треба да се реше.
Дефинисање циљева пројекта захтева дубљи контекст проблема или питања. Прво, потребно је идентификовати и ангажовати оне којима је потребно решење проблема. То могу бити заинтересоване стране у послу или спонзори пројекта, који могу помоћи у идентификацији ко или шта ће имати користи од овог пројекта, као и шта и зашто им је потребно. Добро дефинисан циљ треба да буде мерљив и квантитативан како би се одредио прихватљив резултат.
Питања која научник о подацима може поставити:
- Да ли је овај проблем већ био разматран? Шта је откривено?
- Да ли сви укључени разумеју сврху и циљ?
- Да ли постоји нејасноћа и како је смањити?
- Која су ограничења?
- Како ће потенцијално изгледати крајњи резултат?
- Колико ресурса (време, људи, рачунарски капацитети) је доступно?
Следећи корак је идентификација, прикупљање, а затим истраживање података потребних за постизање дефинисаних циљева. У овој фази прикупљања, научници о подацима морају такође проценити количину и квалитет података. Ово захтева одређено истраживање података како би се потврдило да ће оно што је прикупљено подржати постизање жељеног резултата.
Питања која научник о подацима може поставити о подацима:
- Који подаци су ми већ доступни?
- Ко је власник ових података?
- Који су проблеми приватности?
- Да ли имам довољно података за решавање овог проблема?
- Да ли су подаци прихватљивог квалитета за овај проблем?
- Ако откријем додатне информације кроз ове податке, да ли треба да размотримо промену или редефинисање циљева?
Обрада
Фаза обраде у животном циклусу фокусира се на откривање образаца у подацима као и на моделирање. Неке технике које се користе у фази обраде захтевају статистичке методе за откривање образаца. Типично, ово би био заморан задатак за човека са великим скупом података, па се ослања на рачунаре да убрзају процес. Ова фаза је такође место где се наука о подацима и машинско учење укрштају. Као што сте научили у првој лекцији, машинско учење је процес изградње модела за разумевање података. Модели представљају однос између променљивих у подацима који помажу у предвиђању исхода.
Уобичајене технике које се користе у овој фази покривене су у курикулуму ML за почетнике. Пратите линкове да бисте сазнали више о њима:
- Класификација: Организовање података у категорије ради ефикасније употребе.
- Кластерисање: Груписање података у сличне групе.
- Регресија: Одређивање односа између променљивих ради предвиђања или прогнозе вредности.
Одржавање
На дијаграму животног циклуса, можда сте приметили да одржавање стоји између прикупљања и обраде. Одржавање је континуирани процес управљања, складиштења и обезбеђивања података током целог процеса пројекта и треба га узети у обзир током целог трајања пројекта.
Складиштење података
Разматрања о томе како и где се подаци складиште могу утицати на трошкове складиштења као и на перформансе брзине приступа подацима. Одлуке попут ових вероватно неће доносити само научник о подацима, али могу утицати на изборе о томе како радити са подацима на основу начина њиховог складиштења.
Ево неких аспеката модерних система за складиштење података који могу утицати на ове изборе:
Локално vs удаљено vs јавни или приватни облак
Локално се односи на хостовање и управљање подацима на сопственој опреми, као што је поседовање сервера са хард дисковима који складиште податке, док удаљено зависи од опреме коју не поседујете, као што је дата центар. Јавни облак је популаран избор за складиштење података који не захтева знање о томе како или где су тачно подаци складиштени, где јавни облак подразумева јединствену инфраструктуру коју деле сви корисници облака. Неке организације имају строге безбедносне политике које захтевају потпун приступ опреми где су подаци хостовани и ослањају се на приватни облак који пружа сопствене услуге облака. Више о подацима у облаку научићете у каснијим лекцијама.
Хладни vs топли подаци
Када тренирате своје моделе, можда ће вам бити потребно више података за обуку. Ако сте задовољни својим моделом, нови подаци ће пристизати како би модел служио својој сврси. У сваком случају, трошкови складиштења и приступа подацима ће расти како их буде више. Одвајање ретко коришћених података, познатих као хладни подаци, од често приступаних топлих података може бити јефтинија опција складиштења кроз хардверске или софтверске услуге. Ако је потребно приступити хладним подацима, може потрајати мало дуже у поређењу са топлим подацима.
Управљање подацима
Док радите са подацима, можда ћете открити да неки од њих треба да се очисте користећи неке од техника покривених у лекцији о припреми података како би се изградили тачни модели. Када нови подаци пристигну, потребно је применити исте технике како би се одржала конзистентност у квалитету. Неки пројекти ће укључивати употребу аутоматизованог алата за чишћење, агрегирање и компресију пре него што се подаци преместе на своју коначну локацију. Azure Data Factory је пример једног од ових алата.
Обезбеђивање података
Један од главних циљева обезбеђивања података је осигурање да они који раде са њима имају контролу над оним што се прикупља и у ком контексту се користи. Чување података безбедним подразумева ограничавање приступа само онима којима је потребан, придржавање локалних закона и прописа, као и одржавање етичких стандарда, као што је покривено у лекцији о етици.
Ево неких ствари које тим може урадити са безбедношћу на уму:
- Потврдити да су сви подаци шифровани
- Пружити корисницима информације о томе како се њихови подаци користе
- Уклонити приступ подацима онима који су напустили пројекат
- Омогућити само одређеним члановима пројекта да мењају податке
🚀 Изазов
Постоји много верзија животног циклуса науке о подацима, где сваки корак може имати различита имена и број фаза, али ће садржати исте процесе поменуте у овој лекцији.
Истражите Team Data Science Process lifecycle и Cross-industry standard process for data mining. Наведите 3 сличности и разлике између ова два.
| Team Data Science Process (TDSP) | Cross-industry standard process for data mining (CRISP-DM) |
|---|---|
 |
 |
| Слика од Microsoft | Слика од Data Science Process Alliance |
Квиз после предавања
Преглед и самостално учење
Примена животног циклуса науке о подацима укључује више улога и задатака, где се неки могу фокусирати на одређене делове сваке фазе. Team Data Science Process пружа неколико ресурса који објашњавају типове улога и задатака које неко може имати у пројекту.
- Улоге и задаци у процесу тимске науке о подацима
- Извршавање задатака науке о подацима: истраживање, моделирање и имплементација
Задатак
Одрицање од одговорности:
Овај документ је преведен коришћењем услуге за превођење помоћу вештачке интелигенције Co-op Translator. Иако тежимо тачности, молимо вас да имате у виду да аутоматски преводи могу садржати грешке или нетачности. Оригинални документ на изворном језику треба сматрати ауторитативним извором. За критичне информације препоручује се професионални превод од стране људи. Не сносимо одговорност за било каква погрешна тумачења или неспоразуме који могу произаћи из коришћења овог превода.