22 KiB
Delo z podatki: Python in knjižnica Pandas
 |
|---|
| Delo s Pythonom - Sketchnote avtorja @nitya |
Medtem ko baze podatkov ponujajo zelo učinkovite načine za shranjevanje podatkov in njihovo poizvedovanje z uporabo jezikov za poizvedbe, je najbolj prilagodljiv način obdelave podatkov pisanje lastnega programa za manipulacijo podatkov. V mnogih primerih bi bila poizvedba v bazi podatkov bolj učinkovita. Vendar pa v nekaterih primerih, ko je potrebna bolj zapletena obdelava podatkov, tega ni mogoče enostavno doseči z uporabo SQL. Obdelavo podatkov je mogoče programirati v katerem koli programskem jeziku, vendar obstajajo določeni jeziki, ki so na višji ravni glede dela s podatki. Podatkovni znanstveniki običajno uporabljajo enega od naslednjih jezikov:
- Python, splošno namenski programski jezik, ki se pogosto šteje za eno najboljših možnosti za začetnike zaradi svoje preprostosti. Python ima veliko dodatnih knjižnic, ki vam lahko pomagajo rešiti številne praktične težave, kot so pridobivanje podatkov iz ZIP arhiva ali pretvorba slike v sivinsko lestvico. Poleg podatkovne znanosti se Python pogosto uporablja tudi za razvoj spletnih aplikacij.
- R je tradicionalno orodje, razvito z mislijo na statistično obdelavo podatkov. Vsebuje tudi veliko skladišče knjižnic (CRAN), kar ga naredi dobro izbiro za obdelavo podatkov. Vendar pa R ni splošno namenski programski jezik in se redko uporablja zunaj področja podatkovne znanosti.
- Julia je še en jezik, razvit posebej za podatkovno znanost. Namenjen je zagotavljanju boljše zmogljivosti kot Python, kar ga naredi odlično orodje za znanstvene eksperimente.
V tej lekciji se bomo osredotočili na uporabo Pythona za preprosto obdelavo podatkov. Predpostavljamo osnovno poznavanje jezika. Če želite podrobnejši pregled Pythona, se lahko obrnete na enega od naslednjih virov:
- Naučite se Pythona na zabaven način z grafiko Turtle in fraktali - GitHub tečaj za hiter uvod v programiranje v Pythonu
- Naredite prve korake s Pythonom Učni načrt na Microsoft Learn
Podatki lahko pridejo v različnih oblikah. V tej lekciji bomo obravnavali tri oblike podatkov - tabelarične podatke, besedilo in slike.
Osredotočili se bomo na nekaj primerov obdelave podatkov, namesto da bi vam dali celoten pregled vseh povezanih knjižnic. To vam bo omogočilo, da dobite glavno idejo o tem, kaj je mogoče, in vas pustilo z razumevanjem, kje najti rešitve za vaše težave, ko jih potrebujete.
Najbolj uporaben nasvet. Ko morate izvesti določeno operacijo na podatkih, za katero ne veste, kako jo narediti, poskusite iskati po internetu. Stackoverflow običajno vsebuje veliko uporabnih vzorcev kode v Pythonu za številne tipične naloge.
Predlekcijski kviz
Tabelarični podatki in DataFrame
Tabelarične podatke ste že srečali, ko smo govorili o relacijskih bazah podatkov. Ko imate veliko podatkov, ki so shranjeni v številnih povezanih tabelah, se vsekakor splača uporabiti SQL za delo z njimi. Vendar pa obstaja veliko primerov, ko imamo tabelo podatkov in želimo pridobiti nekaj razumevanja ali vpogledov v te podatke, kot so porazdelitev, korelacija med vrednostmi itd. V podatkovni znanosti je veliko primerov, ko moramo izvesti nekatere transformacije izvornih podatkov, ki jim sledi vizualizacija. Obe ti koraki je mogoče enostavno izvesti z uporabo Pythona.
Obstajata dve najbolj uporabni knjižnici v Pythonu, ki vam lahko pomagata pri delu s tabelaričnimi podatki:
- Pandas omogoča manipulacijo tako imenovanih DataFrame, ki so analogni relacijskim tabelam. Lahko imate poimenovane stolpce in izvajate različne operacije na vrsticah, stolpcih in DataFrame na splošno.
- Numpy je knjižnica za delo s tenzorji, tj. večdimenzionalnimi polji. Polje ima vrednosti iste osnovne vrste in je preprostejše od DataFrame, vendar ponuja več matematičnih operacij in ustvarja manj režijskih stroškov.
Obstaja tudi nekaj drugih knjižnic, ki jih morate poznati:
- Matplotlib je knjižnica, ki se uporablja za vizualizacijo podatkov in risanje grafov
- SciPy je knjižnica z nekaterimi dodatnimi znanstvenimi funkcijami. S to knjižnico smo se že srečali, ko smo govorili o verjetnosti in statistiki
Tukaj je kos kode, ki bi ga običajno uporabili za uvoz teh knjižnic na začetku vašega programa v Pythonu:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas temelji na nekaj osnovnih konceptih.
Series
Series je zaporedje vrednosti, podobno seznamu ali numpy polju. Glavna razlika je, da ima Series tudi indeks, in ko izvajamo operacije na Series (npr. jih seštevamo), se upošteva indeks. Indeks je lahko tako preprost kot številka vrstice (to je privzeti indeks, ko ustvarjamo Series iz seznama ali polja), ali pa ima lahko kompleksno strukturo, kot je časovni interval.
Opomba: Uvodno kodo Pandas najdete v priloženem zvezku
notebook.ipynb. Tukaj podajamo le nekaj primerov, vsekakor pa ste vabljeni, da si ogledate celoten zvezek.
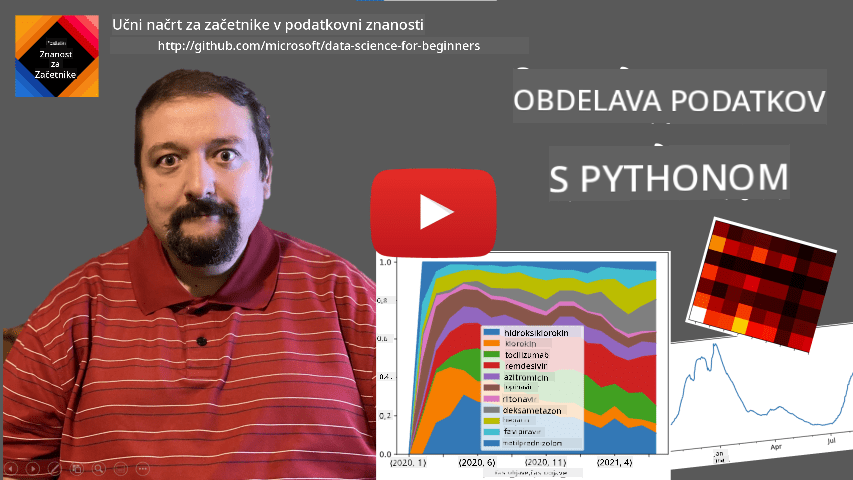
Razmislimo o primeru: želimo analizirati prodajo našega sladolednega lokala. Ustvarimo Series številk prodaje (število prodanih artiklov vsak dan) za določeno časovno obdobje:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
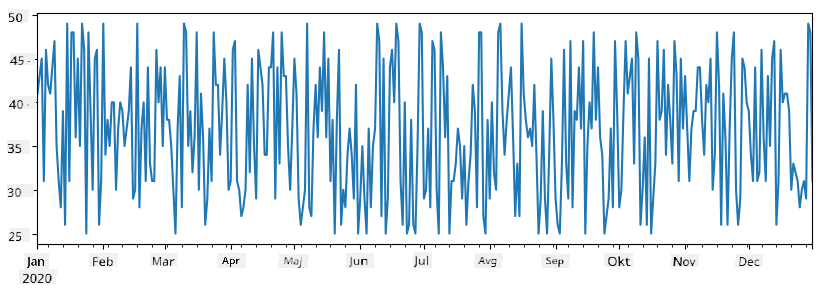
Recimo, da vsak teden organiziramo zabavo za prijatelje in vzamemo dodatnih 10 paketov sladoleda za zabavo. Ustvarimo lahko drugo Series, indeksirano po tednih, da to prikažemo:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Ko seštejemo dve Series, dobimo skupno število:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
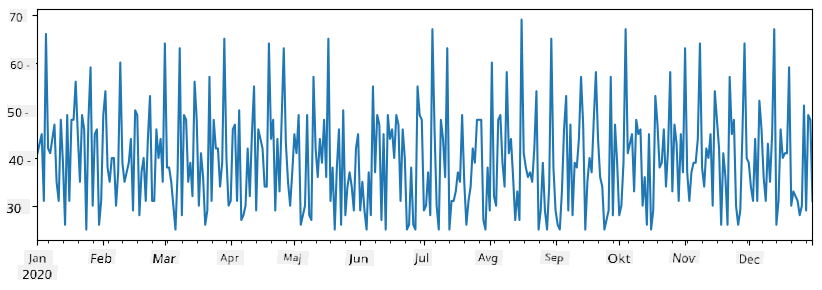
Opomba: Ne uporabljamo preproste sintakse
total_items+additional_items. Če bi jo, bi dobili veliko vrednostiNaN(Not a Number) v rezultatni Series. To je zato, ker manjkajo vrednosti za nekatere točke indeksa v Seriesadditional_items, in seštevanjeNaNz nečim rezultira vNaN. Zato moramo med seštevanjem določiti parameterfill_value.
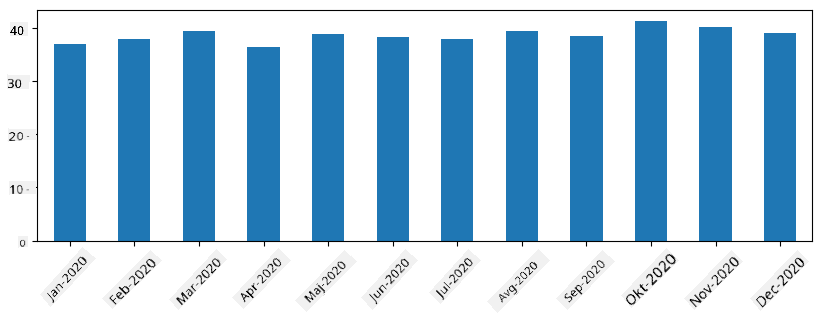
Pri časovnih serijah lahko tudi ponovno vzorčimo serijo z različnimi časovnimi intervali. Na primer, če želimo izračunati povprečno prodajo mesečno, lahko uporabimo naslednjo kodo:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame je v bistvu zbirka Series z istim indeksom. Več Series lahko združimo v DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
To bo ustvarilo horizontalno tabelo, kot je ta:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Series lahko uporabimo tudi kot stolpce in določimo imena stolpcev z uporabo slovarja:
df = pd.DataFrame({ 'A' : a, 'B' : b })
To nam bo dalo tabelo, kot je ta:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Opomba: To postavitev tabele lahko dobimo tudi z transponiranjem prejšnje tabele, npr. z zapisom
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Tukaj .T pomeni operacijo transponiranja DataFrame, tj. zamenjavo vrstic in stolpcev, operacija rename pa nam omogoča preimenovanje stolpcev, da ustrezajo prejšnjemu primeru.
Tukaj je nekaj najpomembnejših operacij, ki jih lahko izvedemo na DataFrame:
Izbor stolpcev. Posamezne stolpce lahko izberemo z zapisom df['A'] - ta operacija vrne Series. Podmnožico stolpcev lahko izberemo v drug DataFrame z zapisom df[['B','A']] - to vrne drug DataFrame.
Filtriranje določenih vrstic po kriterijih. Na primer, da pustimo le vrstice, kjer je stolpec A večji od 5, lahko zapišemo df[df['A']>5].
Opomba: Način delovanja filtriranja je naslednji. Izraz
df['A']<5vrne logično Series, ki označuje, ali je izrazTruealiFalseza vsak element izvorne Seriesdf['A']. Ko se logična Series uporabi kot indeks, vrne podmnožico vrstic v DataFrame. Zato ni mogoče uporabiti poljubnega Python logičnega izraza, na primer zapisdf[df['A']>5 and df['A']<7]bi bil napačen. Namesto tega morate uporabiti posebno operacijo&na logični Series, z zapisomdf[(df['A']>5) & (df['A']<7)](oklepaji so tukaj pomembni).
Ustvarjanje novih izračunljivih stolpcev. Z lahkoto lahko ustvarimo nove izračunljive stolpce za naš DataFrame z uporabo intuitivnega izraza, kot je ta:
df['DivA'] = df['A']-df['A'].mean()
Ta primer izračuna odstopanje A od njegove povprečne vrednosti. Kaj se tukaj dejansko zgodi, je, da izračunamo Series in nato to Series dodelimo levi strani, s čimer ustvarimo nov stolpec. Zato ne moremo uporabiti nobenih operacij, ki niso združljive s Series, na primer spodnja koda je napačna:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Zadnji primer, čeprav je sintaktično pravilen, daje napačen rezultat, ker dodeli dolžino Series B vsem vrednostim v stolpcu, in ne dolžine posameznih elementov, kot smo nameravali.
Če moramo izračunati kompleksne izraze, kot je ta, lahko uporabimo funkcijo apply. Zadnji primer lahko napišemo takole:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Po zgornjih operacijah bomo dobili naslednji DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Izbor vrstic glede na številke lahko izvedemo z uporabo konstrukta iloc. Na primer, da izberemo prvih 5 vrstic iz DataFrame:
df.iloc[:5]
Skupinjenje se pogosto uporablja za pridobitev rezultata, podobnega pivot tabelam v Excelu. Recimo, da želimo izračunati povprečno vrednost stolpca A za vsako dano število LenB. Nato lahko skupinimo naš DataFrame po LenB in pokličemo mean:
df.groupby(by='LenB')[['A','DivA']].mean()
Če moramo izračunati povprečje in število elementov v skupini, lahko uporabimo bolj kompleksno funkcijo aggregate:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
To nam da naslednjo tabelo:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Pridobivanje podatkov
Videli smo, kako enostavno je ustvariti Series in DataFrames iz Pythonovih objektov. Vendar pa podatki običajno prihajajo v obliki besedilne datoteke ali Excelove tabele. Na srečo nam Pandas ponuja preprost način za nalaganje podatkov z diska. Na primer, branje CSV datoteke je tako preprosto kot tole:
df = pd.read_csv('file.csv')
V razdelku "Izziv" bomo videli več primerov nalaganja podatkov, vključno s pridobivanjem podatkov z zunanjih spletnih mest.
Tiskanje in risanje grafov
Podatkovni znanstvenik mora pogosto raziskovati podatke, zato je pomembno, da jih zna vizualizirati. Ko je DataFrame velik, si pogosto želimo le zagotoviti, da delamo vse pravilno, tako da natisnemo prvih nekaj vrstic. To lahko storimo z uporabo df.head(). Če to izvajate v Jupyter Notebooku, bo DataFrame prikazan v lepi tabelarični obliki.
Prav tako smo videli uporabo funkcije plot za vizualizacijo nekaterih stolpcev. Čeprav je plot zelo uporaben za številne naloge in podpira različne vrste grafov prek parametra kind=, lahko vedno uporabite knjižnico matplotlib za risanje bolj zapletenih grafov. Podrobneje bomo obravnavali vizualizacijo podatkov v ločenih lekcijah tečaja.
Ta pregled zajema najpomembnejše koncepte Pandas, vendar je knjižnica zelo bogata in ni omejitev, kaj lahko z njo naredite! Zdaj pa uporabimo to znanje za reševanje specifičnega problema.
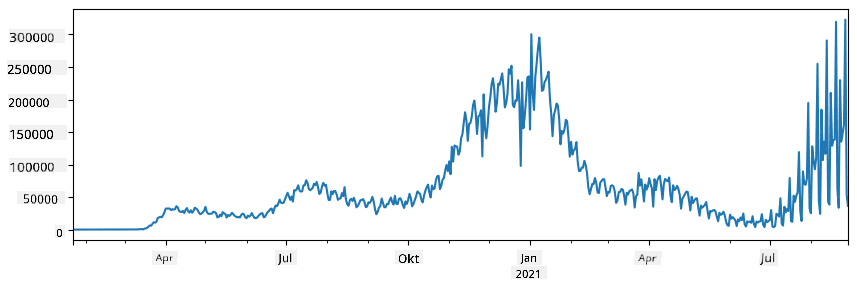
🚀 Izziv 1: Analiza širjenja COVID-a
Prvi problem, na katerega se bomo osredotočili, je modeliranje širjenja epidemije COVID-19. Za to bomo uporabili podatke o številu okuženih posameznikov v različnih državah, ki jih zagotavlja Center za sisteme znanosti in inženiringa (CSSE) na Univerzi Johns Hopkins. Podatkovni niz je na voljo v tem GitHub repozitoriju.
Ker želimo pokazati, kako ravnati s podatki, vas vabimo, da odprete notebook-covidspread.ipynb in ga preberete od začetka do konca. Prav tako lahko zaženete celice in rešite nekaj izzivov, ki smo jih pripravili za vas na koncu.
Če ne veste, kako zagnati kodo v Jupyter Notebooku, si oglejte ta članek.
Delo z nestrukturiranimi podatki
Čeprav podatki pogosto prihajajo v tabelarični obliki, se v nekaterih primerih srečamo z manj strukturiranimi podatki, na primer besedilom ali slikami. V tem primeru moramo za uporabo tehnik obdelave podatkov, ki smo jih videli zgoraj, nekako izluščiti strukturirane podatke. Tukaj je nekaj primerov:
- Izluščitev ključnih besed iz besedila in analiza njihove pogostosti
- Uporaba nevronskih mrež za pridobivanje informacij o objektih na sliki
- Pridobivanje informacij o čustvih ljudi na video posnetkih
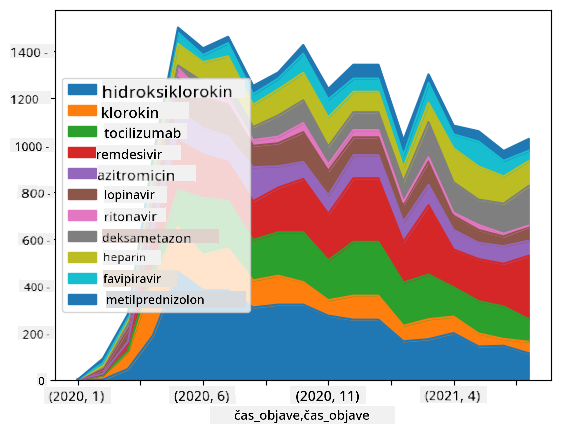
🚀 Izziv 2: Analiza COVID člankov
V tem izzivu bomo nadaljevali s temo pandemije COVID in se osredotočili na obdelavo znanstvenih člankov na to temo. Obstaja CORD-19 podatkovni niz z več kot 7000 (v času pisanja) članki o COVID-u, ki so na voljo z metapodatki in povzetki (za približno polovico člankov je na voljo tudi celotno besedilo).
Celoten primer analize tega podatkovnega niza z uporabo kognitivne storitve Text Analytics for Health je opisan v tem blogu. Obravnavali bomo poenostavljeno različico te analize.
NOTE: Kopija podatkovnega niza ni vključena v ta repozitorij. Najprej boste morda morali prenesti datoteko
metadata.csviz tega podatkovnega niza na Kagglu. Registracija na Kagglu je morda potrebna. Podatkovni niz lahko prenesete tudi brez registracije tukaj, vendar bo vključeval vsa celotna besedila poleg datoteke z metapodatki.
Odprite notebook-papers.ipynb in ga preberite od začetka do konca. Prav tako lahko zaženete celice in rešite nekaj izzivov, ki smo jih pripravili za vas na koncu.
Obdelava slikovnih podatkov
V zadnjem času so bili razviti zelo zmogljivi AI modeli, ki omogočajo razumevanje slik. Obstaja veliko nalog, ki jih je mogoče rešiti z uporabo vnaprej naučenih nevronskih mrež ali oblačnih storitev. Nekaj primerov vključuje:
- Razvrščanje slik, ki vam lahko pomaga kategorizirati sliko v eno od vnaprej določenih kategorij. Svoje klasifikatorje slik lahko enostavno naučite z uporabo storitev, kot je Custom Vision
- Zaznavanje objektov za prepoznavanje različnih objektov na sliki. Storitve, kot je computer vision, lahko zaznajo številne pogoste objekte, vi pa lahko naučite model Custom Vision za zaznavanje specifičnih objektov.
- Zaznavanje obrazov, vključno z zaznavanjem starosti, spola in čustev. To je mogoče storiti prek Face API.
Vse te oblačne storitve je mogoče klicati z uporabo Python SDK-jev, zato jih je mogoče enostavno vključiti v vaš potek raziskovanja podatkov.
Tukaj je nekaj primerov raziskovanja podatkov iz slikovnih virov:
- V blogu Kako se naučiti podatkovne znanosti brez programiranja raziskujemo fotografije na Instagramu in poskušamo razumeti, kaj ljudi spodbudi, da všečkajo določeno fotografijo. Najprej iz slik pridobimo čim več informacij z uporabo computer vision, nato pa uporabimo Azure Machine Learning AutoML za izdelavo razložljivega modela.
- V delavnici o študijah obrazov uporabljamo Face API za pridobivanje čustev ljudi na fotografijah z dogodkov, da bi poskušali razumeti, kaj ljudi osrečuje.
Zaključek
Ne glede na to, ali že imate strukturirane ali nestrukturirane podatke, lahko s Pythonom izvedete vse korake, povezane z obdelavo in razumevanjem podatkov. To je verjetno najbolj prilagodljiv način obdelave podatkov, zato večina podatkovnih znanstvenikov uporablja Python kot svoje glavno orodje. Če ste resni glede svoje poti v podatkovni znanosti, je poglobljeno učenje Pythona verjetno dobra ideja!
Kvizi po predavanju
Pregled in samostojno učenje
Knjige
Spletni viri
- Uradni 10 minut za Pandas vodič
- Dokumentacija o Pandas vizualizaciji
Učenje Pythona
- Naučite se Pythona na zabaven način z grafiko Turtle in fraktali
- Naredite prve korake s Pythonom učna pot na Microsoft Learn
Naloga
Izvedite podrobnejšo študijo podatkov za zgornje izzive
Zahvale
To lekcijo je z ljubeznijo napisal Dmitry Soshnikov
Omejitev odgovornosti:
Ta dokument je bil preveden z uporabo storitve za strojno prevajanje Co-op Translator. Čeprav si prizadevamo za natančnost, vas prosimo, da se zavedate, da lahko avtomatizirani prevodi vsebujejo napake ali netočnosti. Izvirni dokument v njegovem izvirnem jeziku je treba obravnavati kot avtoritativni vir. Za ključne informacije priporočamo strokovno človeško prevajanje. Ne prevzemamo odgovornosti za morebitna nesporazumevanja ali napačne razlage, ki izhajajo iz uporabe tega prevoda.