41 KiB
Краткое введение в статистику и теорию вероятностей
 |
|---|
| Статистика и теория вероятностей - Скетчноут от @nitya |
Статистика и теория вероятностей — это две тесно связанные области математики, которые имеют большое значение для анализа данных. Можно работать с данными без глубоких знаний математики, но лучше знать хотя бы основные концепции. Здесь мы представим краткое введение, которое поможет вам начать.

Тест перед лекцией
Вероятность и случайные переменные
Вероятность — это число от 0 до 1, которое выражает, насколько вероятно наступление события. Она определяется как количество положительных исходов (ведущих к событию), делённое на общее количество исходов, при условии, что все исходы равновероятны. Например, если мы бросаем кубик, вероятность того, что выпадет чётное число, равна 3/6 = 0.5.
Когда мы говорим о событиях, мы используем случайные переменные. Например, случайная переменная, представляющая число, полученное при броске кубика, принимает значения от 1 до 6. Множество чисел от 1 до 6 называется пространством выборки. Мы можем говорить о вероятности того, что случайная переменная примет определённое значение, например P(X=3)=1/6.
Случайная переменная в предыдущем примере называется дискретной, потому что её пространство выборки счётное, то есть есть отдельные значения, которые можно перечислить. Бывают случаи, когда пространство выборки — это диапазон действительных чисел или весь набор действительных чисел. Такие переменные называются непрерывными. Хороший пример — время прибытия автобуса.
Распределение вероятностей
В случае дискретных случайных переменных легко описать вероятность каждого события с помощью функции P(X). Для каждого значения s из пространства выборки S она даст число от 0 до 1, такое, что сумма всех значений P(X=s) для всех событий будет равна 1.
Самое известное дискретное распределение — это равномерное распределение, в котором есть пространство выборки из N элементов с равной вероятностью 1/N для каждого из них.
Описать распределение вероятностей непрерывной переменной, значения которой берутся из некоторого интервала [a,b] или всего множества действительных чисел ℝ, сложнее. Рассмотрим случай времени прибытия автобуса. На самом деле, для каждого точного времени прибытия t вероятность того, что автобус прибудет именно в это время, равна 0!
Теперь вы знаете, что события с нулевой вероятностью происходят, и довольно часто! Например, каждый раз, когда прибывает автобус!
Мы можем говорить только о вероятности того, что переменная попадёт в заданный интервал значений, например P(t1≤X<t2). В этом случае распределение вероятностей описывается функцией плотности вероятности p(x), такой, что
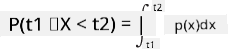
Непрерывный аналог равномерного распределения называется непрерывным равномерным, который определяется на конечном интервале. Вероятность того, что значение X попадёт в интервал длиной l, пропорциональна l и достигает 1.
Другое важное распределение — это нормальное распределение, о котором мы поговорим подробнее ниже.
Среднее, дисперсия и стандартное отклонение
Предположим, мы берём последовательность из n выборок случайной переменной X: x1, x2, ..., xn. Мы можем определить среднее (или арифметическое среднее) значение последовательности традиционным способом как (x1+x2+xn)/n. По мере увеличения размера выборки (то есть при предельном переходе n→∞) мы получим среднее (также называемое математическим ожиданием) распределения. Мы будем обозначать ожидание как E(x).
Можно показать, что для любого дискретного распределения с значениями {x1, x2, ..., xN} и соответствующими вероятностями p1, p2, ..., pN, математическое ожидание будет равно E(X)=x1p1+x2p2+...+xNpN.
Чтобы определить, насколько значения разбросаны, мы можем вычислить дисперсию σ2 = ∑(xi - μ)2/n, где μ — это среднее значение последовательности. Значение σ называется стандартным отклонением, а σ2 — дисперсией.
Мода, медиана и квартили
Иногда среднее значение неадекватно представляет "типичное" значение данных. Например, если есть несколько экстремальных значений, которые полностью выходят за рамки, они могут повлиять на среднее. Другим хорошим показателем является медиана — значение, такое, что половина точек данных ниже него, а другая половина — выше.
Чтобы лучше понять распределение данных, полезно говорить о квартилях:
- Первый квартиль, или Q1, — это значение, такое, что 25% данных ниже него
- Третий квартиль, или Q3, — это значение, такое, что 75% данных ниже него
Графически мы можем представить связь между медианой и квартилями в диаграмме, называемой боксплот:

Здесь мы также вычисляем межквартильный размах IQR=Q3-Q1 и так называемые выбросы — значения, которые лежат за пределами [Q1-1.5IQR,Q3+1.5IQR].
Для конечного распределения, содержащего небольшое количество возможных значений, хорошим "типичным" значением является то, которое встречается чаще всего, и оно называется модой. Это часто применяется к категориальным данным, таким как цвета. Рассмотрим ситуацию, когда у нас есть две группы людей — одни сильно предпочитают красный, а другие — синий. Если мы кодируем цвета числами, среднее значение для любимого цвета будет где-то в спектре оранжево-зелёного, что не отражает реальных предпочтений ни одной из групп. Однако мода будет либо одним из цветов, либо обоими цветами, если количество людей, голосующих за них, одинаково (в этом случае выборка называется мультимодальной).
Данные из реального мира
Когда мы анализируем данные из реальной жизни, они часто не являются случайными переменными в строгом смысле, то есть мы не проводим эксперименты с неизвестным результатом. Например, рассмотрим команду бейсболистов и их физические данные, такие как рост, вес и возраст. Эти числа не совсем случайны, но мы всё равно можем применять те же математические концепции. Например, последовательность весов людей можно рассматривать как последовательность значений, взятых из некоторой случайной переменной. Ниже приведена последовательность весов реальных бейсболистов из Major League Baseball, взятая из этого набора данных (для удобства показаны только первые 20 значений):
[180.0, 215.0, 210.0, 210.0, 188.0, 176.0, 209.0, 200.0, 231.0, 180.0, 188.0, 180.0, 185.0, 160.0, 180.0, 185.0, 197.0, 189.0, 185.0, 219.0]
Примечание: Чтобы увидеть пример работы с этим набором данных, посмотрите сопутствующий ноутбук. В этом уроке также есть несколько задач, которые вы можете выполнить, добавив код в этот ноутбук. Если вы не уверены, как работать с данными, не переживайте — мы вернёмся к работе с данными с использованием Python позже. Если вы не знаете, как запускать код в Jupyter Notebook, ознакомьтесь с этой статьёй.
Вот боксплот, показывающий среднее, медиану и квартили для наших данных:
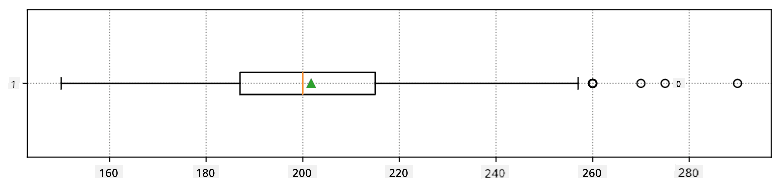
Поскольку наши данные содержат информацию о разных ролях игроков, мы также можем построить боксплот по ролям — это позволит нам понять, как значения параметров различаются в зависимости от ролей. На этот раз мы рассмотрим рост:
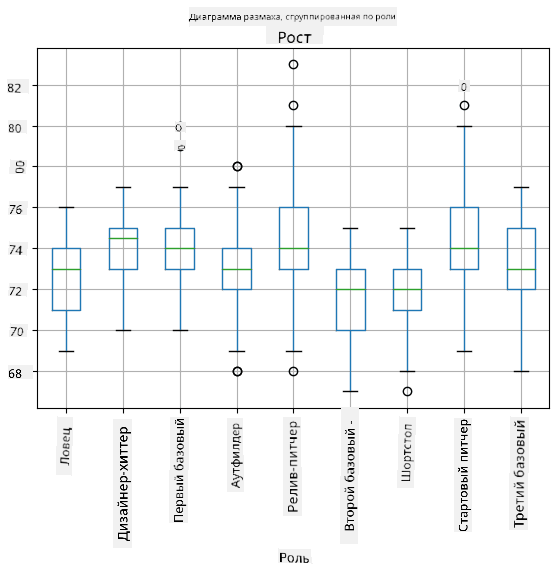
Эта диаграмма показывает, что, в среднем, рост игроков первой базы выше, чем рост игроков второй базы. Позже в этом уроке мы узнаем, как можно более формально проверить эту гипотезу и как продемонстрировать, что наши данные статистически значимы для её подтверждения.
При работе с данными из реального мира мы предполагаем, что все точки данных — это выборки, взятые из некоторого распределения вероятностей. Это предположение позволяет нам применять методы машинного обучения и строить рабочие предсказательные модели.
Чтобы увидеть, как распределены наши данные, мы можем построить график, называемый гистограммой. Ось X будет содержать количество различных интервалов веса (так называемых бинов), а вертикальная ось будет показывать количество раз, когда выборка случайной переменной попадала в данный интервал.
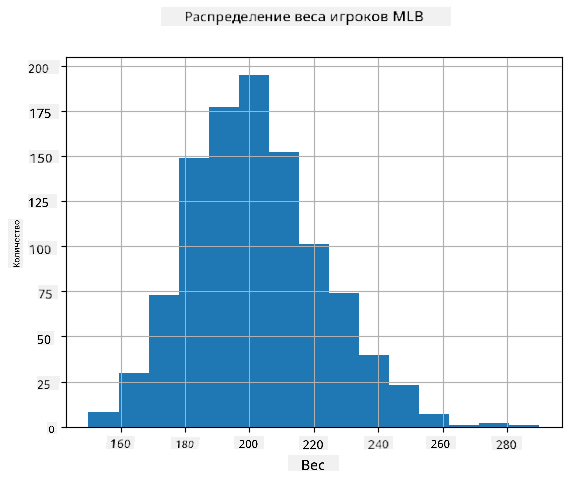
Из этой гистограммы видно, что все значения сосредоточены вокруг определённого среднего веса, и чем дальше мы отходим от этого веса, тем реже встречаются веса такого значения. То есть, вероятность того, что вес бейсболиста будет сильно отличаться от среднего веса, очень мала. Дисперсия весов показывает степень, в которой веса могут отличаться от среднего.
Если мы возьмём веса других людей, не из бейсбольной лиги, распределение, вероятно, будет другим. Однако форма распределения останется той же, но среднее и дисперсия изменятся. Таким образом, если мы обучим нашу модель на бейсболистах, она, скорее всего, даст неверные результаты при применении к студентам университета, потому что исходное распределение отличается.
Нормальное распределение
Распределение весов, которое мы видели выше, очень типично, и многие измерения из реального мира следуют тому же типу распределения, но с разными средним и дисперсией. Это распределение называется нормальным распределением, и оно играет очень важную роль в статистике.
Использование нормального распределения — это правильный способ генерировать случайные веса потенциальных бейсболистов. Как только мы знаем средний вес mean и стандартное отклонение std, мы можем сгенерировать 1000 выборок веса следующим образом:
samples = np.random.normal(mean,std,1000)
Если мы построим гистограмму сгенерированных выборок, мы увидим картину, очень похожую на ту, что показана выше. А если мы увеличим количество выборок и количество бинов, мы сможем получить изображение нормального распределения, которое будет ближе к идеальному:
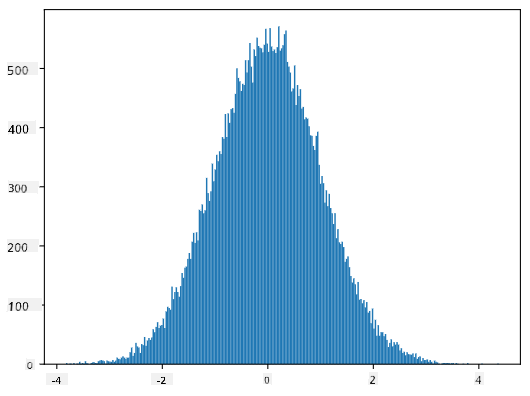
Нормальное распределение со средним=0 и стандартным отклонением=1
Доверительные интервалы
Когда мы говорим о весах бейсболистов, мы предполагаем, что существует определённая случайная переменная W, которая соответствует идеальному распределению вероятностей весов всех бейсболистов (так называемой генеральной совокупности). Наша последовательность весов соответствует подмножеству всех бейсболистов, которое мы называем выборкой. Интересный вопрос: можем ли мы узнать параметры распределения W, то есть среднее и дисперсию генеральной совокупности?
Самый простой ответ — вычислить среднее и дисперсию нашей выборки. Однако может случиться так, что наша случайная выборка не точно представляет полную генеральную совокупность. Поэтому имеет смысл говорить о доверительном интервале.
Доверительный интервал — это оценка истинного среднего генеральной совокупности на основе нашей выборки, которая точна с определённой вероятностью (или уровнем доверия).
Предположим, у нас есть выборка X...
1, ..., Xn из нашего распределения. Каждый раз, когда мы берем выборку из нашего распределения, мы получаем различное среднее значение μ. Таким образом, μ можно считать случайной величиной. Доверительный интервал с уровнем доверия p — это пара значений (Lp,Rp), таких, что P(Lp≤μ≤Rp) = p, то есть вероятность того, что измеренное среднее значение попадет в интервал, равна p.
Обсуждение того, как именно рассчитываются эти доверительные интервалы, выходит за рамки нашего краткого введения. Более подробную информацию можно найти на Википедии. Вкратце, мы определяем распределение вычисленного среднего выборки относительно истинного среднего генеральной совокупности, которое называется распределением Стьюдента.
Интересный факт: Распределение Стьюдента названо в честь математика Уильяма Сили Госета, который опубликовал свою работу под псевдонимом "Student". Он работал на пивоварне Guinness, и, согласно одной из версий, его работодатель не хотел, чтобы широкая общественность знала, что они используют статистические тесты для оценки качества сырья.
Если мы хотим оценить среднее значение μ нашей генеральной совокупности с уровнем доверия p, нам нужно взять (1-p)/2-й процентиль распределения Стьюдента A, который можно либо найти в таблицах, либо вычислить с помощью встроенных функций статистического программного обеспечения (например, Python, R и т.д.). Тогда интервал для μ будет задан как X±A*D/√n, где X — полученное среднее выборки, D — стандартное отклонение.
Примечание: Мы также опускаем обсуждение важной концепции степеней свободы, которая имеет значение в контексте распределения Стьюдента. Вы можете обратиться к более полным книгам по статистике, чтобы глубже понять эту концепцию.
Пример расчета доверительного интервала для веса и роста приведен в сопроводительных ноутбуках.
| p | Средний вес |
|---|---|
| 0.85 | 201.73±0.94 |
| 0.90 | 201.73±1.08 |
| 0.95 | 201.73±1.28 |
Обратите внимание, что чем выше вероятность доверия, тем шире доверительный интервал.
Проверка гипотез
В нашем наборе данных о бейсболистах есть разные роли игроков, которые можно обобщить следующим образом (см. сопроводительный ноутбук, чтобы узнать, как можно рассчитать эту таблицу):
| Роль | Рост | Вес | Количество |
|---|---|---|---|
| Ловец | 72.723684 | 204.328947 | 76 |
| Назначенный отбивающий | 74.222222 | 220.888889 | 18 |
| Первый базовый | 74.000000 | 213.109091 | 55 |
| Аутфилдер | 73.010309 | 199.113402 | 194 |
| Питчер-реливер | 74.374603 | 203.517460 | 315 |
| Второй базовый | 71.362069 | 184.344828 | 58 |
| Шортстоп | 71.903846 | 182.923077 | 52 |
| Стартовый питчер | 74.719457 | 205.163636 | 221 |
| Третий базовый | 73.044444 | 200.955556 | 45 |
Мы можем заметить, что средний рост первых базовых выше, чем у вторых базовых. Таким образом, мы можем сделать вывод, что первые базовые выше вторых базовых.
Это утверждение называется гипотезой, потому что мы не знаем, является ли этот факт действительно верным.
Однако не всегда очевидно, можем ли мы сделать такой вывод. Из обсуждения выше мы знаем, что каждое среднее значение имеет связанный с ним доверительный интервал, и поэтому эта разница может быть просто статистической ошибкой. Нам нужен более формальный способ проверки нашей гипотезы.
Давайте вычислим доверительные интервалы отдельно для роста первых и вторых базовых:
| Уровень доверия | Первые базовые | Вторые базовые |
|---|---|---|
| 0.85 | 73.62..74.38 | 71.04..71.69 |
| 0.90 | 73.56..74.44 | 70.99..71.73 |
| 0.95 | 73.47..74.53 | 70.92..71.81 |
Мы видим, что ни при одном уровне доверия интервалы не пересекаются. Это доказывает нашу гипотезу, что первые базовые выше вторых базовых.
Более формально, проблема, которую мы решаем, заключается в том, чтобы определить, являются ли два распределения одинаковыми, или хотя бы имеют одинаковые параметры. В зависимости от распределения, нам нужно использовать разные тесты для этого. Если мы знаем, что наши распределения нормальны, мы можем применить t-тест Стьюдента.
В t-тесте Стьюдента мы вычисляем так называемое t-значение, которое указывает на разницу между средними значениями, учитывая дисперсию. Показано, что t-значение следует распределению Стьюдента, что позволяет нам получить пороговое значение для заданного уровня доверия p (это можно вычислить или найти в числовых таблицах). Затем мы сравниваем t-значение с этим порогом, чтобы подтвердить или отклонить гипотезу.
В Python мы можем использовать пакет SciPy, который включает функцию ttest_ind (в дополнение ко многим другим полезным статистическим функциям!). Она вычисляет t-значение за нас, а также выполняет обратный поиск значения доверия p, чтобы мы могли просто посмотреть на уровень доверия и сделать вывод.
Например, наше сравнение роста первых и вторых базовых дает следующие результаты:
from scipy.stats import ttest_ind
tval, pval = ttest_ind(df.loc[df['Role']=='First_Baseman',['Height']], df.loc[df['Role']=='Designated_Hitter',['Height']],equal_var=False)
print(f"T-value = {tval[0]:.2f}\nP-value: {pval[0]}")
T-value = 7.65
P-value: 9.137321189738925e-12
В нашем случае значение p очень низкое, что означает, что есть сильные доказательства того, что первые базовые выше.
Существуют также другие типы гипотез, которые мы можем захотеть проверить, например:
- Доказать, что данная выборка следует некоторому распределению. В нашем случае мы предположили, что рост распределен нормально, но это требует формальной статистической проверки.
- Доказать, что среднее значение выборки соответствует некоторому заранее заданному значению.
- Сравнить средние значения нескольких выборок (например, различия в уровнях счастья среди разных возрастных групп).
Закон больших чисел и центральная предельная теорема
Одной из причин, почему нормальное распределение так важно, является так называемая центральная предельная теорема. Предположим, у нас есть большая выборка независимых N значений X1, ..., XN, взятых из любого распределения с средним μ и дисперсией σ2. Тогда, для достаточно большого N (другими словами, когда N→∞), среднее ΣiXi будет нормально распределено, с средним μ и дисперсией σ2/N.
Другой способ интерпретировать центральную предельную теорему — это сказать, что независимо от распределения, когда вы вычисляете среднее суммы любых значений случайной величины, вы получаете нормальное распределение.
Из центральной предельной теоремы также следует, что, когда N→∞, вероятность того, что среднее значение выборки будет равно μ, становится равной 1. Это известно как закон больших чисел.
Ковариация и корреляция
Одной из задач Data Science является поиск связей между данными. Мы говорим, что две последовательности коррелируют, когда они демонстрируют схожее поведение одновременно, то есть либо растут/падают одновременно, либо одна последовательность растет, когда другая падает, и наоборот. Другими словами, между двумя последовательностями, кажется, есть какая-то связь.
Корреляция не обязательно указывает на причинно-следственную связь между двумя последовательностями; иногда обе переменные могут зависеть от какой-то внешней причины, или это может быть чисто случайным совпадением, что две последовательности коррелируют. Однако сильная математическая корреляция — хороший признак того, что две переменные как-то связаны.
Математически основным понятием, показывающим связь между двумя случайными величинами, является ковариация, которая вычисляется следующим образом: Cov(X,Y) = E[(X-E(X))(Y-E(Y))]. Мы вычисляем отклонение обеих переменных от их средних значений, а затем произведение этих отклонений. Если обе переменные отклоняются вместе, произведение всегда будет положительным значением, которое добавится к положительной ковариации. Если обе переменные отклоняются несинхронно (то есть одна падает ниже среднего, когда другая растет выше среднего), мы всегда получим отрицательные числа, которые добавятся к отрицательной ковариации. Если отклонения не зависят друг от друга, они сложатся примерно в ноль.
Абсолютное значение ковариации не говорит нам много о том, насколько велика корреляция, потому что оно зависит от величины фактических значений. Чтобы нормализовать его, мы можем разделить ковариацию на стандартное отклонение обеих переменных, чтобы получить корреляцию. Хорошо то, что корреляция всегда находится в диапазоне [-1,1], где 1 указывает на сильную положительную корреляцию между значениями, -1 — на сильную отрицательную корреляцию, а 0 — на отсутствие корреляции (переменные независимы).
Пример: Мы можем вычислить корреляцию между весом и ростом бейсболистов из упомянутого выше набора данных:
print(np.corrcoef(weights,heights))
В результате мы получаем матрицу корреляции, подобную этой:
array([[1. , 0.52959196],
[0.52959196, 1. ]])
Матрица корреляции C может быть вычислена для любого количества входных последовательностей S1, ..., Sn. Значение Cij — это корреляция между Si и Sj, а диагональные элементы всегда равны 1 (что также является самокорреляцией Si).
В нашем случае значение 0.53 указывает на то, что существует некоторая корреляция между весом и ростом человека. Мы также можем построить диаграмму рассеяния одного значения против другого, чтобы визуально увидеть связь:
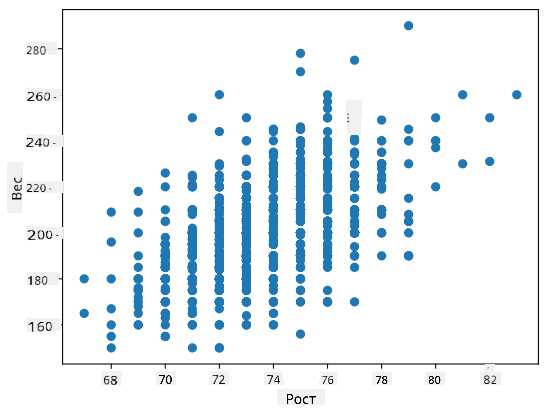
Больше примеров корреляции и ковариации можно найти в сопроводительном ноутбуке.
Заключение
В этом разделе мы узнали:
- основные статистические свойства данных, такие как среднее, дисперсия, мода и квартили
- различные распределения случайных величин, включая нормальное распределение
- как найти корреляцию между различными свойствами
- как использовать математический и статистический аппарат для доказательства гипотез
- как вычислять доверительные интервалы для случайной величины на основе выборки данных
Хотя это, безусловно, не исчерпывающий список тем, существующих в теории вероятностей и статистике, он должен быть достаточным, чтобы дать вам хороший старт в этом курсе.
🚀 Задание
Используйте пример кода в ноутбуке, чтобы проверить другие гипотезы:
- Первые базовые старше вторых базовых
- Первые базовые выше третьих базовых
- Шортстопы выше вторых базовых
Тест после лекции
Обзор и самостоятельное изучение
Теория вероятностей и статистика — настолько обширная тема, что заслуживает отдельного курса. Если вы хотите углубиться в теорию, вам могут быть интересны следующие книги:
- Карлос Фернандес-Гранда из Нью-Йоркского университета подготовил отличные лекционные материалы Probability and Statistics for Data Science (доступны онлайн).
- Питер и Эндрю Брюс. Практическая статистика для специалистов по данным. [пример кода на R].
- Джеймс Д. Миллер. Статистика для специалистов по данным [пример кода на R].
Задание
Благодарности
Этот урок был создан с ♥️ Дмитрием Сошниковым.
Отказ от ответственности:
Этот документ был переведен с использованием сервиса автоматического перевода Co-op Translator. Несмотря на наши усилия обеспечить точность, автоматические переводы могут содержать ошибки или неточности. Оригинальный документ на его исходном языке следует считать авторитетным источником. Для получения критически важной информации рекомендуется профессиональный перевод человеком. Мы не несем ответственности за любые недоразумения или неправильные интерпретации, возникшие в результате использования данного перевода.