19 KiB
Știința Datelor în Cloud: Metoda "Azure ML SDK"
 |
|---|
| Știința Datelor în Cloud: Azure ML SDK - Sketchnote de @nitya |
Cuprins:
- Știința Datelor în Cloud: Metoda "Azure ML SDK"
Chestionar înainte de lecție
1. Introducere
1.1 Ce este Azure ML SDK?
Cercetătorii în domeniul datelor și dezvoltatorii AI folosesc Azure Machine Learning SDK pentru a construi și rula fluxuri de lucru de învățare automată cu serviciul Azure Machine Learning. Poți interacționa cu serviciul în orice mediu Python, inclusiv Jupyter Notebooks, Visual Studio Code sau IDE-ul tău preferat pentru Python.
Zonele cheie ale SDK-ului includ:
- Explorarea, pregătirea și gestionarea ciclului de viață al dataseturilor utilizate în experimentele de învățare automată.
- Gestionarea resurselor cloud pentru monitorizare, logare și organizarea experimentelor de învățare automată.
- Antrenarea modelelor fie local, fie utilizând resurse cloud, inclusiv antrenarea modelelor accelerată de GPU.
- Utilizarea învățării automate automate, care acceptă parametrii de configurare și datele de antrenament. Aceasta iterează automat prin algoritmi și setări de hiperparametri pentru a găsi cel mai bun model pentru rularea predicțiilor.
- Implementarea serviciilor web pentru a transforma modelele antrenate în servicii RESTful care pot fi consumate în orice aplicație.
Află mai multe despre Azure Machine Learning SDK
În lecția anterioară, am văzut cum să antrenăm, implementăm și consumăm un model într-un mod Low code/No code. Am folosit datasetul de insuficiență cardiacă pentru a genera un model de predicție a insuficienței cardiace. În această lecție, vom face exact același lucru, dar utilizând Azure Machine Learning SDK.
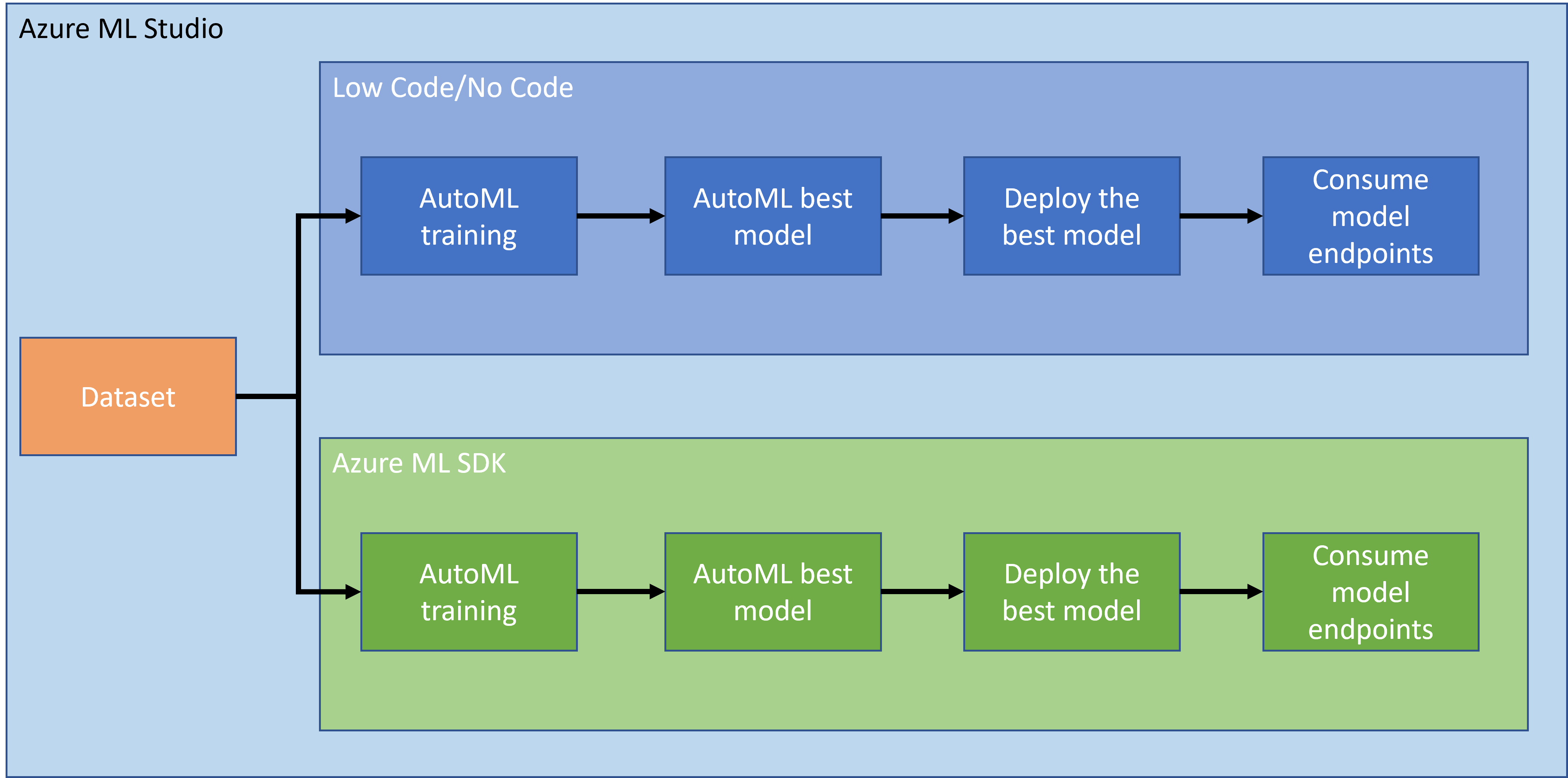
1.2 Proiectul de predicție a insuficienței cardiace și introducerea datasetului
Consultă aici introducerea proiectului de predicție a insuficienței cardiace și datasetului.
2. Antrenarea unui model cu Azure ML SDK
2.1 Crearea unui workspace Azure ML
Pentru simplitate, vom lucra într-un notebook Jupyter. Acest lucru implică faptul că deja ai un Workspace și o instanță de calcul. Dacă ai deja un Workspace, poți sări direct la secțiunea 2.3 Crearea notebook-urilor.
Dacă nu, te rugăm să urmezi instrucțiunile din secțiunea 2.1 Crearea unui workspace Azure ML din lecția anterioară pentru a crea un workspace.
2.2 Crearea unei instanțe de calcul
În workspace-ul Azure ML pe care l-am creat anterior, accesează meniul de calcul și vei vedea diferitele resurse de calcul disponibile.

Să creăm o instanță de calcul pentru a provisiona un notebook Jupyter.
- Apasă pe butonul + New.
- Dă un nume instanței tale de calcul.
- Alege opțiunile: CPU sau GPU, dimensiunea VM și numărul de nuclee.
- Apasă pe butonul Create.
Felicitări, tocmai ai creat o instanță de calcul! Vom folosi această instanță de calcul pentru a crea un notebook în secțiunea Crearea notebook-urilor.
2.3 Încărcarea datasetului
Consultă lecția anterioară în secțiunea 2.3 Încărcarea datasetului dacă nu ai încărcat încă datasetul.
2.4 Crearea notebook-urilor
NOTĂ: Pentru pasul următor, poți fie să creezi un notebook nou de la zero, fie să încarci notebook-ul pe care l-am creat în Azure ML Studio. Pentru a-l încărca, pur și simplu apasă pe meniul "Notebook" și încarcă notebook-ul.
Notebook-urile sunt o parte foarte importantă a procesului de știință a datelor. Ele pot fi utilizate pentru a efectua Analiza Exploratorie a Datelor (EDA), pentru a apela un cluster de calcul pentru antrenarea unui model sau pentru a apela un cluster de inferență pentru a implementa un endpoint.
Pentru a crea un notebook, avem nevoie de un nod de calcul care servește instanța notebook-ului Jupyter. Revino la workspace-ul Azure ML și apasă pe Instanțe de calcul. În lista de instanțe de calcul ar trebui să vezi instanța de calcul pe care am creat-o anterior.
- În secțiunea Aplicații, apasă pe opțiunea Jupyter.
- Bifează caseta "Yes, I understand" și apasă pe butonul Continue.

- Acest lucru ar trebui să deschidă o filă nouă în browser cu instanța notebook-ului Jupyter. Apasă pe butonul "New" pentru a crea un notebook.

Acum că avem un notebook, putem începe antrenarea modelului cu Azure ML SDK.
2.5 Antrenarea unui model
În primul rând, dacă ai vreodată vreo îndoială, consultă documentația Azure ML SDK. Aceasta conține toate informațiile necesare pentru a înțelege modulele pe care le vom vedea în această lecție.
2.5.1 Configurarea workspace-ului, experimentului, clusterului de calcul și datasetului
Trebuie să încarci workspace din fișierul de configurare utilizând următorul cod:
from azureml.core import Workspace
ws = Workspace.from_config()
Acesta returnează un obiect de tip Workspace care reprezintă workspace-ul. Apoi trebuie să creezi un experiment utilizând următorul cod:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Pentru a obține sau crea un experiment dintr-un workspace, soliciți experimentul utilizând numele experimentului. Numele experimentului trebuie să aibă între 3 și 36 de caractere, să înceapă cu o literă sau un număr și să conțină doar litere, numere, underscore-uri și liniuțe. Dacă experimentul nu este găsit în workspace, se creează un experiment nou.
Acum trebuie să creezi un cluster de calcul pentru antrenare utilizând următorul cod. Reține că acest pas poate dura câteva minute.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Poți obține datasetul din workspace utilizând numele datasetului în următorul mod:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Configurarea AutoML și antrenarea
Pentru a seta configurația AutoML, folosește clasa AutoMLConfig.
Așa cum este descris în documentație, există o mulțime de parametri cu care poți lucra. Pentru acest proiect, vom folosi următorii parametri:
experiment_timeout_minutes: Timpul maxim (în minute) permis pentru rularea experimentului înainte ca acesta să fie oprit automat și rezultatele să fie disponibile automat.max_concurrent_iterations: Numărul maxim de iterații de antrenament concurente permise pentru experiment.primary_metric: Metrica principală utilizată pentru a determina starea experimentului.compute_target: Resursa de calcul Azure Machine Learning pe care se rulează experimentul de învățare automată automatizată.task: Tipul de sarcină de rulare. Valorile pot fi 'classification', 'regression' sau 'forecasting', în funcție de tipul de problemă de învățare automată automatizată de rezolvat.training_data: Datele de antrenament care urmează să fie utilizate în cadrul experimentului. Acestea ar trebui să conțină atât caracteristicile de antrenament, cât și o coloană de etichete (opțional o coloană de greutăți ale eșantionului).label_column_name: Numele coloanei de etichete.path: Calea completă către folderul proiectului Azure Machine Learning.enable_early_stopping: Dacă se permite terminarea timpurie în cazul în care scorul nu se îmbunătățește pe termen scurt.featurization: Indicator pentru dacă pasul de featurizare ar trebui să fie realizat automat sau nu, sau dacă ar trebui utilizată featurizarea personalizată.debug_log: Fișierul de log în care se scriu informațiile de depanare.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Acum că ai configurarea setată, poți antrena modelul utilizând următorul cod. Acest pas poate dura până la o oră, în funcție de dimensiunea clusterului.
remote_run = experiment.submit(automl_config)
Poți rula widgetul RunDetails pentru a afișa diferitele experimente.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Implementarea modelului și consumul endpointului cu Azure ML SDK
3.1 Salvarea celui mai bun model
remote_run este un obiect de tip AutoMLRun. Acest obiect conține metoda get_output() care returnează cea mai bună rulare și modelul ajustat corespunzător.
best_run, fitted_model = remote_run.get_output()
Poți vedea parametrii utilizați pentru cel mai bun model doar prin imprimarea fitted_model și poți vedea proprietățile celui mai bun model utilizând metoda get_properties().
best_run.get_properties()
Acum înregistrează modelul cu metoda register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Implementarea modelului
Odată ce cel mai bun model este salvat, îl putem implementa cu clasa InferenceConfig. InferenceConfig reprezintă setările de configurare pentru un mediu personalizat utilizat pentru implementare. Clasa AciWebservice reprezintă un model de învățare automată implementat ca un endpoint de serviciu web pe Azure Container Instances. Un serviciu implementat este creat dintr-un model, script și fișiere asociate. Serviciul web rezultat este un endpoint HTTP echilibrat, cu o API REST. Poți trimite date către această API și primi predicția returnată de model.
Modelul este implementat utilizând metoda deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Acest pas ar trebui să dureze câteva minute.
3.3 Consumarea endpointului
Poți consuma endpointul creând un input de exemplu:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Apoi poți trimite acest input către modelul tău pentru predicție:
response = aci_service.run(input_data=test_sample)
response
Acesta ar trebui să returneze '{"result": [false]}'. Aceasta înseamnă că datele pacientului pe care le-am trimis la endpoint au generat predicția false, ceea ce indică faptul că această persoană nu este predispusă la un atac de cord.
Felicitări! Tocmai ai utilizat modelul implementat și antrenat pe Azure ML folosind Azure ML SDK!
NOTE: După ce ai terminat proiectul, nu uita să ștergi toate resursele.
🚀 Provocare
Există multe alte lucruri pe care le poți face prin SDK, din păcate, nu le putem acoperi pe toate în această lecție. Dar vestea bună este că învățarea modului de a naviga prin documentația SDK te poate ajuta foarte mult pe cont propriu. Aruncă o privire la documentația Azure ML SDK și găsește clasa Pipeline, care îți permite să creezi pipeline-uri. Un Pipeline este o colecție de pași care pot fi executați ca un flux de lucru.
INDICIU: Accesează documentația SDK și tastează cuvinte cheie în bara de căutare, cum ar fi "Pipeline". Ar trebui să găsești clasa azureml.pipeline.core.Pipeline în rezultatele căutării.
Test de verificare după lecție
Recapitulare & Studiu individual
În această lecție, ai învățat cum să antrenezi, implementezi și utilizezi un model pentru a prezice riscul de insuficiență cardiacă folosind Azure ML SDK în cloud. Consultă această documentație pentru informații suplimentare despre Azure ML SDK. Încearcă să creezi propriul tău model folosind Azure ML SDK.
Temă
Proiect de Data Science folosind Azure ML SDK
Declinare de responsabilitate:
Acest document a fost tradus folosind serviciul de traducere AI Co-op Translator. Deși ne străduim să asigurăm acuratețea, vă rugăm să fiți conștienți că traducerile automate pot conține erori sau inexactități. Documentul original în limba sa natală ar trebui considerat sursa autoritară. Pentru informații critice, se recomandă traducerea profesională realizată de un specialist uman. Nu ne asumăm responsabilitatea pentru eventualele neînțelegeri sau interpretări greșite care pot apărea din utilizarea acestei traduceri.