20 KiB
ਵੰਡਾਂ ਨੂੰ ਦਿਖਾਉਣਾ
 |
|---|
| ਵੰਡਾਂ ਨੂੰ ਦਿਖਾਉਣਾ - ਸਕੇਚਨੋਟ @nitya ਦੁਆਰਾ |
ਪਿਛਲੇ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਮਿਨੇਸੋਟਾ ਦੇ ਪੰਛੀਆਂ ਬਾਰੇ ਡਾਟਾਸੈਟ ਦੇ ਕੁਝ ਦਿਲਚਸਪ ਤੱਥ ਸਿੱਖੇ। ਤੁਸੀਂ ਆਊਟਲਾਇਰਜ਼ ਨੂੰ ਦਿਖਾ ਕੇ ਗਲਤ ਡਾਟਾ ਲੱਭਿਆ ਅਤੇ ਵੱਖ-ਵੱਖ ਪੰਛੀ ਸ਼੍ਰੇਣੀਆਂ ਦੇ ਵੱਧ ਤੋਂ ਵੱਧ ਲੰਬਾਈ ਦੇ ਅੰਤਰਾਂ ਨੂੰ ਵੇਖਿਆ।
ਪਾਠ-ਪਹਿਲਾਂ ਕਵਿਜ਼
ਪੰਛੀਆਂ ਦੇ ਡਾਟਾਸੈਟ ਦੀ ਖੋਜ ਕਰੋ
ਡਾਟਾ ਵਿੱਚ ਖੋਜ ਕਰਨ ਦਾ ਇੱਕ ਹੋਰ ਤਰੀਕਾ ਇਹ ਦੇਖਣਾ ਹੈ ਕਿ ਇਹ ਕਿਵੇਂ ਇੱਕ ਧੁਰੇ 'ਤੇ ਵਿਵਸਥਿਤ ਹੈ। ਉਦਾਹਰਣ ਲਈ, ਸ਼ਾਇਦ ਤੁਸੀਂ ਮਿਨੇਸੋਟਾ ਦੇ ਪੰਛੀਆਂ ਲਈ ਵੱਧ ਤੋਂ ਵੱਧ ਪੰਖਾਂ ਦੇ ਫੈਲਾਅ ਜਾਂ ਵੱਧ ਤੋਂ ਵੱਧ ਸਰੀਰਕ ਭਾਰ ਦੀ ਆਮ ਵੰਡ ਬਾਰੇ ਜਾਣਨਾ ਚਾਹੁੰਦੇ ਹੋ।
ਆਓ ਇਸ ਡਾਟਾਸੈਟ ਵਿੱਚ ਡਾਟਾ ਦੀਆਂ ਵੰਡਾਂ ਬਾਰੇ ਕੁਝ ਤੱਥ ਪਤਾ ਕਰੀਏ। ਆਪਣੇ R ਕੰਸੋਲ ਵਿੱਚ, ggplot2 ਅਤੇ ਡਾਟਾਬੇਸ ਨੂੰ ਇੰਪੋਰਟ ਕਰੋ। ਪਿਛਲੇ ਵਿਸ਼ੇ ਵਿੱਚ ਦਿੱਤੇ ਗਏ ਤਰੀਕੇ ਨਾਲ ਡਾਟਾਬੇਸ ਤੋਂ ਆਊਟਲਾਇਰਜ਼ ਨੂੰ ਹਟਾਓ।
library(ggplot2)
birds <- read.csv("../../data/birds.csv",fileEncoding="UTF-8-BOM")
birds_filtered <- subset(birds, MaxWingspan < 500)
head(birds_filtered)
| ਨਾਮ | ਵਿਗਿਆਨਕ ਨਾਮ | ਸ਼੍ਰੇਣੀ | ਕ੍ਰਮ | ਪਰਿਵਾਰ | ਜਨਸ | ਸੰਰਕਸ਼ਣ ਸਥਿਤੀ | ਘੱਟੋ-ਘੱਟ ਲੰਬਾਈ | ਵੱਧ ਤੋਂ ਵੱਧ ਲੰਬਾਈ | ਘੱਟੋ-ਘੱਟ ਸਰੀਰਕ ਭਾਰ | ਵੱਧ ਤੋਂ ਵੱਧ ਸਰੀਰਕ ਭਾਰ | ਘੱਟੋ-ਘੱਟ ਪੰਖਾਂ ਦਾ ਫੈਲਾਅ | ਵੱਧ ਤੋਂ ਵੱਧ ਪੰਖਾਂ ਦਾ ਫੈਲਾਅ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ਕਾਲੇ ਪੇਟ ਵਾਲਾ ਵਿਸਲਿੰਗ-ਡੱਕ | Dendrocygna autumnalis | ਬਤਖਾਂ/ਹੰਸ/ਜਲ ਪੰਛੀ | Anseriformes | Anatidae | Dendrocygna | LC | 47 | 56 | 652 | 1020 | 76 | 94 |
| 1 | ਫੁਲਵਸ ਵਿਸਲਿੰਗ-ਡੱਕ | Dendrocygna bicolor | ਬਤਖਾਂ/ਹੰਸ/ਜਲ ਪੰਛੀ | Anseriformes | Anatidae | Dendrocygna | LC | 45 | 53 | 712 | 1050 | 85 | 93 |
| 2 | ਸਨੋ ਗੂਸ | Anser caerulescens | ਬਤਖਾਂ/ਹੰਸ/ਜਲ ਪੰਛੀ | Anseriformes | Anatidae | Anser | LC | 64 | 79 | 2050 | 4050 | 135 | 165 |
| 3 | ਰੌਸ ਦਾ ਗੂਸ | Anser rossii | ਬਤਖਾਂ/ਹੰਸ/ਜਲ ਪੰਛੀ | Anseriformes | Anatidae | Anser | LC | 57.3 | 64 | 1066 | 1567 | 113 | 116 |
| 4 | ਵੱਡਾ ਸਫੈਦ-ਮੂੰਹ ਵਾਲਾ ਗੂਸ | Anser albifrons | ਬਤਖਾਂ/ਹੰਸ/ਜਲ ਪੰਛੀ | Anseriformes | Anatidae | Anser | LC | 64 | 81 | 1930 | 3310 | 130 | 165 |
ਆਮ ਤੌਰ 'ਤੇ, ਤੁਸੀਂ ਸਕੈਟਰ ਪਲਾਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਜਿਵੇਂ ਪਿਛਲੇ ਪਾਠ ਵਿੱਚ ਕੀਤਾ ਸੀ, ਡਾਟਾ ਦੀ ਵੰਡ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਦੇਖ ਸਕਦੇ ਹੋ:
ggplot(data=birds_filtered, aes(x=Order, y=MaxLength,group=1)) +
geom_point() +
ggtitle("Max Length per order") + coord_flip()
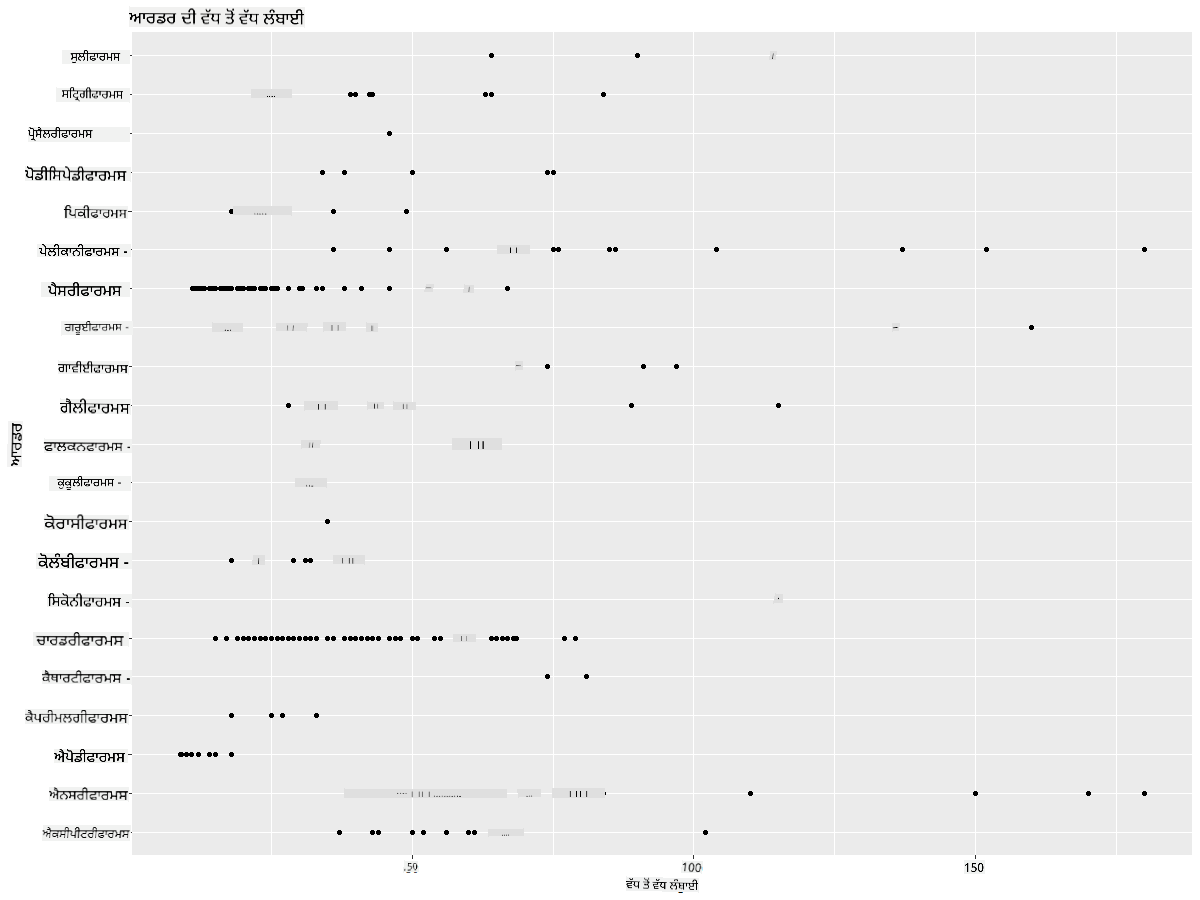
ਇਹ ਪੰਛੀ ਦੇ ਕ੍ਰਮ ਪ੍ਰਤੀ ਸਰੀਰਕ ਲੰਬਾਈ ਦੀ ਆਮ ਵੰਡ ਦਾ ਝਲਕ ਦਿੰਦਾ ਹੈ, ਪਰ ਇਹ ਸੱਚੀ ਵੰਡਾਂ ਨੂੰ ਦਿਖਾਉਣ ਦਾ ਸਭ ਤੋਂ ਵਧੀਆ ਤਰੀਕਾ ਨਹੀਂ ਹੈ। ਇਹ ਕੰਮ ਆਮ ਤੌਰ 'ਤੇ ਹਿਸਟੋਗ੍ਰਾਮ ਬਣਾਉਣ ਦੁਆਰਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਹਿਸਟੋਗ੍ਰਾਮ ਨਾਲ ਕੰਮ ਕਰਨਾ
ggplot2 ਹਿਸਟੋਗ੍ਰਾਮ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਡਾਟਾ ਵੰਡ ਨੂੰ ਦਿਖਾਉਣ ਦੇ ਬਹੁਤ ਵਧੀਆ ਤਰੀਕੇ ਪੇਸ਼ ਕਰਦਾ ਹੈ। ਇਸ ਪ੍ਰਕਾਰ ਦਾ ਚਾਰਟ ਇੱਕ ਬਾਰ ਚਾਰਟ ਵਾਂਗ ਹੁੰਦਾ ਹੈ ਜਿੱਥੇ ਵੰਡ ਬਾਰਾਂ ਦੇ ਉਤਾਰ-ਚੜ੍ਹਾਅ ਰਾਹੀਂ ਵੇਖੀ ਜਾ ਸਕਦੀ ਹੈ। ਹਿਸਟੋਗ੍ਰਾਮ ਬਣਾਉਣ ਲਈ, ਤੁਹਾਨੂੰ ਸੰਖਿਆਤਮਕ ਡਾਟਾ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਹਿਸਟੋਗ੍ਰਾਮ ਬਣਾਉਣ ਲਈ, ਤੁਸੀਂ ਚਾਰਟ ਨੂੰ 'hist' ਕਿਸਮ ਵਜੋਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰਕੇ ਪਲਾਟ ਕਰ ਸਕਦੇ ਹੋ। ਇਹ ਚਾਰਟ ਪੂਰੇ ਡਾਟਾਸੈਟ ਦੀ ਵੱਧ ਤੋਂ ਵੱਧ ਸਰੀਰਕ ਭਾਰ ਦੀ ਵੰਡ ਦਿਖਾਉਂਦਾ ਹੈ। ਡਾਟਾ ਦੀ ਲੜੀ ਨੂੰ ਛੋਟੇ ਬਿਨਾਂ ਵਿੱਚ ਵੰਡ ਕੇ, ਇਹ ਡਾਟਾ ਦੇ ਮੁੱਲਾਂ ਦੀ ਵੰਡ ਦਿਖਾ ਸਕਦਾ ਹੈ:
ggplot(data = birds_filtered, aes(x = MaxBodyMass)) +
geom_histogram(bins=10)+ylab('Frequency')
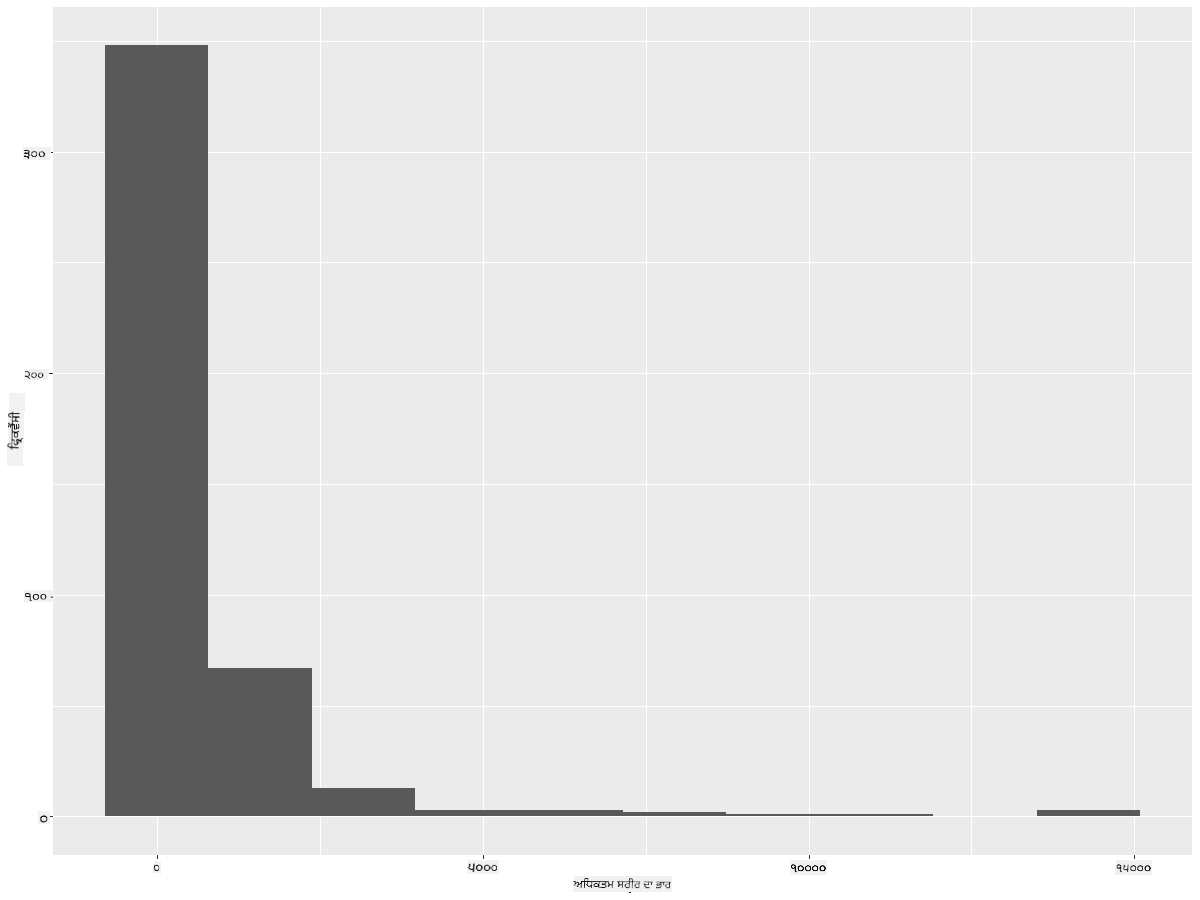
ਜਿਵੇਂ ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ, ਇਸ ਡਾਟਾਸੈਟ ਵਿੱਚ ਮੌਜੂਦ 400+ ਪੰਛੀਆਂ ਵਿੱਚੋਂ ਜ਼ਿਆਦਾਤਰ ਦਾ ਵੱਧ ਤੋਂ ਵੱਧ ਸਰੀਰਕ ਭਾਰ 2000 ਤੋਂ ਘੱਟ ਹੈ। bins ਪੈਰਾਮੀਟਰ ਨੂੰ ਵਧੇਰੇ ਸੰਖਿਆ, ਜਿਵੇਂ ਕਿ 30, ਵਿੱਚ ਬਦਲ ਕੇ ਡਾਟਾ ਬਾਰੇ ਹੋਰ ਜਾਣਕਾਰੀ ਪ੍ਰਾਪਤ ਕਰੋ:
ggplot(data = birds_filtered, aes(x = MaxBodyMass)) + geom_histogram(bins=30)+ylab('Frequency')
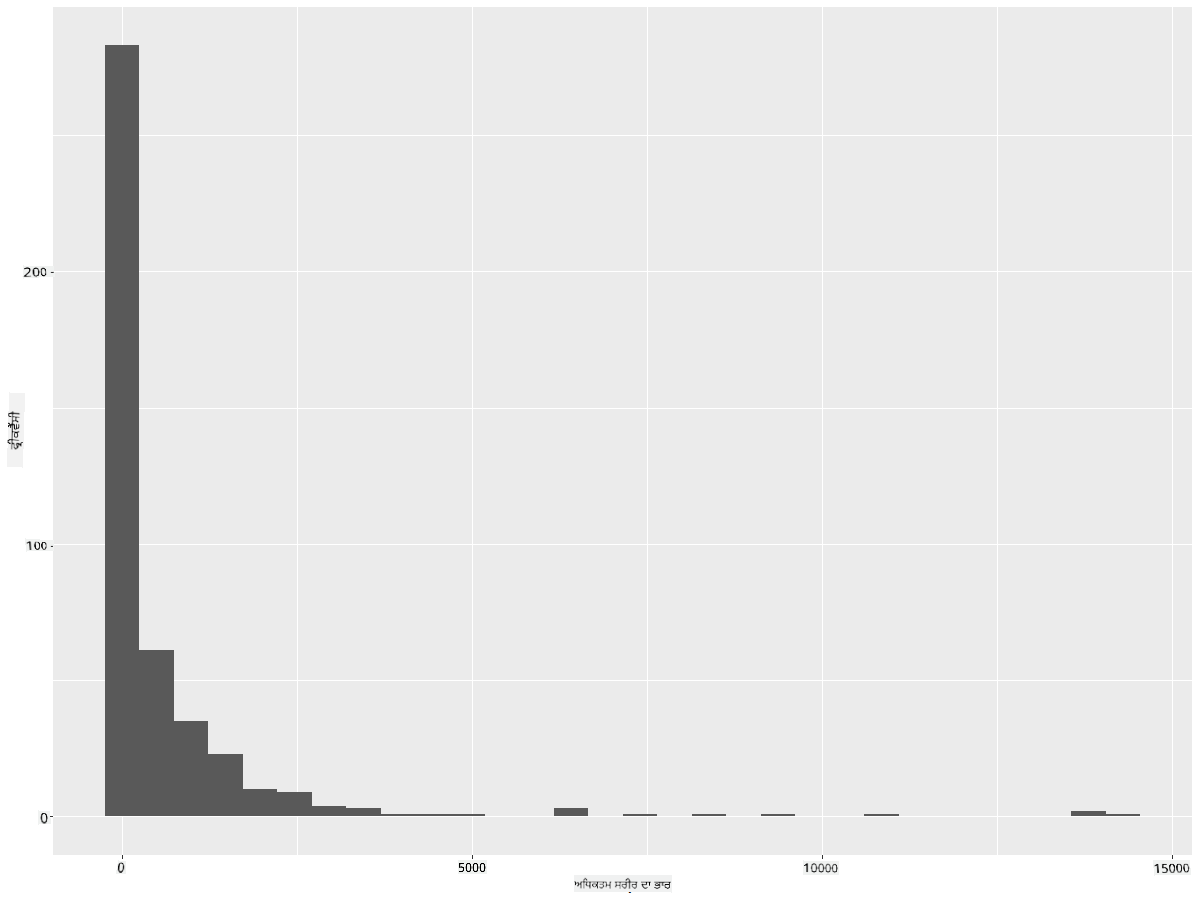
ਇਹ ਚਾਰਟ ਵੰਡ ਨੂੰ ਹੋਰ ਵਿਸਤ੍ਰਿਤ ਢੰਗ ਨਾਲ ਦਿਖਾਉਂਦਾ ਹੈ। ਇੱਕ ਚਾਰਟ ਜੋ ਖੱਬੇ ਵੱਲ ਘੱਟ ਝੁਕਿਆ ਹੋਵੇ, ਉਹ ਇਸ ਤਰੀਕੇ ਨਾਲ ਬਣਾਇਆ ਜਾ ਸਕਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਸਿਰਫ਼ ਇੱਕ ਦਿੱਤੇ ਗਏ ਰੇਂਜ ਦੇ ਅੰਦਰ ਡਾਟਾ ਚੁਣੋ:
ਆਪਣੇ ਡਾਟਾ ਨੂੰ ਫਿਲਟਰ ਕਰੋ ਤਾਂ ਜੋ ਸਿਰਫ਼ ਉਹ ਪੰਛੀ ਮਿਲਣ ਜਿਨ੍ਹਾਂ ਦਾ ਸਰੀਰਕ ਭਾਰ 60 ਤੋਂ ਘੱਟ ਹੈ, ਅਤੇ 30 bins ਦਿਖਾਓ:
birds_filtered_1 <- subset(birds_filtered, MaxBodyMass > 1 & MaxBodyMass < 60)
ggplot(data = birds_filtered_1, aes(x = MaxBodyMass)) +
geom_histogram(bins=30)+ylab('Frequency')

✅ ਕੁਝ ਹੋਰ ਫਿਲਟਰ ਅਤੇ ਡਾਟਾ ਪੌਇੰਟਸ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋ। ਡਾਟਾ ਦੀ ਪੂਰੀ ਵੰਡ ਦੇਖਣ ਲਈ, ['MaxBodyMass'] ਫਿਲਟਰ ਨੂੰ ਹਟਾਓ ਅਤੇ ਲੇਬਲ ਕੀਤੀਆਂ ਵੰਡਾਂ ਦਿਖਾਓ।
ਹਿਸਟੋਗ੍ਰਾਮ ਵਿੱਚ ਰੰਗ ਅਤੇ ਲੇਬਲਿੰਗ ਨੂੰ ਸੁਧਾਰਨ ਦੇ ਕੁਝ ਵਧੀਆ ਵਿਕਲਪ ਵੀ ਹਨ:
ਦੋ ਵੰਡਾਂ ਦੇ ਰਿਸ਼ਤੇ ਦੀ ਤੁਲਨਾ ਕਰਨ ਲਈ ਇੱਕ 2D ਹਿਸਟੋਗ੍ਰਾਮ ਬਣਾਓ। ਆਓ MaxBodyMass ਅਤੇ MaxLength ਦੀ ਤੁਲਨਾ ਕਰੀਏ। ggplot2 ਰੌਸ਼ਨ ਰੰਗਾਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਮਿਲਾਪ ਦਿਖਾਉਣ ਦਾ ਇੱਕ ਬਣਾਇਆ ਹੋਇਆ ਤਰੀਕਾ ਪੇਸ਼ ਕਰਦਾ ਹੈ:
ggplot(data=birds_filtered_1, aes(x=MaxBodyMass, y=MaxLength) ) +
geom_bin2d() +scale_fill_continuous(type = "viridis")
ਇਹ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ ਕਿ ਉਮੀਦ ਕੀਤੀ ਗਈ ਧੁਰੇ ਦੇ ਨਾਲ ਇਹ ਦੋ ਤੱਤ ਇੱਕ ਦੂਜੇ ਨਾਲ ਸੰਬੰਧਿਤ ਹਨ, ਇੱਕ ਖਾਸ ਤੌਰ 'ਤੇ ਮਜ਼ਬੂਤ ਮਿਲਾਪ ਦੇ ਬਿੰਦੂ ਨਾਲ:
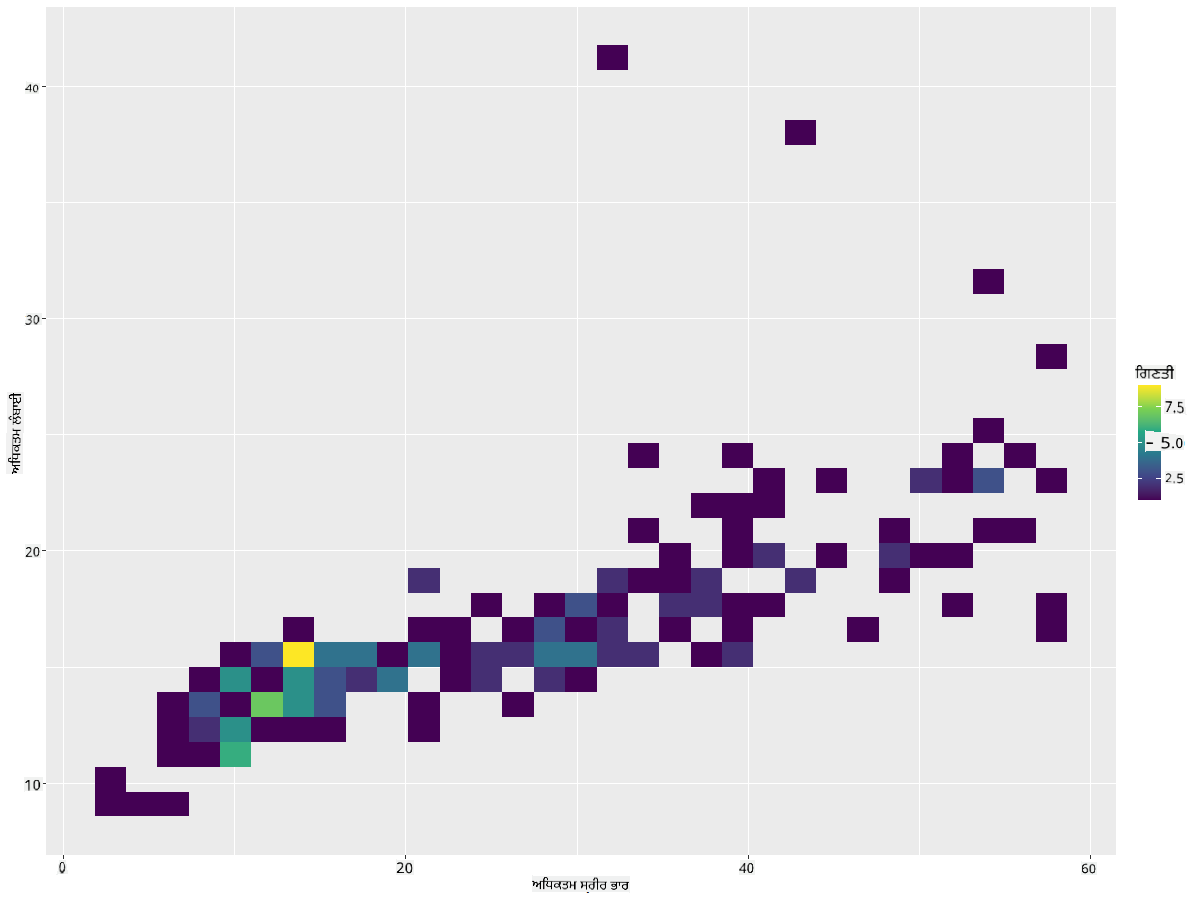
ਹਿਸਟੋਗ੍ਰਾਮ ਆਮ ਤੌਰ 'ਤੇ ਸੰਖਿਆਤਮਕ ਡਾਟਾ ਲਈ ਚੰਗੇ ਕੰਮ ਕਰਦੇ ਹਨ। ਪਰ ਜੇ ਤੁਸੀਂ ਟੈਕਸਟ ਡਾਟਾ ਦੇ ਅਨੁਸਾਰ ਵੰਡਾਂ ਨੂੰ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਕੀ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ?
ਟੈਕਸਟ ਡਾਟਾ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਡਾਟਾਸੈਟ ਦੀ ਖੋਜ ਕਰੋ
ਇਸ ਡਾਟਾਸੈਟ ਵਿੱਚ ਪੰਛੀ ਦੀ ਸ਼੍ਰੇਣੀ, ਜਨਸ, ਪ੍ਰਜਾਤੀ, ਪਰਿਵਾਰ ਅਤੇ ਸੰਰਕਸ਼ਣ ਸਥਿਤੀ ਬਾਰੇ ਵੀ ਚੰਗੀ ਜਾਣਕਾਰੀ ਸ਼ਾਮਲ ਹੈ। ਆਓ ਇਸ ਸੰਰਕਸ਼ਣ ਜਾਣਕਾਰੀ ਦੀ ਖੋਜ ਕਰੀਏ। ਪੰਛੀਆਂ ਦੀ ਸੰਰਕਸ਼ਣ ਸਥਿਤੀ ਦੇ ਅਨੁਸਾਰ ਵੰਡ ਕੀ ਹੈ?
✅ ਡਾਟਾਸੈਟ ਵਿੱਚ, ਸੰਰਕਸ਼ਣ ਸਥਿਤੀ ਨੂੰ ਵੇਰਵਾ ਦੇਣ ਲਈ ਕਈ ਸੰਖੇਪ ਰੂਪ ਵਰਤੇ ਗਏ ਹਨ। ਇਹ ਸੰਖੇਪ ਰੂਪ IUCN ਰੈੱਡ ਲਿਸਟ ਸ਼੍ਰੇਣੀਆਂ ਤੋਂ ਆਉਂਦੇ ਹਨ, ਜੋ ਪ੍ਰਜਾਤੀਆਂ ਦੀ ਸਥਿਤੀ ਨੂੰ ਦਰਜ ਕਰਨ ਵਾਲਾ ਇੱਕ ਸੰਗਠਨ ਹੈ।
- CR: ਗੰਭੀਰ ਖਤਰੇ ਵਿੱਚ
- EN: ਖਤਰੇ ਵਿੱਚ
- EX: ਲੁਪਤ
- LC: ਘੱਟ ਚਿੰਤਾ
- NT: ਖਤਰੇ ਦੇ ਨੇੜੇ
- VU: ਅਸੁਰੱਖਿਅਤ
ਇਹ ਟੈਕਸਟ-ਅਧਾਰਿਤ ਮੁੱਲ ਹਨ, ਇਸ ਲਈ ਤੁਹਾਨੂੰ ਹਿਸਟੋਗ੍ਰਾਮ ਬਣਾਉਣ ਲਈ ਇੱਕ ਰੂਪਾਂਤਰ ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇਗੀ। ਫਿਲਟਰ ਕੀਤੇ ਗਏ ਪੰਛੀਆਂ ਦੇ ਡਾਟਾਫਰੇਮ ਦੀ ਵਰਤੋਂ ਕਰਕੇ, ਇਸ ਦੀ ਸੰਰਕਸ਼ਣ ਸਥਿਤੀ ਨੂੰ ਘੱਟੋ-ਘੱਟ ਪੰਖਾਂ ਦੇ ਫੈਲਾਅ ਦੇ ਨਾਲ ਦਿਖਾਓ। ਤੁਹਾਨੂੰ ਕੀ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ?
birds_filtered_1$ConservationStatus[birds_filtered_1$ConservationStatus == 'EX'] <- 'x1'
birds_filtered_1$ConservationStatus[birds_filtered_1$ConservationStatus == 'CR'] <- 'x2'
birds_filtered_1$ConservationStatus[birds_filtered_1$ConservationStatus == 'EN'] <- 'x3'
birds_filtered_1$ConservationStatus[birds_filtered_1$ConservationStatus == 'NT'] <- 'x4'
birds_filtered_1$ConservationStatus[birds_filtered_1$ConservationStatus == 'VU'] <- 'x5'
birds_filtered_1$ConservationStatus[birds_filtered_1$ConservationStatus == 'LC'] <- 'x6'
ggplot(data=birds_filtered_1, aes(x = MinWingspan, fill = ConservationStatus)) +
geom_histogram(position = "identity", alpha = 0.4, bins = 20) +
scale_fill_manual(name="Conservation Status",values=c("red","green","blue","pink"),labels=c("Endangered","Near Threathened","Vulnerable","Least Concern"))
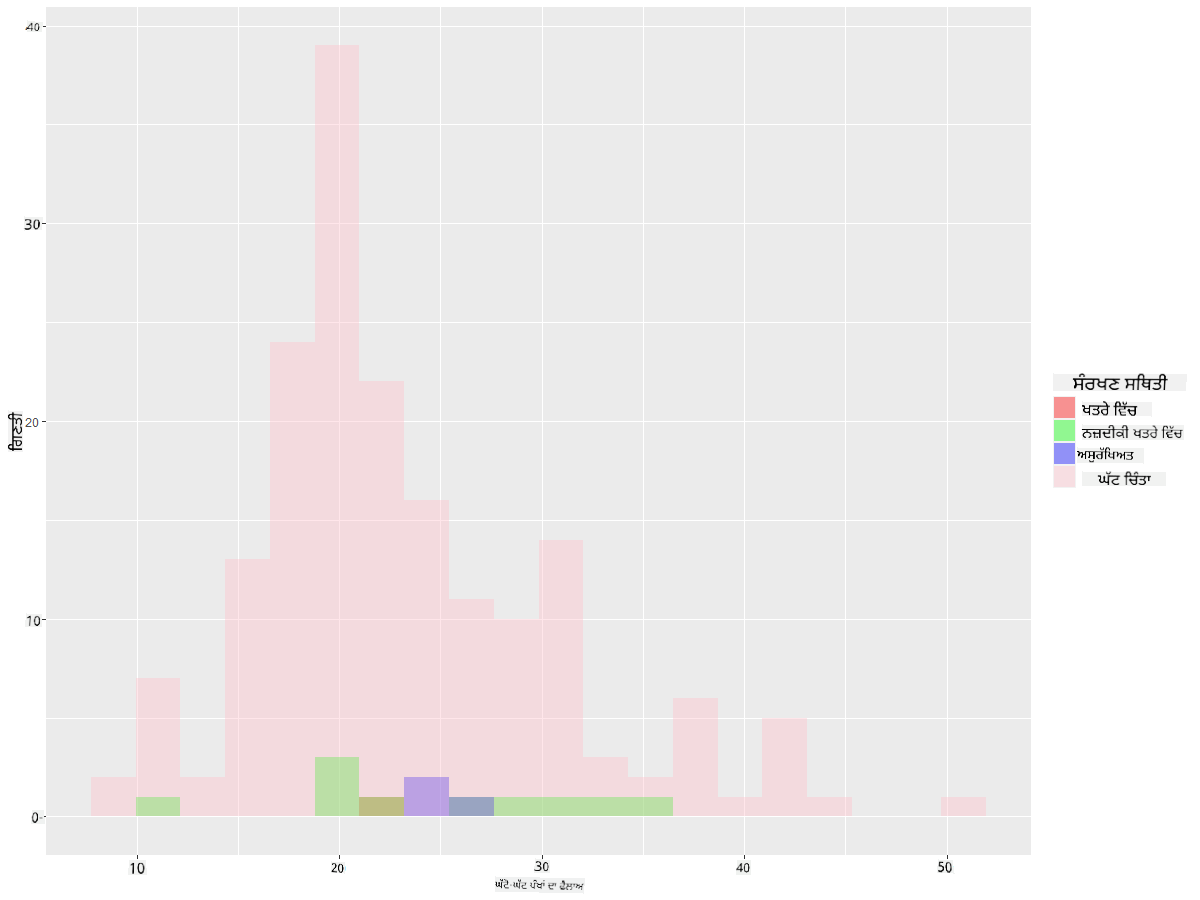
ਘੱਟੋ-ਘੱਟ ਪੰਖਾਂ ਦੇ ਫੈਲਾਅ ਅਤੇ ਸੰਰਕਸ਼ਣ ਸਥਿਤੀ ਦੇ ਵਿਚਕਾਰ ਕੋਈ ਵਧੀਆ ਸੰਬੰਧ ਨਹੀਂ ਦਿਖਾਈ ਦਿੰਦਾ। ਇਸ ਤਰੀਕੇ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਡਾਟਾਸੈਟ ਦੇ ਹੋਰ ਤੱਤਾਂ ਦੀ ਜਾਂਚ ਕਰੋ। ਤੁਸੀਂ ਵੱਖ-ਵੱਖ ਫਿਲਟਰਾਂ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਸਕਦੇ ਹੋ। ਕੀ ਤੁਹਾਨੂੰ ਕੋਈ ਸੰਬੰਧ ਮਿਲਦਾ ਹੈ?
ਡੈਂਸਿਟੀ ਪਲਾਟਸ
ਤੁਸੀਂ ਸ਼ਾਇਦ ਨੋਟ ਕੀਤਾ ਹੋਵੇਗਾ ਕਿ ਅਸੀਂ ਹੁਣ ਤੱਕ ਦੇਖੇ ਹਿਸਟੋਗ੍ਰਾਮ 'ਸਟੈਪਡ' ਹਨ ਅਤੇ ਇੱਕ ਆਰਕ ਵਿੱਚ ਸਮੂਥ ਨਹੀਂ ਹਨ। ਇੱਕ ਸਮੂਥਰ ਡੈਂਸਿਟੀ ਚਾਰਟ ਦਿਖਾਉਣ ਲਈ, ਤੁਸੀਂ ਡੈਂਸਿਟੀ ਪਲਾਟ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਸਕਦੇ ਹੋ।
ਆਓ ਹੁਣ ਡੈਂਸਿਟੀ ਪਲਾਟਸ ਨਾਲ ਕੰਮ ਕਰੀਏ!
ggplot(data = birds_filtered_1, aes(x = MinWingspan)) +
geom_density()
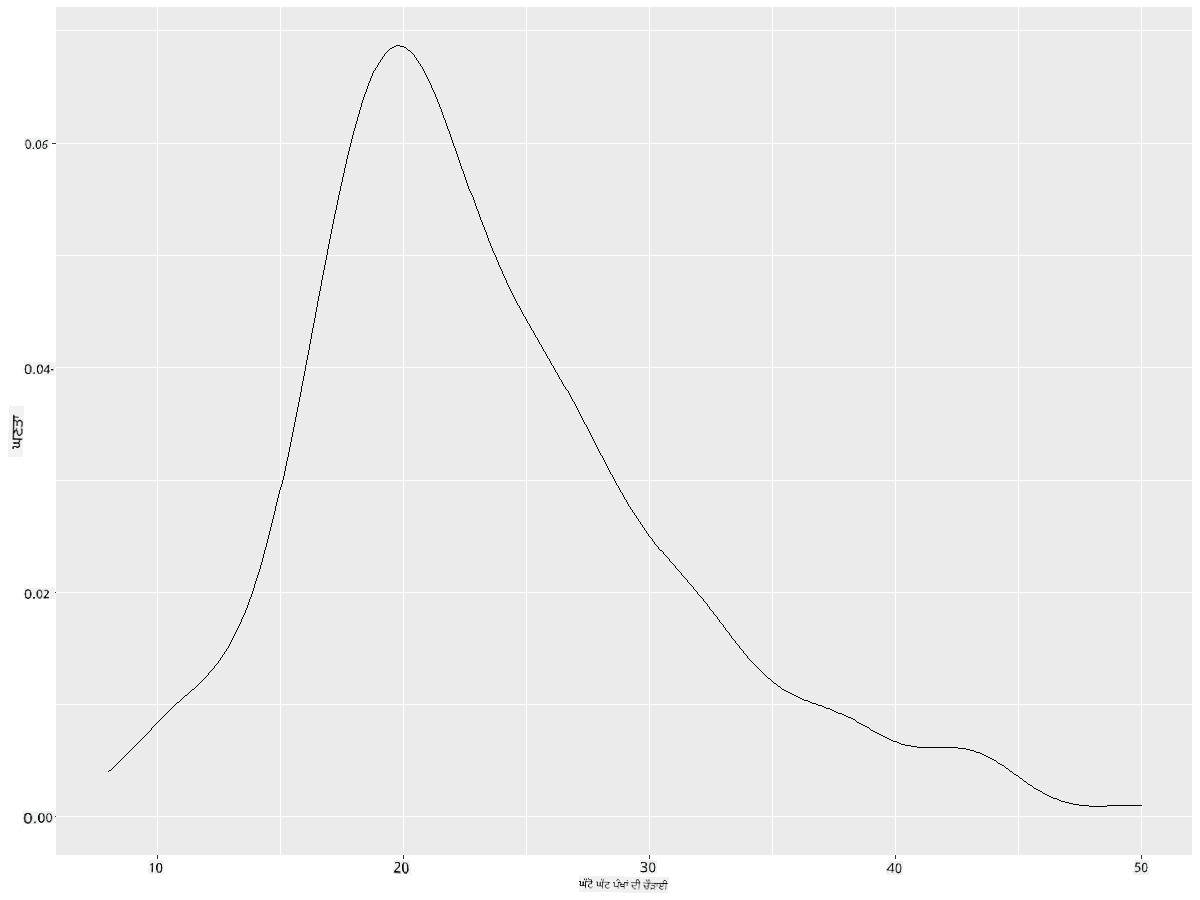
ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਇਹ ਪਲਾਟ ਘੱਟੋ-ਘੱਟ ਪੰਖਾਂ ਦੇ ਫੈਲਾਅ ਲਈ ਪਿਛਲੇ ਚਾਰਟ ਨੂੰ ਦੁਹਰਾਉਂਦਾ ਹੈ; ਇਹ ਸਿਰਫ਼ ਕੁਝ ਸਮੂਥ ਹੈ। ਜੇ ਤੁਸੀਂ ਉਸ ਜੱਗਡ ਵੱਧ ਤੋਂ ਵੱਧ ਸਰੀਰਕ ਭਾਰ ਦੀ ਲਾਈਨ ਨੂੰ ਦੁਬਾਰਾ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਦੂਜੇ ਚਾਰਟ ਵਿੱਚ ਬਣਾਈ ਸੀ, ਤਾਂ ਤੁਸੀਂ ਇਸ ਤਰੀਕੇ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇਸਨੂੰ ਬਹੁਤ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸਮੂਥ ਕਰ ਸਕਦੇ ਹੋ:
ggplot(data = birds_filtered_1, aes(x = MaxBodyMass)) +
geom_density()
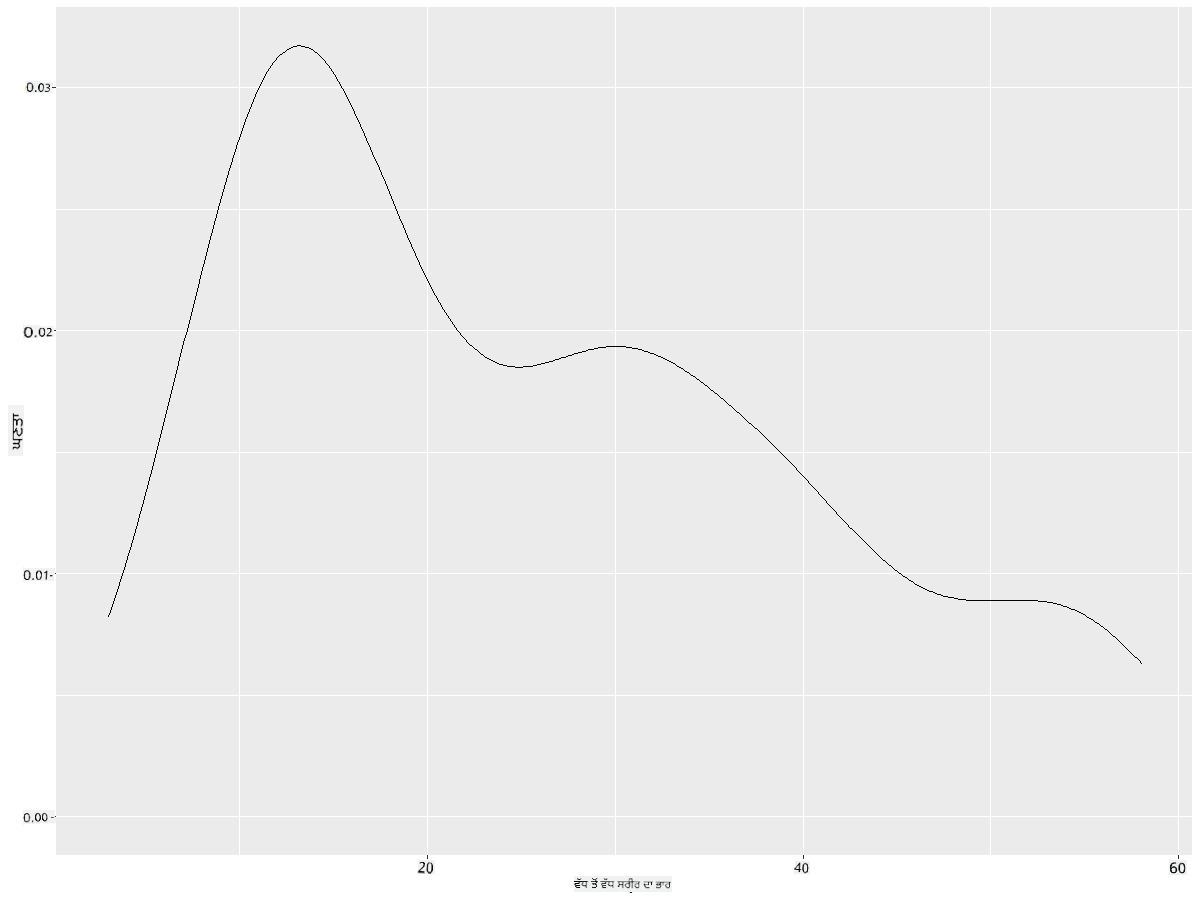
ਜੇ ਤੁਸੀਂ ਇੱਕ ਸਮੂਥ, ਪਰ ਬਹੁਤ ਜ਼ਿਆਦਾ ਸਮੂਥ ਲਾਈਨ ਨਹੀਂ ਚਾਹੁੰਦੇ, ਤਾਂ adjust ਪੈਰਾਮੀਟਰ ਨੂੰ ਸੋਧੋ:
ggplot(data = birds_filtered_1, aes(x = MaxBodyMass)) +
geom_density(adjust = 1/5)
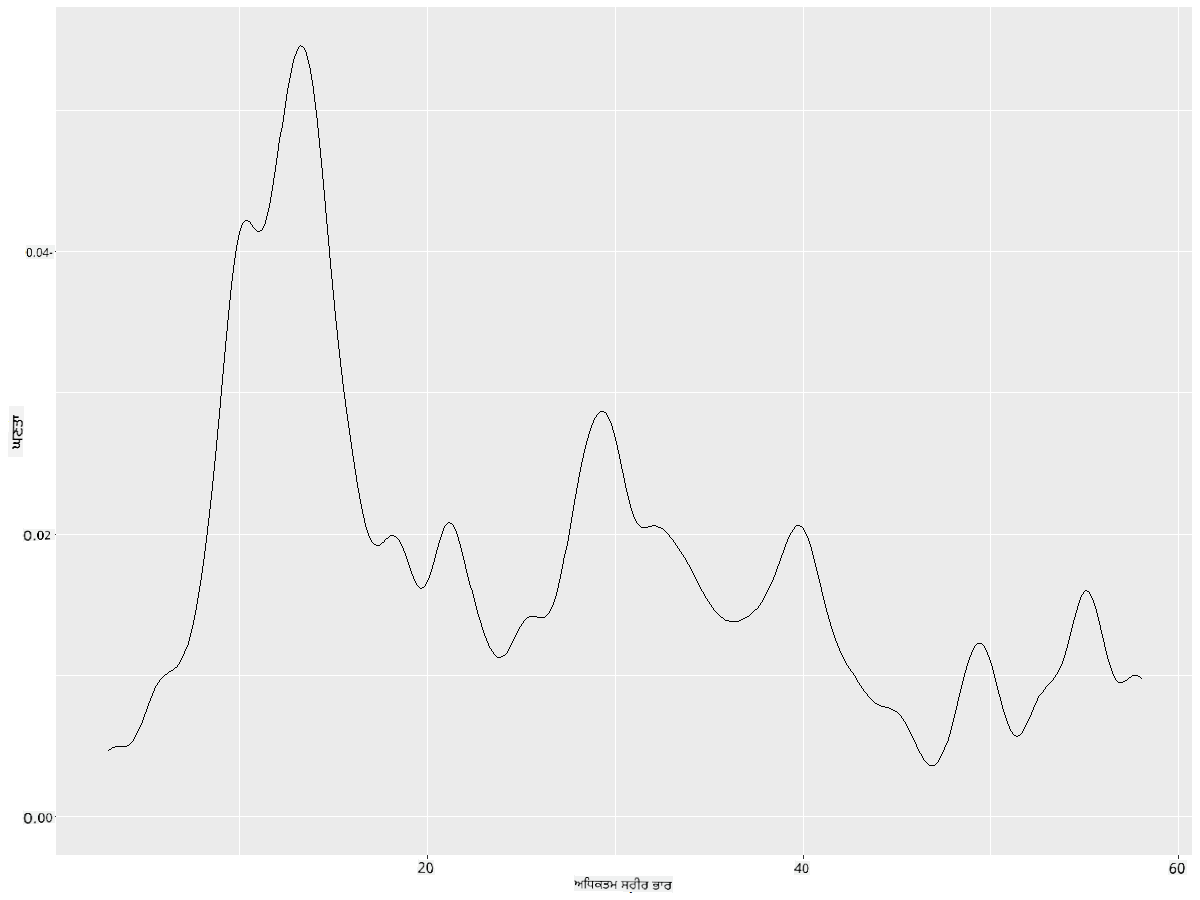
✅ ਇਸ ਪ੍ਰਕਾਰ ਦੇ ਪਲਾਟ ਲਈ ਉਪਲਬਧ ਪੈਰਾਮੀਟਰਾਂ ਬਾਰੇ ਪੜ੍ਹੋ ਅਤੇ ਪ੍ਰਯੋਗ ਕਰੋ!
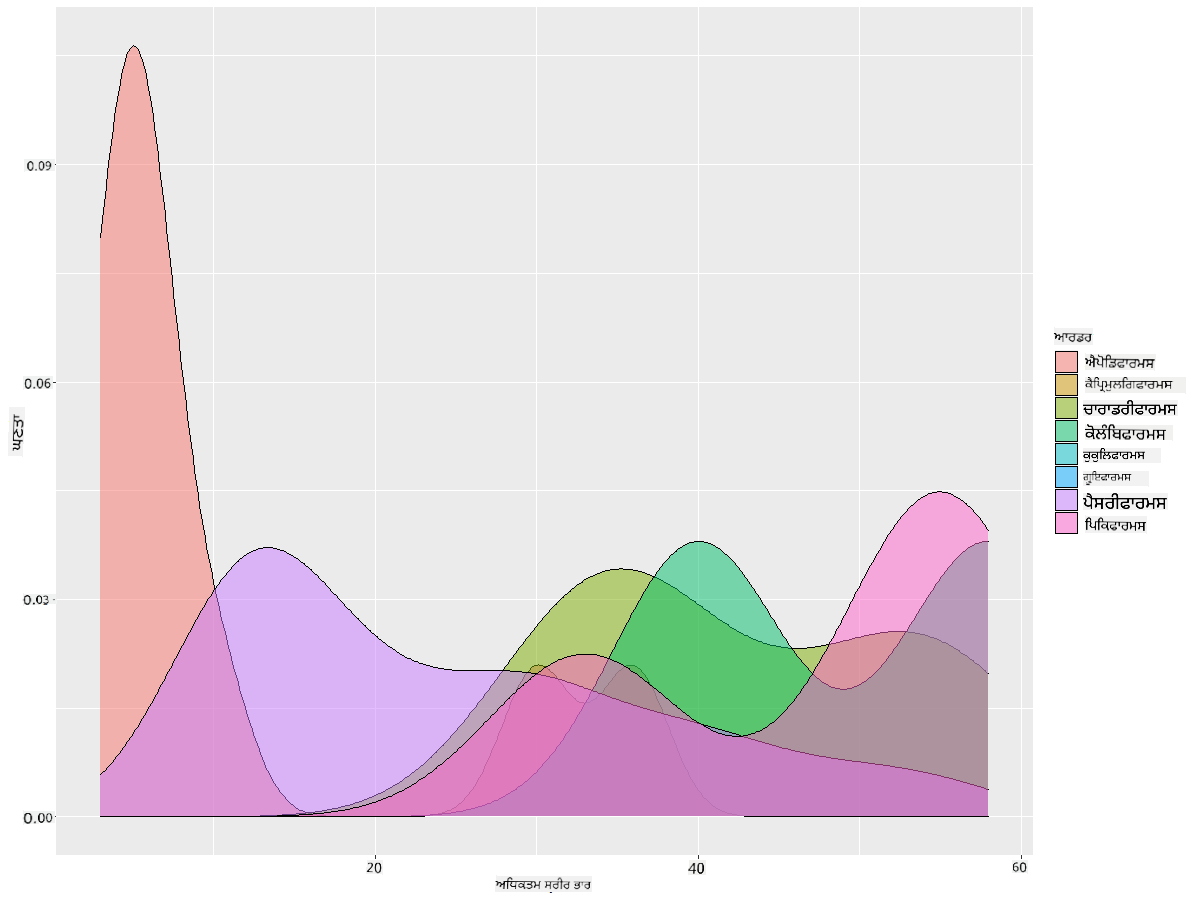
ਇਸ ਪ੍ਰਕਾਰ ਦਾ ਚਾਰਟ ਸੁੰਦਰ ਅਤੇ ਵਿਆਖਿਆਤਮਕ ਵਿਜੁਅਲਾਈਜ਼ੇਸ਼ਨ ਪੇਸ਼ ਕਰਦਾ ਹੈ। ਉਦਾਹਰਣ ਲਈ, ਕੁਝ ਲਾਈਨਾਂ ਦੇ ਕੋਡ ਨਾਲ, ਤੁਸੀਂ ਪੰਛੀ ਦੇ ਕ੍ਰਮ ਪ੍ਰਤੀ ਵੱਧ ਤੋਂ ਵੱਧ ਸਰੀਰਕ ਭਾਰ ਦੀ ਡੈਂਸਿਟੀ ਦਿਖਾ ਸਕਦੇ ਹੋ:
ggplot(data=birds_filtered_1,aes(x = MaxBodyMass, fill = Order)) +
geom_density(alpha=0.5)
🚀 ਚੁਣੌਤੀ
ਹਿਸਟੋਗ੍ਰਾਮ ਬੁਨਿਆਦੀ ਸਕੈਟਰਪਲਾਟਸ, ਬਾਰ ਚਾਰਟਸ ਜਾਂ ਲਾਈਨ ਚਾਰਟਸ ਨਾਲੋਂ ਇੱਕ ਹੋਰ ਸੁਧਾਰਿਤ ਚਾਰਟ ਕਿਸਮ ਹਨ। ਇੰਟਰਨੈਟ 'ਤੇ ਜਾਓ ਅਤੇ ਹਿਸਟੋਗ੍ਰਾਮ ਦੀ ਵਰਤੋਂ ਦੇ ਚੰਗੇ ਉਦਾਹਰਣ ਲੱਭੋ। ਇਹ ਕਿਵੇਂ ਵਰਤੇ ਜਾਂਦੇ ਹਨ, ਇਹ ਕੀ ਦਿਖਾਉਂਦੇ ਹਨ, ਅਤੇ ਇਹ ਕਿਹੜੇ ਖੇਤਰਾਂ ਜਾਂ ਅਧਿਐਨ ਦੇ ਖੇਤਰਾਂ ਵਿੱਚ ਵਰਤੇ ਜਾਂਦੇ ਹਨ?
ਪਾਠ-ਬਾਅਦ ਕਵਿਜ਼
ਸਮੀਖਿਆ ਅਤੇ ਸਵੈ ਅਧਿਐਨ
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ggplot2 ਦੀ ਵਰਤੋਂ ਕੀਤੀ ਅਤੇ ਹੋਰ ਸੁਧਾਰਿਤ ਚਾਰਟਸ ਦਿਖਾਉਣ ਲਈ ਕੰਮ ਸ਼ੁਰੂ ਕੀਤਾ। geom_density_2d() ਬਾਰੇ ਕੁਝ ਖੋਜ ਕਰੋ, ਜੋ "ਇੱਕ ਜਾਂ ਵੱਧ ਆਯਾਮਾਂ ਵਿੱਚ ਲਗਾਤਾਰ ਸੰਭਾਵਨਾ ਡੈਂਸਿਟੀ ਵਕਰ" ਹੈ। ਡਾਕੂਮੈਂਟੇਸ਼ਨ ਨੂੰ ਪੜ੍ਹੋ ਤਾਂ ਜੋ ਇਹ ਸਮਝਿਆ ਜਾ ਸਕੇ ਕਿ ਇਹ ਕਿਵੇਂ ਕੰਮ ਕਰਦਾ ਹੈ।
ਅਸਾਈਨਮੈਂਟ
ਅਸਵੀਕਰਤੀ:
ਇਹ ਦਸਤਾਵੇਜ਼ AI ਅਨੁਵਾਦ ਸੇਵਾ Co-op Translator ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਅਨੁਵਾਦ ਕੀਤਾ ਗਿਆ ਹੈ। ਜਦੋਂ ਕਿ ਅਸੀਂ ਸਹੀ ਹੋਣ ਦਾ ਯਤਨ ਕਰਦੇ ਹਾਂ, ਕਿਰਪਾ ਕਰਕੇ ਧਿਆਨ ਦਿਓ ਕਿ ਸਵੈਚਾਲਿਤ ਅਨੁਵਾਦਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਜਾਂ ਅਸੁਣਭਵਤਾਵਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਇਸ ਦੀ ਮੂਲ ਭਾਸ਼ਾ ਵਿੱਚ ਮੌਜੂਦ ਮੂਲ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਪ੍ਰਮਾਣਿਕ ਸਰੋਤ ਮੰਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਮਹੱਤਵਪੂਰਨ ਜਾਣਕਾਰੀ ਲਈ, ਪੇਸ਼ੇਵਰ ਮਨੁੱਖੀ ਅਨੁਵਾਦ ਦੀ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਇਸ ਅਨੁਵਾਦ ਦੇ ਪ੍ਰਯੋਗ ਤੋਂ ਪੈਦਾ ਹੋਣ ਵਾਲੇ ਕਿਸੇ ਵੀ ਗਲਤਫਹਮੀਆਂ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆਵਾਂ ਲਈ ਅਸੀਂ ਜ਼ਿੰਮੇਵਾਰ ਨਹੀਂ ਹਾਂ।