12 KiB
Visualisering av proporsjoner
 |
|---|
| Visualisering av proporsjoner - Sketchnote av @nitya |
I denne leksjonen skal du bruke et annet naturfokusert datasett for å visualisere proporsjoner, som for eksempel hvor mange forskjellige typer sopp som finnes i et gitt datasett om sopper. La oss utforske disse fascinerende soppene ved hjelp av et datasett hentet fra Audubon, som inneholder detaljer om 23 arter av skivesopper i Agaricus- og Lepiota-familiene. Du vil eksperimentere med smakfulle visualiseringer som:
- Kakediagrammer 🥧
- Smultringdiagrammer 🍩
- Vaffeldiagrammer 🧇
💡 Et veldig interessant prosjekt kalt Charticulator fra Microsoft Research tilbyr et gratis dra-og-slipp-grensesnitt for datavisualiseringer. I en av deres opplæringer bruker de også dette soppdatasettet! Så du kan utforske dataene og lære biblioteket samtidig: Charticulator-opplæring.
Quiz før leksjonen
Bli kjent med soppene dine 🍄
Sopper er veldig interessante. La oss importere et datasett for å studere dem:
import pandas as pd
import matplotlib.pyplot as plt
mushrooms = pd.read_csv('../../data/mushrooms.csv')
mushrooms.head()
En tabell skrives ut med noen flotte data for analyse:
| class | cap-shape | cap-surface | cap-color | bruises | odor | gill-attachment | gill-spacing | gill-size | gill-color | stalk-shape | stalk-root | stalk-surface-above-ring | stalk-surface-below-ring | stalk-color-above-ring | stalk-color-below-ring | veil-type | veil-color | ring-number | ring-type | spore-print-color | population | habitat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Giftig | Konveks | Glatt | Brun | Blåmerker | Stikkende | Fri | Tett | Smal | Svart | Forstørret | Lik | Glatt | Glatt | Hvit | Hvit | Delvis | Hvit | En | Hengende | Svart | Spredd | Urban |
| Spiselig | Konveks | Glatt | Gul | Blåmerker | Mandel | Fri | Tett | Bred | Svart | Forstørret | Klubb | Glatt | Glatt | Hvit | Hvit | Delvis | Hvit | En | Hengende | Brun | Tallrik | Gress |
| Spiselig | Klokke | Glatt | Hvit | Blåmerker | Anis | Fri | Tett | Bred | Brun | Forstørret | Klubb | Glatt | Glatt | Hvit | Hvit | Delvis | Hvit | En | Hengende | Brun | Tallrik | Enger |
| Giftig | Konveks | Skjellete | Hvit | Blåmerker | Stikkende | Fri | Tett | Smal | Brun | Forstørret | Lik | Glatt | Glatt | Hvit | Hvit | Delvis | Hvit | En | Hengende | Svart | Spredd | Urban |
Med en gang legger du merke til at alle dataene er tekstbaserte. Du må konvertere disse dataene for å kunne bruke dem i et diagram. De fleste dataene er faktisk representert som et objekt:
print(mushrooms.select_dtypes(["object"]).columns)
Resultatet er:
Index(['class', 'cap-shape', 'cap-surface', 'cap-color', 'bruises', 'odor',
'gill-attachment', 'gill-spacing', 'gill-size', 'gill-color',
'stalk-shape', 'stalk-root', 'stalk-surface-above-ring',
'stalk-surface-below-ring', 'stalk-color-above-ring',
'stalk-color-below-ring', 'veil-type', 'veil-color', 'ring-number',
'ring-type', 'spore-print-color', 'population', 'habitat'],
dtype='object')
Ta disse dataene og konverter 'class'-kolonnen til en kategori:
cols = mushrooms.select_dtypes(["object"]).columns
mushrooms[cols] = mushrooms[cols].astype('category')
edibleclass=mushrooms.groupby(['class']).count()
edibleclass
Nå, hvis du skriver ut soppdataene, kan du se at de har blitt gruppert i kategorier basert på giftig/spiselig-klassene:
| cap-shape | cap-surface | cap-color | bruises | odor | gill-attachment | gill-spacing | gill-size | gill-color | stalk-shape | ... | stalk-surface-below-ring | stalk-color-above-ring | stalk-color-below-ring | veil-type | veil-color | ring-number | ring-type | spore-print-color | population | habitat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| class | |||||||||||||||||||||
| Spiselig | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | ... | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 | 4208 |
| Giftig | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | ... | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 | 3916 |
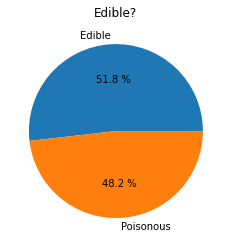
Hvis du følger rekkefølgen presentert i denne tabellen for å lage etikettene for klassene, kan du lage et kakediagram:
Kake!
labels=['Edible','Poisonous']
plt.pie(edibleclass['population'],labels=labels,autopct='%.1f %%')
plt.title('Edible?')
plt.show()
Voila, et kakediagram som viser proporsjonene av disse dataene i henhold til de to klassene av sopper. Det er ganske viktig å få rekkefølgen på etikettene riktig, spesielt her, så sørg for å verifisere rekkefølgen når du bygger etikettarrayet!
Smultringer!
Et litt mer visuelt interessant kakediagram er et smultringdiagram, som er et kakediagram med et hull i midten. La oss se på dataene våre ved hjelp av denne metoden.
Se på de ulike habitatene hvor sopper vokser:
habitat=mushrooms.groupby(['habitat']).count()
habitat
Her grupperer du dataene dine etter habitat. Det er 7 oppførte, så bruk disse som etiketter for smultringdiagrammet ditt:
labels=['Grasses','Leaves','Meadows','Paths','Urban','Waste','Wood']
plt.pie(habitat['class'], labels=labels,
autopct='%1.1f%%', pctdistance=0.85)
center_circle = plt.Circle((0, 0), 0.40, fc='white')
fig = plt.gcf()
fig.gca().add_artist(center_circle)
plt.title('Mushroom Habitats')
plt.show()
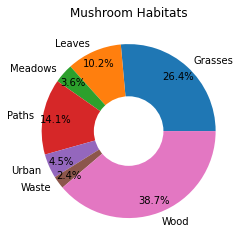
Denne koden tegner et diagram og en sirkel i midten, og legger deretter til den sirkelen i diagrammet. Endre bredden på sirkelen i midten ved å justere 0.40 til en annen verdi.
Smultringdiagrammer kan tilpasses på flere måter for å endre etikettene. Etikettene kan spesielt fremheves for bedre lesbarhet. Lær mer i dokumentasjonen.
Nå som du vet hvordan du grupperer dataene dine og deretter viser dem som kake eller smultring, kan du utforske andre typer diagrammer. Prøv et vaffeldiagram, som bare er en annen måte å utforske mengder på.
Vafler!
Et 'vaffel'-type diagram er en annen måte å visualisere mengder som et 2D-array av firkanter. Prøv å visualisere de forskjellige mengdene av soppens hattfarger i dette datasettet. For å gjøre dette må du installere et hjelpebibliotek kalt PyWaffle og bruke Matplotlib:
pip install pywaffle
Velg et segment av dataene dine for å gruppere:
capcolor=mushrooms.groupby(['cap-color']).count()
capcolor
Lag et vaffeldiagram ved å lage etiketter og deretter gruppere dataene dine:
import pandas as pd
import matplotlib.pyplot as plt
from pywaffle import Waffle
data ={'color': ['brown', 'buff', 'cinnamon', 'green', 'pink', 'purple', 'red', 'white', 'yellow'],
'amount': capcolor['class']
}
df = pd.DataFrame(data)
fig = plt.figure(
FigureClass = Waffle,
rows = 100,
values = df.amount,
labels = list(df.color),
figsize = (30,30),
colors=["brown", "tan", "maroon", "green", "pink", "purple", "red", "whitesmoke", "yellow"],
)
Ved hjelp av et vaffeldiagram kan du tydelig se proporsjonene av hattfarger i dette soppdatasettet. Interessant nok er det mange grønne sopphatter!

✅ PyWaffle støtter ikoner i diagrammene som bruker alle ikoner tilgjengelige i Font Awesome. Gjør noen eksperimenter for å lage et enda mer interessant vaffeldiagram ved å bruke ikoner i stedet for firkanter.
I denne leksjonen lærte du tre måter å visualisere proporsjoner på. Først må du gruppere dataene dine i kategorier og deretter bestemme hvilken som er den beste måten å vise dataene på - kake, smultring eller vaffel. Alle er deilige og gir brukeren et øyeblikksbilde av et datasett.
🚀 Utfordring
Prøv å gjenskape disse smakfulle diagrammene i Charticulator.
Quiz etter leksjonen
Gjennomgang og selvstudium
Noen ganger er det ikke åpenbart når man skal bruke et kake-, smultring- eller vaffeldiagram. Her er noen artikler du kan lese om dette emnet:
https://www.beautiful.ai/blog/battle-of-the-charts-pie-chart-vs-donut-chart
https://medium.com/@hypsypops/pie-chart-vs-donut-chart-showdown-in-the-ring-5d24fd86a9ce
https://www.mit.edu/~mbarker/formula1/f1help/11-ch-c6.htm
Gjør litt research for å finne mer informasjon om denne vanskelige avgjørelsen.
Oppgave
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi tilstreber nøyaktighet, vennligst vær oppmerksom på at automatiske oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for eventuelle misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.