|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| R | 2 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook-covidspread.ipynb | 2 weeks ago | |
| notebook-papers.ipynb | 2 weeks ago | |
| notebook.ipynb | 2 weeks ago | |
README.md
使用數據:Python 和 Pandas 庫
 |
|---|
| 使用 Python - 由 @nitya 繪製的速記筆記 |
雖然資料庫提供了非常高效的方式來存儲數據並使用查詢語言進行查詢,但最靈活的數據處理方式是編寫自己的程式來操作數據。在許多情況下,使用資料庫查詢可能更有效。然而,當需要更複雜的數據處理時,使用 SQL 可能不容易完成。
數據處理可以用任何程式語言編寫,但有些語言在處理數據方面更高效。數據科學家通常偏好以下語言之一:
- Python 是一種通用程式語言,因其簡單性常被認為是初學者的最佳選擇。Python 擁有許多額外的庫,可以幫助解決許多實際問題,例如從 ZIP 壓縮檔案中提取數據或將圖片轉換為灰度。除了數據科學,Python 也常用於網頁開發。
- R 是一個傳統工具箱,專為統計數據處理而設計。它擁有大量的庫(CRAN),使其成為數據處理的良好選擇。然而,R 不是通用程式語言,通常僅限於數據科學領域使用。
- Julia 是另一種專為數據科學設計的語言。它旨在提供比 Python 更好的性能,是科學實驗的理想工具。
在本課程中,我們將重點使用 Python 進行簡單的數據處理。我們假設您已對該語言有基本的熟悉。如果您想深入了解 Python,可以參考以下資源:
- 使用 Turtle Graphics 和 Fractals 以有趣的方式學習 Python - 基於 GitHub 的 Python 程式快速入門課程
- 從 Python 開始您的第一步 Microsoft Learn 上的學習路徑
數據可以有多種形式。在本課程中,我們將考慮三種數據形式——表格數據、文本和圖片。
我們將專注於一些數據處理的例子,而不是全面介紹所有相關庫。這樣可以讓您了解主要概念,並在需要時知道如何找到解決問題的方法。
最有用的建議:當您需要對數據執行某些操作但不知道如何進行時,嘗試在網路上搜索。Stackoverflow 通常包含許多針對常見任務的 Python 代碼範例。
課前測驗
表格數據和 DataFrame
當我們討論關聯式資料庫時,您已經接觸過表格數據。當您擁有大量數據並且它包含在許多不同的連結表中時,使用 SQL 來處理它是非常合理的。然而,在許多情況下,我們有一個數據表,並需要對該數據進行一些理解或洞察,例如分佈、值之間的相關性等。在數據科學中,經常需要對原始數據進行一些轉換,然後進行可視化。這兩個步驟都可以輕鬆地使用 Python 完成。
在 Python 中,有兩個最有用的庫可以幫助您處理表格數據:
- Pandas 允許您操作所謂的 DataFrame,它類似於關聯式表格。您可以擁有命名的列,並對行、列以及整個 DataFrame 執行不同的操作。
- Numpy 是一個用於處理 張量(即多維陣列)的庫。陣列具有相同的基礎類型值,比 DataFrame 更簡單,但提供了更多的數學操作,並且開銷更少。
此外,還有幾個您應該了解的庫:
- Matplotlib 是一個用於數據可視化和繪製圖表的庫
- SciPy 是一個包含一些額外科學函數的庫。我們在討論概率和統計時已經接觸過該庫
以下是您通常在 Python 程式開頭用來導入這些庫的代碼:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas 圍繞幾個基本概念構建。
Series
Series 是一系列值,類似於列表或 numpy 陣列。主要區別在於 Series 還具有索引,當我們對 Series 進行操作(例如相加)時,索引會被考慮。索引可以像整數行號一樣簡單(當從列表或陣列創建 Series 時,默認使用此索引),也可以具有複雜結構,例如日期間隔。
注意:在附帶的筆記本
notebook.ipynb中有一些 Pandas 的入門代碼。我們僅在此概述一些例子,您可以查看完整的筆記本。
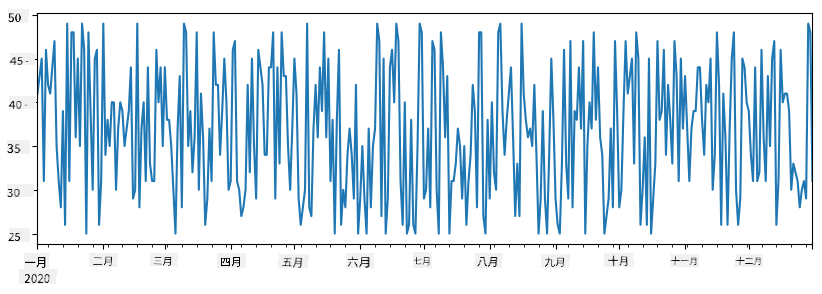
舉個例子:我們想分析我們冰淇淋店的銷售情況。讓我們生成一段時間內的銷售數字(每天售出的商品數量)Series:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
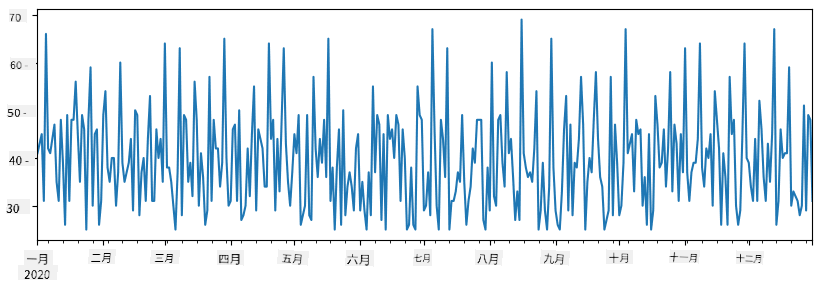
假設每週我們都會為朋友舉辦派對,並額外準備 10 盒冰淇淋。我們可以創建另一個以週為索引的 Series 來展示這一點:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
當我們將兩個 Series 相加時,我們得到總數:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
注意:我們沒有使用簡單的語法
total_items+additional_items。如果使用該語法,我們會在結果 Series 中得到許多NaN(非數值)值。這是因為在additional_itemsSeries 的某些索引點缺少值,並且將NaN與任何值相加都會得到NaN。因此,我們需要在相加時指定fill_value參數。
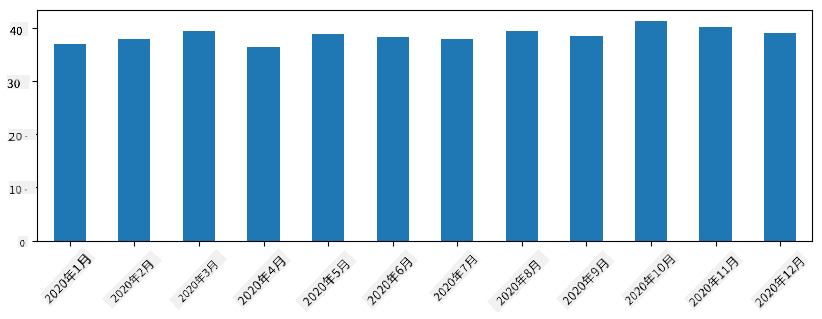
使用時間序列,我們還可以使用不同的時間間隔對 Series 進行重採樣。例如,假設我們想計算每月的平均銷售量。我們可以使用以下代碼:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame 本質上是具有相同索引的 Series 集合。我們可以將幾個 Series 組合成一個 DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
這將創建如下的水平表格:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
我們還可以使用 Series 作為列,並通過字典指定列名:
df = pd.DataFrame({ 'A' : a, 'B' : b })
這將生成如下表格:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
注意:我們也可以通過轉置前面的表格來獲得此表格佈局,例如,通過編寫
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
這裡 .T 表示轉置 DataFrame 的操作,即更改行和列,而 rename 操作允許我們重命名列以匹配前面的例子。
以下是我們可以對 DataFrame 執行的一些最重要的操作:
列選擇。我們可以通過編寫 df['A'] 選擇單個列——此操作返回一個 Series。我們還可以通過編寫 df[['B','A']] 選擇列的子集到另一個 DataFrame——此操作返回另一個 DataFrame。
篩選符合條件的行。例如,要僅保留列 A 大於 5 的行,我們可以編寫 df[df['A']>5]。
注意:篩選的工作方式如下。表達式
df['A']<5返回一個布林 Series,指示原始 Seriesdf['A']的每個元素是否為True或False。當布林 Series 用作索引時,它返回 DataFrame 中的行子集。因此,不能使用任意的 Python 布林表達式,例如,編寫df[df['A']>5 and df['A']<7]是錯誤的。相反,您應該使用布林 Series 的特殊&操作,編寫df[(df['A']>5) & (df['A']<7)](括號在這裡很重要)。
創建新的可計算列。我們可以通過使用直觀的表達式輕鬆為 DataFrame 創建新的可計算列:
df['DivA'] = df['A']-df['A'].mean()
此例子計算 A 與其平均值的偏差。實際上,我們正在計算一個 Series,然後將此 Series 分配給左側,創建另一列。因此,我們不能使用與 Series 不兼容的任何操作,例如,以下代碼是錯誤的:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
後一個例子雖然語法正確,但給出了錯誤的結果,因為它將 Series B 的長度分配給列中的所有值,而不是分配給每個元素的長度。
如果需要計算此類複雜表達式,我們可以使用 apply 函數。最後一個例子可以寫成如下:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
執行上述操作後,我們將得到以下 DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
基於數字選擇行可以使用 iloc 結構。例如,要選擇 DataFrame 的前 5 行:
df.iloc[:5]
分組通常用於獲得類似於 Excel 中樞紐分析表的結果。假設我們想計算列 A 的平均值,按 LenB 的每個數字分組。然後我們可以按 LenB 分組 DataFrame,並調用 mean:
df.groupby(by='LenB')[['A','DivA']].mean()
如果我們需要計算平均值和組中的元素數量,那麼我們可以使用更複雜的 aggregate 函數:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
這將生成以下表格:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
獲取數據
我們已經看到如何輕鬆地從 Python 對象構建 Series 和 DataFrame。然而,數據通常以文本文件或 Excel 表格的形式存在。幸運的是,Pandas 提供了一種簡單的方法來從磁碟中載入數據。例如,讀取 CSV 文件就像這樣簡單:
df = pd.read_csv('file.csv')
我們將在“挑戰”部分中看到更多載入數據的例子,包括從外部網站獲取數據。
打印與繪圖
數據科學家經常需要探索數據,因此能夠可視化數據非常重要。當 DataFrame 很大時,我們通常只需要打印出前幾行來確保我們的操作是正確的。這可以通過調用 df.head() 完成。如果你在 Jupyter Notebook 中運行,它會以漂亮的表格形式打印出 DataFrame。
我們也已經看到使用 plot 函數來可視化某些列。雖然 plot 對許多任務非常有用,並且通過 kind= 參數支持多種不同的圖表類型,但你也可以使用原始的 matplotlib 庫來繪製更複雜的圖表。我們將在單獨的課程中詳細介紹數據可視化。
這個概述涵蓋了 Pandas 的最重要概念,但這個庫非常豐富,幾乎沒有你不能用它完成的事情!現在讓我們應用這些知識來解決具體問題。
🚀 挑戰 1:分析 COVID 傳播
我們將專注於的第一個問題是 COVID-19 的流行病傳播建模。為了做到這一點,我們將使用由 約翰霍普金斯大學 系統科學與工程中心 (CSSE) 提供的不同國家感染人數數據。數據集可在 這個 GitHub 存儲庫 中找到。
由於我們想展示如何處理數據,我們邀請你打開 notebook-covidspread.ipynb 並從頭到尾閱讀。你也可以執行單元格,並完成我們在最後留下的一些挑戰。
如果你不知道如何在 Jupyter Notebook 中運行代碼,可以查看 這篇文章。
處理非結構化數據
雖然數據通常以表格形式存在,但在某些情況下,我們需要處理較少結構化的數據,例如文本或圖像。在這種情況下,要應用我們上面看到的數據處理技術,我們需要以某種方式提取結構化數據。以下是一些例子:
- 從文本中提取關鍵字,並查看這些關鍵字出現的頻率
- 使用神經網絡提取圖片中物體的信息
- 獲取視頻鏡頭中人物的情感信息
🚀 挑戰 2:分析 COVID 相關論文
在這個挑戰中,我們將繼續探討 COVID 疫情的主題,並專注於處理相關的科學論文。有一個 CORD-19 數據集,其中包含超過 7000 篇(撰寫時)關於 COVID 的論文,並提供元數據和摘要(其中約一半還提供全文)。
使用 Text Analytics for Health 認知服務分析此數據集的完整示例已在 這篇博客文章 中描述。我們將討論此分析的簡化版本。
NOTE: 我們不提供此存儲庫中的數據集副本。你可能需要先從 Kaggle 上的這個數據集 下載
metadata.csv文件。可能需要在 Kaggle 註冊。你也可以從 這裡 無需註冊下載數據集,但它將包括所有全文以及元數據文件。
打開 notebook-papers.ipynb 並從頭到尾閱讀。你也可以執行單元格,並完成我們在最後留下的一些挑戰。
處理圖像數據
最近,已經開發出非常強大的 AI 模型,可以幫助我們理解圖像。有許多任務可以使用預訓練的神經網絡或雲服務解決。一些例子包括:
- 圖像分類,可以幫助你將圖像分類到預定義的類別之一。你可以使用像 Custom Vision 這樣的服務輕鬆訓練自己的圖像分類器。
- 物體檢測,用於檢測圖像中的不同物體。像 Computer Vision 這樣的服務可以檢測許多常見物體,你也可以訓練 Custom Vision 模型來檢測一些特定的感興趣物體。
- 人臉檢測,包括年齡、性別和情感檢測。這可以通過 Face API 完成。
所有這些雲服務都可以通過 Python SDKs 調用,因此可以輕鬆地集成到你的數據探索工作流程中。
以下是一些探索圖像數據源的例子:
- 在博客文章 如何在無需編碼的情況下學習數據科學 中,我們探索 Instagram 照片,試圖了解什麼使人們更喜歡某張照片。我們首先使用 Computer Vision 從圖片中提取盡可能多的信息,然後使用 Azure Machine Learning AutoML 構建可解釋的模型。
- 在 Facial Studies Workshop 中,我們使用 Face API 提取照片中人物的情感,試圖了解什麼使人們感到快樂。
結論
無論你已經擁有結構化數據還是非結構化數據,使用 Python 你都可以完成所有與數據處理和理解相關的步驟。這可能是最靈活的數據處理方式,這也是大多數數據科學家將 Python 作為主要工具的原因。如果你對數據科學之旅是認真的,深入學習 Python 可能是一個好主意!
課後測驗
回顧與自學
書籍
線上資源
- 官方 10 分鐘學 Pandas 教程
- Pandas 可視化文檔
學習 Python
作業
致謝
這節課由 Dmitry Soshnikov 用 ♥️ 編寫。
免責聲明:
本文件已使用 AI 翻譯服務 Co-op Translator 進行翻譯。雖然我們致力於提供準確的翻譯,但請注意,自動翻譯可能包含錯誤或不準確之處。原始文件的母語版本應被視為權威來源。對於關鍵資訊,建議使用專業人工翻譯。我們對因使用此翻譯而引起的任何誤解或誤釋不承擔責任。