|
|
6 months ago | |
|---|---|---|
| .. | ||
| solution | 11 months ago | |
| README.md | 6 months ago | |
| assignment.md | 6 months ago | |
| notebook.ipynb | 11 months ago | |
README.md
クラウドでのデータサイエンス: "Azure ML SDK" の方法
 |
|---|
| クラウドでのデータサイエンス: Azure ML SDK - @nitya によるスケッチノート |
目次:
- クラウドでのデータサイエンス: "Azure ML SDK" の方法
講義前クイズ
1. はじめに
1.1 Azure ML SDKとは?
データサイエンティストやAI開発者は、Azure Machine Learning SDKを使用して、Azure Machine Learningサービスを利用した機械学習ワークフローを構築・実行します。このSDKは、Jupyter Notebooks、Visual Studio Code、またはお気に入りのPython IDEなど、任意のPython環境でサービスとやり取りすることができます。
SDKの主な機能は以下の通りです:
- 機械学習実験で使用するデータセットの探索、準備、ライフサイクル管理。
- 機械学習実験の監視、ログ記録、整理のためのクラウドリソース管理。
- ローカルまたはクラウドリソース(GPUを使用したモデルトレーニングを含む)を使用したモデルのトレーニング。
- 自動機械学習(AutoML)の利用。設定パラメータとトレーニングデータを受け取り、アルゴリズムやハイパーパラメータ設定を自動的に試行して、予測に最適なモデルを見つけます。
- トレーニング済みモデルをRESTfulサービスに変換し、任意のアプリケーションで利用可能なWebサービスとしてデプロイ。
Azure Machine Learning SDKについてさらに学ぶ
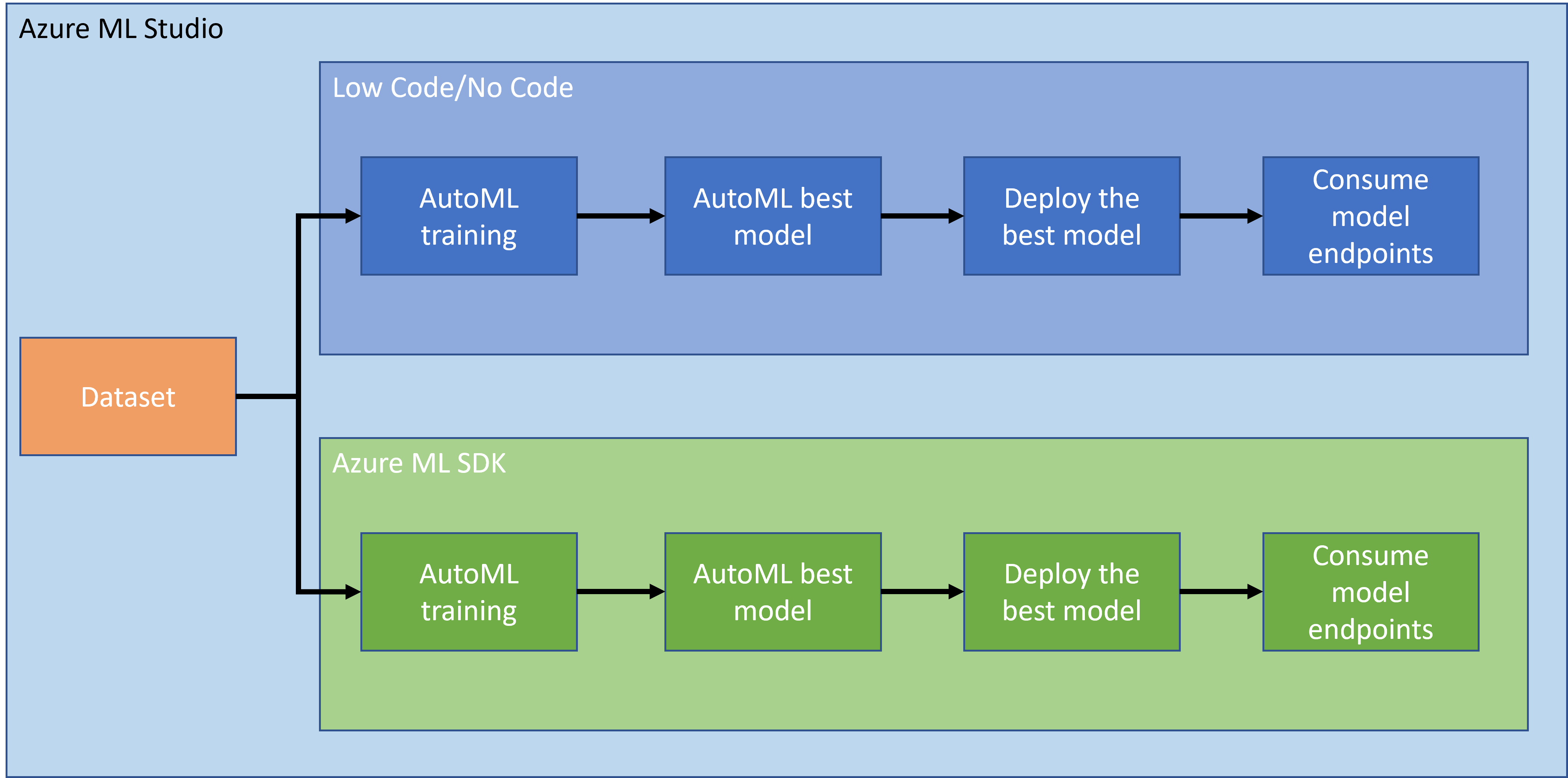
前回のレッスンでは、ローコード/ノーコードの方法でモデルをトレーニング、デプロイ、利用する方法を学びました。心不全データセットを使用して心不全予測モデルを生成しました。このレッスンでは、Azure Machine Learning SDKを使用して同じことを行います。
1.2 心不全予測プロジェクトとデータセットの紹介
心不全予測プロジェクトとデータセットの紹介については、こちらをご覧ください。
2. Azure ML SDKを使ったモデルのトレーニング
2.1 Azure ML ワークスペースの作成
簡単のため、Jupyter Notebookを使用します。これは、すでにワークスペースとコンピュートインスタンスを持っていることを前提としています。すでにワークスペースを持っている場合は、直接2.3 ノートブックの作成セクションに進んでください。
まだワークスペースを作成していない場合は、前回のレッスンの2.1 Azure ML ワークスペースの作成セクションの手順に従ってください。
2.2 コンピュートインスタンスの作成
以前に作成したAzure ML ワークスペースに移動し、コンピュートメニューを開くと、利用可能なさまざまなコンピュートリソースが表示されます。

Jupyter Notebookをプロビジョニングするためのコンピュートインスタンスを作成します。
- 「+ New」ボタンをクリックします。
- コンピュートインスタンスに名前を付けます。
- CPUまたはGPU、VMサイズ、コア数を選択します。
- 「Create」ボタンをクリックします。
おめでとうございます!コンピュートインスタンスが作成されました。このコンピュートインスタンスを使用して、ノートブックの作成セクションでノートブックを作成します。
2.3 データセットの読み込み
まだデータセットをアップロードしていない場合は、前回のレッスンの2.3 データセットの読み込みセクションを参照してください。
2.4 ノートブックの作成
NOTE: 次のステップでは、新しいノートブックをゼロから作成するか、作成済みのノートブックをAzure ML Studioにアップロードすることができます。アップロードするには、「Notebook」メニューをクリックしてノートブックをアップロードしてください。
ノートブックはデータサイエンスプロセスにおいて非常に重要です。探索的データ分析(EDA)を実施したり、コンピュータクラスターを呼び出してモデルをトレーニングしたり、推論クラスターを呼び出してエンドポイントをデプロイしたりするために使用されます。
ノートブックを作成するには、Jupyter Notebookインスタンスを提供するコンピュートノードが必要です。Azure ML ワークスペースに戻り、コンピュートインスタンスをクリックします。作成したコンピュートインスタンスがリストに表示されるはずです。
- 「Applications」セクションで「Jupyter」オプションをクリックします。
- 「Yes, I understand」ボックスにチェックを入れ、「Continue」ボタンをクリックします。

- 新しいブラウザタブが開き、以下のようにJupyter Notebookインスタンスが表示されます。「New」ボタンをクリックしてノートブックを作成します。

これでノートブックが作成されました。Azure ML SDKを使用してモデルのトレーニングを開始できます。
2.5 モデルのトレーニング
まず、疑問がある場合は、Azure ML SDK ドキュメントを参照してください。このレッスンで使用するモジュールに関する必要な情報がすべて含まれています。
2.5.1 ワークスペース、実験、コンピュートクラスター、データセットのセットアップ
以下のコードを使用して、構成ファイルからworkspaceを読み込みます:
from azureml.core import Workspace
ws = Workspace.from_config()
これにより、ワークスペースを表すWorkspace型のオブジェクトが返されます。その後、以下のコードを使用してexperimentを作成します:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
ワークスペースから実験を取得または作成するには、実験名を指定してリクエストします。実験名は3〜36文字で、文字または数字で始まり、文字、数字、アンダースコア、ダッシュのみを含む必要があります。ワークスペースに実験が見つからない場合、新しい実験が作成されます。
次に、以下のコードを使用してトレーニング用のコンピュートクラスターを作成します。このステップには数分かかる場合があります。
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
以下の方法で、ワークスペースからデータセットを取得できます:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 AutoMLの設定とトレーニング
AutoMLConfigクラスを使用してAutoMLの設定を行います。
ドキュメントに記載されているように、多くのパラメータを調整することができます。このプロジェクトでは、以下のパラメータを使用します:
experiment_timeout_minutes: 実験が自動的に停止され、結果が利用可能になるまでの最大実行時間(分)。max_concurrent_iterations: 実験で許可される最大同時トレーニング反復回数。primary_metric: 実験のステータスを決定するために使用される主要なメトリック。compute_target: 自動機械学習実験を実行するAzure Machine Learningコンピュートターゲット。task: 実行するタスクの種類。'classification'、'regression'、または'forecasting'のいずれか。training_data: 実験内で使用されるトレーニングデータ。トレーニング特徴量とラベル列(オプションでサンプル重み列)を含む必要があります。label_column_name: ラベル列の名前。path: Azure Machine Learningプロジェクトフォルダーへのフルパス。enable_early_stopping: スコアが短期間で改善しない場合に早期終了を有効にするかどうか。featurization: 特徴量エンジニアリングステップを自動的に行うか、カスタマイズされた特徴量エンジニアリングを使用するかの指標。debug_log: デバッグ情報を書き込むログファイル。
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
設定が完了したら、以下のコードを使用してモデルをトレーニングします。このステップはクラスターサイズによっては1時間ほどかかる場合があります。
remote_run = experiment.submit(automl_config)
RunDetailsウィジェットを実行して、さまざまな実験を表示できます。
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Azure ML SDKを使ったモデルのデプロイとエンドポイントの利用
3.1 最適なモデルの保存
remote_runはAutoMLRun型のオブジェクトです。このオブジェクトにはget_output()メソッドが含まれており、最適な実行と対応するフィット済みモデルを返します。
best_run, fitted_model = remote_run.get_output()
最適なモデルで使用されたパラメータを確認するには、fitted_modelを出力するだけで確認できます。また、get_properties()メソッドを使用して最適なモデルのプロパティを確認できます。
best_run.get_properties()
次に、register_modelメソッドを使用してモデルを登録します。
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 モデルのデプロイ
最適なモデルが保存されたら、InferenceConfigクラスを使用してデプロイできます。InferenceConfigは、デプロイメントに使用されるカスタム環境の設定を表します。AciWebserviceクラスは、Azure Container Instances上にデプロイされたWebサービスエンドポイントとしての機械学習モデルを表します。デプロイされたサービスは、モデル、スクリプト、および関連ファイルから作成されます。結果として得られるWebサービスは、ロードバランスされたHTTPエンドポイントであり、REST APIを備えています。このAPIにデータを送信し、モデルによる予測を受け取ることができます。
モデルはdeployメソッドを使用してデプロイされます。
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
このステップには数分かかる場合があります。
3.3 エンドポイントの利用
エンドポイントを利用するには、サンプル入力を作成します:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
その後、この入力をモデルに送信して予測を取得します:
response = aci_service.run(input_data=test_sample)
response
これにより、'{"result": [false]}' が出力されるはずです。これは、エンドポイントに送信した患者の入力が予測結果 false を生成したことを意味します。つまり、この人が心臓発作を起こす可能性は低いということです。
おめでとうございます!Azure ML SDKを使用して、Azure ML上でトレーニングおよびデプロイされたモデルを利用することができました!
NOTE: プロジェクトが完了したら、すべてのリソースを忘れずに削除してください。
🚀 チャレンジ
SDKを通じてできることはたくさんありますが、残念ながらこのレッスンですべてを紹介することはできません。しかし、良いニュースとして、SDKのドキュメントを効率よく調べる方法を学ぶことで、自分自身で多くのことを進めることができます。Azure ML SDKのドキュメントを確認し、パイプラインを作成できるPipelineクラスを探してみてください。パイプラインは、ワークフローとして実行できる一連のステップの集合です。
ヒント: SDKドキュメントにアクセスし、検索バーに「Pipeline」などのキーワードを入力してください。検索結果にazureml.pipeline.core.Pipelineクラスが表示されるはずです。
講義後のクイズ
復習と自己学習
このレッスンでは、Azure ML SDKを使用してクラウド上で心不全リスクを予測するモデルをトレーニング、デプロイ、利用する方法を学びました。Azure ML SDKに関するさらなる情報は、このドキュメントを確認してください。Azure ML SDKを使用して、自分自身のモデルを作成してみてください。
課題
Azure ML SDKを使用したデータサイエンスプロジェクト
免責事項:
この文書は、AI翻訳サービス Co-op Translator を使用して翻訳されています。正確性を追求しておりますが、自動翻訳には誤りや不正確な部分が含まれる可能性があることをご承知ください。元の言語で記載された文書が正式な情報源とみなされるべきです。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の使用に起因する誤解や誤解釈について、当方は責任を負いません。