12 KiB
データサイエンスライフサイクルの紹介
 |
|---|
| データサイエンスライフサイクルの紹介 - スケッチノート by @nitya |
講義前クイズ
ここまでで、データサイエンスがプロセスであることに気づいたかもしれません。このプロセスは以下の5つの段階に分けることができます:
- データの収集
- 処理
- 分析
- コミュニケーション
- 保守
このレッスンでは、ライフサイクルの3つの部分、つまりデータの収集、処理、保守に焦点を当てます。
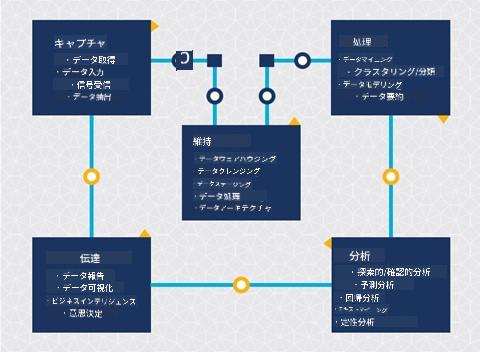
データの収集
ライフサイクルの最初の段階は非常に重要です。なぜなら、次の段階がこれに依存しているからです。この段階は、データの取得と目的や解決すべき問題の定義という2つのステージを組み合わせたものです。
プロジェクトの目標を定義するには、問題や質問に対する深い理解が必要です。まず、問題解決を必要としている人々を特定し、取得する必要があります。これらは、ビジネスの利害関係者やプロジェクトのスポンサーである可能性があり、プロジェクトが誰に、何に、そしてなぜ役立つのかを特定する手助けをしてくれます。明確に定義された目標は、測定可能で定量化可能であるべきで、許容可能な結果を定義する必要があります。
データサイエンティストが尋ねる可能性のある質問:
- この問題は以前に取り組まれたことがあるか?何が発見されたか?
- 関係者全員が目的と目標を理解しているか?
- 曖昧さはあるか?それをどう減らすか?
- 制約は何か?
- 最終的な結果はどのようなものになる可能性があるか?
- 利用可能なリソース(時間、人員、計算能力)はどれくらいか?
次に、目標を達成するために必要なデータを特定し、収集し、探索します。この取得のステップでは、データサイエンティストはデータの量と質を評価する必要があります。これには、取得したデータが望ましい結果を達成するのに役立つかどうかを確認するためのデータ探索が含まれます。
データに関してデータサイエンティストが尋ねる可能性のある質問:
- すでに利用可能なデータは何か?
- このデータの所有者は誰か?
- プライバシーに関する懸念は何か?
- この問題を解決するのに十分なデータがあるか?
- この問題に対してデータの質は許容範囲か?
- このデータを通じて追加情報を発見した場合、目標を変更または再定義するべきか?
処理
ライフサイクルの処理段階では、データのパターンを発見したり、モデリングを行ったりします。この段階で使用されるいくつかの技術は、統計的手法を用いてパターンを明らかにします。通常、大規模なデータセットでは人間が手作業で行うには非常に手間がかかるため、コンピュータを使用してプロセスを迅速化します。この段階では、データサイエンスと機械学習が交差します。最初のレッスンで学んだように、機械学習はデータを理解するためのモデルを構築するプロセスです。モデルは、データ内の変数間の関係を表現し、結果を予測するのに役立ちます。
この段階で使用される一般的な技術は、ML for Beginnersカリキュラムで取り上げられています。以下のリンクから詳細を学べます:
保守
ライフサイクルの図では、保守がデータの収集と処理の間に位置していることに気づいたかもしれません。保守は、プロジェクトの過程でデータを管理、保存、保護する継続的なプロセスであり、プロジェクト全体を通じて考慮されるべきです。
データの保存
データがどのように、どこに保存されるかの考慮は、保存コストやデータのアクセス速度に影響を与える可能性があります。このような決定はデータサイエンティストだけで行われることは少ないですが、保存方法に基づいてデータをどのように扱うかについて選択を迫られることがあります。
現代のデータ保存システムのいくつかの側面がこれらの選択に影響を与える可能性があります:
オンプレミス vs オフプレミス vs 公共またはプライベートクラウド
オンプレミスは、自分の設備でデータを管理することを指します。例えば、サーバーを所有し、そのハードドライブにデータを保存することです。一方、オフプレミスは、自分が所有していない設備(例えばデータセンター)を利用することを指します。公共クラウドは、データがどのように、どこに保存されているかを正確に知る必要がない人気の選択肢です。公共クラウドは、クラウドを利用するすべての人が共有する統一された基盤インフラを指します。一部の組織は厳格なセキュリティポリシーを持ち、データがホストされている設備に完全にアクセスできる必要があるため、独自のクラウドサービスを提供するプライベートクラウドを利用します。後のレッスンでクラウド内のデータについてさらに学びます。
コールドデータ vs ホットデータ
モデルをトレーニングする際には、より多くのトレーニングデータが必要になる場合があります。モデルに満足している場合でも、モデルが目的を果たすために新しいデータが到着します。いずれの場合でも、データを蓄積するにつれて保存とアクセスのコストが増加します。あまり使用されないデータ(コールドデータ)を頻繁にアクセスされるデータ(ホットデータ)から分離することで、ハードウェアやソフトウェアサービスを通じて安価なデータ保存オプションを利用できます。コールドデータをアクセスする必要がある場合、ホットデータに比べて取得に少し時間がかかるかもしれません。
データの管理
データを扱う中で、一部のデータをクリーンアップする必要があることに気づくかもしれません。これは、データ準備に焦点を当てたレッスンで取り上げた技術を使用して正確なモデルを構築するためです。新しいデータが到着すると、品質の一貫性を維持するために同じ技術を適用する必要があります。一部のプロジェクトでは、データを最終的な場所に移動する前に、クレンジング、集約、圧縮を行う自動化ツールを使用することがあります。Azure Data Factoryはこれらのツールの一例です。
データの保護
データを保護する主な目的の1つは、データを扱う人々が収集される内容とその使用される文脈を管理できるようにすることです。データを安全に保つには、必要な人だけがアクセスできるようにし、地域の法律や規制を遵守し、倫理のレッスンで取り上げた倫理基準を維持することが含まれます。
チームがセキュリティを考慮して行う可能性のあること:
- すべてのデータが暗号化されていることを確認する
- 顧客にデータの使用方法について情報を提供する
- プロジェクトを離れた人からデータアクセスを削除する
- 特定のプロジェクトメンバーだけがデータを変更できるようにする
🚀 チャレンジ
データサイエンスライフサイクルには多くのバージョンがあり、それぞれのステップには異なる名前や段階数があるかもしれませんが、このレッスンで述べたプロセスは含まれています。
Team Data Science Processライフサイクルとデータマイニングの業界標準プロセスを調査し、3つの類似点と相違点を挙げてください。
| Team Data Science Process (TDSP) | データマイニングの業界標準プロセス (CRISP-DM) |
|---|---|
 |
 |
| 画像提供:Microsoft | 画像提供:Data Science Process Alliance |
講義後クイズ
復習と自己学習
データサイエンスライフサイクルを適用するには、複数の役割とタスクが関わり、それぞれの段階の特定の部分に焦点を当てる場合があります。Team Data Science Processは、プロジェクトで誰がどのような役割やタスクを持つかを説明するいくつかのリソースを提供しています。
課題
免責事項:
この文書は、AI翻訳サービス Co-op Translator を使用して翻訳されています。正確性を期すよう努めておりますが、自動翻訳には誤りや不正確な表現が含まれる可能性があります。元の言語で記載された原文を公式な情報源としてご参照ください。重要な情報については、専門の人間による翻訳を推奨します。本翻訳の利用に起因する誤解や誤認について、当社は一切の責任を負いません。