25 KiB
データの操作: PythonとPandasライブラリ
 |
|---|
| Pythonでの操作 - @nitya によるスケッチノート |
データベースはデータを効率的に保存し、クエリ言語を使用して検索する方法を提供しますが、データ処理の最も柔軟な方法は、自分自身でプログラムを書いてデータを操作することです。多くの場合、データベースクエリを使用する方が効果的です。しかし、より複雑なデータ処理が必要な場合、SQLでは簡単に実現できないことがあります。
データ処理はどのプログラミング言語でもプログラム可能ですが、データ操作に特化した高レベルな言語があります。データサイエンティストは通常、以下の言語のいずれかを好みます:
- Python: 汎用プログラミング言語であり、そのシンプルさから初心者に最適とされています。Pythonには多くの追加ライブラリがあり、ZIPアーカイブからデータを抽出したり、画像をグレースケールに変換したりといった実用的な問題を解決できます。データサイエンスだけでなく、ウェブ開発にもよく使用されます。
- R: 統計データ処理を目的に開発された伝統的なツールボックスです。大規模なライブラリリポジトリ(CRAN)を含んでおり、データ処理に適しています。ただし、Rは汎用プログラミング言語ではなく、データサイエンス以外の分野ではあまり使用されません。
- Julia: データサイエンス専用に開発された言語で、Pythonよりも高いパフォーマンスを提供することを目的としています。科学的な実験に適したツールです。
このレッスンでは、Pythonを使用した簡単なデータ処理に焦点を当てます。Pythonの基本的な知識があることを前提とします。Pythonをより深く学びたい場合は、以下のリソースを参照してください:
- Learn Python in a Fun Way with Turtle Graphics and Fractals - PythonプログラミングのGitHubベースの簡易入門コース
- Take your First Steps with Python - Microsoft Learn の学習パス
データはさまざまな形式で存在します。このレッスンでは、表形式データ、テキスト、画像の3つの形式を考えます。
関連するすべてのライブラリの概要を提供するのではなく、いくつかのデータ処理の例に焦点を当てます。これにより、可能性の主なアイデアを理解し、必要なときに問題の解決策を見つける方法を学ぶことができます。
最も役立つアドバイス: データに対して特定の操作を行う必要があるが方法がわからない場合、インターネットで検索してみてください。Stackoverflow には、Pythonでの典型的なタスクに関する有用なコードサンプルが多数掲載されています。
講義前のクイズ
表形式データとデータフレーム
リレーショナルデータベースについて話した際に、表形式データにすでに触れました。大量のデータがあり、それが多くの異なるリンクされたテーブルに含まれている場合、SQLを使用して操作するのが理にかなっています。しかし、データの分布や値間の相関など、このデータについての理解や洞察を得る必要がある場合があります。データサイエンスでは、元のデータの変換とその後の可視化を行う必要があるケースが多くあります。これらのステップはPythonを使用して簡単に実行できます。
Pythonで表形式データを扱う際に役立つ最も重要なライブラリは以下の2つです:
- Pandas: データフレームを操作するためのライブラリで、リレーショナルテーブルに類似しています。名前付きの列を持ち、行、列、データフレーム全体に対してさまざまな操作を実行できます。
- Numpy: テンソル、つまり多次元配列を操作するためのライブラリです。配列は同じ基礎型の値を持ち、データフレームよりもシンプルですが、より多くの数学的操作を提供し、オーバーヘッドが少なくなります。
また、知っておくべきライブラリがいくつかあります:
- Matplotlib: データの可視化やグラフのプロットに使用されるライブラリ
- SciPy: 追加の科学的関数を含むライブラリ。確率と統計について話した際にすでにこのライブラリに触れました
以下は、Pythonプログラムの冒頭でこれらのライブラリをインポートする際に通常使用されるコードの一例です:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandasはいくつかの基本的な概念を中心に構築されています。
Series
Seriesは、リストやnumpy配列に似た値のシーケンスです。主な違いは、Seriesにはインデックスがあり、Seriesを操作する際(例: 加算する際)にインデックスが考慮されることです。インデックスは単純な整数行番号(リストや配列からSeriesを作成する際のデフォルトインデックス)である場合もあれば、日付間隔のような複雑な構造を持つ場合もあります。
注意: 付属のノートブック
notebook.ipynbにPandasの入門コードが含まれています。ここではいくつかの例を簡単に説明しますが、ぜひ完全なノートブックを確認してください。
例を考えてみましょう: アイスクリームショップの売上を分析したいとします。一定期間の売上数(各日販売されたアイテム数)のSeriesを生成します:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
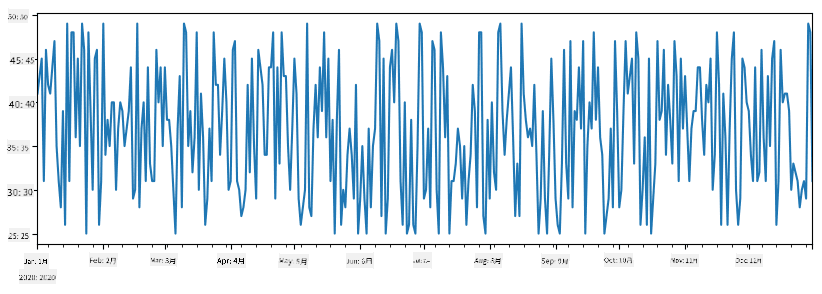
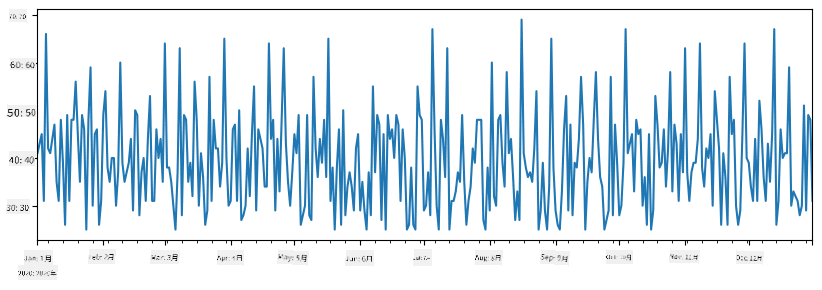
次に、毎週友人のためにパーティーを開催し、パーティー用にアイスクリームを10パック追加で購入するとします。これを示すために、週ごとにインデックス付けされた別のSeriesを作成できます:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
2つのSeriesを加算すると、合計数が得られます:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
注意: 単純な構文
total_items+additional_itemsを使用していないことに注意してください。この場合、結果のSeriesに多くのNaN(Not a Number)値が含まれることになります。これは、additional_itemsSeriesのインデックスポイントの一部に欠損値があり、NaNを加算すると結果がNaNになるためです。そのため、加算時にfill_valueパラメータを指定する必要があります。
時系列データでは、異なる時間間隔でSeriesをリサンプリングすることもできます。たとえば、月ごとの平均売上量を計算したい場合、以下のコードを使用できます:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')

DataFrame
DataFrameは、同じインデックスを持つ複数のSeriesのコレクションです。複数のSeriesを組み合わせてDataFrameを作成できます:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
これにより、以下のような横方向のテーブルが作成されます:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
また、Seriesを列として使用し、辞書を使用して列名を指定することもできます:
df = pd.DataFrame({ 'A' : a, 'B' : b })
これにより、以下のようなテーブルが得られます:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
注意: 前のテーブルを転置することで、このテーブルレイアウトを得ることもできます。例えば、以下のように書くことで:
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
ここで.TはDataFrameを転置する操作を意味し、rename操作を使用して列名を前の例に一致させることができます。
DataFrameで実行できる最も重要な操作をいくつか紹介します:
列の選択: df['A']と書くことで個々の列を選択できます。この操作はSeriesを返します。また、df[['B','A']]と書くことで列のサブセットを別のDataFrameに選択できます。
条件に基づく行のフィルタリング: 例えば、列Aが5より大きい行のみを残すには、df[df['A']>5]と書きます。
注意: フィルタリングの仕組みは次の通りです。式
df['A']<5はブールSeriesを返し、元のSeriesdf['A']の各要素に対して式がTrueまたはFalseであるかを示します。ブールSeriesがインデックスとして使用されると、DataFrameの行のサブセットが返されます。そのため、任意のPythonブール式を使用することはできません。例えば、df[df['A']>5 and df['A']<7]と書くのは間違いです。代わりに、ブールSeriesに対して特別な&操作を使用し、df[(df['A']>5) & (df['A']<7)]と書く必要があります(括弧が重要です)。
計算可能な新しい列の作成: 直感的な式を使用してDataFrameに新しい計算可能な列を簡単に作成できます:
df['DivA'] = df['A']-df['A'].mean()
この例では、列Aの平均値からの乖離を計算しています。ここで実際に行われているのは、Seriesを計算し、それを左辺に割り当てて新しい列を作成することです。そのため、Seriesと互換性のない操作は使用できません。例えば、以下のコードは間違っています:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
後者の例は構文的には正しいですが、意図した個々の要素の長さではなく、SeriesBの長さをすべての値に割り当ててしまうため、誤った結果を返します。
このような複雑な式を計算する必要がある場合は、apply関数を使用できます。最後の例は次のように書き換えることができます:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
上記の操作後、以下のDataFrameが得られます:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
行番号に基づく選択はiloc構文を使用して行うことができます。例えば、DataFrameの最初の5行を選択するには:
df.iloc[:5]
グループ化は、Excelのピボットテーブルに似た結果を得るためによく使用されます。例えば、LenBの各値に対して列Aの平均値を計算したい場合、DataFrameをLenBでグループ化し、meanを呼び出します:
df.groupby(by='LenB')[['A','DivA']].mean()
グループ内の平均値と要素数を計算する必要がある場合は、より複雑なaggregate関数を使用できます:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
これにより、以下のテーブルが得られます:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
データの取得
PythonオブジェクトからSeriesやDataFrameを構築するのがいかに簡単かを見てきました。しかし、データは通常、テキストファイルやExcelテーブルの形式で提供されます。幸いなことに、Pandasはディスクからデータを読み込むための簡単な方法を提供しています。例えば、CSVファイルを読み込むのは以下のように簡単です:
df = pd.read_csv('file.csv')
「チャレンジ」セクションでは、外部ウェブサイトからデータを取得する例を含め、データの読み込みについてさらに詳しく見ていきます。
データの表示とプロット
データサイエンティストはデータを探索する必要があるため、データを視覚化することが重要です。DataFrameが大きい場合、最初の数行を表示してすべてが正しく動作していることを確認したいことがよくあります。これにはdf.head()を呼び出すことで対応できます。Jupyter Notebookで実行している場合、DataFrameがきれいな表形式で表示されます。
また、いくつかの列を視覚化するためにplot関数を使用する方法も見てきました。plotは多くのタスクに非常に便利で、kind=パラメータを使用してさまざまなグラフタイプをサポートしていますが、より複雑なものをプロットしたい場合は、matplotlibライブラリを直接使用することもできます。データの視覚化については、別のコースレッスンで詳しく説明します。
この概要ではPandasの重要な概念をほとんど網羅していますが、このライブラリは非常に豊富で、できることに限界はありません!では、この知識を使って具体的な問題を解決してみましょう。
🚀 チャレンジ1: COVIDの拡散を分析する
最初に取り組む問題は、COVID-19の流行拡散のモデル化です。そのために、ジョンズ・ホプキンス大学のシステム科学工学センター (CSSE)が提供する、各国の感染者数に関するデータを使用します。このデータセットはこのGitHubリポジトリで利用可能です。
データの扱い方を示すために、notebook-covidspread.ipynbを開き、上から下まで読んでみてください。また、セルを実行したり、最後に残しておいたチャレンジに取り組むこともできます。
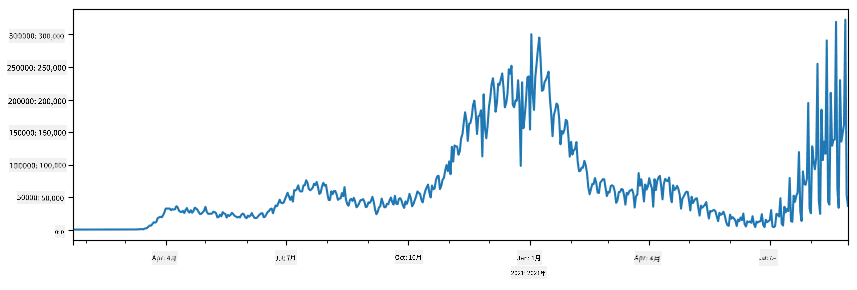
Jupyter Notebookでコードを実行する方法がわからない場合は、この記事を参照してください。
非構造化データの扱い
データは非常に頻繁に表形式で提供されますが、場合によってはテキストや画像など、あまり構造化されていないデータを扱う必要があります。この場合、上記で見たデータ処理技術を適用するために、何らかの方法で構造化データを抽出する必要があります。以下はその例です:
- テキストからキーワードを抽出し、それらのキーワードがどのくらい頻繁に出現するかを確認する
- ニューラルネットワークを使用して画像内のオブジェクトに関する情報を抽出する
- ビデオカメラのフィードから人々の感情に関する情報を取得する
🚀 チャレンジ2: COVID関連論文の分析
このチャレンジでは、COVIDパンデミックのテーマを続け、関連する科学論文の処理に焦点を当てます。CORD-19 Datasetには、COVIDに関する7000以上(執筆時点)の論文が、メタデータや要約とともに提供されています(約半分には全文も含まれています)。
このデータセットを分析する完全な例は、Text Analytics for Healthコグニティブサービスを使用してこのブログ記事で説明されています。ここでは、この分析の簡略版を議論します。
NOTE: このリポジトリにはデータセットのコピーは含まれていません。まず、このKaggleデータセットから
metadata.csvファイルをダウンロードする必要があります。Kaggleへの登録が必要になる場合があります。また、登録なしでこちらからデータセットをダウンロードすることもできますが、メタデータファイルに加えて全文も含まれます。
notebook-papers.ipynbを開き、上から下まで読んでみてください。また、セルを実行したり、最後に残しておいたチャレンジに取り組むこともできます。
画像データの処理
最近、画像を理解するための非常に強力なAIモデルが開発されています。事前学習済みのニューラルネットワークやクラウドサービスを使用して解決できるタスクが多数あります。以下はその例です:
- 画像分類:画像を事前定義されたクラスのいずれかに分類することができます。Custom Visionなどのサービスを使用して独自の画像分類器を簡単にトレーニングできます。
- オブジェクト検出:画像内のさまざまなオブジェクトを検出します。Computer Visionなどのサービスは多くの一般的なオブジェクトを検出でき、Custom Visionモデルをトレーニングして特定の関心オブジェクトを検出することもできます。
- 顔検出:年齢、性別、感情の検出を含みます。Face APIを使用して実現できます。
これらのクラウドサービスはPython SDKsを使用して呼び出すことができるため、データ探索ワークフローに簡単に組み込むことができます。
以下は画像データソースを探索する例です:
- How to Learn Data Science without Codingというブログ記事では、Instagramの写真を探索し、人々が写真に多くの「いいね」を付ける理由を理解しようとしています。まずComputer Visionを使用して写真から可能な限り多くの情報を抽出し、その後Azure Machine Learning AutoMLを使用して解釈可能なモデルを構築します。
- Facial Studies Workshopでは、Face APIを使用してイベントの写真に写っている人々の感情を抽出し、人々を幸せにする要因を理解しようとしています。
結論
構造化データでも非構造化データでも、Pythonを使用すればデータ処理と理解に関連するすべてのステップを実行できます。Pythonはおそらく最も柔軟なデータ処理方法であり、そのため多くのデータサイエンティストがPythonを主要なツールとして使用しています。データサイエンスの旅を本格的に進めたい場合は、Pythonを深く学ぶことをお勧めします!
講義後のクイズ
復習と自己学習
書籍
オンラインリソース
Python学習
- Learn Python in a Fun Way with Turtle Graphics and Fractals
- Take your First Steps with Python Microsoft Learnの学習パス
課題
クレジット
このレッスンはDmitry Soshnikovによって♥️を込めて作成されました。
免責事項:
この文書は、AI翻訳サービス Co-op Translator を使用して翻訳されています。正確性を追求しておりますが、自動翻訳には誤りや不正確な部分が含まれる可能性があることをご承知ください。元の言語で記載された文書が正式な情報源とみなされるべきです。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の使用に起因する誤解や誤解釈について、当方は一切の責任を負いません。