16 KiB
データの操作: 非リレーショナルデータ
 |
|---|
| NoSQLデータの操作 - スケッチノート by @nitya |
講義前クイズ
データはリレーショナルデータベースに限定されません。このレッスンでは、非リレーショナルデータに焦点を当て、スプレッドシートとNoSQLの基本について学びます。
スプレッドシート
スプレッドシートは、セットアップや開始に手間がかからないため、データを保存・探索するための一般的な方法です。このレッスンでは、スプレッドシートの基本的な構成要素、数式や関数について学びます。例はMicrosoft Excelを使用して説明しますが、他のスプレッドシートソフトウェアでも似たような名称や手順が多くあります。

スプレッドシートはファイルであり、コンピュータ、デバイス、またはクラウドベースのファイルシステムでアクセス可能です。ソフトウェア自体はブラウザベースの場合もあれば、コンピュータにインストールするアプリケーションやアプリとしてダウンロードする必要がある場合もあります。Excelでは、これらのファイルはワークブックと定義されており、このレッスンではこの用語を使用します。
ワークブックには1つ以上のワークシートが含まれ、それぞれのワークシートはタブでラベル付けされています。ワークシート内にはセルと呼ばれる長方形があり、実際のデータが含まれます。セルは行と列の交差点であり、列はアルファベットで、行は数字でラベル付けされています。一部のスプレッドシートでは、最初の数行にヘッダーが含まれ、セル内のデータを説明します。
Excelワークブックのこれらの基本要素を使用して、Microsoft Templatesの在庫管理に焦点を当てた例を使い、スプレッドシートの追加部分を見ていきます。
在庫管理
"InventoryExample"という名前のスプレッドシートファイルは、在庫内のアイテムをフォーマットしたスプレッドシートで、3つのワークシートが含まれています。タブには「Inventory List」、「Inventory Pick List」、「Bin Lookup」とラベル付けされています。Inventory Listワークシートの4行目はヘッダーで、ヘッダー列内の各セルの値を説明しています。
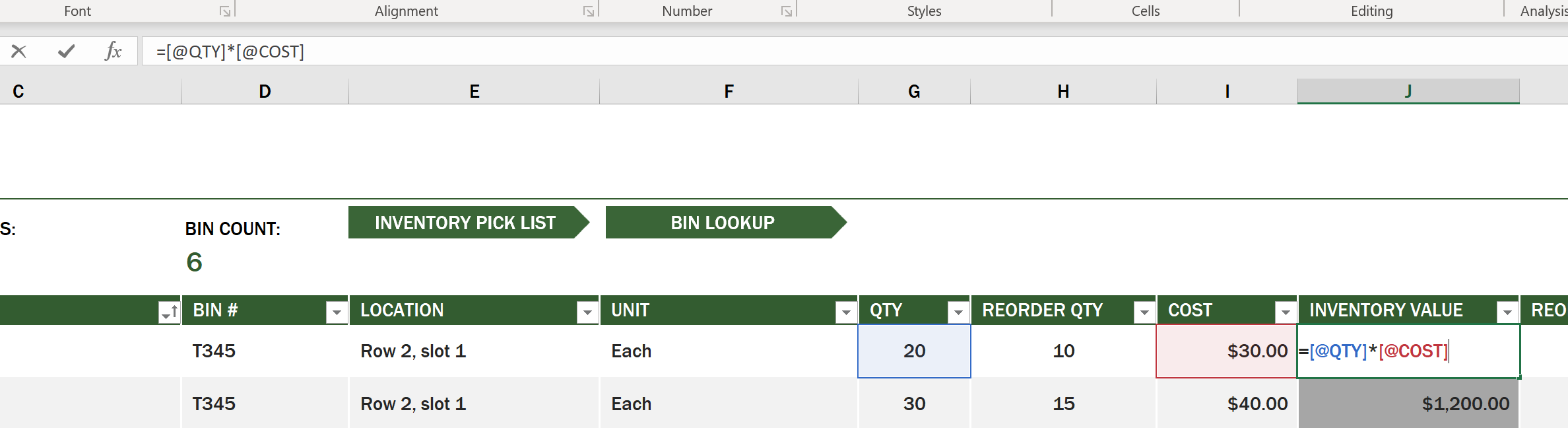
セルが他のセルの値に依存して値を生成する場合があります。この在庫リストスプレッドシートでは、在庫内の各アイテムのコストを追跡していますが、在庫全体の価値を知りたい場合はどうすればよいでしょうか。数式はセルデータに対して操作を行い、この例では在庫の価値を計算するために使用されます。このスプレッドシートでは、Inventory Value列に数式を使用して、QTYヘッダーの下の数量とCOSTヘッダーの下のコストを掛け合わせて各アイテムの価値を計算しています。セルをダブルクリックまたはハイライトすると数式が表示されます。数式は等号(=)で始まり、その後に計算や操作が続きます。
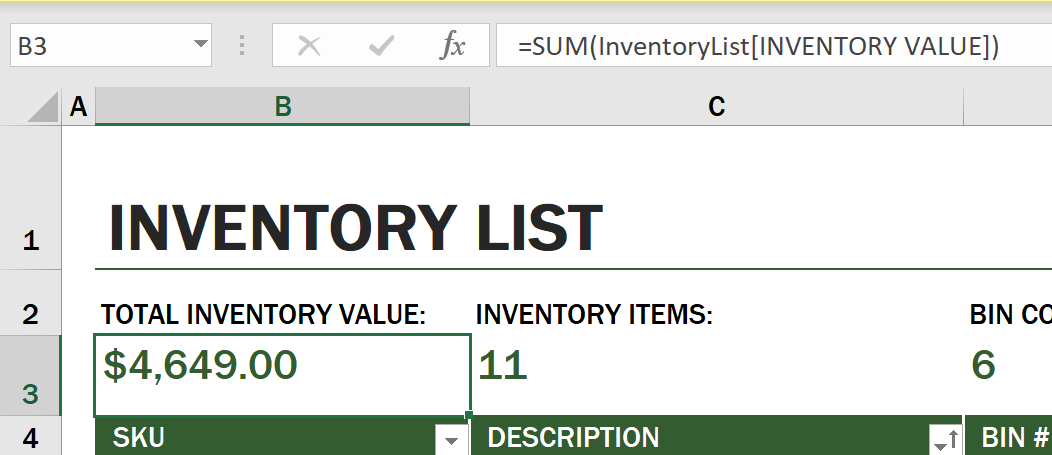
在庫価値のすべての値を合計して総価値を求める別の数式を使用することもできます。各セルを加算して合計を生成することもできますが、それは手間のかかる作業です。Excelには関数と呼ばれる、セル値に対して計算を行うための事前定義された数式があります。関数には引数が必要で、これは計算を行うために必要な値です。複数の引数が必要な場合、それらは特定の順序でリストされる必要があり、そうでないと関数が正しい値を計算できない場合があります。この例ではSUM関数を使用し、Inventory Valueの値を引数として使用して合計を生成し、B3(3行目、列B)にリストされています。
NoSQL
NoSQLは、非リレーショナルデータを保存するさまざまな方法を指す包括的な用語であり、「非SQL」、「非リレーショナル」、または「SQLだけではない」と解釈されることがあります。このタイプのデータベースシステムは、4つのタイプに分類されます。
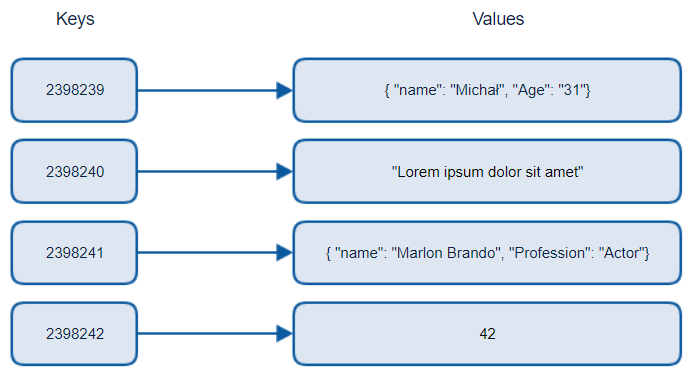
キーと値のデータベースは、一意の識別子であるキーと値をペアにして保存します。これらのペアは、適切なハッシュ関数を使用したハッシュテーブルを使用して保存されます。
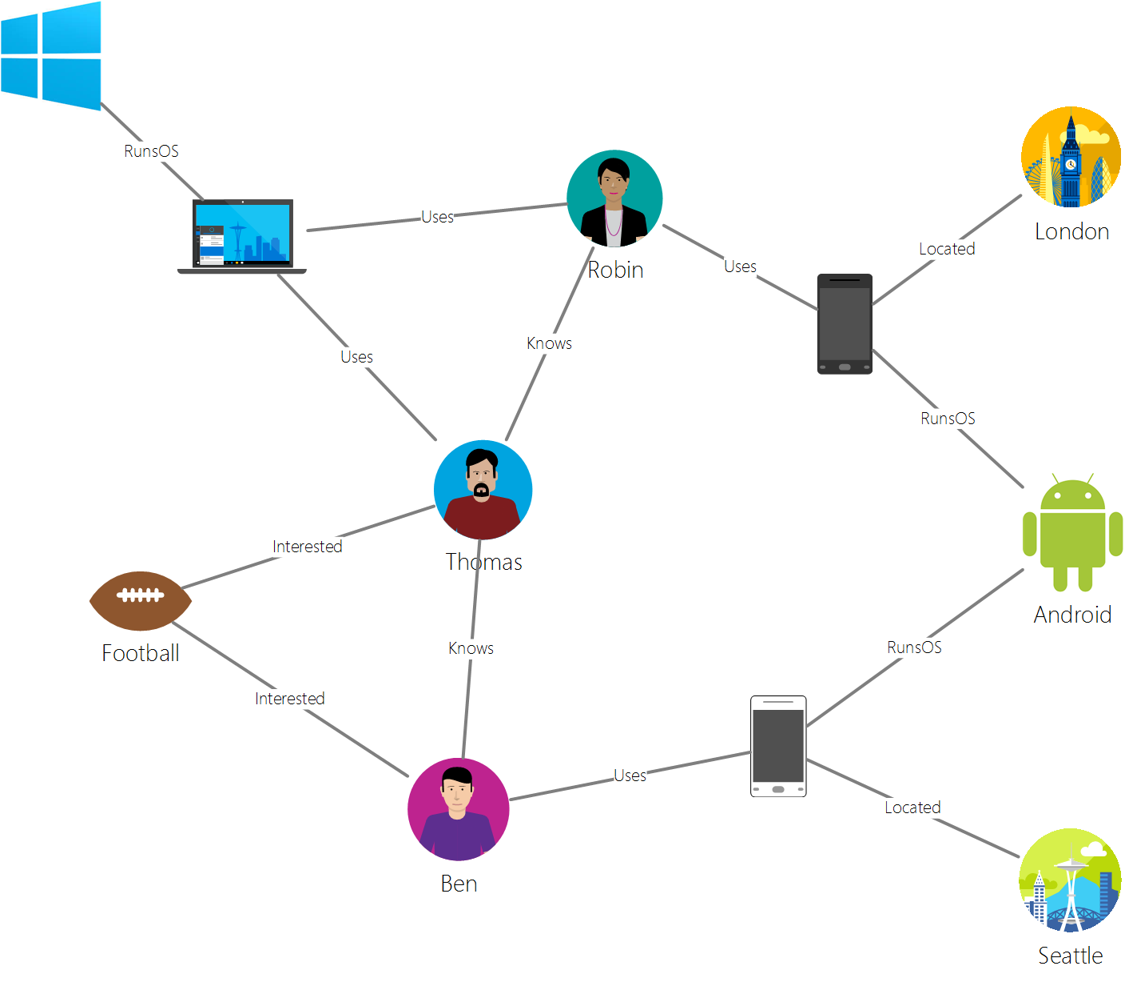
出典: Microsoft
グラフデータベースはデータの関係を記述し、ノードとエッジの集合として表されます。ノードは、学生や銀行明細書など、現実世界に存在するエンティティを表します。エッジは2つのエンティティ間の関係を表します。各ノードとエッジには、それぞれの追加情報を提供するプロパティがあります。

カラム型データストアは、リレーショナルデータ構造のようにデータを列と行に整理しますが、各列はカラムファミリーと呼ばれるグループに分けられます。同じ列内のすべてのデータは関連しており、一つの単位として取得および変更することができます。
Azure Cosmos DBを使ったドキュメントデータストア
ドキュメントデータストアは、キーと値のデータストアの概念を基に構築され、フィールドとオブジェクトの一連で構成されています。このセクションでは、Cosmos DBエミュレーターを使用してドキュメントデータベースを探ります。
Cosmos DBデータベースは「SQLだけではない」という定義に当てはまり、Cosmos DBのドキュメントデータベースはデータをクエリするためにSQLを使用します。前回のレッスンではSQLの基本を学びましたが、ここではドキュメントデータベースに同じクエリを適用することができます。Cosmos DBエミュレーターを使用すると、ローカルコンピュータ上でドキュメントデータベースを作成し、探索することができます。エミュレーターについての詳細はこちらをご覧ください。
ドキュメントはフィールドとオブジェクト値の集合であり、フィールドはオブジェクト値が何を表しているかを説明します。以下はドキュメントの例です。
{
"firstname": "Eva",
"age": 44,
"id": "8c74a315-aebf-4a16-bb38-2430a9896ce5",
"_rid": "bHwDAPQz8s0BAAAAAAAAAA==",
"_self": "dbs/bHwDAA==/colls/bHwDAPQz8s0=/docs/bHwDAPQz8s0BAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f95-010a691e01d7\"",
"_attachments": "attachments/",
"_ts": 1630544034
}
このドキュメントで注目すべきフィールドは、firstname、id、ageです。アンダースコア付きの他のフィールドはCosmos DBによって生成されました。
Cosmos DBエミュレーターを使ったデータの探索
エミュレーターはWindows用はこちらからダウンロードしてインストールできます。macOSやLinuxでエミュレーターを実行する方法については、このドキュメントを参照してください。
エミュレーターを起動するとブラウザウィンドウが開き、Explorerビューでドキュメントを探索できます。
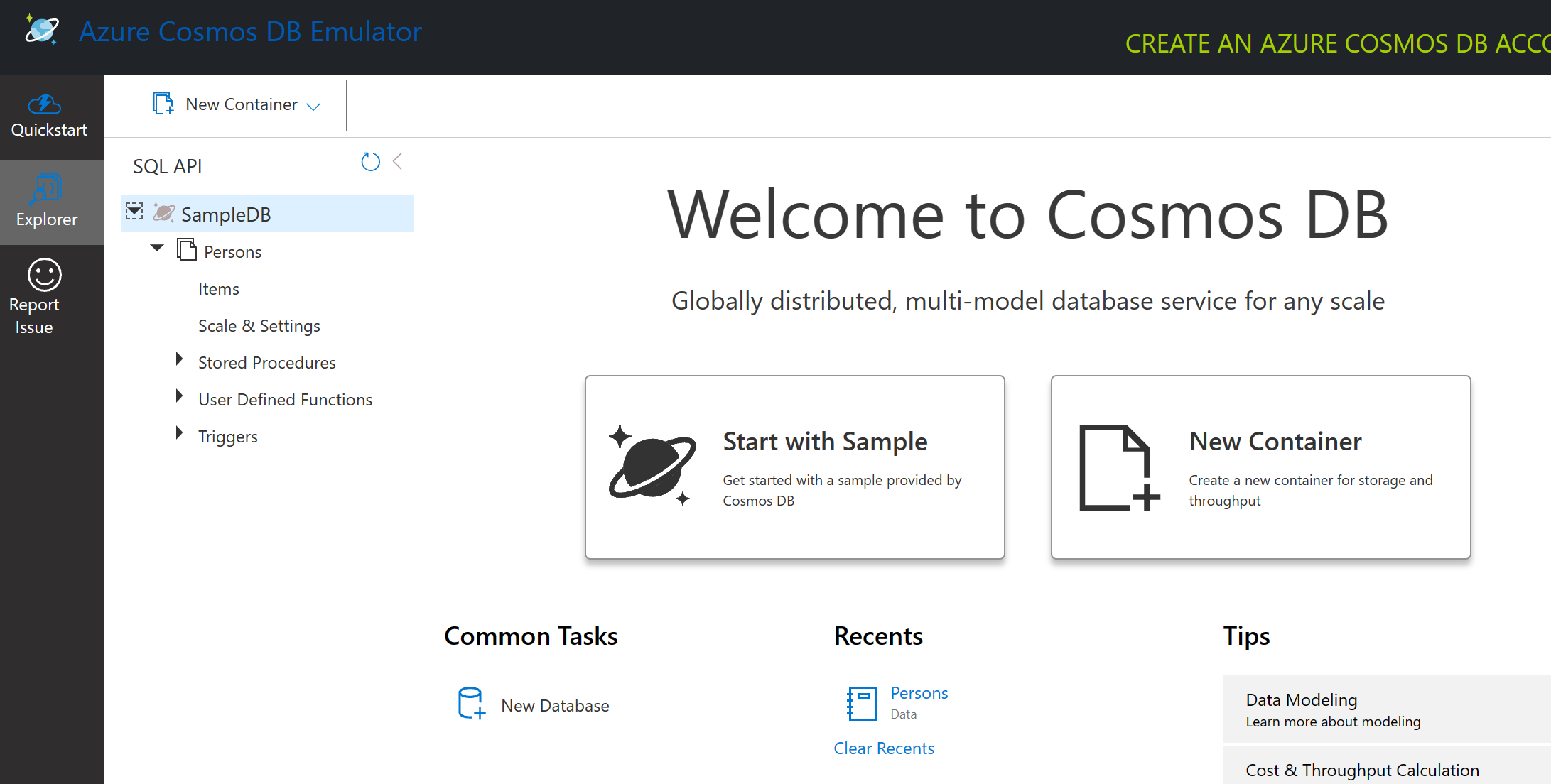
もし一緒に進めている場合は、「Start with Sample」をクリックしてSampleDBというサンプルデータベースを生成してください。SampleDBを展開すると、Personsというコンテナーが見つかります。コンテナーはアイテムのコレクションを保持しており、これがコンテナー内のドキュメントです。Itemsの下にある4つの個別のドキュメントを探索できます。
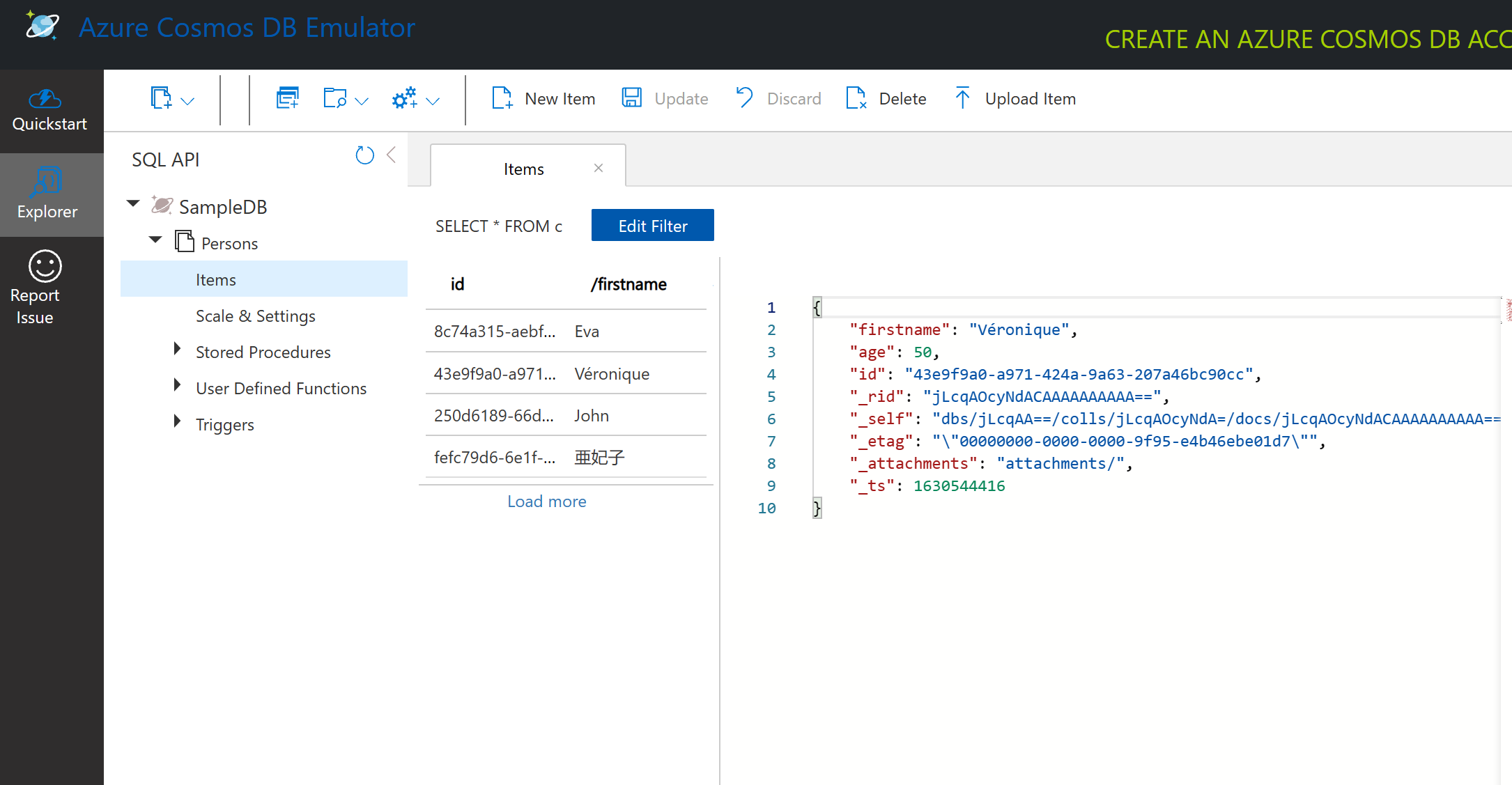
Cosmos DBエミュレーターを使ったドキュメントデータのクエリ
新しいSQLクエリボタン(左から2番目のボタン)をクリックすると、サンプルデータにクエリを実行できます。
SELECT * FROM c はコンテナー内のすべてのドキュメントを返します。where句を追加して、40歳未満の人を見つけてみましょう。
SELECT * FROM c where c.age < 40
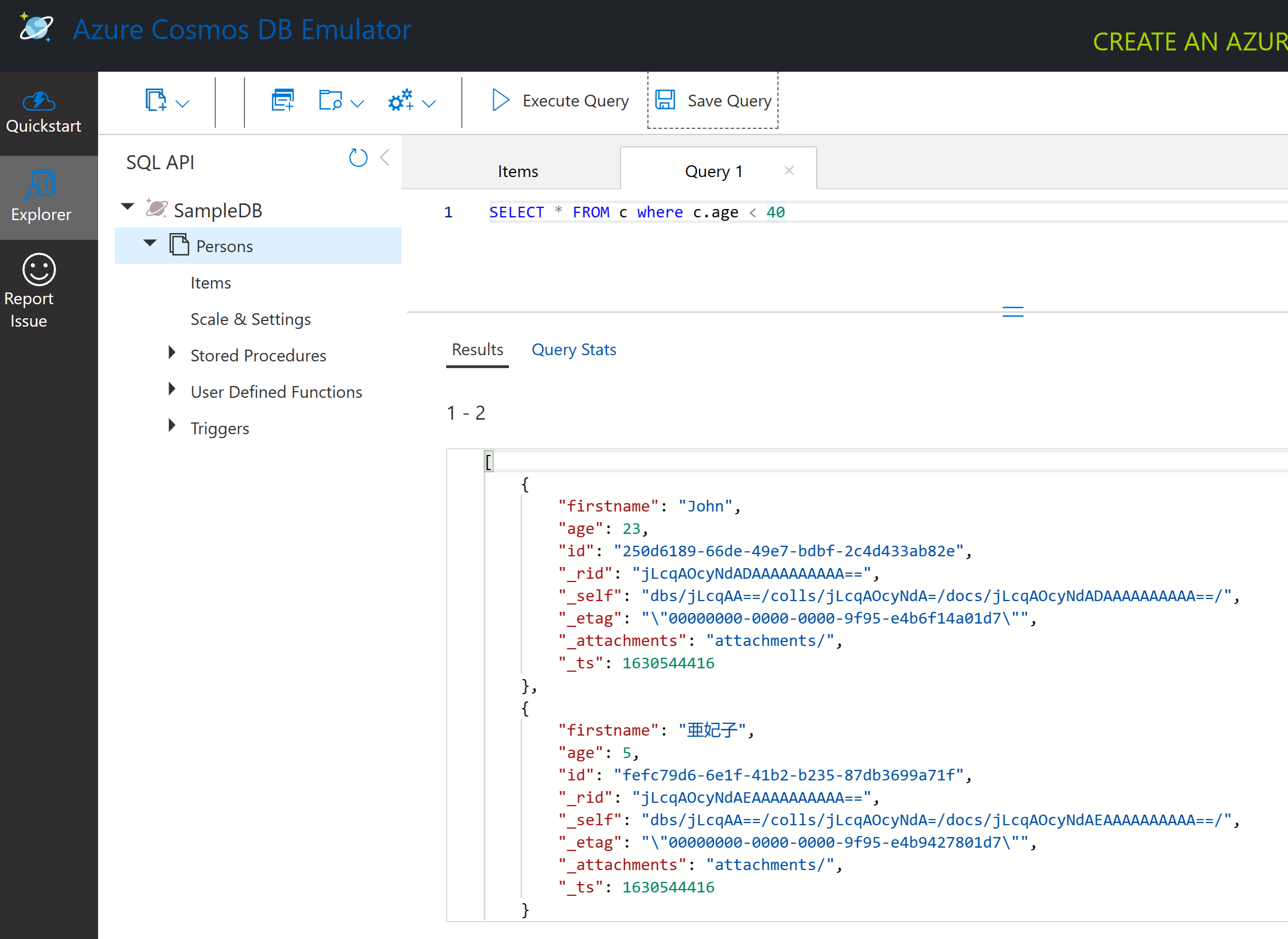
このクエリは2つのドキュメントを返します。それぞれのドキュメントのage値が40未満であることに注目してください。
JSONとドキュメント
JavaScript Object Notation (JSON) に詳しい方は、ドキュメントがJSONに似ていることに気付くでしょう。このディレクトリにはPersonsData.jsonというファイルがあり、エミュレーターのPersonsコンテナーにUpload Itemボタンを使ってアップロードできます。
ほとんどの場合、JSONデータを返すAPIは、ドキュメントデータベースに直接転送して保存することができます。以下は別のドキュメントで、MicrosoftのTwitterアカウントから取得したツイートを表しています。このデータはTwitter APIを使用して取得され、その後Cosmos DBに挿入されました。
{
"created_at": "2021-08-31T19:03:01.000Z",
"id": "1432780985872142341",
"text": "Blank slate. Like this tweet if you’ve ever painted in Microsoft Paint before. https://t.co/cFeEs8eOPK",
"_rid": "dhAmAIUsA4oHAAAAAAAAAA==",
"_self": "dbs/dhAmAA==/colls/dhAmAIUsA4o=/docs/dhAmAIUsA4oHAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f84-a0958ad901d7\"",
"_attachments": "attachments/",
"_ts": 1630537000
このドキュメントで注目すべきフィールドは、created_at、id、textです。
🚀 チャレンジ
TwitterData.jsonというファイルをSampleDBデータベースにアップロードできます。これを別のコンテナーに追加することをお勧めします。以下の手順で行えます:
- 右上の新しいコンテナーボタンをクリック
- 既存のデータベース(SampleDB)を選択し、コンテナーIDを作成
- パーティションキーを
/idに設定 - OKをクリック(このビューの他の情報は無視して構いません。これはローカルマシンで実行される小さなデータセットです)
- 新しいコンテナーを開き、
Upload ItemボタンでTwitter Dataファイルをアップロード
いくつかのSELECTクエリを実行して、textフィールドにMicrosoftが含まれているドキュメントを見つけてみてください。ヒント:LIKEキーワードを使用してみてください。
講義後クイズ
復習と自己学習
-
このレッスンではカバーしていないスプレッドシートの追加のフォーマットや機能があります。MicrosoftはExcelに関する豊富なドキュメントとビデオライブラリを提供していますので、さらに学びたい方はぜひご覧ください。
-
非リレーショナルデータの特性についての詳細は、このアーキテクチャドキュメントをご覧ください:非リレーショナルデータとNoSQL
-
Cosmos DBは、レッスンで紹介したさまざまなNoSQLタイプを保存できるクラウドベースの非リレーショナルデータベースです。このCosmos DB Microsoft Learnモジュールでこれらのタイプについてさらに学ぶことができます。
課題
免責事項:
この文書は、AI翻訳サービス Co-op Translator を使用して翻訳されています。正確性を期すよう努めておりますが、自動翻訳には誤りや不正確な表現が含まれる可能性があります。元の言語で記載された原文が正式な情報源とみなされるべきです。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の利用に起因する誤解や誤認について、当方は一切の責任を負いません。