18 KiB
Data Science u oblaku: Put "Azure ML SDK"
 |
|---|
| Data Science u oblaku: Azure ML SDK - Sketchnote by @nitya |
Sadržaj:
- Data Science u oblaku: Put "Azure ML SDK"
Pre-lecture kviz
1. Uvod
1.1 Što je Azure ML SDK?
Data znanstvenici i AI developeri koriste Azure Machine Learning SDK za izgradnju i pokretanje radnih tijekova strojnog učenja pomoću Azure Machine Learning usluge. Možete komunicirati s uslugom u bilo kojem Python okruženju, uključujući Jupyter Notebooks, Visual Studio Code ili vaš omiljeni Python IDE.
Ključna područja SDK-a uključuju:
- Istraživanje, pripremu i upravljanje životnim ciklusom vaših skupova podataka koji se koriste u eksperimentima strojnog učenja.
- Upravljanje resursima u oblaku za praćenje, zapisivanje i organizaciju vaših eksperimenata strojnog učenja.
- Treniranje modela lokalno ili korištenjem resursa u oblaku, uključujući treniranje modela ubrzano GPU-om.
- Korištenje automatiziranog strojnog učenja, koje prihvaća parametre konfiguracije i podatke za treniranje. Automatski iterira kroz algoritme i postavke hiperparametara kako bi pronašao najbolji model za predviđanja.
- Implementacija web usluga za pretvaranje vaših treniranih modela u RESTful usluge koje se mogu koristiti u bilo kojoj aplikaciji.
Više o Azure Machine Learning SDK-u
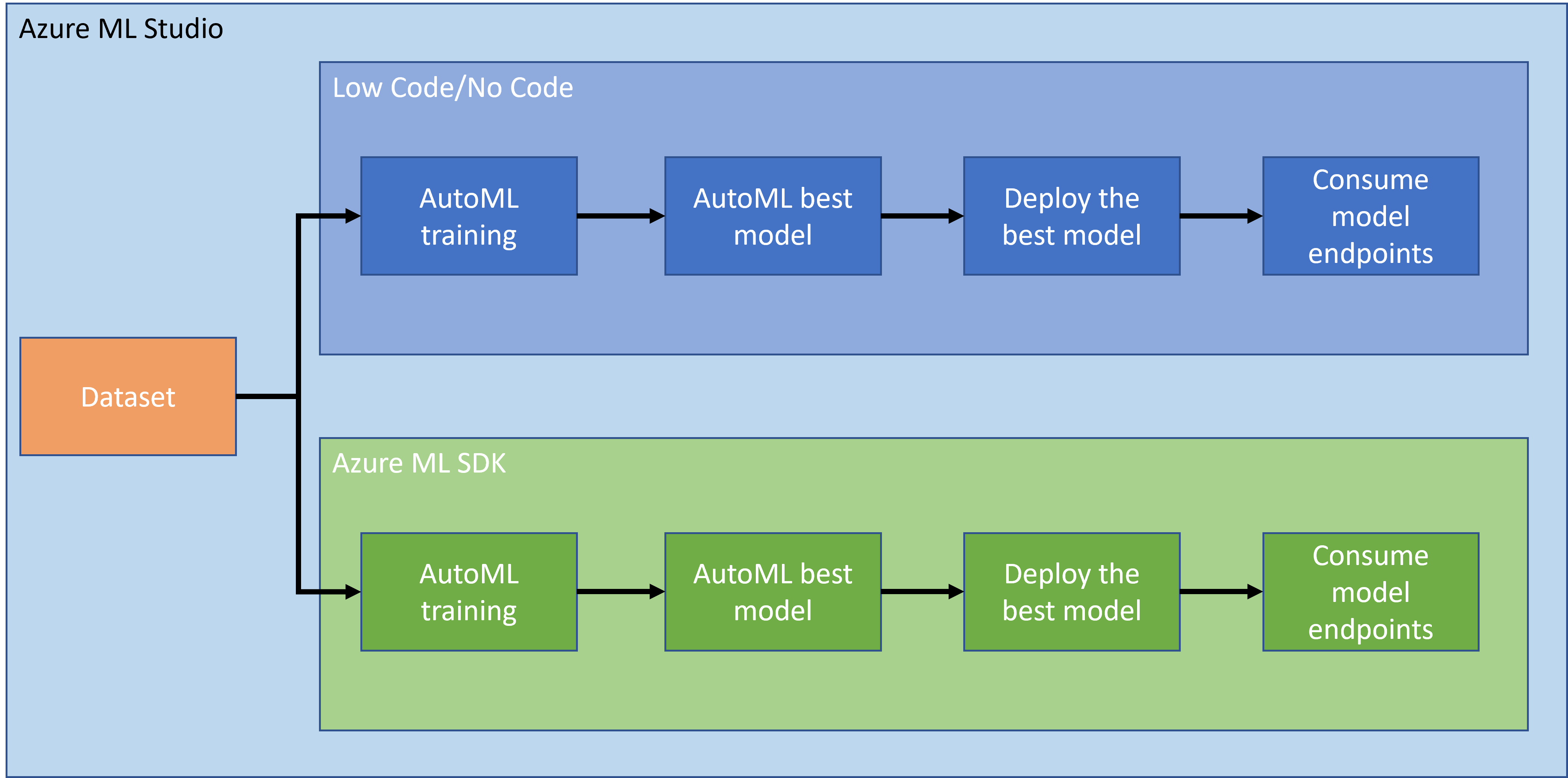
U prethodnoj lekciji, vidjeli smo kako trenirati, implementirati i koristiti model na način s malo ili bez koda. Koristili smo skup podataka o zatajenju srca za generiranje modela predviđanja zatajenja srca. U ovoj lekciji ćemo učiniti isto, ali koristeći Azure Machine Learning SDK.
1.2 Projekt predviđanja zatajenja srca i uvod u skup podataka
Pogledajte ovdje uvod u projekt predviđanja zatajenja srca i skup podataka.
2. Treniranje modela pomoću Azure ML SDK-a
2.1 Kreiranje Azure ML radnog prostora
Radi jednostavnosti, radit ćemo u jupyter bilježnici. To podrazumijeva da već imate radni prostor i računalni instance. Ako već imate radni prostor, možete odmah prijeći na odjeljak 2.3 Kreiranje bilježnice.
Ako ne, slijedite upute u odjeljku 2.1 Kreiranje Azure ML radnog prostora u prethodnoj lekciji za kreiranje radnog prostora.
2.2 Kreiranje računalnog instance
U Azure ML radnom prostoru koji smo ranije kreirali, idite na izbornik za računalne resurse i vidjet ćete različite dostupne računalne resurse.

Kreirajmo računalni instance za postavljanje jupyter bilježnice.
- Kliknite na gumb + New.
- Dajte ime svom računalnom instanceu.
- Odaberite opcije: CPU ili GPU, veličinu VM-a i broj jezgri.
- Kliknite na gumb Create.
Čestitamo, upravo ste kreirali računalni instance! Koristit ćemo ovaj računalni instance za kreiranje bilježnice u odjeljku Kreiranje bilježnica.
2.3 Učitavanje skupa podataka
Pogledajte prethodnu lekciju u odjeljku 2.3 Učitavanje skupa podataka ako još niste učitali skup podataka.
2.4 Kreiranje bilježnica
NAPOMENA: Za sljedeći korak možete kreirati novu bilježnicu od nule ili možete učitati bilježnicu koju smo kreirali u vašem Azure ML Studiju. Za učitavanje, jednostavno kliknite na izbornik "Notebook" i učitajte bilježnicu.
Bilježnice su vrlo važan dio procesa data znanosti. Mogu se koristiti za provođenje analize istraživačkih podataka (EDA), pozivanje računalnog klastera za treniranje modela, pozivanje klastera za inferenciju za implementaciju krajnje točke.
Za kreiranje bilježnice, trebamo računalni čvor koji poslužuje instancu jupyter bilježnice. Vratite se na Azure ML radni prostor i kliknite na Računalni instance. Na popisu računalnih instanci trebali biste vidjeti računalni instance koji smo ranije kreirali.
- U odjeljku Applications kliknite na opciju Jupyter.
- Označite okvir "Yes, I understand" i kliknite na gumb Continue.

- Ovo bi trebalo otvoriti novu karticu preglednika s vašom instancom jupyter bilježnice. Kliknite na gumb "New" za kreiranje bilježnice.

Sada kada imamo bilježnicu, možemo započeti treniranje modela pomoću Azure ML SDK-a.
2.5 Treniranje modela
Prije svega, ako ikada imate sumnju, pogledajte dokumentaciju Azure ML SDK-a. Sadrži sve potrebne informacije za razumijevanje modula koje ćemo vidjeti u ovoj lekciji.
2.5.1 Postavljanje radnog prostora, eksperimenta, računalnog klastera i skupa podataka
Trebate učitati workspace iz konfiguracijske datoteke koristeći sljedeći kod:
from azureml.core import Workspace
ws = Workspace.from_config()
Ovo vraća objekt tipa Workspace koji predstavlja radni prostor. Zatim trebate kreirati experiment koristeći sljedeći kod:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Za dobivanje ili kreiranje eksperimenta iz radnog prostora, zatražite eksperiment koristeći ime eksperimenta. Ime eksperimenta mora imati 3-36 znakova, početi slovom ili brojem i može sadržavati samo slova, brojeve, donje crte i crtice. Ako eksperiment nije pronađen u radnom prostoru, kreira se novi eksperiment.
Sada trebate kreirati računalni klaster za treniranje koristeći sljedeći kod. Imajte na umu da ovaj korak može potrajati nekoliko minuta.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Skup podataka možete dobiti iz radnog prostora koristeći ime skupa podataka na sljedeći način:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Konfiguracija AutoML-a i treniranje
Za postavljanje konfiguracije AutoML-a koristite AutoMLConfig klasu.
Kako je opisano u dokumentaciji, postoji mnogo parametara s kojima možete eksperimentirati. Za ovaj projekt koristit ćemo sljedeće parametre:
experiment_timeout_minutes: Maksimalno vrijeme (u minutama) koje je eksperimentu dopušteno da traje prije nego što se automatski zaustavi i rezultati automatski postanu dostupni.max_concurrent_iterations: Maksimalan broj istovremenih iteracija treniranja dopuštenih za eksperiment.primary_metric: Primarna metrika koja se koristi za određivanje statusa eksperimenta.compute_target: Cilj računalnog resursa Azure Machine Learning za pokretanje eksperimenta automatiziranog strojnog učenja.task: Vrsta zadatka koji se pokreće. Vrijednosti mogu biti 'classification', 'regression' ili 'forecasting' ovisno o vrsti problema automatiziranog strojnog učenja koji se rješava.training_data: Podaci za treniranje koji će se koristiti unutar eksperimenta. Trebali bi sadržavati značajke za treniranje i stupac oznaka (opcionalno stupac težina uzorka).label_column_name: Ime stupca oznaka.path: Puna putanja do mape projekta Azure Machine Learning.enable_early_stopping: Hoće li se omogućiti rano zaustavljanje ako se rezultat ne poboljšava u kratkom roku.featurization: Indikator za automatsko provođenje koraka featurizacije ili ne, ili korištenje prilagođene featurizacije.debug_log: Datoteka za zapisivanje informacija o otklanjanju pogrešaka.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Sada kada ste postavili konfiguraciju, možete trenirati model koristeći sljedeći kod. Ovaj korak može trajati do sat vremena, ovisno o veličini vašeg klastera.
remote_run = experiment.submit(automl_config)
Možete pokrenuti RunDetails widget za prikaz različitih eksperimenata.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Implementacija modela i korištenje krajnje točke pomoću Azure ML SDK-a
3.1 Spremanje najboljeg modela
remote_run je objekt tipa AutoMLRun. Ovaj objekt sadrži metodu get_output() koja vraća najbolju iteraciju i odgovarajući trenirani model.
best_run, fitted_model = remote_run.get_output()
Možete vidjeti parametre korištene za najbolji model jednostavnim ispisivanjem fitted_model i pregledati svojstva najboljeg modela koristeći metodu get_properties().
best_run.get_properties()
Sada registrirajte model koristeći metodu register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Implementacija modela
Nakon što je najbolji model spremljen, možemo ga implementirati koristeći klasu InferenceConfig. InferenceConfig predstavlja postavke konfiguracije za prilagođeno okruženje koje se koristi za implementaciju. Klasa AciWebservice predstavlja model strojnog učenja implementiran kao krajnja točka web usluge na Azure Container Instances. Implementirana usluga kreira se iz modela, skripte i povezanih datoteka. Rezultirajuća web usluga je uravnotežena HTTP krajnja točka s REST API-jem. Možete poslati podatke ovom API-ju i primiti predviđanje koje vraća model.
Model se implementira koristeći metodu deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Ovaj korak bi trebao trajati nekoliko minuta.
3.3 Korištenje krajnje točke
Krajnju točku koristite kreiranjem uzorka ulaznih podataka:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Zatim možete poslati ovaj ulaz svom modelu za predviđanje:
response = aci_service.run(input_data=test_sample)
response
Ovo bi trebalo prikazati '{"result": [false]}'. To znači da je unos pacijenta koji smo poslali na endpoint generirao predikciju false, što znači da ova osoba vjerojatno neće doživjeti srčani udar.
Čestitamo! Upravo ste iskoristili model koji je implementiran i treniran na Azure ML pomoću Azure ML SDK-a!
NOTE: Kada završite projekt, ne zaboravite obrisati sve resurse.
🚀 Izazov
Postoji mnogo drugih stvari koje možete raditi putem SDK-a, nažalost, ne možemo ih sve obraditi u ovoj lekciji. Ali dobra vijest je da vas učenje kako brzo pregledavati dokumentaciju SDK-a može daleko odvesti. Pogledajte dokumentaciju Azure ML SDK-a i pronađite klasu Pipeline koja vam omogućuje kreiranje cjevovoda. Cjevovod je zbirka koraka koji se mogu izvršiti kao tijek rada.
SAVJET: Idite na SDK dokumentaciju i upišite ključne riječi u traku za pretraživanje, poput "Pipeline". Trebali biste vidjeti klasu azureml.pipeline.core.Pipeline u rezultatima pretraživanja.
Post-lecture kviz
Pregled i samostalno učenje
U ovoj lekciji naučili ste kako trenirati, implementirati i koristiti model za predviđanje rizika od zatajenja srca pomoću Azure ML SDK-a u oblaku. Pogledajte ovu dokumentaciju za dodatne informacije o Azure ML SDK-u. Pokušajte kreirati vlastiti model pomoću Azure ML SDK-a.
Zadatak
Projekt iz Data Sciencea koristeći Azure ML SDK
Odricanje od odgovornosti:
Ovaj dokument je preveden pomoću AI usluge za prevođenje Co-op Translator. Iako nastojimo osigurati točnost, imajte na umu da automatski prijevodi mogu sadržavati pogreške ili netočnosti. Izvorni dokument na izvornom jeziku treba smatrati autoritativnim izvorom. Za ključne informacije preporučuje se profesionalni prijevod od strane ljudskog prevoditelja. Ne preuzimamo odgovornost za bilo kakve nesporazume ili pogrešne interpretacije koje proizlaze iz korištenja ovog prijevoda.