25 KiB
Travailler avec des données : Python et la bibliothèque Pandas
 |
|---|
| Travailler avec Python - Sketchnote par @nitya |

Bien que les bases de données offrent des moyens très efficaces de stocker et d'interroger des données à l'aide de langages de requête, la méthode la plus flexible pour traiter les données reste d'écrire son propre programme pour les manipuler. Dans de nombreux cas, effectuer une requête dans une base de données serait plus efficace. Cependant, dans certains cas où un traitement de données plus complexe est nécessaire, cela ne peut pas être facilement réalisé avec SQL.
Le traitement des données peut être programmé dans n'importe quel langage, mais certains langages sont plus adaptés au travail avec les données. Les data scientists préfèrent généralement l'un des langages suivants :
- Python, un langage de programmation généraliste, souvent considéré comme l'une des meilleures options pour les débutants grâce à sa simplicité. Python dispose de nombreuses bibliothèques supplémentaires qui peuvent vous aider à résoudre de nombreux problèmes pratiques, comme extraire vos données d'une archive ZIP ou convertir une image en niveaux de gris. En plus de la science des données, Python est également souvent utilisé pour le développement web.
- R est un outil traditionnel développé spécifiquement pour le traitement statistique des données. Il contient également un vaste dépôt de bibliothèques (CRAN), ce qui en fait un bon choix pour le traitement des données. Cependant, R n'est pas un langage de programmation généraliste et est rarement utilisé en dehors du domaine de la science des données.
- Julia est un autre langage développé spécifiquement pour la science des données. Il est conçu pour offrir de meilleures performances que Python, ce qui en fait un excellent outil pour les expérimentations scientifiques.
Dans cette leçon, nous nous concentrerons sur l'utilisation de Python pour un traitement simple des données. Nous supposerons une familiarité de base avec le langage. Si vous souhaitez une introduction plus approfondie à Python, vous pouvez consulter l'une des ressources suivantes :
- Apprenez Python de manière ludique avec Turtle Graphics et les fractales - Un cours d'introduction rapide à Python sur GitHub
- Faites vos premiers pas avec Python - Parcours d'apprentissage sur Microsoft Learn
Les données peuvent se présenter sous de nombreuses formes. Dans cette leçon, nous examinerons trois formes de données : les données tabulaires, le texte et les images.
Nous nous concentrerons sur quelques exemples de traitement de données, au lieu de vous donner un aperçu complet de toutes les bibliothèques associées. Cela vous permettra de comprendre les possibilités principales et de savoir où chercher des solutions à vos problèmes lorsque vous en aurez besoin.
Le conseil le plus utile : Lorsque vous devez effectuer une opération sur des données que vous ne savez pas comment réaliser, essayez de chercher sur Internet. Stackoverflow contient généralement de nombreux exemples de code utiles en Python pour de nombreuses tâches typiques.
Quiz pré-lecture
Données tabulaires et DataFrames
Vous avez déjà rencontré des données tabulaires lorsque nous avons parlé des bases de données relationnelles. Lorsque vous avez beaucoup de données contenues dans de nombreuses tables liées, il est logique d'utiliser SQL pour les manipuler. Cependant, il existe de nombreux cas où nous avons une table de données et où nous devons obtenir une compréhension ou des informations sur ces données, comme leur distribution, les corrélations entre les valeurs, etc. En science des données, il y a de nombreux cas où nous devons effectuer des transformations des données originales, suivies de visualisations. Ces deux étapes peuvent être facilement réalisées avec Python.
Il existe deux bibliothèques Python particulièrement utiles pour travailler avec des données tabulaires :
- Pandas permet de manipuler ce qu'on appelle des DataFrames, qui sont analogues aux tables relationnelles. Vous pouvez avoir des colonnes nommées et effectuer différentes opérations sur les lignes, les colonnes et les DataFrames en général.
- Numpy est une bibliothèque pour travailler avec des tenseurs, c'est-à-dire des tableaux multidimensionnels. Un tableau contient des valeurs d'un même type sous-jacent, il est plus simple qu'un DataFrame, mais offre davantage d'opérations mathématiques et génère moins de surcharge.
Il existe également quelques autres bibliothèques que vous devriez connaître :
- Matplotlib est une bibliothèque utilisée pour la visualisation des données et la création de graphiques.
- SciPy est une bibliothèque contenant des fonctions scientifiques supplémentaires. Nous avons déjà rencontré cette bibliothèque en parlant de probabilité et de statistiques.
Voici un exemple de code que vous utiliseriez typiquement pour importer ces bibliothèques au début de votre programme Python :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas repose sur quelques concepts de base.
Series
Une Series est une séquence de valeurs, similaire à une liste ou un tableau numpy. La principale différence est qu'une série possède également un index, et lorsque nous effectuons des opérations sur les séries (par exemple, les additionner), l'index est pris en compte. L'index peut être aussi simple qu'un numéro de ligne entier (c'est l'index utilisé par défaut lors de la création d'une série à partir d'une liste ou d'un tableau), ou il peut avoir une structure complexe, comme un intervalle de dates.
Note : Il y a du code introductif sur Pandas dans le notebook associé
notebook.ipynb. Nous ne présentons ici que quelques exemples, mais n'hésitez pas à consulter le notebook complet.
Prenons un exemple : nous voulons analyser les ventes de notre stand de glaces. Générons une série de chiffres de ventes (nombre d'articles vendus chaque jour) pour une certaine période :
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
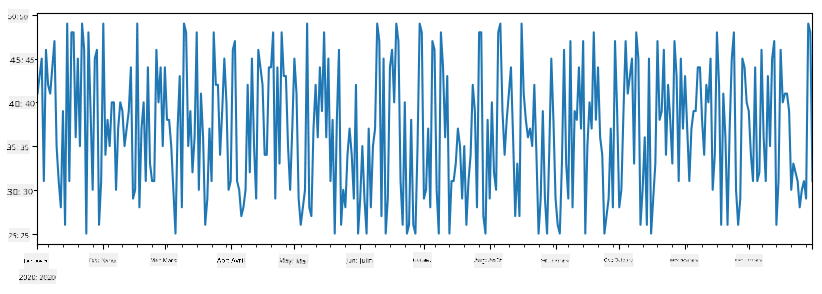
Supposons maintenant que chaque semaine, nous organisons une fête pour nos amis et que nous prenons 10 packs de glaces supplémentaires pour la fête. Nous pouvons créer une autre série, indexée par semaine, pour le démontrer :
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Lorsque nous additionnons deux séries, nous obtenons le total :
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
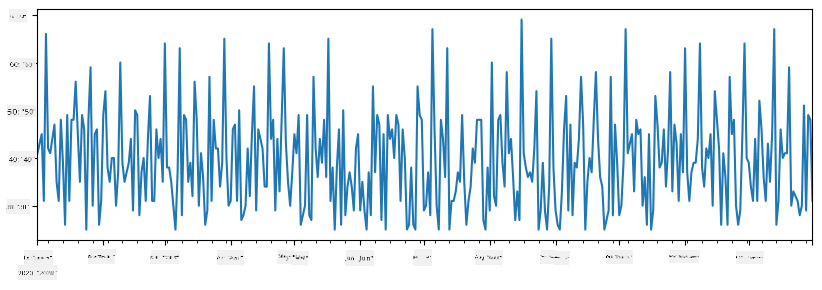
Note : Nous n'utilisons pas la syntaxe simple
total_items+additional_items. Si nous l'avions fait, nous aurions obtenu de nombreuses valeursNaN(Not a Number) dans la série résultante. Cela est dû au fait qu'il manque des valeurs pour certains points d'index dans la sérieadditional_items, et additionnerNaNà quoi que ce soit donneNaN. Ainsi, nous devons spécifier le paramètrefill_valuelors de l'addition.
Avec les séries temporelles, nous pouvons également reéchantillonner la série avec différents intervalles de temps. Par exemple, supposons que nous voulons calculer le volume moyen des ventes mensuelles. Nous pouvons utiliser le code suivant :
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
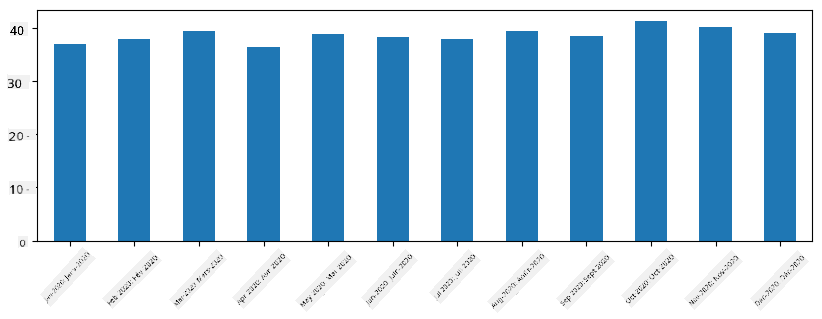
DataFrame
Un DataFrame est essentiellement une collection de séries ayant le même index. Nous pouvons combiner plusieurs séries pour créer un DataFrame :
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Cela créera une table horizontale comme celle-ci :
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Nous pouvons également utiliser des séries comme colonnes et spécifier les noms des colonnes à l'aide d'un dictionnaire :
df = pd.DataFrame({ 'A' : a, 'B' : b })
Cela nous donnera une table comme celle-ci :
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Note : Nous pouvons également obtenir cette disposition de table en transposant la table précédente, par exemple en écrivant
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Ici, .T signifie l'opération de transposition du DataFrame, c'est-à-dire l'inversion des lignes et des colonnes, et l'opération rename nous permet de renommer les colonnes pour correspondre à l'exemple précédent.
Voici quelques-unes des opérations les plus importantes que nous pouvons effectuer sur les DataFrames :
Sélection de colonnes. Nous pouvons sélectionner des colonnes individuelles en écrivant df['A'] - cette opération renvoie une série. Nous pouvons également sélectionner un sous-ensemble de colonnes dans un autre DataFrame en écrivant df[['B','A']] - cela renvoie un autre DataFrame.
Filtrage de certaines lignes selon des critères. Par exemple, pour ne conserver que les lignes où la colonne A est supérieure à 5, nous pouvons écrire df[df['A']>5].
Note : Le fonctionnement du filtrage est le suivant. L'expression
df['A']<5renvoie une série booléenne, qui indique si l'expression estTrueouFalsepour chaque élément de la série originaledf['A']. Lorsqu'une série booléenne est utilisée comme index, elle renvoie un sous-ensemble de lignes dans le DataFrame. Ainsi, il n'est pas possible d'utiliser une expression booléenne Python arbitraire, par exemple, écriredf[df['A']>5 and df['A']<7]serait incorrect. À la place, vous devez utiliser l'opérateur spécial&sur les séries booléennes, en écrivantdf[(df['A']>5) & (df['A']<7)](les parenthèses sont importantes ici).
Création de nouvelles colonnes calculables. Nous pouvons facilement créer de nouvelles colonnes calculables pour notre DataFrame en utilisant une expression intuitive comme celle-ci :
df['DivA'] = df['A']-df['A'].mean()
Cet exemple calcule la divergence de A par rapport à sa valeur moyenne. Ce qui se passe réellement ici, c'est que nous calculons une série, puis nous l'assignons au côté gauche, créant une autre colonne. Ainsi, nous ne pouvons pas utiliser d'opérations incompatibles avec les séries, par exemple, le code ci-dessous est incorrect :
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Ce dernier exemple, bien que syntaxiquement correct, donne un mauvais résultat, car il assigne la longueur de la série B à toutes les valeurs de la colonne, et non la longueur des éléments individuels comme nous l'avions prévu.
Si nous devons calculer des expressions complexes comme celle-ci, nous pouvons utiliser la fonction apply. Le dernier exemple peut être écrit comme suit :
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Après les opérations ci-dessus, nous obtiendrons le DataFrame suivant :
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Sélection de lignes par numéro peut être effectuée à l'aide de la construction iloc. Par exemple, pour sélectionner les 5 premières lignes du DataFrame :
df.iloc[:5]
Regroupement est souvent utilisé pour obtenir un résultat similaire aux tableaux croisés dynamiques dans Excel. Supposons que nous souhaitons calculer la valeur moyenne de la colonne A pour chaque nombre donné de LenB. Nous pouvons alors regrouper notre DataFrame par LenB et appeler mean :
df.groupby(by='LenB')[['A','DivA']].mean()
Si nous devons calculer la moyenne et le nombre d'éléments dans le groupe, nous pouvons utiliser la fonction aggregate plus complexe :
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Cela nous donne le tableau suivant :
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Obtenir des données
Nous avons vu à quel point il est facile de construire des Series et des DataFrames à partir d'objets Python. Cependant, les données se présentent généralement sous forme de fichier texte ou de tableau Excel. Heureusement, Pandas nous offre un moyen simple de charger des données depuis le disque. Par exemple, lire un fichier CSV est aussi simple que cela :
df = pd.read_csv('file.csv')
Nous verrons plus d'exemples de chargement de données, y compris leur récupération depuis des sites web externes, dans la section "Challenge".
Impression et Visualisation
Un Data Scientist doit souvent explorer les données, il est donc important de pouvoir les visualiser. Lorsque le DataFrame est volumineux, il est souvent utile de vérifier que tout fonctionne correctement en affichant les premières lignes. Cela peut être fait en appelant df.head(). Si vous l'exécutez depuis Jupyter Notebook, cela affichera le DataFrame sous une forme tabulaire agréable.
Nous avons également vu l'utilisation de la fonction plot pour visualiser certaines colonnes. Bien que plot soit très utile pour de nombreuses tâches et prenne en charge différents types de graphiques via le paramètre kind=, vous pouvez toujours utiliser la bibliothèque matplotlib brute pour tracer quelque chose de plus complexe. Nous couvrirons la visualisation des données en détail dans des leçons de cours séparées.
Cette vue d'ensemble couvre les concepts les plus importants de Pandas, mais la bibliothèque est très riche, et il n'y a pas de limite à ce que vous pouvez faire avec elle ! Appliquons maintenant ces connaissances pour résoudre un problème spécifique.
🚀 Challenge 1 : Analyser la propagation du COVID
Le premier problème sur lequel nous allons nous concentrer est la modélisation de la propagation de l'épidémie de COVID-19. Pour ce faire, nous utiliserons les données sur le nombre de personnes infectées dans différents pays, fournies par le Center for Systems Science and Engineering (CSSE) de l'Université Johns Hopkins. Le jeu de données est disponible dans ce dépôt GitHub.
Puisque nous voulons démontrer comment traiter les données, nous vous invitons à ouvrir notebook-covidspread.ipynb et à le lire de haut en bas. Vous pouvez également exécuter les cellules et relever certains défis que nous avons laissés pour vous à la fin.
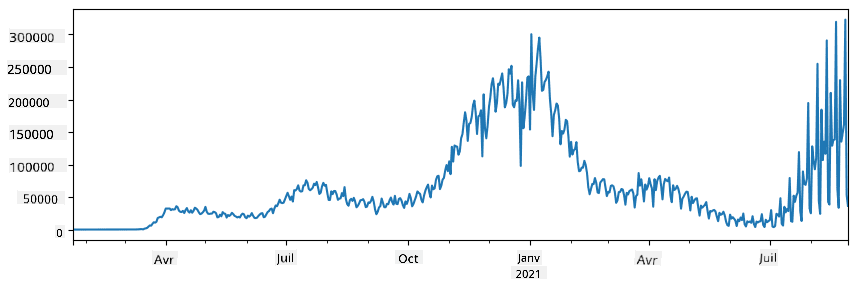
Si vous ne savez pas comment exécuter du code dans Jupyter Notebook, consultez cet article.
Travailler avec des données non structurées
Bien que les données soient souvent sous forme tabulaire, dans certains cas, nous devons traiter des données moins structurées, comme du texte ou des images. Dans ce cas, pour appliquer les techniques de traitement des données que nous avons vues précédemment, nous devons extraire des données structurées. Voici quelques exemples :
- Extraire des mots-clés d'un texte et voir à quelle fréquence ces mots-clés apparaissent
- Utiliser des réseaux neuronaux pour extraire des informations sur les objets dans une image
- Obtenir des informations sur les émotions des personnes à partir d'un flux vidéo
🚀 Challenge 2 : Analyser les articles sur le COVID
Dans ce défi, nous continuerons avec le sujet de la pandémie de COVID et nous concentrerons sur le traitement des articles scientifiques sur le sujet. Il existe un jeu de données CORD-19 contenant plus de 7000 articles (au moment de la rédaction) sur le COVID, disponibles avec des métadonnées et des résumés (et pour environ la moitié d'entre eux, le texte complet est également fourni).
Un exemple complet d'analyse de ce jeu de données en utilisant le service cognitif Text Analytics for Health est décrit dans ce billet de blog. Nous discuterons d'une version simplifiée de cette analyse.
NOTE : Nous ne fournissons pas une copie du jeu de données dans ce dépôt. Vous devrez peut-être d'abord télécharger le fichier
metadata.csvdepuis ce jeu de données sur Kaggle. Une inscription sur Kaggle peut être requise. Vous pouvez également télécharger le jeu de données sans inscription ici, mais cela inclura tous les textes complets en plus du fichier de métadonnées.
Ouvrez notebook-papers.ipynb et lisez-le de haut en bas. Vous pouvez également exécuter les cellules et relever certains défis que nous avons laissés pour vous à la fin.
Traitement des données d'image
Récemment, des modèles d'IA très puissants ont été développés pour comprendre les images. De nombreuses tâches peuvent être résolues en utilisant des réseaux neuronaux pré-entraînés ou des services cloud. Voici quelques exemples :
- Classification d'images, qui peut vous aider à catégoriser une image dans l'une des classes prédéfinies. Vous pouvez facilement entraîner vos propres classificateurs d'images en utilisant des services comme Custom Vision
- Détection d'objets pour détecter différents objets dans une image. Des services comme computer vision peuvent détecter un certain nombre d'objets courants, et vous pouvez entraîner un modèle Custom Vision pour détecter des objets spécifiques d'intérêt.
- Détection de visages, y compris l'âge, le genre et les émotions. Cela peut être fait via Face API.
Tous ces services cloud peuvent être appelés en utilisant les SDK Python, et peuvent donc être facilement intégrés dans votre flux de travail d'exploration de données.
Voici quelques exemples d'exploration de données à partir de sources d'images :
- Dans le billet de blog Comment apprendre la science des données sans coder, nous explorons les photos Instagram, en essayant de comprendre ce qui pousse les gens à donner plus de "likes" à une photo. Nous extrayons d'abord autant d'informations que possible des images en utilisant computer vision, puis nous utilisons Azure Machine Learning AutoML pour construire un modèle interprétable.
- Dans l'atelier sur les études faciales, nous utilisons Face API pour extraire les émotions des personnes sur des photographies d'événements, afin de tenter de comprendre ce qui rend les gens heureux.
Conclusion
Que vous disposiez déjà de données structurées ou non structurées, avec Python, vous pouvez effectuer toutes les étapes liées au traitement et à la compréhension des données. C'est probablement le moyen le plus flexible de traiter les données, et c'est la raison pour laquelle la majorité des data scientists utilisent Python comme principal outil. Apprendre Python en profondeur est probablement une bonne idée si vous êtes sérieux dans votre parcours en science des données !
Quiz post-lecture
Révision et Auto-apprentissage
Livres
Ressources en ligne
- Tutoriel officiel 10 minutes pour Pandas
- Documentation sur la visualisation avec Pandas
Apprendre Python
- Apprenez Python de manière ludique avec Turtle Graphics et Fractals
- Faites vos premiers pas avec Python sur Microsoft Learn
Devoir
Effectuez une étude de données plus détaillée pour les défis ci-dessus
Crédits
Cette leçon a été rédigée avec ♥️ par Dmitry Soshnikov
Avertissement :
Ce document a été traduit à l'aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d'assurer l'exactitude, veuillez noter que les traductions automatisées peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d'origine doit être considéré comme la source faisant autorité. Pour des informations critiques, il est recommandé de recourir à une traduction professionnelle réalisée par un humain. Nous déclinons toute responsabilité en cas de malentendus ou d'interprétations erronées résultant de l'utilisation de cette traduction.