2.7 KiB
Pilvilaskenta ja Data Science

Kuva: Jelleke Vanooteghem palvelusta Unsplash
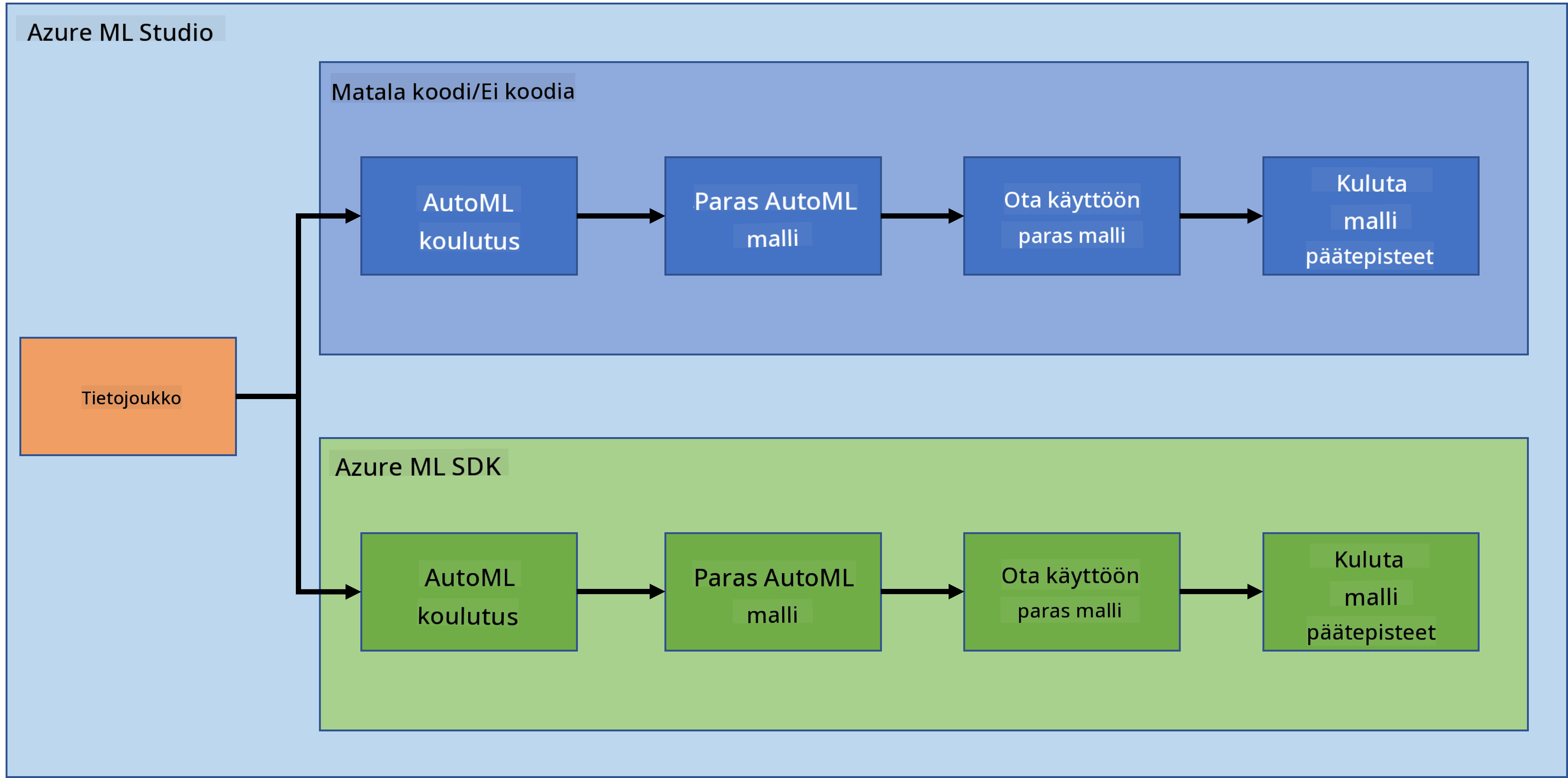
Kun käsitellään suuria datamääriä data science -projektissa, pilvilaskenta voi olla todellinen pelin muuttaja. Seuraavien kolmen oppitunnin aikana tutustumme siihen, mitä pilvilaskenta on ja miksi se voi olla erittäin hyödyllistä. Lisäksi tutkimme sydämen vajaatoimintaa koskevaa datasettiä ja rakennamme mallin, joka auttaa arvioimaan sydämen vajaatoiminnan todennäköisyyttä. Käytämme pilvilaskennan voimaa mallin kouluttamiseen, käyttöönottoon ja hyödyntämiseen kahdella eri tavalla: ensimmäinen tapa hyödyntää pelkästään käyttöliittymää Low code/No code -tyylillä, ja toinen tapa käyttää Azure Machine Learning Software Developer Kit (Azure ML SDK) -työkalua.
Aiheet
- Miksi käyttää pilvilaskentaa data science -projekteissa?
- Data Science pilvessä: "Low code/No code" -lähestymistapa
- Data Science pilvessä: "Azure ML SDK" -lähestymistapa
Tekijät
Nämä oppitunnit on kirjoitettu ☁️ ja 💕 avulla Maud Levy ja Tiffany Souterre.
Sydämen vajaatoiminnan ennustamiseen liittyvän projektin data on peräisin Larxel palvelusta Kaggle. Data on lisensoitu Attribution 4.0 International (CC BY 4.0).
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäinen asiakirja sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa väärinkäsityksistä tai virhetulkinnoista, jotka johtuvat tämän käännöksen käytöstä.