11 KiB
Einführung in den Lebenszyklus der Datenwissenschaft
 |
|---|
| Einführung in den Lebenszyklus der Datenwissenschaft - Sketchnote von @nitya |
Quiz vor der Vorlesung
An diesem Punkt haben Sie wahrscheinlich erkannt, dass Datenwissenschaft ein Prozess ist. Dieser Prozess kann in fünf Phasen unterteilt werden:
- Erfassung
- Verarbeitung
- Analyse
- Kommunikation
- Wartung
Diese Lektion konzentriert sich auf drei Teile des Lebenszyklus: Erfassung, Verarbeitung und Wartung.
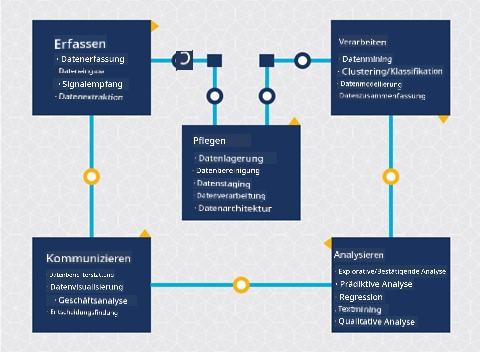
Foto von Berkeley School of Information
Erfassung
Die erste Phase des Lebenszyklus ist sehr wichtig, da die nächsten Phasen davon abhängen. Sie besteht praktisch aus zwei Phasen, die zu einer zusammengefasst sind: das Erfassen der Daten und das Definieren des Zwecks und der Probleme, die angegangen werden müssen.
Das Definieren der Projektziele erfordert ein tieferes Verständnis des Problems oder der Fragestellung. Zunächst müssen wir diejenigen identifizieren und einbeziehen, deren Problem gelöst werden soll. Dies können Stakeholder in einem Unternehmen oder Sponsoren des Projekts sein, die dabei helfen können, zu bestimmen, wer oder was von diesem Projekt profitieren wird, sowie was und warum es benötigt wird. Ein gut definiertes Ziel sollte messbar und quantifizierbar sein, um ein akzeptables Ergebnis zu definieren.
Fragen, die ein Datenwissenschaftler stellen könnte:
- Wurde dieses Problem schon einmal angegangen? Was wurde entdeckt?
- Ist der Zweck und das Ziel allen Beteiligten klar?
- Gibt es Unklarheiten, und wie können diese reduziert werden?
- Welche Einschränkungen gibt es?
- Wie könnte das Endergebnis aussehen?
- Wie viele Ressourcen (Zeit, Personal, Rechenleistung) stehen zur Verfügung?
Als Nächstes geht es darum, die benötigten Daten zu identifizieren, zu sammeln und schließlich zu untersuchen, um die definierten Ziele zu erreichen. In diesem Schritt der Datenerfassung müssen Datenwissenschaftler auch die Menge und Qualität der Daten bewerten. Dies erfordert eine gewisse Datenexploration, um sicherzustellen, dass die erfassten Daten das Erreichen des gewünschten Ergebnisses unterstützen.
Fragen, die ein Datenwissenschaftler zu den Daten stellen könnte:
- Welche Daten stehen mir bereits zur Verfügung?
- Wem gehören diese Daten?
- Welche Datenschutzbedenken gibt es?
- Habe ich genug Daten, um dieses Problem zu lösen?
- Sind die Daten für dieses Problem von ausreichender Qualität?
- Sollte ich, falls ich durch diese Daten zusätzliche Informationen entdecke, die Ziele ändern oder neu definieren?
Verarbeitung
Die Verarbeitungsphase des Lebenszyklus konzentriert sich darauf, Muster in den Daten zu entdecken sowie Modelle zu erstellen. Einige Techniken, die in der Verarbeitungsphase verwendet werden, erfordern statistische Methoden, um die Muster aufzudecken. Normalerweise wäre dies eine mühsame Aufgabe für einen Menschen bei einem großen Datensatz, daher wird auf Computer zurückgegriffen, um den Prozess zu beschleunigen. In dieser Phase überschneiden sich Datenwissenschaft und maschinelles Lernen. Wie Sie in der ersten Lektion gelernt haben, ist maschinelles Lernen der Prozess des Erstellens von Modellen, um die Daten zu verstehen. Modelle sind eine Darstellung der Beziehung zwischen Variablen in den Daten, die dabei helfen, Ergebnisse vorherzusagen.
Gängige Techniken, die in dieser Phase verwendet werden, werden im ML for Beginners-Lehrplan behandelt. Folgen Sie den Links, um mehr darüber zu erfahren:
- Klassifikation: Daten in Kategorien organisieren, um sie effizienter zu nutzen.
- Clustering: Daten in ähnliche Gruppen einteilen.
- Regression: Beziehungen zwischen Variablen bestimmen, um Werte vorherzusagen oder zu prognostizieren.
Wartung
Im Diagramm des Lebenszyklus haben Sie vielleicht bemerkt, dass die Wartung zwischen Erfassung und Verarbeitung liegt. Wartung ist ein fortlaufender Prozess des Verwalten, Speicherns und Sicherstellens der Daten während des gesamten Projektverlaufs und sollte während des gesamten Projekts berücksichtigt werden.
Daten speichern
Überlegungen dazu, wie und wo die Daten gespeichert werden, können die Kosten der Speicherung sowie die Leistung beeinflussen, wie schnell auf die Daten zugegriffen werden kann. Solche Entscheidungen werden wahrscheinlich nicht allein von einem Datenwissenschaftler getroffen, aber sie könnten Entscheidungen darüber treffen, wie sie mit den Daten arbeiten, basierend darauf, wie diese gespeichert sind.
Hier sind einige Aspekte moderner Datenspeichersysteme, die diese Entscheidungen beeinflussen können:
On-Premise vs. Off-Premise vs. Public oder Private Cloud
On-Premise bezieht sich auf das Hosten und Verwalten der Daten auf eigener Hardware, wie z. B. einem Server mit Festplatten, die die Daten speichern, während Off-Premise auf Hardware zurückgreift, die einem nicht gehört, wie z. B. ein Rechenzentrum. Die Public Cloud ist eine beliebte Wahl für die Speicherung von Daten, die kein Wissen darüber erfordert, wie oder wo genau die Daten gespeichert sind. Public bezieht sich auf eine einheitliche zugrunde liegende Infrastruktur, die von allen Nutzern der Cloud geteilt wird. Einige Organisationen haben strenge Sicherheitsrichtlinien, die verlangen, dass sie vollständigen Zugriff auf die Hardware haben, auf der die Daten gehostet werden, und greifen auf eine Private Cloud zurück, die eigene Cloud-Dienste bereitstellt. Mehr über Daten in der Cloud erfahren Sie in späteren Lektionen.
Cold vs. Hot Data
Beim Trainieren Ihrer Modelle benötigen Sie möglicherweise mehr Trainingsdaten. Wenn Sie mit Ihrem Modell zufrieden sind, werden weitere Daten eintreffen, damit das Modell seinen Zweck erfüllen kann. In jedem Fall steigen die Kosten für die Speicherung und den Zugriff auf Daten, je mehr davon angesammelt wird. Das Trennen von selten genutzten Daten, bekannt als Cold Data, von häufig genutzten Hot Data kann eine günstigere Option für die Datenspeicherung durch Hardware- oder Softwaredienste sein. Wenn auf Cold Data zugegriffen werden muss, kann es etwas länger dauern, diese im Vergleich zu Hot Data abzurufen.
Daten verwalten
Während Sie mit Daten arbeiten, stellen Sie möglicherweise fest, dass einige der Daten bereinigt werden müssen, indem einige der in der Lektion über Datenvorbereitung behandelten Techniken angewendet werden, um genaue Modelle zu erstellen. Wenn neue Daten eintreffen, müssen dieselben Anwendungen angewendet werden, um die Konsistenz der Qualität aufrechtzuerhalten. Einige Projekte beinhalten die Verwendung eines automatisierten Tools zur Bereinigung, Aggregation und Komprimierung, bevor die Daten an ihren endgültigen Speicherort verschoben werden. Azure Data Factory ist ein Beispiel für eines dieser Tools.
Daten sichern
Eines der Hauptziele der Datensicherung ist sicherzustellen, dass diejenigen, die mit den Daten arbeiten, die Kontrolle darüber haben, was gesammelt wird und in welchem Kontext es verwendet wird. Die Sicherung von Daten umfasst die Einschränkung des Zugriffs auf diejenigen, die ihn benötigen, die Einhaltung lokaler Gesetze und Vorschriften sowie die Wahrung ethischer Standards, wie in der Ethik-Lektion behandelt.
Hier sind einige Maßnahmen, die ein Team mit Blick auf die Sicherheit ergreifen könnte:
- Sicherstellen, dass alle Daten verschlüsselt sind
- Kunden Informationen darüber bereitstellen, wie ihre Daten verwendet werden
- Datenzugriff für Personen entfernen, die das Projekt verlassen haben
- Nur bestimmten Projektmitgliedern erlauben, die Daten zu ändern
🚀 Herausforderung
Es gibt viele Versionen des Lebenszyklus der Datenwissenschaft, bei denen jeder Schritt unterschiedliche Namen und eine unterschiedliche Anzahl von Phasen haben kann, aber die gleichen in dieser Lektion erwähnten Prozesse enthalten.
Erforschen Sie den Team Data Science Process Lifecycle und den Cross-industry standard process for data mining. Nennen Sie 3 Gemeinsamkeiten und Unterschiede zwischen den beiden.
| Team Data Science Process (TDSP) | Cross-industry standard process for data mining (CRISP-DM) |
|---|---|
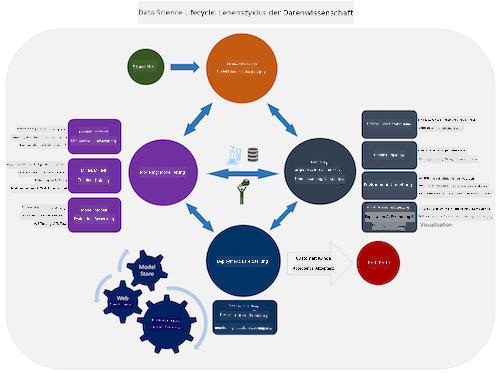 |
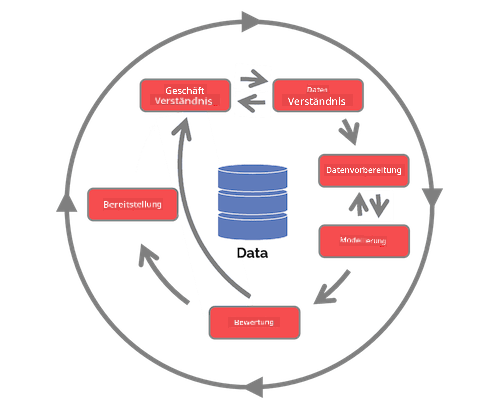 |
| Bild von Microsoft | Bild von Data Science Process Alliance |
Quiz nach der Vorlesung
Rückblick & Selbststudium
Die Anwendung des Lebenszyklus der Datenwissenschaft umfasst mehrere Rollen und Aufgaben, wobei sich einige auf bestimmte Teile jeder Phase konzentrieren können. Der Team Data Science Process bietet einige Ressourcen, die die Arten von Rollen und Aufgaben erklären, die jemand in einem Projekt haben könnte.
- Rollen und Aufgaben im Team Data Science Process
- Datenwissenschaftliche Aufgaben ausführen: Exploration, Modellierung und Bereitstellung
Aufgabe
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, beachten Sie bitte, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.