|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Ciência de Dados na Nuvem: O caminho "Low code/No code"
 |
|---|
| Ciência de Dados na Nuvem: Low Code - Sketchnote por @nitya |
Índice:
- Ciência de Dados na Nuvem: O caminho "Low code/No code"
Quiz Pré-Aula
1. Introdução
1.1 O que é o Azure Machine Learning?
A plataforma de nuvem Azure oferece mais de 200 produtos e serviços em nuvem projetados para ajudar você a criar novas soluções. Cientistas de dados gastam muito esforço explorando e pré-processando dados, além de testar vários tipos de algoritmos de treinamento de modelos para produzir modelos precisos. Essas tarefas consomem tempo e frequentemente utilizam de forma ineficiente recursos de hardware de computação caros.
Azure ML é uma plataforma baseada em nuvem para construir e operar soluções de aprendizado de máquina no Azure. Ela inclui uma ampla gama de recursos e capacidades que ajudam cientistas de dados a preparar dados, treinar modelos, publicar serviços preditivos e monitorar seu uso. O mais importante é que ela aumenta a eficiência ao automatizar muitas das tarefas demoradas associadas ao treinamento de modelos e permite o uso de recursos de computação baseados na nuvem que escalam de forma eficaz para lidar com grandes volumes de dados, incorrendo em custos apenas quando realmente utilizados.
O Azure ML fornece todas as ferramentas que desenvolvedores e cientistas de dados precisam para seus fluxos de trabalho de aprendizado de máquina. Isso inclui:
- Azure Machine Learning Studio: um portal web no Azure Machine Learning para opções de treinamento, implantação, automação, rastreamento e gerenciamento de ativos com pouco ou nenhum código. O Studio integra-se ao SDK do Azure Machine Learning para uma experiência contínua.
- Jupyter Notebooks: para prototipar e testar rapidamente modelos de aprendizado de máquina.
- Azure Machine Learning Designer: permite arrastar e soltar módulos para construir experimentos e, em seguida, implantar pipelines em um ambiente de baixo código.
- Interface de AutoML: automatiza tarefas iterativas de desenvolvimento de modelos de aprendizado de máquina, permitindo construir modelos com alta escala, eficiência e produtividade, mantendo a qualidade do modelo.
- Rotulagem de Dados: uma ferramenta assistida de aprendizado de máquina para rotular dados automaticamente.
- Extensão de aprendizado de máquina para o Visual Studio Code: fornece um ambiente de desenvolvimento completo para construir e gerenciar projetos de aprendizado de máquina.
- CLI de aprendizado de máquina: fornece comandos para gerenciar recursos do Azure ML a partir da linha de comando.
- Integração com frameworks de código aberto como PyTorch, TensorFlow, Scikit-learn e muitos outros para treinar, implantar e gerenciar o processo de aprendizado de máquina de ponta a ponta.
- MLflow: uma biblioteca de código aberto para gerenciar o ciclo de vida de seus experimentos de aprendizado de máquina. MLFlow Tracking é um componente do MLflow que registra e rastreia métricas de execução de treinamento e artefatos do modelo, independentemente do ambiente do experimento.
1.2 O Projeto de Previsão de Insuficiência Cardíaca:
Não há dúvida de que criar e desenvolver projetos é a melhor maneira de colocar suas habilidades e conhecimentos à prova. Nesta lição, vamos explorar duas maneiras diferentes de construir um projeto de ciência de dados para prever ataques de insuficiência cardíaca no Azure ML Studio, através de Low code/No code e do Azure ML SDK, conforme mostrado no esquema a seguir:
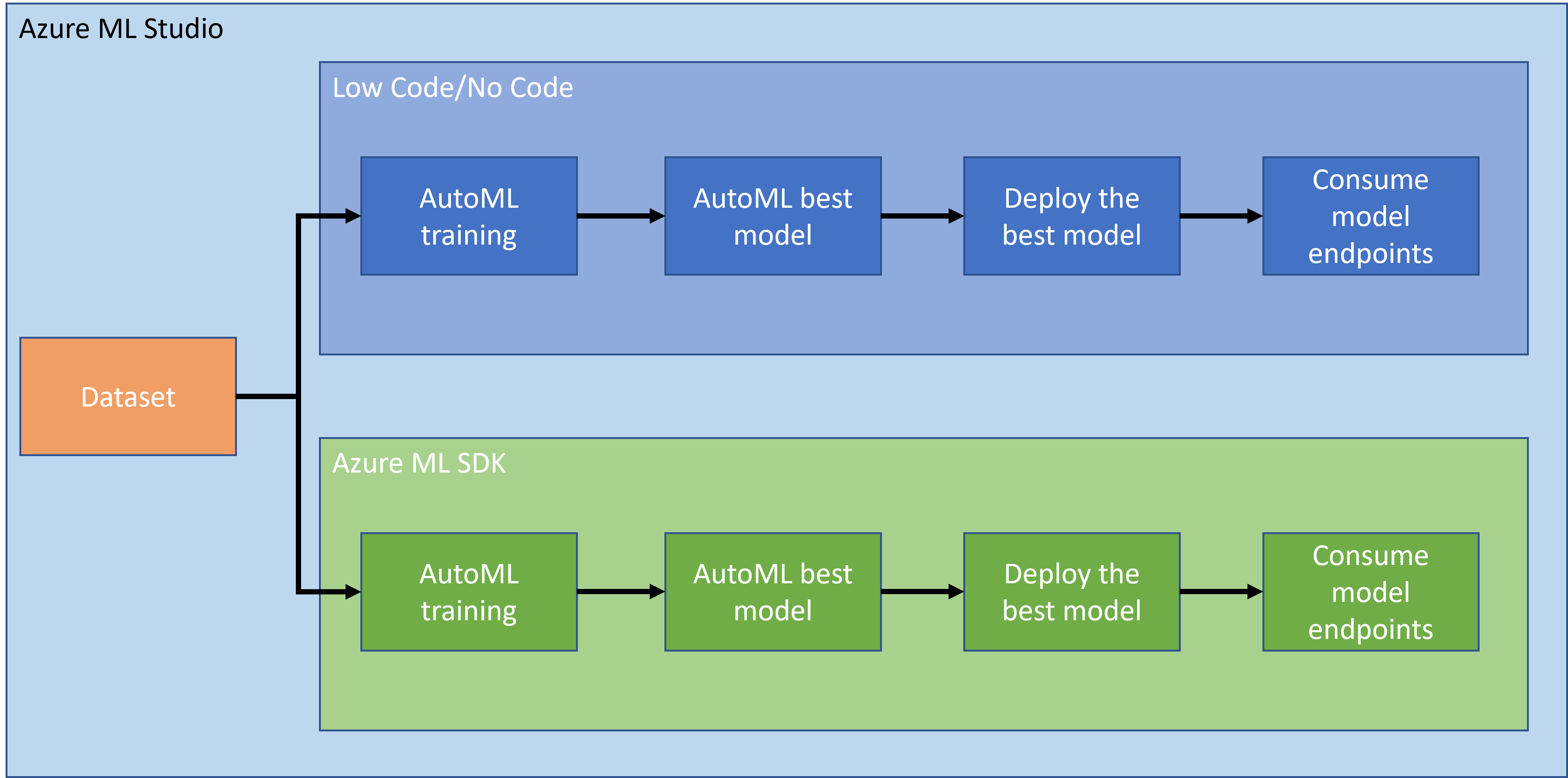
Cada abordagem tem seus próprios prós e contras. O método Low code/No code é mais fácil para começar, pois envolve a interação com uma interface gráfica (GUI), sem necessidade de conhecimento prévio de código. Esse método permite testar rapidamente a viabilidade do projeto e criar um POC (Prova de Conceito). No entanto, à medida que o projeto cresce e precisa estar pronto para produção, não é viável criar recursos por meio de uma GUI. É necessário automatizar tudo programaticamente, desde a criação de recursos até a implantação de um modelo. É aqui que o conhecimento do Azure ML SDK se torna essencial.
| Low code/No code | Azure ML SDK | |
|---|---|---|
| Conhecimento de código | Não necessário | Necessário |
| Tempo de desenvolvimento | Rápido e fácil | Depende da experiência em código |
| Pronto para produção | Não | Sim |
1.3 O Conjunto de Dados de Insuficiência Cardíaca:
As doenças cardiovasculares (DCVs) são a principal causa de morte no mundo, representando 31% de todas as mortes globalmente. Fatores de risco ambientais e comportamentais, como uso de tabaco, dieta não saudável e obesidade, inatividade física e consumo nocivo de álcool, podem ser usados como características para modelos de estimativa. Ser capaz de estimar a probabilidade de desenvolvimento de uma DCV pode ser muito útil para prevenir ataques em pessoas de alto risco.
O Kaggle disponibilizou publicamente um conjunto de dados de insuficiência cardíaca, que usaremos neste projeto. Você pode baixar o conjunto de dados agora. Este é um conjunto de dados tabular com 13 colunas (12 características e 1 variável alvo) e 299 linhas.
| Nome da variável | Tipo | Descrição | Exemplo | |
|---|---|---|---|---|
| 1 | age | numérico | idade do paciente | 25 |
| 2 | anaemia | booleano | Diminuição de glóbulos vermelhos ou hemoglobina | 0 ou 1 |
| 3 | creatinine_phosphokinase | numérico | Nível da enzima CPK no sangue | 542 |
| 4 | diabetes | booleano | Se o paciente tem diabetes | 0 ou 1 |
| 5 | ejection_fraction | numérico | Percentual de sangue que sai do coração a cada contração | 45 |
| 6 | high_blood_pressure | booleano | Se o paciente tem hipertensão | 0 ou 1 |
| 7 | platelets | numérico | Plaquetas no sangue | 149000 |
| 8 | serum_creatinine | numérico | Nível de creatinina sérica no sangue | 0.5 |
| 9 | serum_sodium | numérico | Nível de sódio sérico no sangue | jun |
| 10 | sex | booleano | mulher ou homem | 0 ou 1 |
| 11 | smoking | booleano | Se o paciente fuma | 0 ou 1 |
| 12 | time | numérico | período de acompanhamento (dias) | 4 |
| ---- | --------------------------- | ----------------- | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Alvo] | booleano | se o paciente morre durante o período de acompanhamento | 0 ou 1 |
Depois de obter o conjunto de dados, podemos começar o projeto no Azure.
2. Treinamento Low code/No code de um modelo no Azure ML Studio
2.1 Criar um workspace no Azure ML
Para treinar um modelo no Azure ML, você precisa primeiro criar um workspace no Azure ML. O workspace é o recurso de nível superior para o Azure Machine Learning, fornecendo um local centralizado para trabalhar com todos os artefatos que você cria ao usar o Azure Machine Learning. O workspace mantém um histórico de todas as execuções de treinamento, incluindo logs, métricas, saídas e um snapshot de seus scripts. Você usa essas informações para determinar qual execução de treinamento produz o melhor modelo. Saiba mais
Recomenda-se usar o navegador mais atualizado compatível com seu sistema operacional. Os seguintes navegadores são suportados:
- Microsoft Edge (O novo Microsoft Edge, versão mais recente. Não o Microsoft Edge legado)
- Safari (versão mais recente, apenas para Mac)
- Chrome (versão mais recente)
- Firefox (versão mais recente)
Para usar o Azure Machine Learning, crie um workspace em sua assinatura do Azure. Você pode então usar esse workspace para gerenciar dados, recursos de computação, código, modelos e outros artefatos relacionados às suas cargas de trabalho de aprendizado de máquina.
NOTA: Sua assinatura do Azure será cobrada uma pequena quantia pelo armazenamento de dados enquanto o workspace do Azure Machine Learning existir em sua assinatura. Portanto, recomendamos que você exclua o workspace do Azure Machine Learning quando não estiver mais usando.
-
Faça login no portal do Azure usando as credenciais da Microsoft associadas à sua assinatura do Azure.
-
Selecione +Criar um recurso
Pesquise por Machine Learning e selecione o tile Machine Learning.
Clique no botão criar.
Preencha as configurações da seguinte forma:
- Assinatura: Sua assinatura do Azure
- Grupo de recursos: Crie ou selecione um grupo de recursos
- Nome do workspace: Insira um nome único para seu workspace
- Região: Selecione a região geográfica mais próxima de você
- Conta de armazenamento: Observe a nova conta de armazenamento padrão que será criada para seu workspace
- Cofre de chaves: Observe o novo cofre de chaves padrão que será criado para seu workspace
- Insights de aplicação: Observe o novo recurso de insights de aplicação padrão que será criado para seu workspace
- Registro de contêiner: Nenhum (um será criado automaticamente na primeira vez que você implantar um modelo em um contêiner)
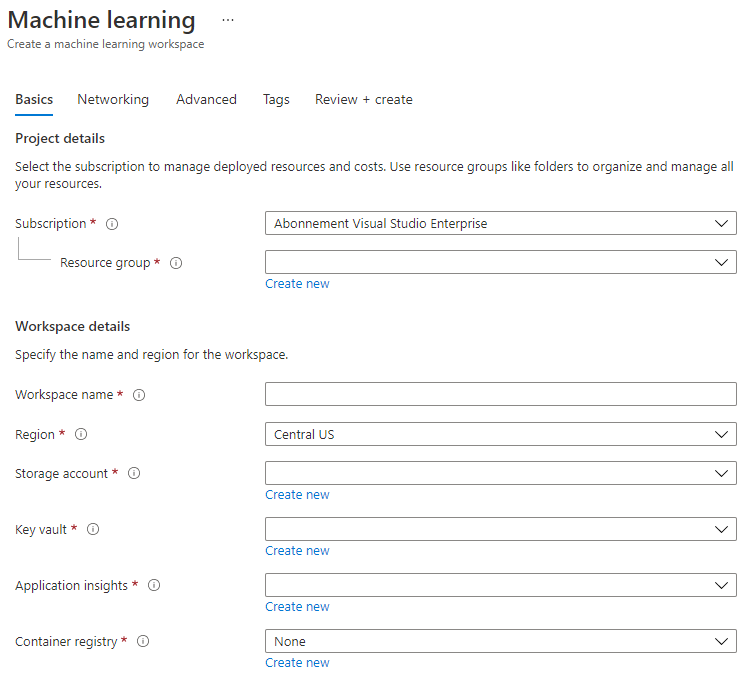
- Clique em criar + revisar e, em seguida, no botão criar.
-
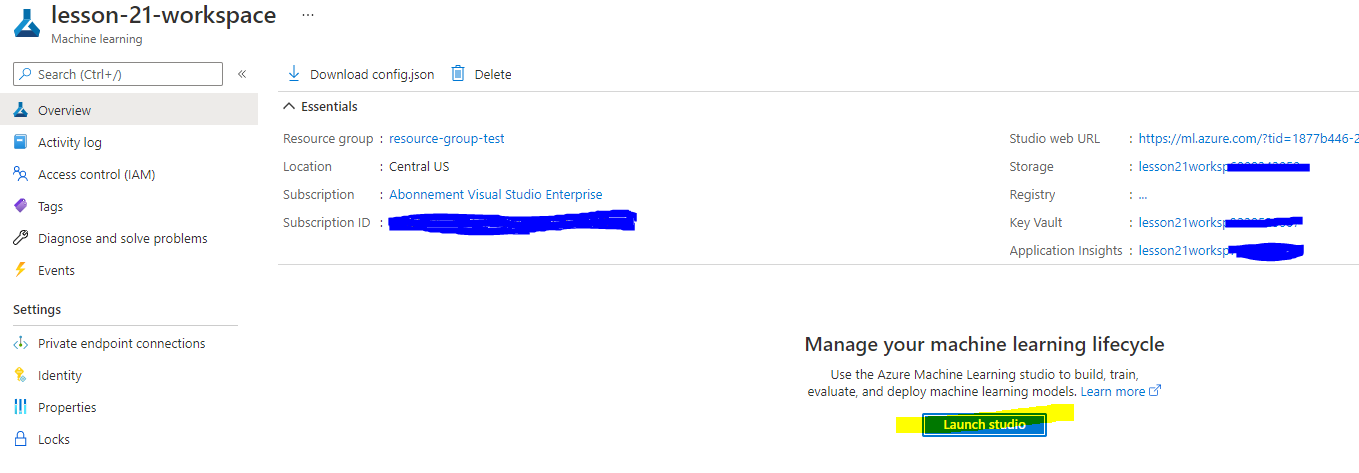
Aguarde a criação do seu workspace (isso pode levar alguns minutos). Depois, acesse-o no portal. Você pode encontrá-lo através do serviço Azure Machine Learning.
-
Na página de visão geral do seu workspace, inicie o Azure Machine Learning Studio (ou abra uma nova aba do navegador e navegue até https://ml.azure.com), e faça login no Azure Machine Learning Studio usando sua conta Microsoft. Se solicitado, selecione seu diretório e assinatura do Azure, e seu workspace do Azure Machine Learning.
- No Azure Machine Learning Studio, alterne o ícone ☰ no canto superior esquerdo para visualizar as várias páginas da interface. Você pode usar essas páginas para gerenciar os recursos do seu workspace.
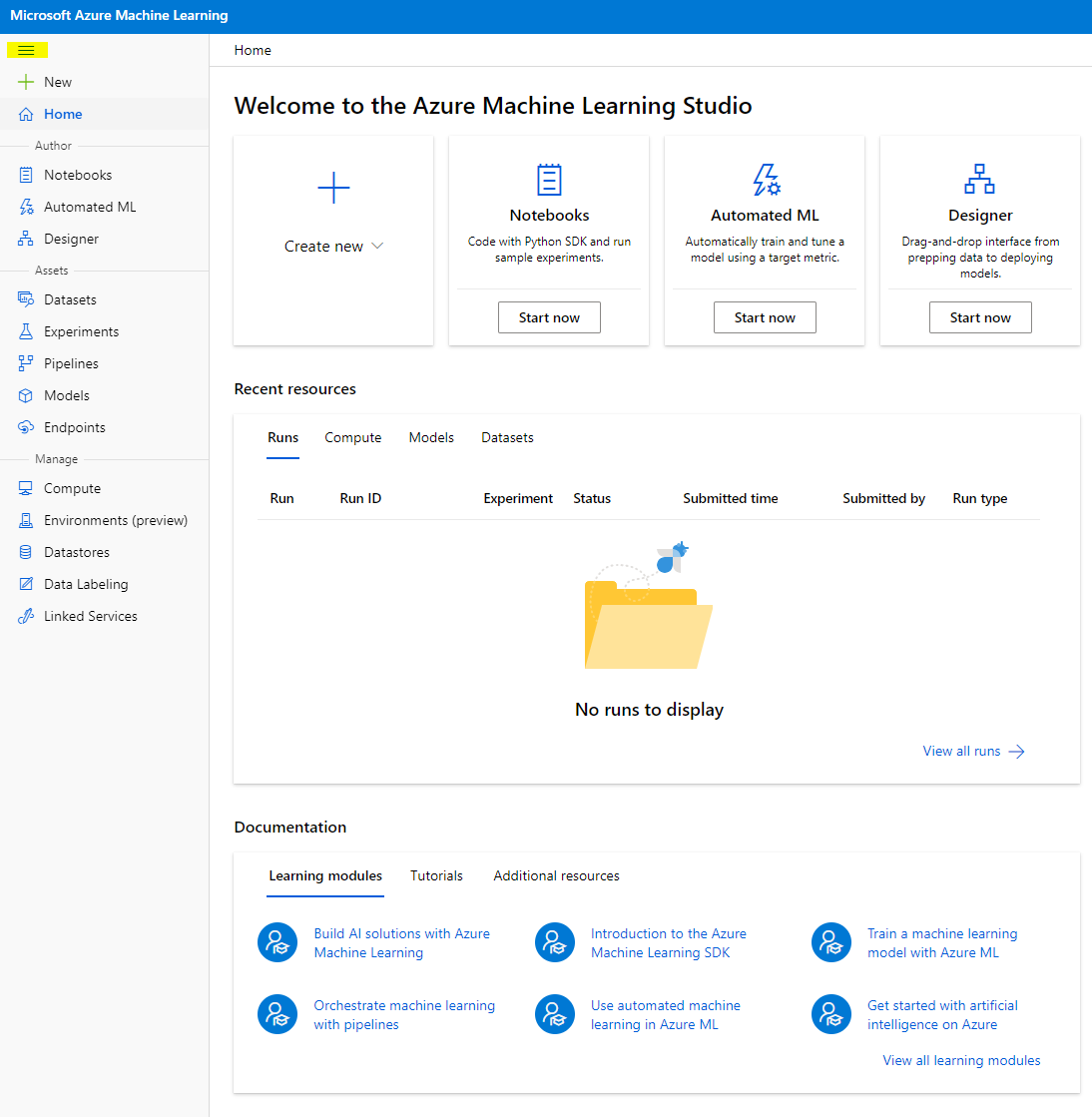
Você pode gerenciar seu workspace usando o portal do Azure, mas para cientistas de dados e engenheiros de operações de aprendizado de máquina, o Azure Machine Learning Studio fornece uma interface de usuário mais focada para gerenciar os recursos do workspace.
2.2 Recursos de Computação
Os Recursos de Computação são recursos baseados na nuvem nos quais você pode executar processos de treinamento de modelo e exploração de dados. Existem quatro tipos de recursos de computação que você pode criar:
- Instâncias de Computação: Estações de trabalho de desenvolvimento que cientistas de dados podem usar para trabalhar com dados e modelos. Isso envolve a criação de uma Máquina Virtual (VM) e o lançamento de uma instância de notebook. Você pode então treinar um modelo chamando um cluster de computação a partir do notebook.
- Clusters de Computação: Clusters escaláveis de VMs para processamento sob demanda de código de experimentos. Você precisará deles ao treinar um modelo. Clusters de computação também podem empregar recursos especializados de GPU ou CPU.
- Clusters de Inferência: Alvos de implantação para serviços preditivos que usam seus modelos treinados.
- Attached Compute: Links para recursos de computação existentes no Azure, como Máquinas Virtuais ou clusters do Azure Databricks.
2.2.1 Escolhendo as opções certas para seus recursos de computação
Alguns fatores importantes devem ser considerados ao criar um recurso de computação, e essas escolhas podem ser decisões críticas.
Você precisa de CPU ou GPU?
Uma CPU (Unidade Central de Processamento) é o circuito eletrônico que executa instruções que compõem um programa de computador. Uma GPU (Unidade de Processamento Gráfico) é um circuito eletrônico especializado que pode executar código relacionado a gráficos em uma taxa muito alta.
A principal diferença entre a arquitetura de CPU e GPU é que uma CPU é projetada para lidar com uma ampla gama de tarefas rapidamente (medida pela velocidade do clock da CPU), mas é limitada na simultaneidade das tarefas que podem ser executadas. GPUs são projetadas para computação paralela e, portanto, são muito melhores para tarefas de aprendizado profundo.
| CPU | GPU |
|---|---|
| Menos caro | Mais caro |
| Menor nível de simultaneidade | Maior nível de simultaneidade |
| Mais lento no treinamento de modelos de aprendizado profundo | Ideal para aprendizado profundo |
Tamanho do Cluster
Clusters maiores são mais caros, mas resultarão em melhor capacidade de resposta. Portanto, se você tem tempo, mas não muito dinheiro, deve começar com um cluster pequeno. Por outro lado, se você tem dinheiro, mas pouco tempo, deve começar com um cluster maior.
Tamanho da VM
Dependendo das suas restrições de tempo e orçamento, você pode variar o tamanho da RAM, disco, número de núcleos e velocidade do clock. Aumentar todos esses parâmetros será mais caro, mas resultará em melhor desempenho.
Instâncias Dedicadas ou de Baixa Prioridade?
Uma instância de baixa prioridade significa que ela é interrompível: essencialmente, o Microsoft Azure pode tomar esses recursos e atribuí-los a outra tarefa, interrompendo assim um trabalho. Uma instância dedicada, ou não interrompível, significa que o trabalho nunca será encerrado sem sua permissão. Essa é outra consideração entre tempo e dinheiro, já que instâncias interrompíveis são menos caras do que as dedicadas.
2.2.2 Criando um cluster de computação
No workspace do Azure ML que criamos anteriormente, vá para a seção de computação e você poderá ver os diferentes recursos de computação que discutimos (ou seja, instâncias de computação, clusters de computação, clusters de inferência e computação anexada). Para este projeto, precisaremos de um cluster de computação para o treinamento do modelo. No Studio, clique no menu "Compute", depois na aba "Compute cluster" e clique no botão "+ New" para criar um cluster de computação.
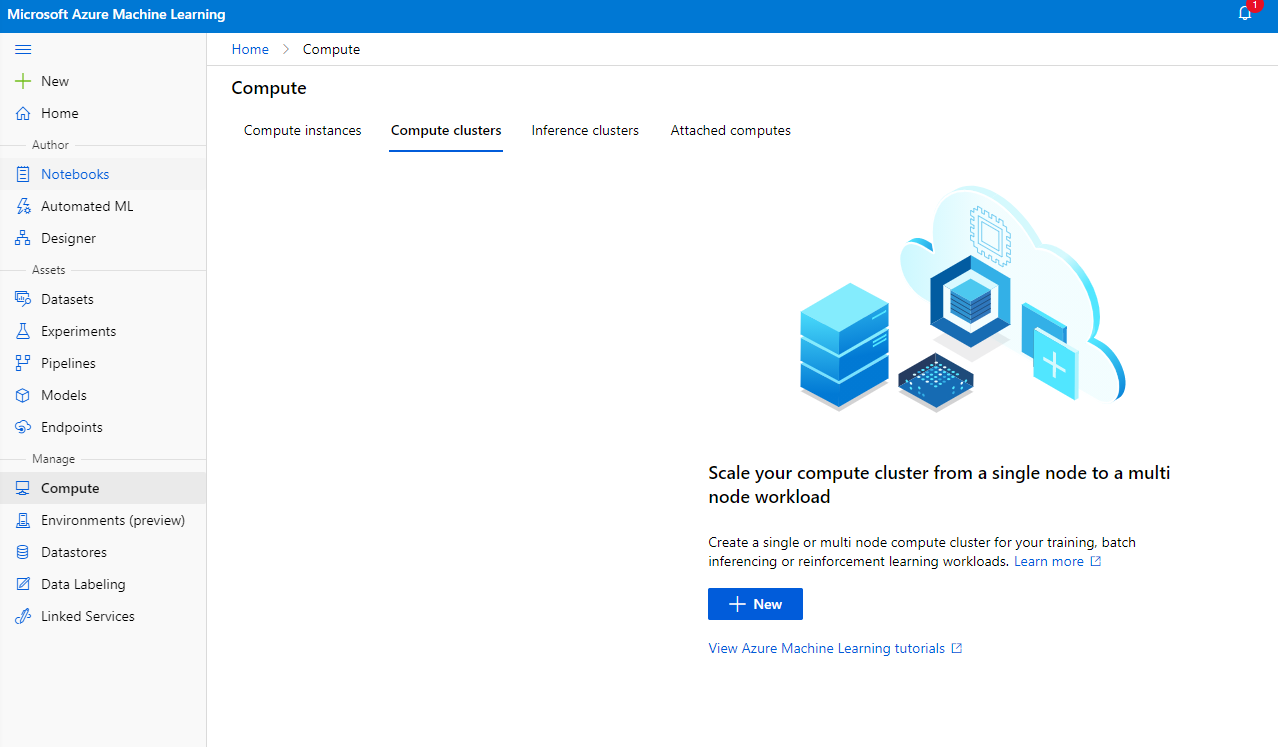
- Escolha suas opções: Dedicado vs Baixa prioridade, CPU ou GPU, tamanho da VM e número de núcleos (você pode manter as configurações padrão para este projeto).
- Clique no botão Next.
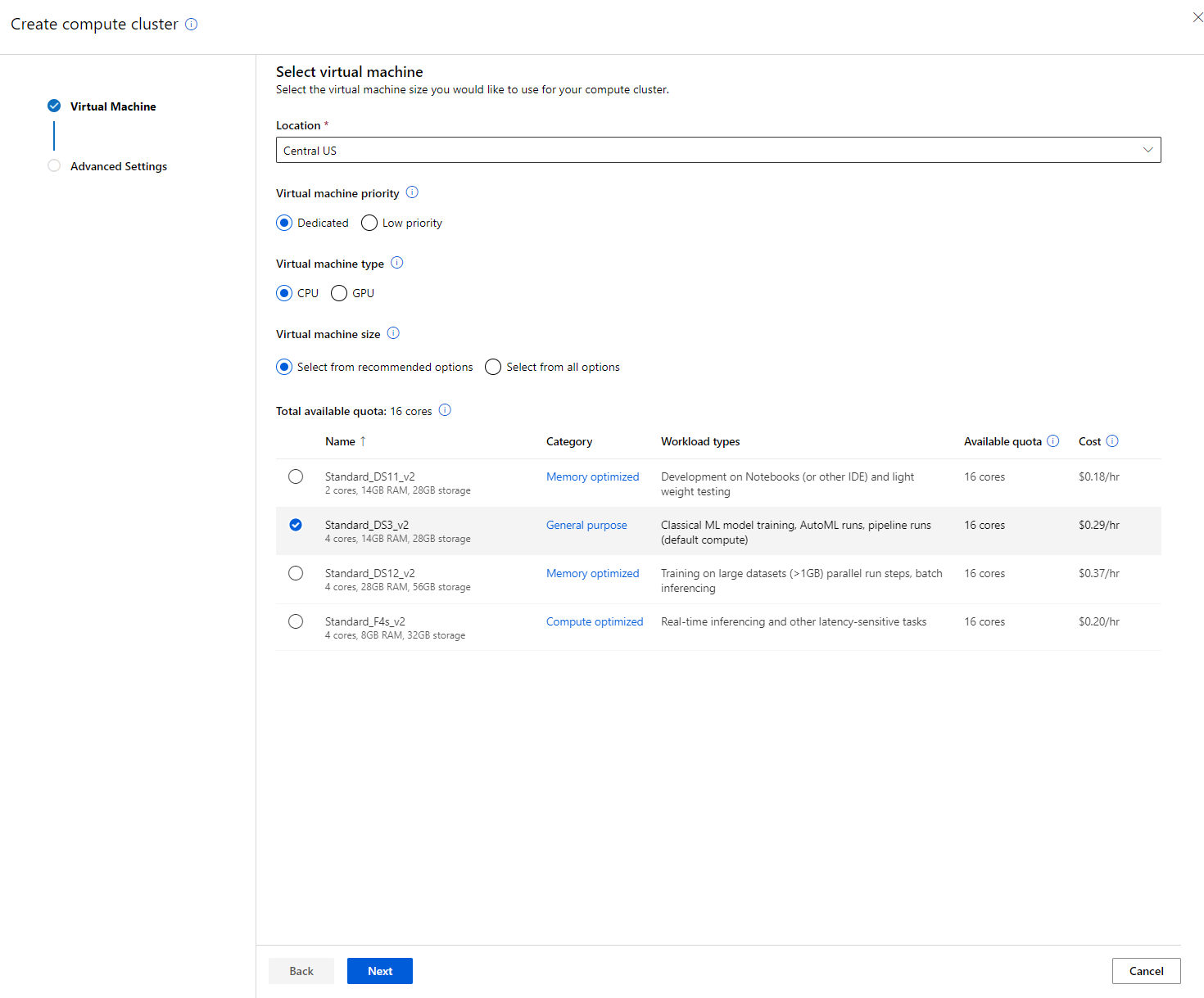
- Dê um nome ao cluster de computação.
- Escolha suas opções: Número mínimo/máximo de nós, segundos de inatividade antes de reduzir o tamanho, acesso SSH. Observe que, se o número mínimo de nós for 0, você economizará dinheiro quando o cluster estiver inativo. Note que quanto maior o número máximo de nós, mais curto será o treinamento. O número máximo de nós recomendado é 3.
- Clique no botão "Create". Esta etapa pode levar alguns minutos.
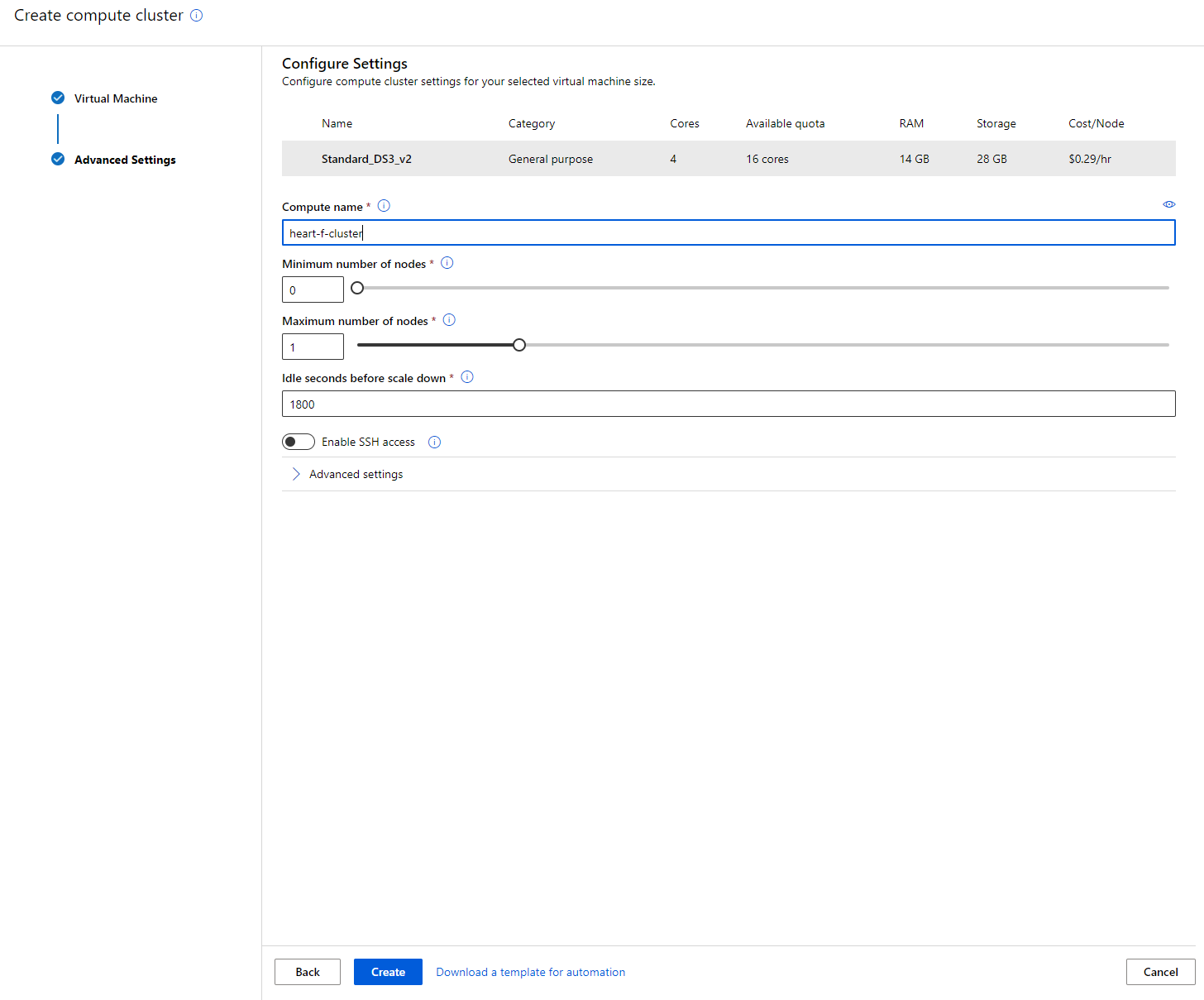
Incrível! Agora que temos um cluster de computação, precisamos carregar os dados para o Azure ML Studio.
2.3 Carregando o Conjunto de Dados
-
No workspace do Azure ML que criamos anteriormente, clique em "Datasets" no menu à esquerda e clique no botão "+ Create dataset" para criar um conjunto de dados. Escolha a opção "From local files" e selecione o conjunto de dados do Kaggle que baixamos anteriormente.
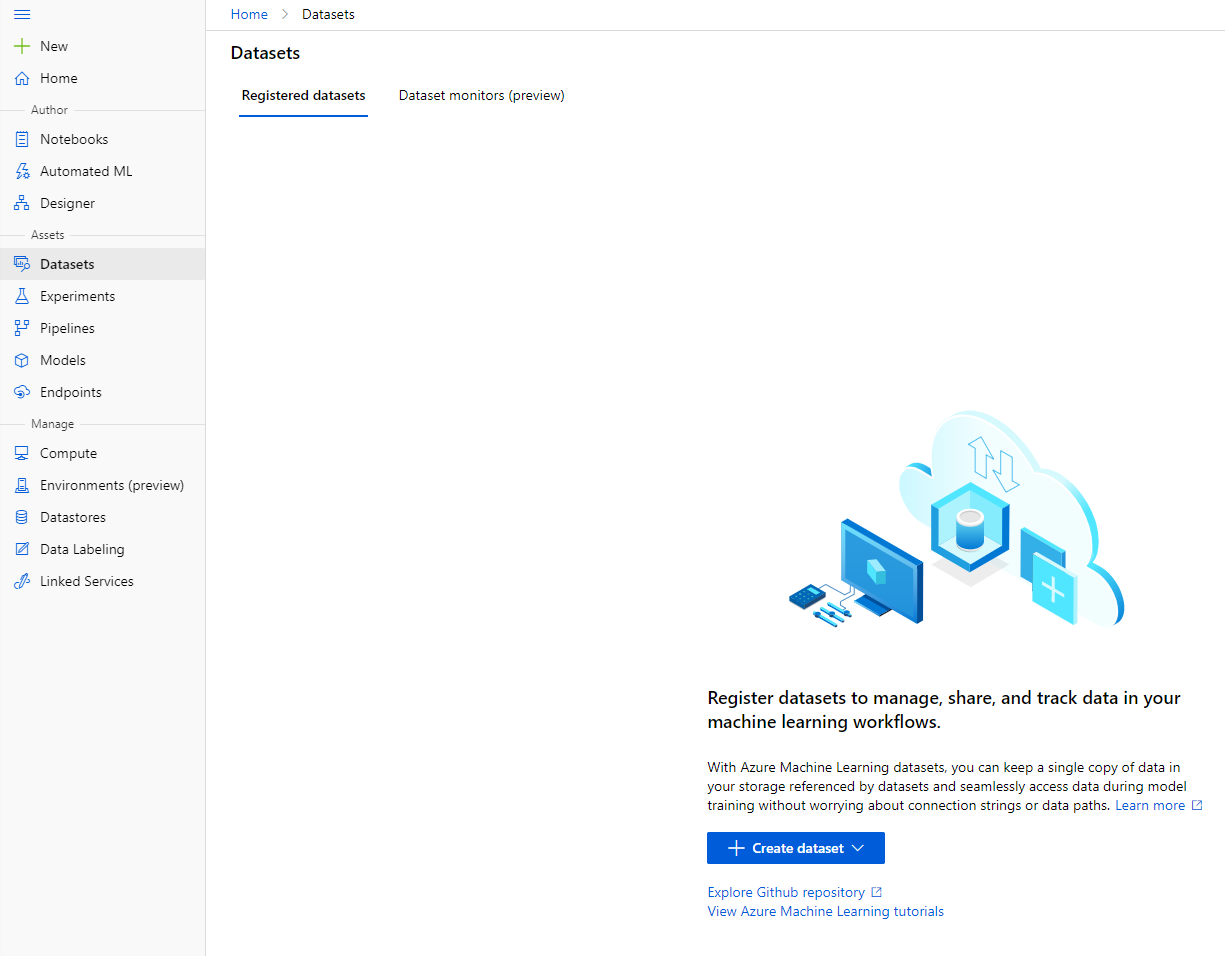
-
Dê um nome, um tipo e uma descrição ao seu conjunto de dados. Clique em Next. Faça o upload dos dados a partir dos arquivos. Clique em Next.
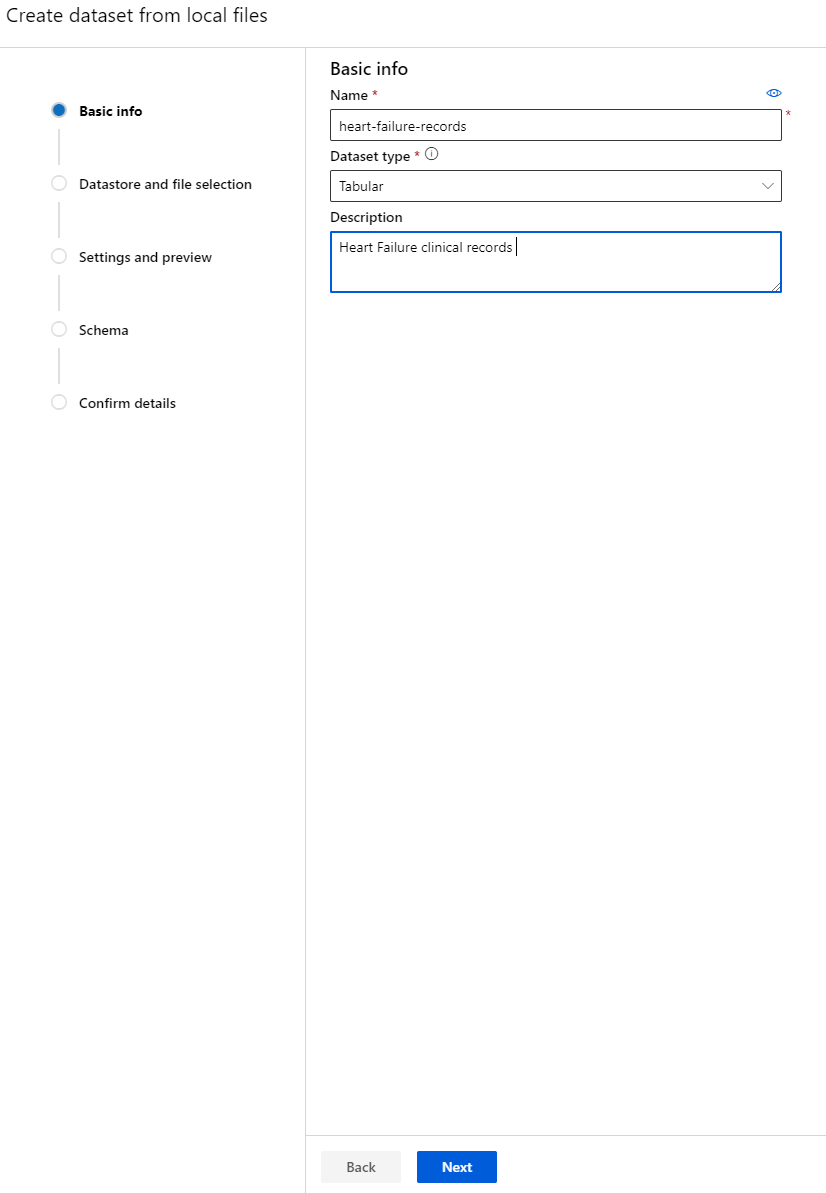
-
No Schema, altere o tipo de dado para Boolean para as seguintes características: anaemia, diabetes, high blood pressure, sex, smoking e DEATH_EVENT. Clique em Next e depois em Create.
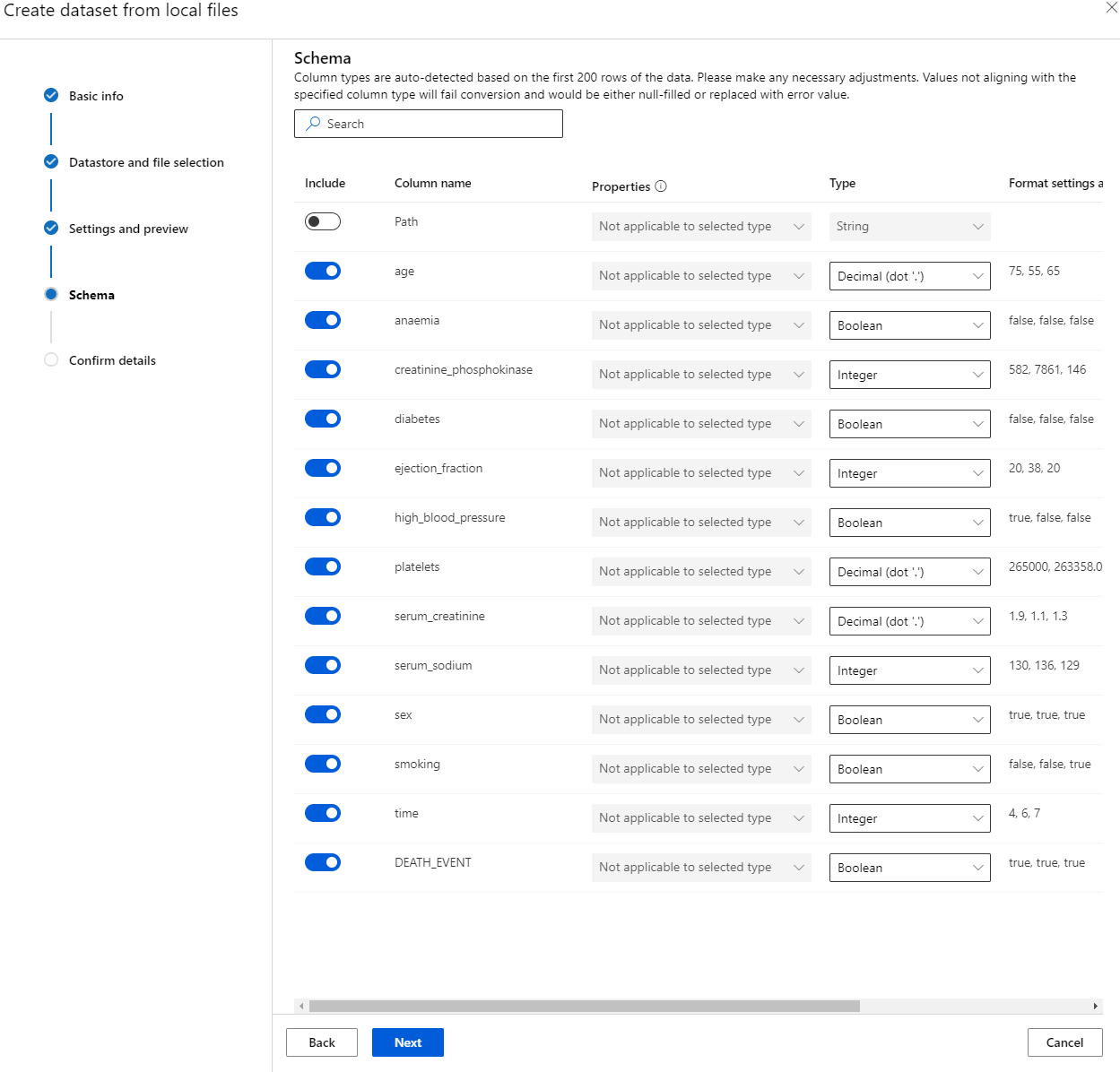
Ótimo! Agora que o conjunto de dados está configurado e o cluster de computação foi criado, podemos começar o treinamento do modelo!
2.4 Treinamento com pouco ou nenhum código usando AutoML
O desenvolvimento tradicional de modelos de aprendizado de máquina é intensivo em recursos, exige conhecimento significativo do domínio e tempo para produzir e comparar dezenas de modelos. O aprendizado de máquina automatizado (AutoML) é o processo de automatizar as tarefas iterativas e demoradas do desenvolvimento de modelos de aprendizado de máquina. Ele permite que cientistas de dados, analistas e desenvolvedores criem modelos de aprendizado de máquina com alta escala, eficiência e produtividade, mantendo a qualidade do modelo. Isso reduz o tempo necessário para obter modelos prontos para produção, com grande facilidade e eficiência. Saiba mais
-
No workspace do Azure ML que criamos anteriormente, clique em "Automated ML" no menu à esquerda e selecione o conjunto de dados que você acabou de carregar. Clique em Next.
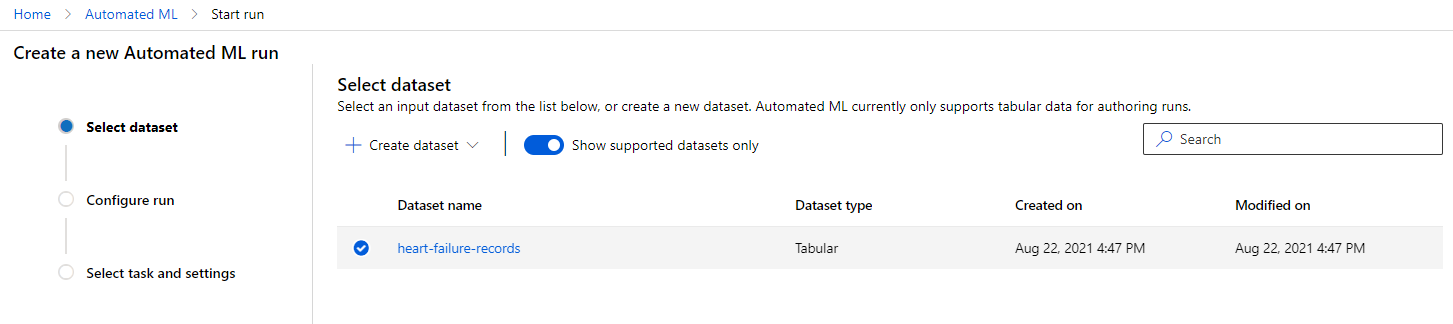
-
Insira um novo nome de experimento, a coluna alvo (DEATH_EVENT) e o cluster de computação que criamos. Clique em Next.
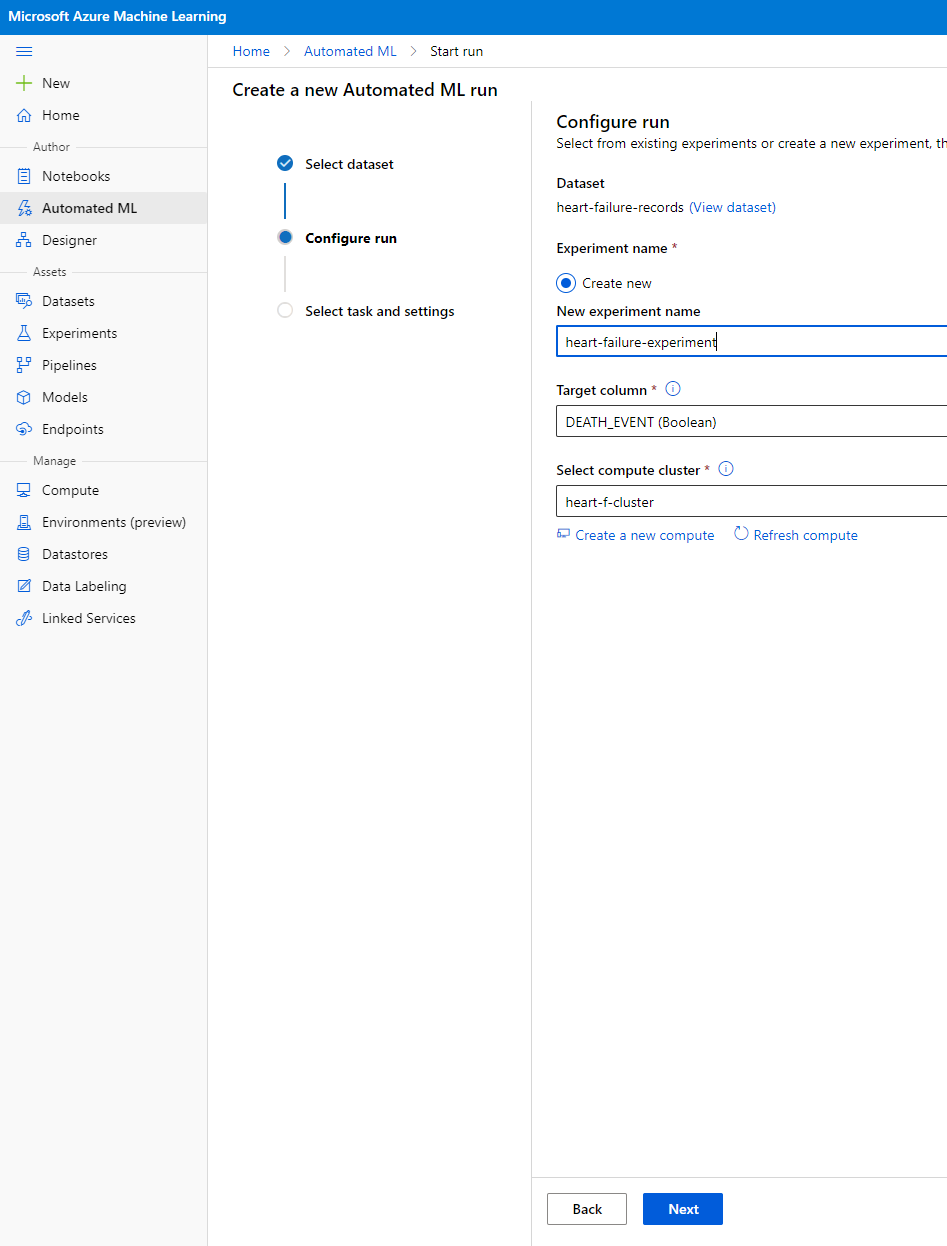
-
Escolha "Classification" e clique em Finish. Esta etapa pode levar entre 30 minutos e 1 hora, dependendo do tamanho do cluster de computação.
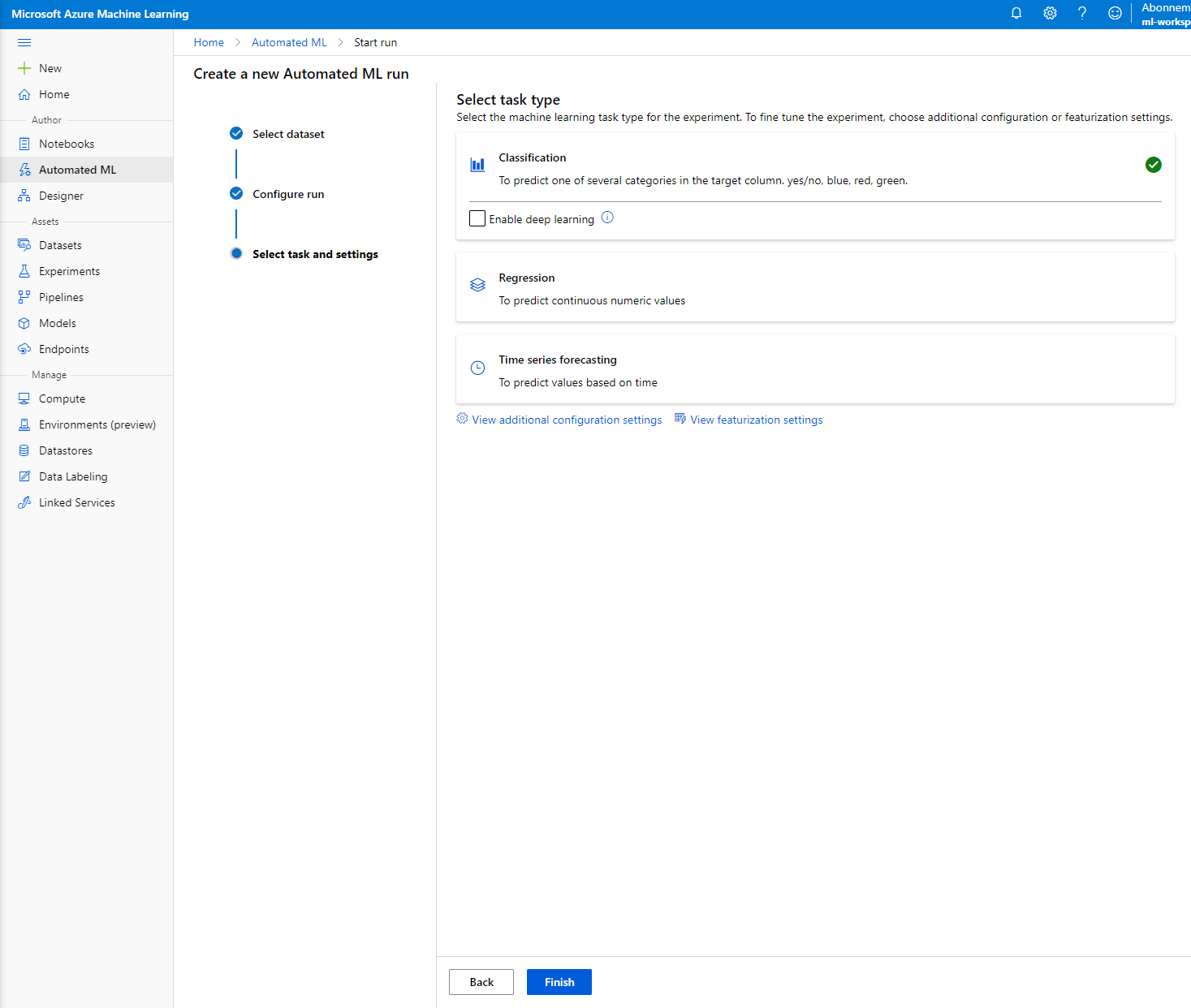
-
Quando a execução for concluída, clique na aba "Automated ML", clique na sua execução e clique no Algoritmo no cartão "Best model summary".
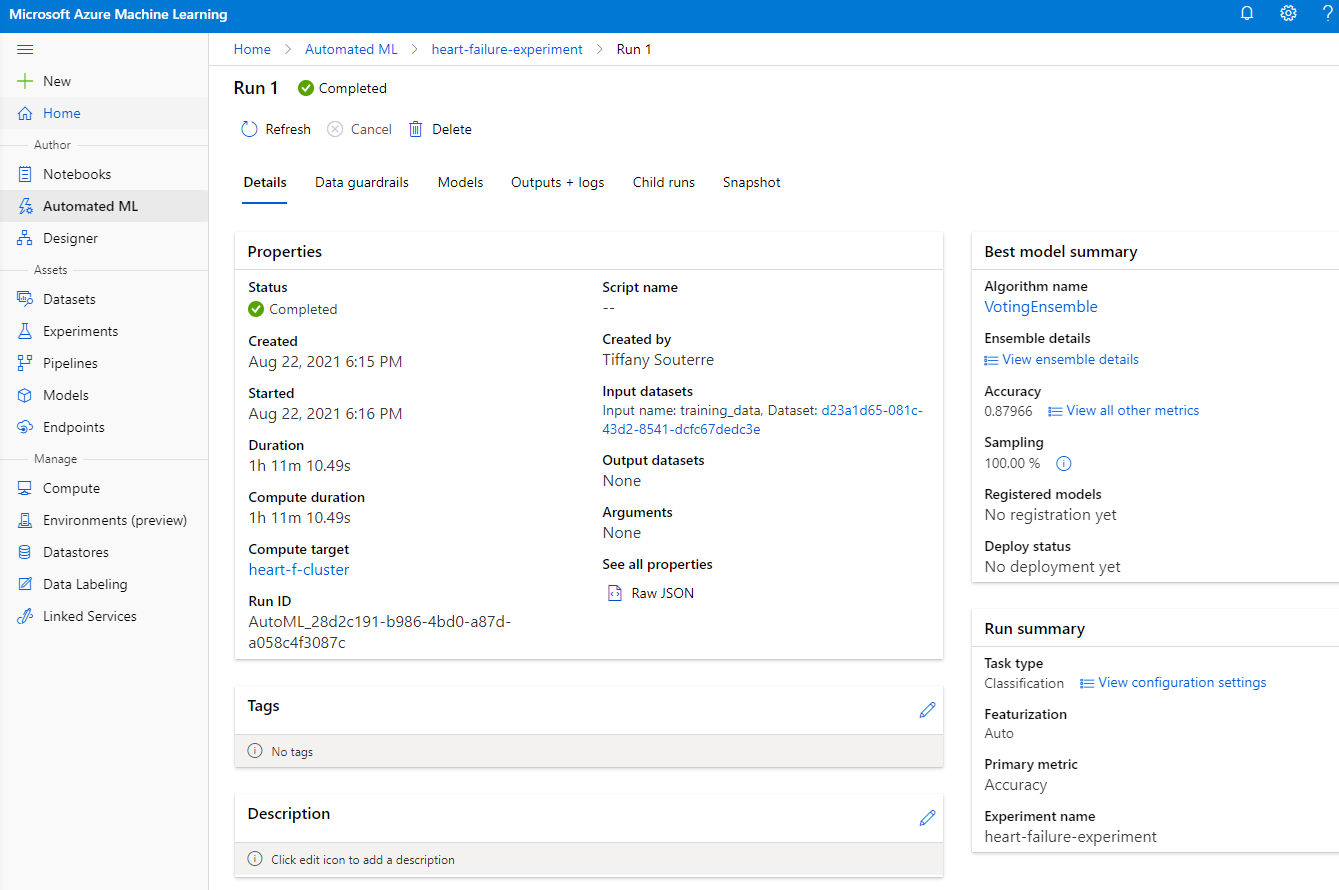
Aqui você pode ver uma descrição detalhada do melhor modelo que o AutoML gerou. Você também pode explorar outros modelos gerados na aba Models. Reserve alguns minutos para explorar os modelos na seção Explanations (botão preview). Depois de escolher o modelo que deseja usar (aqui escolheremos o melhor modelo selecionado pelo AutoML), veremos como podemos implantá-lo.
3. Implantação de modelo com pouco ou nenhum código e consumo de endpoint
3.1 Implantação do modelo
A interface de aprendizado de máquina automatizado permite implantar o melhor modelo como um serviço web em algumas etapas. A implantação é a integração do modelo para que ele possa fazer previsões com base em novos dados e identificar possíveis áreas de oportunidade. Para este projeto, a implantação em um serviço web significa que aplicativos médicos poderão consumir o modelo para fazer previsões ao vivo sobre o risco de seus pacientes sofrerem um ataque cardíaco.
Na descrição do melhor modelo, clique no botão "Deploy".
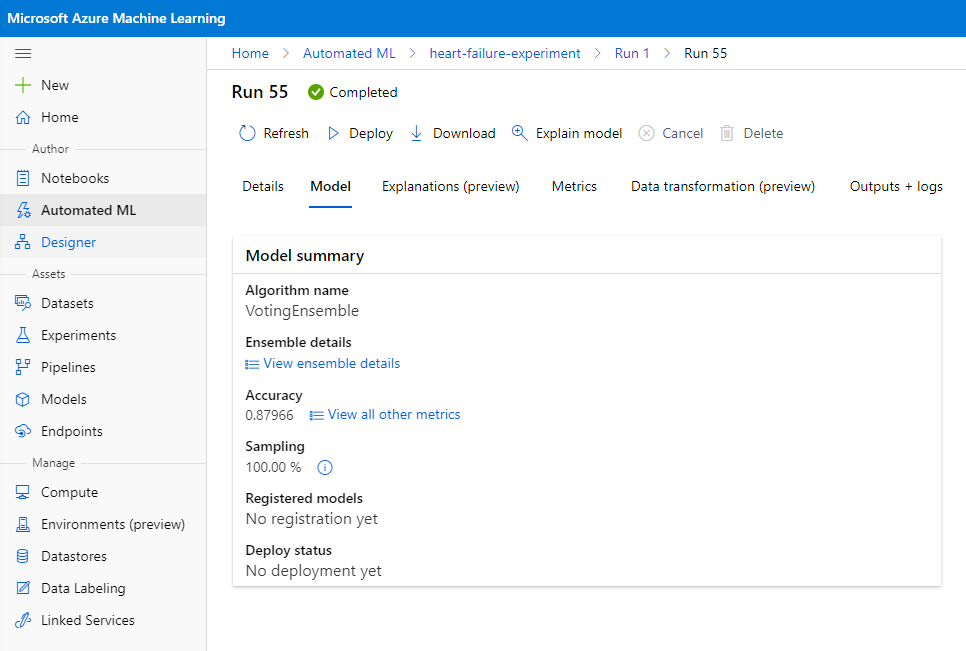
- Dê um nome, uma descrição, tipo de computação (Azure Container Instance), habilite a autenticação e clique em Deploy. Esta etapa pode levar cerca de 20 minutos para ser concluída. O processo de implantação envolve várias etapas, incluindo o registro do modelo, a geração de recursos e sua configuração para o serviço web. Uma mensagem de status aparece em Deploy status. Selecione Refresh periodicamente para verificar o status da implantação. Ele estará implantado e em execução quando o status for "Healthy".
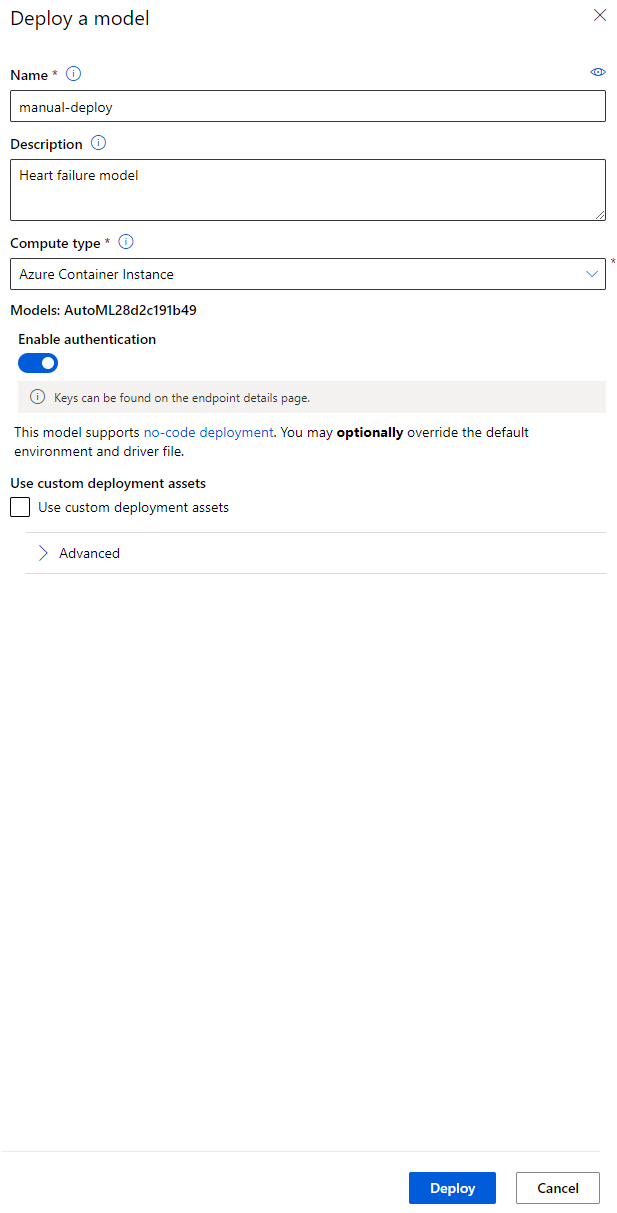
- Depois de implantado, clique na aba Endpoint e clique no endpoint que você acabou de implantar. Aqui você pode encontrar todos os detalhes que precisa saber sobre o endpoint.
Incrível! Agora que temos um modelo implantado, podemos começar o consumo do endpoint.
3.2 Consumo do Endpoint
Clique na aba "Consume". Aqui você pode encontrar o endpoint REST e um script Python na opção de consumo. Reserve um tempo para ler o código Python.
Este script pode ser executado diretamente da sua máquina local e consumirá seu endpoint.
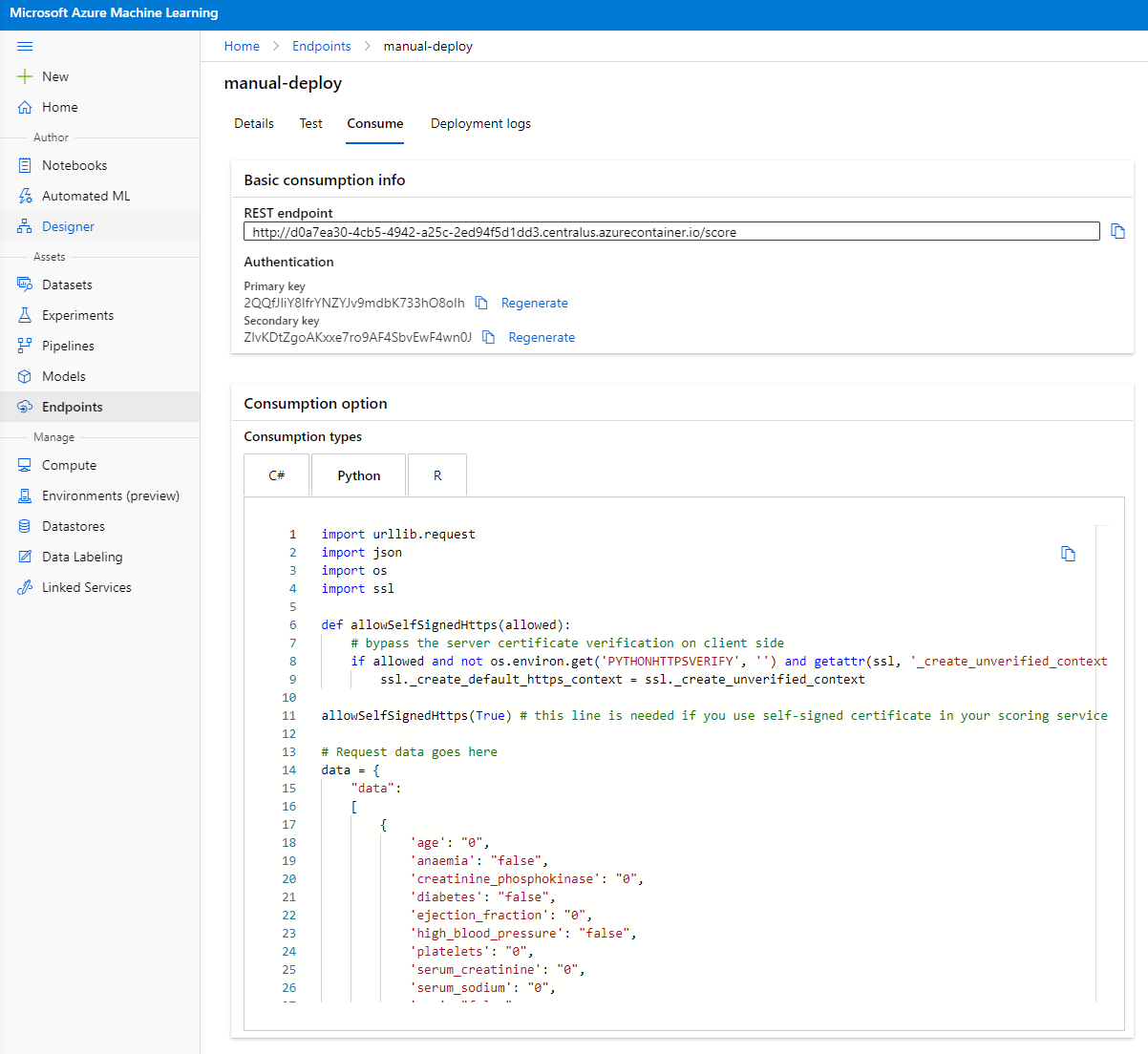
Reserve um momento para verificar estas 2 linhas de código:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
A variável url é o endpoint REST encontrado na aba de consumo e a variável api_key é a chave primária também encontrada na aba de consumo (somente no caso de você ter habilitado a autenticação). É assim que o script pode consumir o endpoint.
- Ao executar o script, você deve ver a seguinte saída:
b'"{\\"result\\": [true]}"'
Isso significa que a previsão de falha cardíaca para os dados fornecidos é verdadeira. Isso faz sentido porque, se você observar mais de perto os dados gerados automaticamente no script, tudo está em 0 e falso por padrão. Você pode alterar os dados com o seguinte exemplo de entrada:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
O script deve retornar:
python b'"{\\"result\\": [true, false]}"'
Parabéns! Você acabou de consumir o modelo implantado e treinado no Azure ML!
NOTA: Quando terminar o projeto, não se esqueça de excluir todos os recursos.
🚀 Desafio
Observe atentamente as explicações e os detalhes do modelo que o AutoML gerou para os principais modelos. Tente entender por que o melhor modelo é melhor do que os outros. Quais algoritmos foram comparados? Quais são as diferenças entre eles? Por que o melhor está tendo um desempenho superior neste caso?
Questionário pós-aula
Revisão e Autoestudo
Nesta lição, você aprendeu como treinar, implantar e consumir um modelo para prever o risco de falha cardíaca de forma Low code/No code na nuvem. Se ainda não fez isso, aprofunde-se nas explicações do modelo que o AutoML gerou para os principais modelos e tente entender por que o melhor modelo é melhor que os outros.
Você pode ir além no AutoML Low code/No code lendo esta documentação.
Tarefa
Projeto de Ciência de Dados Low code/No code no Azure ML
Aviso Legal:
Este documento foi traduzido utilizando o serviço de tradução por IA Co-op Translator. Embora nos esforcemos para garantir a precisão, esteja ciente de que traduções automatizadas podem conter erros ou imprecisões. O documento original em seu idioma nativo deve ser considerado a fonte autoritativa. Para informações críticas, recomenda-se a tradução profissional realizada por humanos. Não nos responsabilizamos por quaisquer mal-entendidos ou interpretações equivocadas decorrentes do uso desta tradução.