|
|
6 months ago | |
|---|---|---|
| .. | ||
| solution | 11 months ago | |
| README.md | 6 months ago | |
| assignment.md | 6 months ago | |
| notebook.ipynb | 11 months ago | |
README.md
ক্লাউডে ডেটা সায়েন্স: "Azure ML SDK" পদ্ধতি
 |
|---|
| ক্লাউডে ডেটা সায়েন্স: Azure ML SDK - Sketchnote by @nitya |
সূচিপত্র:
- ক্লাউডে ডেটা সায়েন্স: "Azure ML SDK" পদ্ধতি
পূর্ব-লেকচার কুইজ
১. পরিচিতি
১.১ Azure ML SDK কী?
ডেটা বিজ্ঞানী এবং AI ডেভেলপাররা Azure Machine Learning SDK ব্যবহার করে Azure Machine Learning সার্ভিসের মাধ্যমে মেশিন লার্নিং ওয়ার্কফ্লো তৈরি এবং চালান। আপনি যেকোনো Python পরিবেশে, যেমন Jupyter Notebooks, Visual Studio Code, বা আপনার পছন্দের Python IDE-তে এই সার্ভিসের সাথে ইন্টারঅ্যাক্ট করতে পারেন।
SDK-এর মূল ক্ষেত্রগুলো:
- মেশিন লার্নিং এক্সপেরিমেন্টে ব্যবহৃত ডেটাসেটের জীবনচক্র অন্বেষণ, প্রস্তুত এবং পরিচালনা করা।
- মেশিন লার্নিং এক্সপেরিমেন্টের জন্য ক্লাউড রিসোর্স মনিটরিং, লগিং এবং সংগঠিত করা।
- মডেল প্রশিক্ষণ স্থানীয়ভাবে বা ক্লাউড রিসোর্স ব্যবহার করে, যার মধ্যে GPU-অ্যাক্সিলারেটেড মডেল প্রশিক্ষণ অন্তর্ভুক্ত।
- স্বয়ংক্রিয় মেশিন লার্নিং ব্যবহার করা, যা কনফিগারেশন প্যারামিটার এবং প্রশিক্ষণ ডেটা গ্রহণ করে। এটি অ্যালগরিদম এবং হাইপারপ্যারামিটার সেটিংসের মাধ্যমে স্বয়ংক্রিয়ভাবে পুনরাবৃত্তি করে সেরা মডেল খুঁজে বের করে।
- ওয়েব সার্ভিস ডিপ্লয় করে প্রশিক্ষিত মডেলকে RESTful সার্ভিসে রূপান্তরিত করা, যা যেকোনো অ্যাপ্লিকেশনে ব্যবহার করা যায়।
Azure Machine Learning SDK সম্পর্কে আরও জানুন
পূর্ববর্তী পাঠে, আমরা দেখেছি কীভাবে Low code/No code পদ্ধতিতে একটি মডেল প্রশিক্ষণ, ডিপ্লয় এবং ব্যবহার করা যায়। আমরা হার্ট ফেইলিউর ডেটাসেট ব্যবহার করে একটি হার্ট ফেইলিউর প্রেডিকশন মডেল তৈরি করেছি। এই পাঠে, আমরা একই কাজ করব কিন্তু Azure Machine Learning SDK ব্যবহার করে।
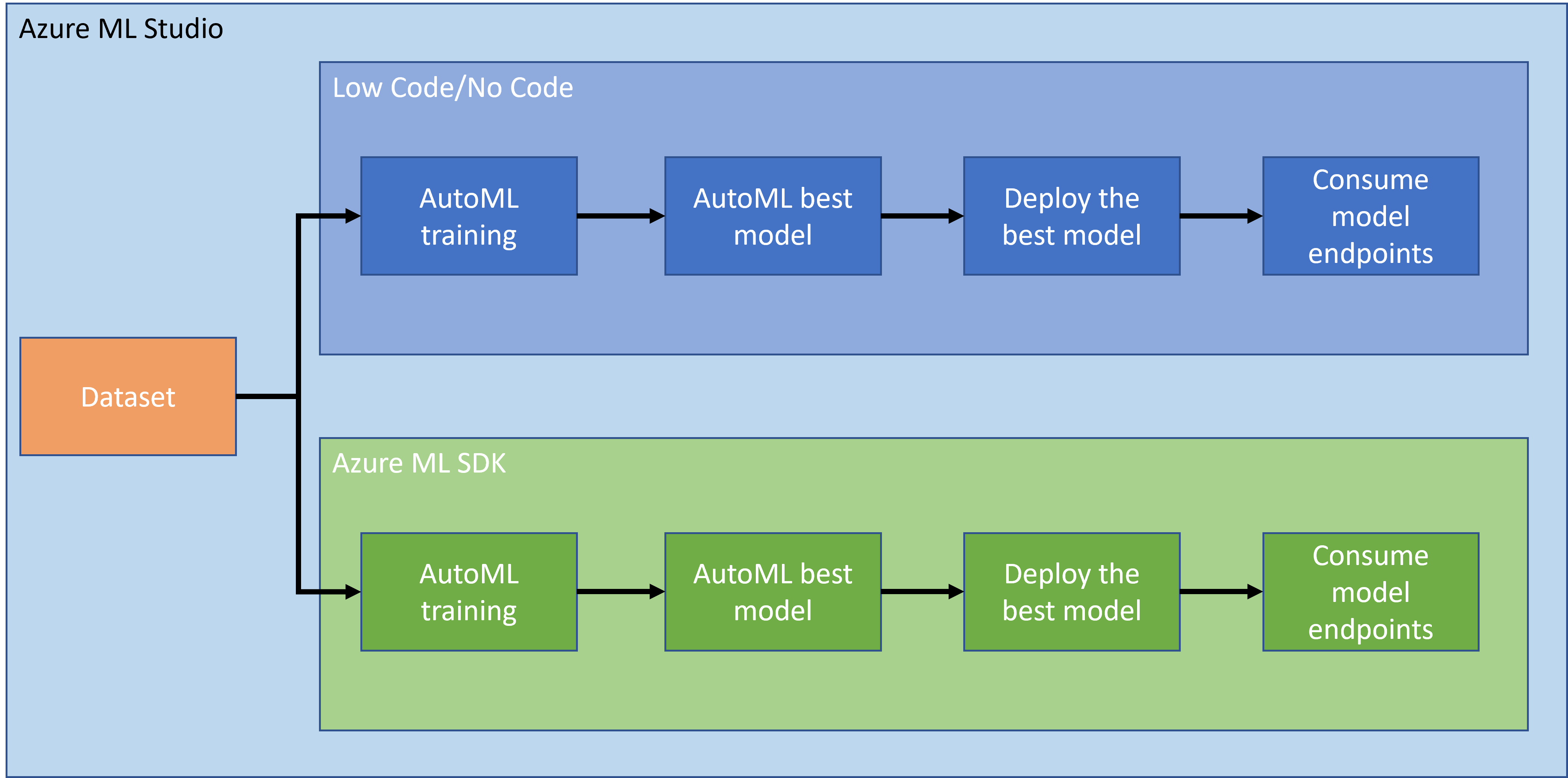
১.২ হার্ট ফেইলিউর প্রেডিকশন প্রকল্প এবং ডেটাসেট পরিচিতি
হার্ট ফেইলিউর প্রেডিকশন প্রকল্প এবং ডেটাসেট পরিচিতির জন্য এখানে দেখুন।
২. Azure ML SDK দিয়ে একটি মডেল প্রশিক্ষণ
২.১ Azure ML ওয়ার্কস্পেস তৈরি
সহজতার জন্য, আমরা একটি জুপিটার নোটবুকে কাজ করব। এর মানে হলো আপনার কাছে ইতিমধ্যেই একটি ওয়ার্কস্পেস এবং একটি কম্পিউট ইনস্ট্যান্স রয়েছে। যদি আপনার কাছে ইতিমধ্যেই একটি ওয়ার্কস্পেস থাকে, আপনি সরাসরি ২.৩ নোটবুক তৈরি বিভাগে যেতে পারেন।
যদি না থাকে, তাহলে পূর্ববর্তী পাঠে ২.১ Azure ML ওয়ার্কস্পেস তৈরি বিভাগে দেওয়া নির্দেশনা অনুসরণ করুন।
২.২ কম্পিউট ইনস্ট্যান্স তৈরি
আমরা আগে তৈরি করা Azure ML ওয়ার্কস্পেস এ যান এবং কম্পিউট মেনুতে যান। এখানে আপনি বিভিন্ন কম্পিউট রিসোর্স দেখতে পাবেন।

জুপিটার নোটবুক প্রভিশন করার জন্য একটি কম্পিউট ইনস্ট্যান্স তৈরি করুন।
-
- New বোতামে ক্লিক করুন।
- আপনার কম্পিউট ইনস্ট্যান্সের জন্য একটি নাম দিন।
- আপনার অপশন নির্বাচন করুন: CPU বা GPU, VM সাইজ এবং কোর সংখ্যা।
- Create বোতামে ক্লিক করুন।
অভিনন্দন, আপনি একটি কম্পিউট ইনস্ট্যান্স তৈরি করেছেন! আমরা এই কম্পিউট ইনস্ট্যান্সটি নোটবুক তৈরি বিভাগে ব্যবহার করব।
২.৩ ডেটাসেট লোড করা
যদি আপনি এখনও ডেটাসেট আপলোড না করে থাকেন, তাহলে পূর্ববর্তী পাঠে ২.৩ ডেটাসেট লোড করা বিভাগটি দেখুন।
২.৪ নোটবুক তৈরি
নোট: পরবর্তী ধাপের জন্য আপনি নতুন নোটবুক তৈরি করতে পারেন অথবা আমরা তৈরি করা নোটবুক আপলোড করতে পারেন। আপলোড করতে, "Notebook" মেনুতে ক্লিক করুন এবং নোটবুকটি আপলোড করুন।
নোটবুক ডেটা সায়েন্স প্রক্রিয়ার একটি গুরুত্বপূর্ণ অংশ। এগুলো ব্যবহার করে Exploratory Data Analysis (EDA) করা যায়, কম্পিউট ক্লাস্টারে মডেল প্রশিক্ষণ করা যায়, এবং ইনফারেন্স ক্লাস্টারে এন্ডপয়েন্ট ডিপ্লয় করা যায়।
নোটবুক তৈরি করতে, আমাদের একটি কম্পিউট নোড দরকার যা জুপিটার নোটবুক ইনস্ট্যান্স সরবরাহ করছে। Azure ML ওয়ার্কস্পেস এ ফিরে যান এবং কম্পিউট ইনস্ট্যান্সে ক্লিক করুন। আপনি আগে তৈরি করা কম্পিউট ইনস্ট্যান্স দেখতে পাবেন।
- Applications বিভাগে, Jupyter অপশনে ক্লিক করুন।
- "Yes, I understand" বক্সে টিক দিন এবং Continue বোতামে ক্লিক করুন।

- এটি একটি নতুন ব্রাউজার ট্যাব খুলবে যেখানে আপনার জুপিটার নোটবুক ইনস্ট্যান্স থাকবে। "New" বোতামে ক্লিক করে একটি নোটবুক তৈরি করুন।

এখন আমাদের কাছে একটি নোটবুক রয়েছে, আমরা Azure ML SDK দিয়ে মডেল প্রশিক্ষণ শুরু করতে পারি।
২.৫ মডেল প্রশিক্ষণ
প্রথমত, যদি আপনার কখনো সন্দেহ হয়, Azure ML SDK ডকুমেন্টেশন দেখুন। এটি এই পাঠে আমরা যে মডিউলগুলো দেখব তার সমস্ত প্রয়োজনীয় তথ্য ধারণ করে।
২.৫.১ ওয়ার্কস্পেস, এক্সপেরিমেন্ট, কম্পিউট ক্লাস্টার এবং ডেটাসেট সেটআপ
আপনাকে নিম্নলিখিত কোড ব্যবহার করে কনফিগারেশন ফাইল থেকে workspace লোড করতে হবে:
from azureml.core import Workspace
ws = Workspace.from_config()
এটি Workspace টাইপের একটি অবজেক্ট রিটার্ন করে যা ওয়ার্কস্পেসকে উপস্থাপন করে। এরপর আপনাকে নিম্নলিখিত কোড ব্যবহার করে একটি experiment তৈরি করতে হবে:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
ওয়ার্কস্পেস থেকে একটি এক্সপেরিমেন্ট পেতে বা তৈরি করতে, আপনাকে এক্সপেরিমেন্টের নাম ব্যবহার করে এটি অনুরোধ করতে হবে। এক্সপেরিমেন্টের নাম ৩-৩৬ অক্ষরের মধ্যে হতে হবে, একটি অক্ষর বা সংখ্যার মাধ্যমে শুরু করতে হবে এবং শুধুমাত্র অক্ষর, সংখ্যা, আন্ডারস্কোর এবং ড্যাশ থাকতে পারে। যদি ওয়ার্কস্পেসে এক্সপেরিমেন্ট পাওয়া না যায়, তাহলে একটি নতুন এক্সপেরিমেন্ট তৈরি করা হয়।
এখন আপনাকে নিম্নলিখিত কোড ব্যবহার করে প্রশিক্ষণের জন্য একটি কম্পিউট ক্লাস্টার তৈরি করতে হবে। মনে রাখবেন, এই ধাপটি কয়েক মিনিট সময় নিতে পারে।
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
আপনি নিম্নলিখিত পদ্ধতিতে ওয়ার্কস্পেস থেকে ডেটাসেট পেতে পারেন:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
২.৫.২ AutoML কনফিগারেশন এবং প্রশিক্ষণ
AutoML কনফিগারেশন সেট করতে, AutoMLConfig ক্লাস ব্যবহার করুন।
ডকুমেন্টেশনে বর্ণিত হিসাবে, আপনি অনেক প্যারামিটার নিয়ে কাজ করতে পারেন। এই প্রকল্পের জন্য, আমরা নিম্নলিখিত প্যারামিটার ব্যবহার করব:
experiment_timeout_minutes: এক্সপেরিমেন্ট চালানোর জন্য সর্বাধিক সময় (মিনিটে)।max_concurrent_iterations: এক্সপেরিমেন্টের জন্য অনুমোদিত সর্বাধিক একযোগে প্রশিক্ষণ পুনরাবৃত্তি।primary_metric: এক্সপেরিমেন্টের স্ট্যাটাস নির্ধারণের জন্য ব্যবহৃত প্রাথমিক মেট্রিক।compute_target: Automated Machine Learning এক্সপেরিমেন্ট চালানোর জন্য Azure Machine Learning কম্পিউট টার্গেট।task: চালানোর কাজের ধরন। 'classification', 'regression', বা 'forecasting' হতে পারে।training_data: এক্সপেরিমেন্টে ব্যবহৃত প্রশিক্ষণ ডেটা। এতে প্রশিক্ষণ বৈশিষ্ট্য এবং একটি লেবেল কলাম থাকতে হবে।label_column_name: লেবেল কলামের নাম।path: Azure Machine Learning প্রকল্প ফোল্ডারের সম্পূর্ণ পথ।enable_early_stopping: স্কোর স্বল্পমেয়াদে উন্নত না হলে প্রাথমিকভাবে বন্ধ করার অনুমতি।featurization: স্বয়ংক্রিয় বা কাস্টমাইজড ফিচারাইজেশন ব্যবহার করা হবে কিনা।debug_log: ডিবাগ তথ্য লেখার জন্য লগ ফাইল।
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
এখন আপনার কনফিগারেশন সেট হয়ে গেছে, আপনি নিম্নলিখিত কোড ব্যবহার করে মডেল প্রশিক্ষণ করতে পারেন। এই ধাপটি আপনার ক্লাস্টার সাইজের উপর নির্ভর করে এক ঘণ্টা পর্যন্ত সময় নিতে পারে।
remote_run = experiment.submit(automl_config)
আপনি RunDetails উইজেট চালিয়ে বিভিন্ন এক্সপেরিমেন্ট দেখতে পারেন।
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
৩. Azure ML SDK দিয়ে মডেল ডিপ্লয়মেন্ট এবং এন্ডপয়েন্ট ব্যবহার
৩.১ সেরা মডেল সংরক্ষণ
remote_run AutoMLRun টাইপের একটি অবজেক্ট। এই অবজেক্টে get_output() মেথড রয়েছে যা সেরা রান এবং সংশ্লিষ্ট ফিটেড মডেল রিটার্ন করে।
best_run, fitted_model = remote_run.get_output()
আপনি ফিটেড মডেল প্রিন্ট করে সেরা মডেলের ব্যবহৃত প্যারামিটার দেখতে পারেন এবং get_properties() মেথড ব্যবহার করে সেরা মডেলের বৈশিষ্ট্য দেখতে পারেন।
best_run.get_properties()
এখন register_model মেথড ব্যবহার করে মডেল রেজিস্টার করুন।
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
৩.২ মডেল ডিপ্লয়মেন্ট
সেরা মডেল সংরক্ষণ করার পর, আমরা InferenceConfig ক্লাস ব্যবহার করে এটি ডিপ্লয় করতে পারি। InferenceConfig ডিপ্লয়মেন্টের জন্য কাস্টম পরিবেশের কনফিগারেশন সেটিংস উপস্থাপন করে। AciWebservice ক্লাস Azure Container Instances-এ ওয়েব সার্ভিস এন্ডপয়েন্ট হিসেবে একটি মেশিন লার্নিং মডেল ডিপ্লয় করে। একটি ডিপ্লয়ড সার্ভিস একটি মডেল, স্ক্রিপ্ট এবং সংশ্লিষ্ট ফাইল থেকে তৈরি হয়। ফলস্বরূপ ওয়েব সার্ভিস একটি লোড-ব্যালেন্সড, HTTP এন্ডপয়েন্ট সহ একটি REST API হয়। আপনি এই API-তে ডেটা পাঠাতে পারেন এবং মডেলের রিটার্ন করা প্রেডিকশন পেতে পারেন।
মডেলটি deploy মেথড ব্যবহার করে ডিপ্লয় করা হয়।
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
এই ধাপটি কয়েক মিনিট সময় নিতে পারে।
৩.৩ এন্ডপয়েন্ট ব্যবহার
আপনার এন্ডপয়েন্ট ব্যবহার করতে একটি নমুনা ইনপুট তৈরি করুন:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
এরপর আপনি এই ইনপুটটি আপনার মডেলে প্রেডিকশনের জন্য পাঠাতে পারেন:
response = aci_service.run(input_data=test_sample)
response
এটি '{"result": [false]}' আউটপুট করবে। এর মানে হলো আমরা যে রোগীর তথ্য এন্ডপয়েন্টে পাঠিয়েছি, সেটি false পূর্বাভাস তৈরি করেছে, যা নির্দেশ করে এই ব্যক্তি হৃদরোগে আক্রান্ত হওয়ার সম্ভাবনা নেই।
অভিনন্দন! আপনি Azure ML SDK ব্যবহার করে Azure ML-এ প্রশিক্ষিত এবং ডিপ্লয় করা মডেলটি সফলভাবে ব্যবহার করেছেন!
NOTE: প্রকল্প শেষ করার পর, সমস্ত রিসোর্স মুছে ফেলতে ভুলবেন না।
🚀 চ্যালেঞ্জ
SDK ব্যবহার করে আরও অনেক কিছু করা সম্ভব, তবে দুর্ভাগ্যবশত আমরা এই পাঠে সবকিছু আলোচনা করতে পারি না। তবে সুখবর হলো, SDK ডকুমেন্টেশন স্কিম করার দক্ষতা আপনাকে অনেক দূর এগিয়ে নিয়ে যেতে পারে। Azure ML SDK ডকুমেন্টেশনটি দেখুন এবং Pipeline ক্লাসটি খুঁজে বের করুন যা আপনাকে পাইপলাইন তৈরি করতে সাহায্য করে। একটি পাইপলাইন হলো ধাপগুলোর একটি সংগ্রহ যা একটি ওয়ার্কফ্লো হিসেবে কার্যকর করা যায়।
HINT: SDK ডকুমেন্টেশন এ যান এবং সার্চ বারে "Pipeline" এর মতো কীওয়ার্ড টাইপ করুন। আপনার সার্চ রেজাল্টে azureml.pipeline.core.Pipeline ক্লাসটি থাকা উচিত।
পোস্ট-লেকচার কুইজ
পর্যালোচনা ও স্ব-অধ্যয়ন
এই পাঠে, আপনি শিখেছেন কীভাবে Azure ML SDK ব্যবহার করে ক্লাউডে হৃদরোগের ঝুঁকি পূর্বাভাসের জন্য একটি মডেল প্রশিক্ষণ, ডিপ্লয় এবং ব্যবহার করতে হয়। Azure ML SDK সম্পর্কে আরও তথ্যের জন্য এই ডকুমেন্টেশন দেখুন। Azure ML SDK ব্যবহার করে আপনার নিজস্ব মডেল তৈরি করার চেষ্টা করুন।
অ্যাসাইনমেন্ট
Azure ML SDK ব্যবহার করে ডেটা সায়েন্স প্রকল্প
অস্বীকৃতি:
এই নথিটি AI অনুবাদ পরিষেবা Co-op Translator ব্যবহার করে অনুবাদ করা হয়েছে। আমরা যথাসম্ভব সঠিক অনুবাদ প্রদানের চেষ্টা করি, তবে অনুগ্রহ করে মনে রাখবেন যে স্বয়ংক্রিয় অনুবাদে ত্রুটি বা অসঙ্গতি থাকতে পারে। মূল ভাষায় থাকা নথিটিকে প্রামাণিক উৎস হিসেবে বিবেচনা করা উচিত। গুরুত্বপূর্ণ তথ্যের জন্য, পেশাদার মানব অনুবাদ সুপারিশ করা হয়। এই অনুবাদ ব্যবহারের ফলে কোনো ভুল বোঝাবুঝি বা ভুল ব্যাখ্যা হলে আমরা দায়বদ্ধ থাকব না।