17 KiB
شہد کے تعلقات کی بصری نمائندگی: شہد کے بارے میں سب کچھ 🍯
 |
|---|
| تعلقات کی بصری نمائندگی - Sketchnote by @nitya |
ہماری تحقیق کی قدرتی توجہ کو جاری رکھتے ہوئے، آئیے مختلف اقسام کے شہد کے درمیان تعلقات کو ظاہر کرنے کے لیے دلچسپ بصری نمائندگیوں کو دریافت کریں، جو کہ امریکہ کے محکمہ زراعت سے حاصل کردہ ڈیٹا سیٹ پر مبنی ہیں۔
یہ ڈیٹا سیٹ تقریباً 600 اشیاء پر مشتمل ہے جو امریکہ کی مختلف ریاستوں میں شہد کی پیداوار کو ظاہر کرتا ہے۔ مثال کے طور پر، آپ دیکھ سکتے ہیں کہ 1998 سے 2012 کے درمیان کسی دی گئی ریاست میں ہر سال کے لیے شہد کے چھتوں کی تعداد، فی چھت پیداوار، کل پیداوار، ذخائر، فی پاؤنڈ قیمت، اور پیداوار کی قدر کیا تھی۔
یہ دلچسپ ہوگا کہ کسی دی گئی ریاست کی سالانہ پیداوار اور اس ریاست میں شہد کی قیمت کے درمیان تعلق کو بصری طور پر دکھایا جائے۔ متبادل طور پر، آپ ریاستوں کی فی چھت شہد کی پیداوار کے درمیان تعلق کو ظاہر کر سکتے ہیں۔ یہ سال 2006 میں پہلی بار دیکھے گئے 'CCD' یا 'Colony Collapse Disorder' (http://npic.orst.edu/envir/ccd.html) کے تباہ کن اثرات کا احاطہ کرتا ہے، اس لیے یہ مطالعہ کے لیے ایک اہم ڈیٹا سیٹ ہے۔ 🐝
لیکچر سے پہلے کا کوئز
اس سبق میں، آپ Seaborn کا استعمال کر سکتے ہیں، جسے آپ پہلے استعمال کر چکے ہیں، جو متغیرات کے درمیان تعلقات کو ظاہر کرنے کے لیے ایک اچھی لائبریری ہے۔ خاص طور پر دلچسپ بات یہ ہے کہ Seaborn کے relplot فنکشن کا استعمال، جو جلدی سے 'شماریاتی تعلقات' کو ظاہر کرنے کے لیے اسکیٹر پلاٹس اور لائن پلاٹس بنانے کی اجازت دیتا ہے، جس سے ڈیٹا سائنسدان کو بہتر طور پر سمجھنے میں مدد ملتی ہے کہ متغیرات ایک دوسرے سے کیسے جڑے ہوئے ہیں۔
اسکیٹر پلاٹس
اسکیٹر پلاٹ کا استعمال کریں تاکہ یہ دکھایا جا سکے کہ شہد کی قیمت سال بہ سال، ہر ریاست کے لیے، کیسے بدلی ہے۔ Seaborn، relplot کا استعمال کرتے ہوئے، ریاست کے ڈیٹا کو گروپ کرتا ہے اور زمرہ وار اور عددی ڈیٹا کے لیے ڈیٹا پوائنٹس کو ظاہر کرتا ہے۔
آئیے ڈیٹا اور Seaborn کو درآمد کرنے سے شروع کرتے ہیں:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
honey = pd.read_csv('../../data/honey.csv')
honey.head()
آپ دیکھیں گے کہ شہد کے ڈیٹا میں کئی دلچسپ کالمز ہیں، جن میں سال اور فی پاؤنڈ قیمت شامل ہیں۔ آئیے اس ڈیٹا کو دریافت کریں، جو امریکی ریاستوں کے لحاظ سے گروپ کیا گیا ہے:
| ریاست | چھتوں کی تعداد | فی چھت پیداوار | کل پیداوار | ذخائر | فی پاؤنڈ قیمت | پیداوار کی قدر | سال |
|---|---|---|---|---|---|---|---|
| AL | 16000 | 71 | 1136000 | 159000 | 0.72 | 818000 | 1998 |
| AZ | 55000 | 60 | 3300000 | 1485000 | 0.64 | 2112000 | 1998 |
| AR | 53000 | 65 | 3445000 | 1688000 | 0.59 | 2033000 | 1998 |
| CA | 450000 | 83 | 37350000 | 12326000 | 0.62 | 23157000 | 1998 |
| CO | 27000 | 72 | 1944000 | 1594000 | 0.7 | 1361000 | 1998 |
ایک بنیادی اسکیٹر پلاٹ بنائیں تاکہ یہ دکھایا جا سکے کہ شہد کی فی پاؤنڈ قیمت اور اس کی امریکی ریاست کے درمیان کیا تعلق ہے۔ y محور کو اتنا لمبا بنائیں کہ تمام ریاستیں نظر آئیں:
sns.relplot(x="priceperlb", y="state", data=honey, height=15, aspect=.5);
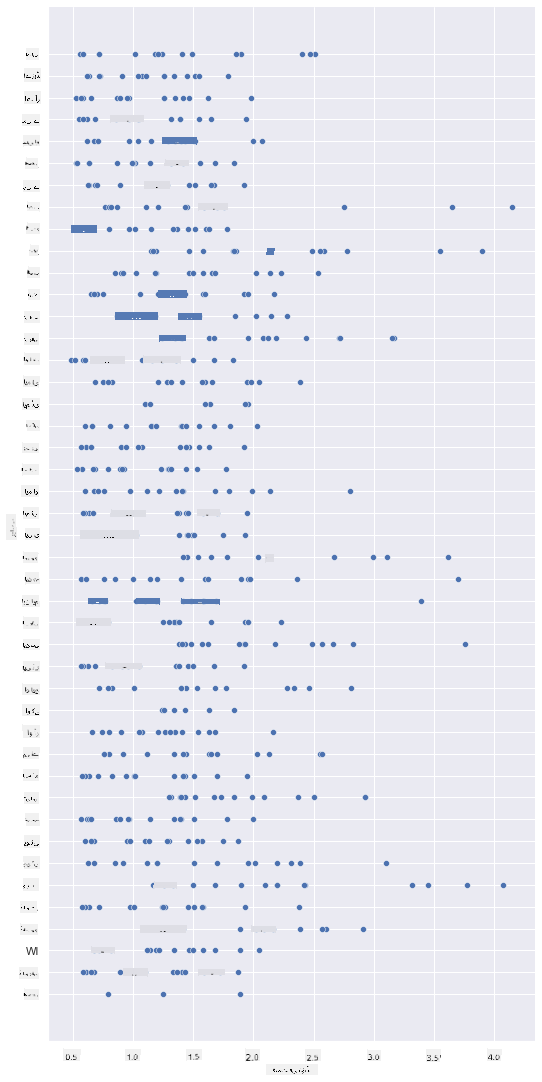
اب، وہی ڈیٹا شہد کے رنگ سکیم کے ساتھ دکھائیں تاکہ یہ ظاہر ہو کہ قیمت سال بہ سال کیسے بدلی ہے۔ آپ یہ 'hue' پیرامیٹر شامل کر کے کر سکتے ہیں تاکہ تبدیلی کو ظاہر کیا جا سکے:
✅ Seaborn میں استعمال ہونے والے رنگ سکیمز کے بارے میں مزید جانیں - ایک خوبصورت قوس قزح رنگ سکیم آزمائیں!
sns.relplot(x="priceperlb", y="state", hue="year", palette="YlOrBr", data=honey, height=15, aspect=.5);
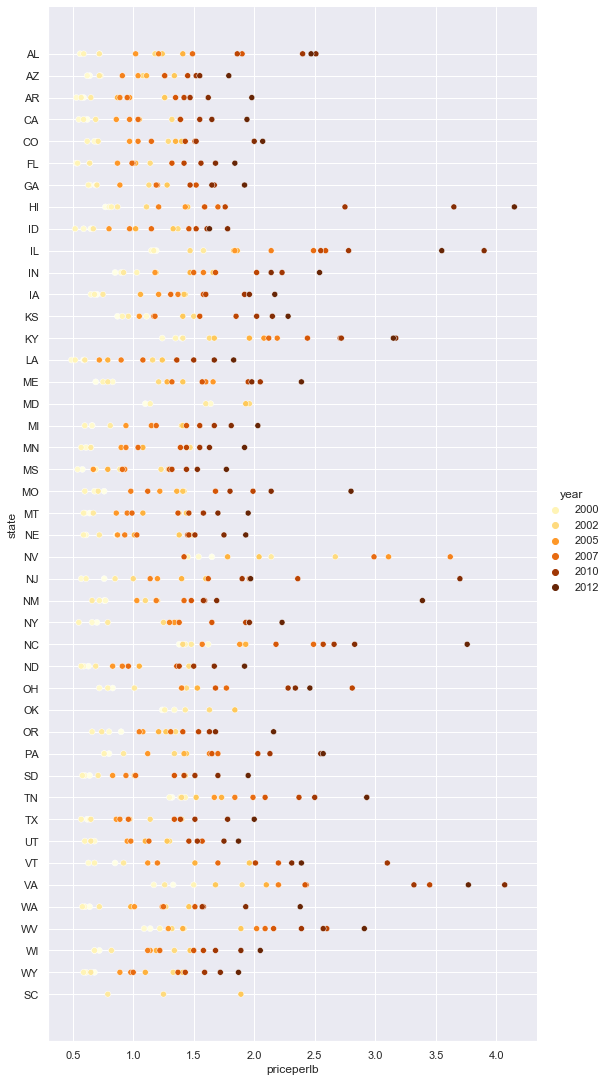
اس رنگ سکیم کی تبدیلی کے ساتھ، آپ واضح طور پر دیکھ سکتے ہیں کہ سال بہ سال شہد کی فی پاؤنڈ قیمت میں ایک مضبوط ترقی ہے۔ درحقیقت، اگر آپ ڈیٹا کے ایک نمونے کو جانچنے کے لیے دیکھیں (مثال کے طور پر، ایریزونا ریاست)، تو آپ دیکھ سکتے ہیں کہ قیمت میں سال بہ سال اضافے کا ایک نمونہ موجود ہے، چند استثنائی صورتوں کے ساتھ:
| ریاست | چھتوں کی تعداد | فی چھت پیداوار | کل پیداوار | ذخائر | فی پاؤنڈ قیمت | پیداوار کی قدر | سال |
|---|---|---|---|---|---|---|---|
| AZ | 55000 | 60 | 3300000 | 1485000 | 0.64 | 2112000 | 1998 |
| AZ | 52000 | 62 | 3224000 | 1548000 | 0.62 | 1999000 | 1999 |
| AZ | 40000 | 59 | 2360000 | 1322000 | 0.73 | 1723000 | 2000 |
| AZ | 43000 | 59 | 2537000 | 1142000 | 0.72 | 1827000 | 2001 |
| AZ | 38000 | 63 | 2394000 | 1197000 | 1.08 | 2586000 | 2002 |
| AZ | 35000 | 72 | 2520000 | 983000 | 1.34 | 3377000 | 2003 |
| AZ | 32000 | 55 | 1760000 | 774000 | 1.11 | 1954000 | 2004 |
| AZ | 36000 | 50 | 1800000 | 720000 | 1.04 | 1872000 | 2005 |
| AZ | 30000 | 65 | 1950000 | 839000 | 0.91 | 1775000 | 2006 |
| AZ | 30000 | 64 | 1920000 | 902000 | 1.26 | 2419000 | 2007 |
| AZ | 25000 | 64 | 1600000 | 336000 | 1.26 | 2016000 | 2008 |
| AZ | 20000 | 52 | 1040000 | 562000 | 1.45 | 1508000 | 2009 |
| AZ | 24000 | 77 | 1848000 | 665000 | 1.52 | 2809000 | 2010 |
| AZ | 23000 | 53 | 1219000 | 427000 | 1.55 | 1889000 | 2011 |
| AZ | 22000 | 46 | 1012000 | 253000 | 1.79 | 1811000 | 2012 |
ایک اور طریقہ یہ ہے کہ اس ترقی کو رنگ کے بجائے سائز کے ذریعے ظاہر کیا جائے۔ رنگ اندھے صارفین کے لیے، یہ ایک بہتر آپشن ہو سکتا ہے۔ اپنی بصری نمائندگی کو اس طرح ایڈٹ کریں کہ قیمت میں اضافے کو نقطے کے دائرے کے سائز میں اضافے کے ذریعے دکھایا جائے:
sns.relplot(x="priceperlb", y="state", size="year", data=honey, height=15, aspect=.5);
آپ دیکھ سکتے ہیں کہ نقطوں کا سائز بتدریج بڑھ رہا ہے۔
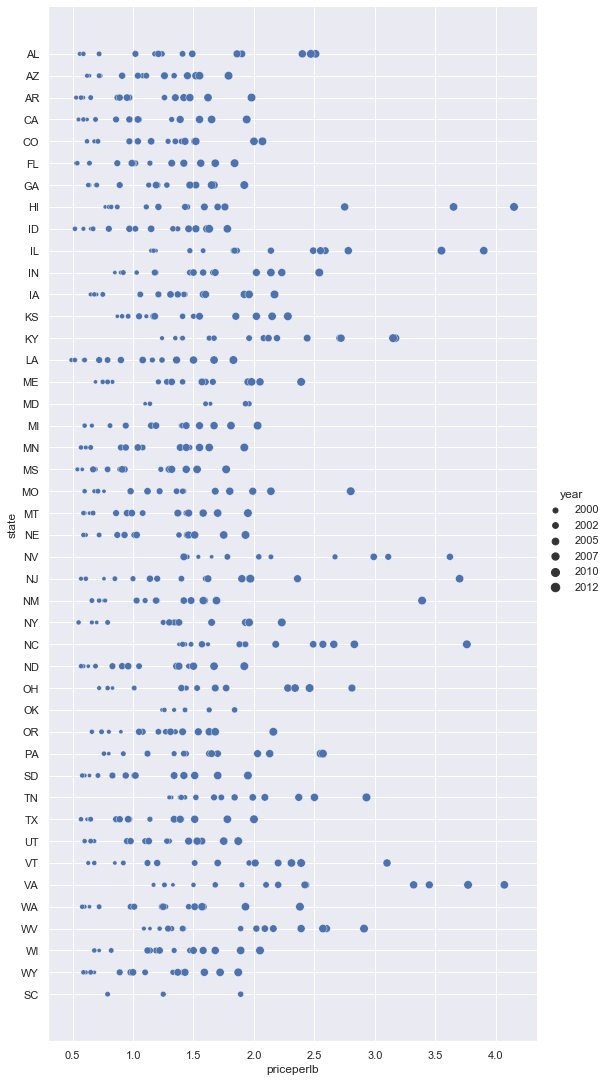
کیا یہ صرف طلب اور رسد کا معاملہ ہے؟ موسمیاتی تبدیلی اور کالونی کے خاتمے جیسے عوامل کی وجہ سے، کیا سال بہ سال خریداری کے لیے کم شہد دستیاب ہے، اور اس لیے قیمت بڑھ رہی ہے؟
اس ڈیٹا سیٹ میں کچھ متغیرات کے درمیان تعلق کو دریافت کرنے کے لیے، آئیے کچھ لائن چارٹس کا جائزہ لیں۔
لائن چارٹس
سوال: کیا شہد کی فی پاؤنڈ قیمت میں سال بہ سال واضح اضافہ ہے؟ آپ اسے سب سے آسانی سے ایک لائن چارٹ بنا کر دریافت کر سکتے ہیں:
sns.relplot(x="year", y="priceperlb", kind="line", data=honey);
جواب: ہاں، کچھ استثنائی صورتوں کے ساتھ، خاص طور پر 2003 کے آس پاس:
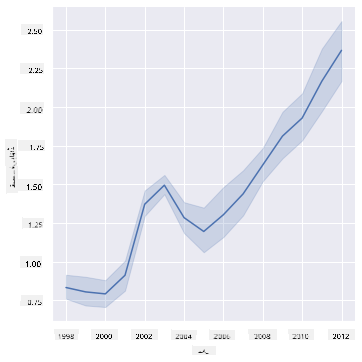
✅ چونکہ Seaborn ایک لائن کے ارد گرد ڈیٹا کو جمع کر رہا ہے، یہ "ہر x ویلیو پر متعدد پیمائشوں کو اوسط اور اوسط کے ارد گرد 95% اعتماد کے وقفے کو پلاٹ کر کے ظاہر کرتا ہے"۔ ماخذ۔ اس وقت لینے والے رویے کو ci=None شامل کر کے غیر فعال کیا جا سکتا ہے۔
سوال: ٹھیک ہے، کیا ہم 2003 میں شہد کی فراہمی میں بھی اضافہ دیکھ سکتے ہیں؟ اگر آپ کل پیداوار کو سال بہ سال دیکھیں تو کیا ہوگا؟
sns.relplot(x="year", y="totalprod", kind="line", data=honey);
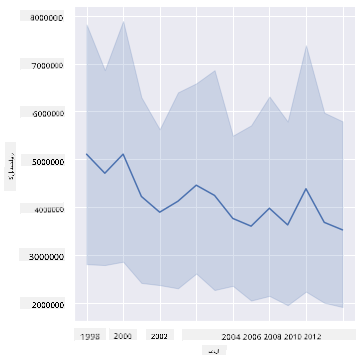
جواب: واقعی نہیں۔ اگر آپ کل پیداوار کو دیکھیں، تو یہ خاص سال میں درحقیقت بڑھتی ہوئی نظر آتی ہے، حالانکہ عمومی طور پر ان سالوں کے دوران شہد کی پیداوار میں کمی ہو رہی ہے۔
سوال: اس صورت میں، 2003 کے آس پاس شہد کی قیمت میں اضافے کی وجہ کیا ہو سکتی ہے؟
یہ دریافت کرنے کے لیے، آپ ایک فیسٹ گرڈ کا جائزہ لے سکتے ہیں۔
فیسٹ گرڈز
فیسٹ گرڈز آپ کے ڈیٹا سیٹ کے ایک پہلو کو لیتے ہیں (ہمارے معاملے میں، آپ 'سال' کو منتخب کر سکتے ہیں تاکہ بہت زیادہ فیسٹس پیدا نہ ہوں)۔ پھر Seaborn آپ کے منتخب کردہ x اور y کوآرڈینیٹس کے لیے ہر فیسٹ کا ایک پلاٹ بنا سکتا ہے تاکہ بصری موازنہ آسان ہو۔ کیا 2003 اس قسم کے موازنہ میں نمایاں نظر آتا ہے؟
Seaborn کی دستاویزات میں تجویز کردہ فیسٹ گرڈ کا استعمال جاری رکھتے ہوئے relplot کا استعمال کرتے ہوئے ایک فیسٹ گرڈ بنائیں۔
sns.relplot(
data=honey,
x="yieldpercol", y="numcol",
col="year",
col_wrap=3,
kind="line"
اس بصری نمائندگی میں، آپ فی چھت پیداوار اور چھتوں کی تعداد کو سال بہ سال، ریاست بہ ریاست، 3 کالمز کے ساتھ موازنہ کر سکتے ہیں:
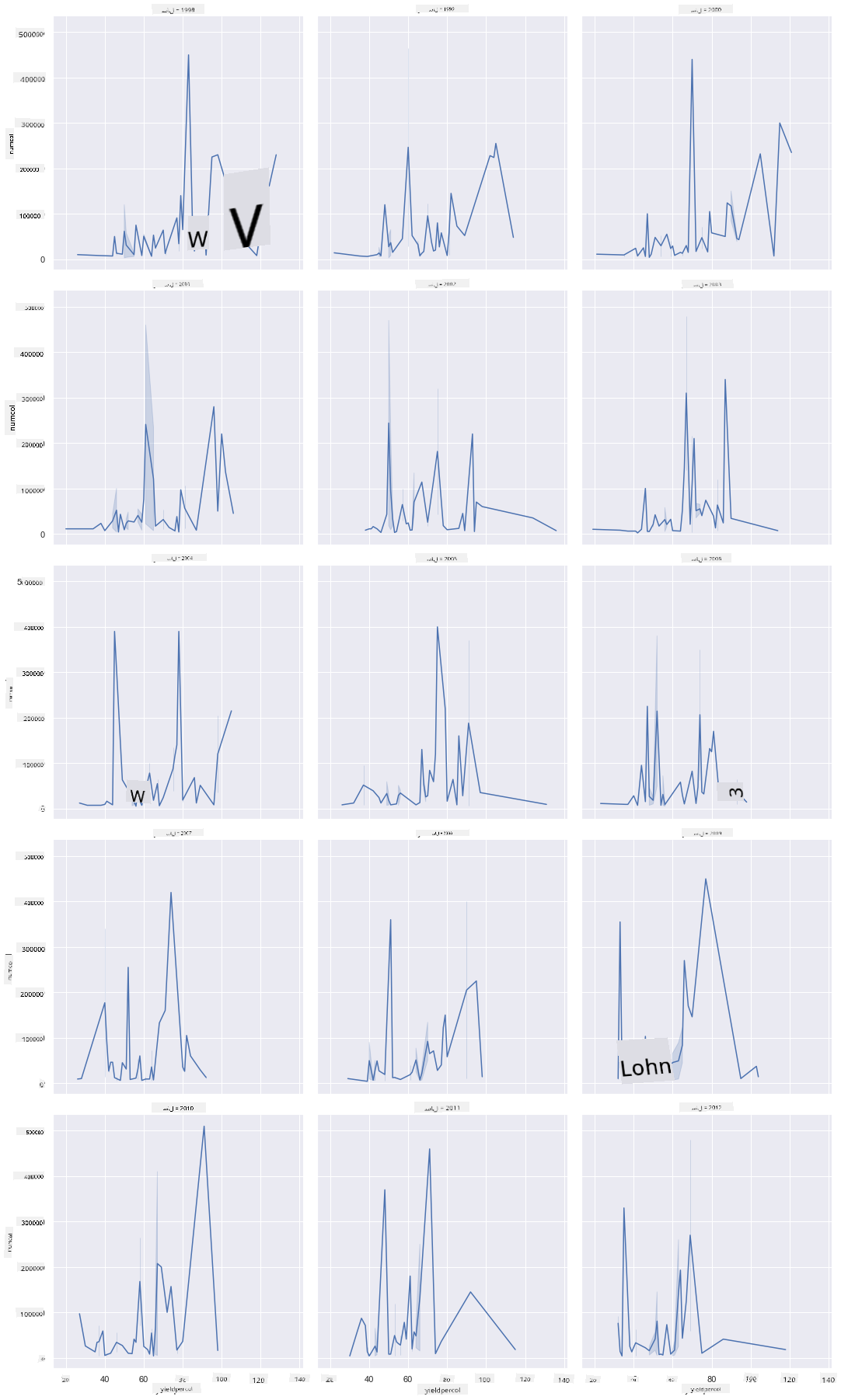
اس ڈیٹا سیٹ کے لیے، ریاست بہ ریاست اور سال بہ سال، چھتوں کی تعداد اور ان کی پیداوار کے حوالے سے کچھ خاص نمایاں نہیں ہوتا۔ کیا ان دو متغیرات کے درمیان تعلق تلاش کرنے کا کوئی مختلف طریقہ ہے؟
دوہری لائن پلاٹس
Seaborn کے 'despine' کا استعمال کرتے ہوئے دو لائن پلاٹس کو ایک دوسرے کے اوپر سپر امپوز کرنے کی کوشش کریں، اور ax.twinx کا استعمال کریں جو Matplotlib سے ماخوذ ہے۔ Twinx ایک چارٹ کو x محور کا اشتراک کرنے اور دو y محور کو ظاہر کرنے کی اجازت دیتا ہے۔ تو، فی چھت پیداوار اور چھتوں کی تعداد کو سپر امپوزڈ دکھائیں:
fig, ax = plt.subplots(figsize=(12,6))
lineplot = sns.lineplot(x=honey['year'], y=honey['numcol'], data=honey,
label = 'Number of bee colonies', legend=False)
sns.despine()
plt.ylabel('# colonies')
plt.title('Honey Production Year over Year');
ax2 = ax.twinx()
lineplot2 = sns.lineplot(x=honey['year'], y=honey['yieldpercol'], ax=ax2, color="r",
label ='Yield per colony', legend=False)
sns.despine(right=False)
plt.ylabel('colony yield')
ax.figure.legend();
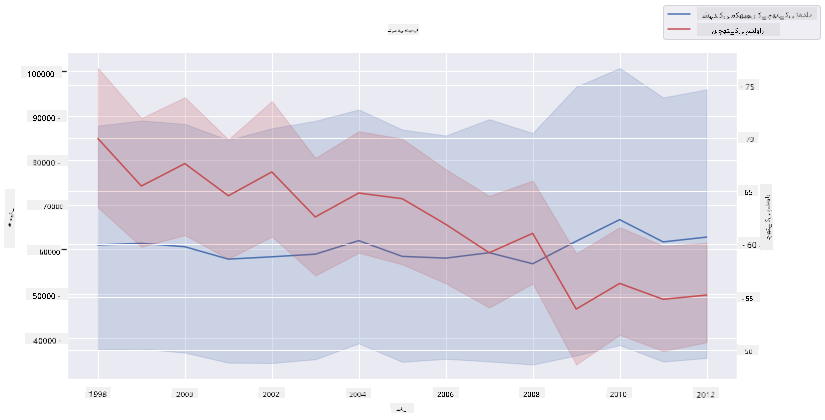
جبکہ 2003 کے آس پاس آنکھ کو کچھ خاص نظر نہیں آتا، یہ ہمیں اس سبق کو ایک خوشگوار نوٹ پر ختم کرنے کی اجازت دیتا ہے: اگرچہ مجموعی طور پر چھتوں کی تعداد میں کمی ہو رہی ہے، لیکن چھتوں کی تعداد مستحکم ہو رہی ہے، چاہے ان کی فی چھت پیداوار کم ہو رہی ہو۔
چلو، شہد کی مکھیوں، چلو!
🐝❤️
🚀 چیلنج
اس سبق میں، آپ نے اسکیٹر پلاٹس اور لائن گرڈز کے دیگر استعمالات کے بارے میں مزید سیکھا، بشمول فیسٹ گرڈز۔ اپنے آپ کو چیلنج کریں کہ کسی مختلف ڈیٹا سیٹ کا استعمال کرتے ہوئے ایک فیسٹ گرڈ بنائیں، شاید وہی جو آپ نے ان اسباق سے پہلے استعمال کیا ہو۔ نوٹ کریں کہ انہیں بنانے میں کتنا وقت لگتا ہے اور آپ کو ان تکنیکوں کا استعمال کرتے ہوئے کتنے گرڈز بنانے میں محتاط رہنے کی ضرورت ہے۔
لیکچر کے بعد کا کوئز
جائزہ اور خود مطالعہ
لائن پلاٹس سادہ یا کافی پیچیدہ ہو سکتے ہیں۔ Seaborn کی دستاویزات میں لائن پلاٹ کے مختلف طریقوں پر تھوڑا سا مطالعہ کریں۔ ان طریقوں کو استعمال کرتے ہوئے اس سبق میں بنائے گئے لائن چارٹس کو بہتر بنانے کی کوشش کریں۔
اسائنمنٹ
ڈسکلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے پوری کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا خامیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے لیے ہم ذمہ دار نہیں ہیں۔