32 KiB
ڈیٹا کے ساتھ کام کرنا: پائتھون اور پانڈاز لائبریری
 |
|---|
| پائتھون کے ساتھ کام کرنا - @nitya کی اسکیچ نوٹ |
ڈیٹا بیسز ڈیٹا کو محفوظ کرنے اور انہیں کوئری زبانوں کے ذریعے تلاش کرنے کے لیے بہت مؤثر طریقے فراہم کرتے ہیں، لیکن ڈیٹا پروسیسنگ کا سب سے لچکدار طریقہ اپنا پروگرام لکھ کر ڈیٹا کو تبدیل کرنا ہے۔ اکثر اوقات، ڈیٹا بیس کوئری کرنا زیادہ مؤثر ہوتا ہے۔ لیکن کچھ معاملات میں جب زیادہ پیچیدہ ڈیٹا پروسیسنگ کی ضرورت ہو، تو یہ کام SQL کے ذریعے آسانی سے نہیں کیا جا سکتا۔
ڈیٹا پروسیسنگ کسی بھی پروگرامنگ زبان میں کی جا سکتی ہے، لیکن کچھ زبانیں ڈیٹا کے ساتھ کام کرنے کے لحاظ سے زیادہ اعلیٰ سطح کی ہوتی ہیں۔ ڈیٹا سائنسدان عام طور پر درج ذیل زبانوں میں سے ایک کو ترجیح دیتے ہیں:
- پائتھون، ایک عمومی مقصد کی پروگرامنگ زبان، جو اپنی سادگی کی وجہ سے اکثر ابتدائی افراد کے لیے بہترین آپشن سمجھی جاتی ہے۔ پائتھون میں بہت سی اضافی لائبریریاں موجود ہیں جو آپ کو عملی مسائل حل کرنے میں مدد دے سکتی ہیں، جیسے کہ ZIP آرکائیو سے ڈیٹا نکالنا یا تصویر کو گرے اسکیل میں تبدیل کرنا۔ ڈیٹا سائنس کے علاوہ، پائتھون ویب ڈیولپمنٹ کے لیے بھی اکثر استعمال ہوتی ہے۔
- آر ایک روایتی ٹول باکس ہے جو شماریاتی ڈیٹا پروسیسنگ کے لیے بنایا گیا ہے۔ اس میں لائبریریوں کا بڑا ذخیرہ (CRAN) موجود ہے، جو اسے ڈیٹا پروسیسنگ کے لیے ایک اچھا انتخاب بناتا ہے۔ تاہم، آر ایک عمومی مقصد کی پروگرامنگ زبان نہیں ہے اور ڈیٹا سائنس کے دائرے سے باہر شاذ و نادر ہی استعمال ہوتی ہے۔
- جولیا ایک اور زبان ہے جو خاص طور پر ڈیٹا سائنس کے لیے تیار کی گئی ہے۔ یہ پائتھون سے بہتر کارکردگی فراہم کرنے کے لیے بنائی گئی ہے، جو اسے سائنسی تجربات کے لیے ایک بہترین ٹول بناتی ہے۔
اس سبق میں، ہم پائتھون کا استعمال کرتے ہوئے سادہ ڈیٹا پروسیسنگ پر توجہ مرکوز کریں گے۔ ہم زبان کی بنیادی واقفیت فرض کریں گے۔ اگر آپ پائتھون کا گہرا جائزہ لینا چاہتے ہیں، تو آپ درج ذیل وسائل میں سے کسی ایک کا حوالہ دے سکتے ہیں:
- پائتھون کو تفریحی طریقے سے سیکھیں: ٹرٹل گرافکس اور فرکٹلز کے ساتھ - پائتھون پروگرامنگ کا ایک مختصر تعارفی کورس
- پائتھون کے ساتھ اپنے پہلے قدم اٹھائیں Microsoft Learn پر لرننگ پاتھ
ڈیٹا مختلف شکلوں میں آ سکتا ہے۔ اس سبق میں، ہم ڈیٹا کی تین شکلوں پر غور کریں گے - ٹیبلر ڈیٹا، متن اور تصاویر۔
ہم آپ کو تمام متعلقہ لائبریریوں کا مکمل جائزہ دینے کے بجائے ڈیٹا پروسیسنگ کی چند مثالوں پر توجہ مرکوز کریں گے۔ اس سے آپ کو یہ سمجھنے میں مدد ملے گی کہ کیا ممکن ہے، اور جب آپ کو ضرورت ہو تو اپنے مسائل کے حل تلاش کرنے کے لیے کہاں جانا ہے۔
سب سے مفید مشورہ۔ جب آپ کو ڈیٹا پر کوئی خاص آپریشن کرنے کی ضرورت ہو اور آپ کو معلوم نہ ہو کہ اسے کیسے کرنا ہے، تو انٹرنیٹ پر تلاش کرنے کی کوشش کریں۔ Stackoverflow عام طور پر پائتھون میں بہت سے عام کاموں کے لیے مفید کوڈ نمونے فراہم کرتا ہے۔
لیکچر سے پہلے کا کوئز
ٹیبلر ڈیٹا اور ڈیٹا فریمز
آپ پہلے ہی ٹیبلر ڈیٹا سے واقف ہو چکے ہیں جب ہم نے ریلیشنل ڈیٹا بیسز کے بارے میں بات کی تھی۔ جب آپ کے پاس بہت زیادہ ڈیٹا ہو، اور یہ مختلف جڑی ہوئی ٹیبلز میں موجود ہو، تو اس کے ساتھ کام کرنے کے لیے SQL کا استعمال کرنا یقینی طور پر معنی رکھتا ہے۔ تاہم، بہت سے معاملات میں جب ہمارے پاس ڈیٹا کی ایک ٹیبل ہو، اور ہمیں اس ڈیٹا کے بارے میں کچھ سمجھ یا بصیرت حاصل کرنی ہو، جیسے کہ تقسیم، اقدار کے درمیان تعلق، وغیرہ۔ ڈیٹا سائنس میں، بہت سے معاملات میں ہمیں اصل ڈیٹا کی کچھ تبدیلیاں کرنے کی ضرورت ہوتی ہے، جس کے بعد بصری نمائندگی کی جاتی ہے۔ یہ دونوں مراحل پائتھون کا استعمال کرتے ہوئے آسانی سے کیے جا سکتے ہیں۔
پائتھون میں دو سب سے مفید لائبریریاں ہیں جو آپ کو ٹیبلر ڈیٹا کے ساتھ کام کرنے میں مدد دے سکتی ہیں:
- پانڈاز آپ کو ڈیٹا فریمز کے ساتھ کام کرنے کی اجازت دیتا ہے، جو ریلیشنل ٹیبلز کے مترادف ہیں۔ آپ نامزد کالمز رکھ سکتے ہیں، اور قطاروں، کالمز اور ڈیٹا فریمز پر مختلف آپریشنز انجام دے سکتے ہیں۔
- نمپائی ایک لائبریری ہے جو ٹینسرز، یعنی کثیر جہتی ارے کے ساتھ کام کرنے کے لیے استعمال ہوتی ہے۔ ارے میں ایک ہی بنیادی قسم کی اقدار ہوتی ہیں، اور یہ ڈیٹا فریم سے زیادہ سادہ ہوتا ہے، لیکن یہ زیادہ ریاضیاتی آپریشنز فراہم کرتا ہے اور کم اوور ہیڈ پیدا کرتا ہے۔
کچھ دیگر لائبریریاں بھی ہیں جن کے بارے میں آپ کو معلوم ہونا چاہیے:
- میٹپلاٹلب ڈیٹا کی بصری نمائندگی اور گراف بنانے کے لیے استعمال ہونے والی لائبریری ہے
- سائپائی کچھ اضافی سائنسی فنکشنز کے ساتھ ایک لائبریری ہے۔ ہم پہلے ہی اس لائبریری سے واقف ہو چکے ہیں جب ہم نے احتمال اور شماریات کے بارے میں بات کی تھی
یہاں ایک کوڈ کا ٹکڑا ہے جو آپ عام طور پر اپنے پائتھون پروگرام کے آغاز میں ان لائبریریوں کو درآمد کرنے کے لیے استعمال کریں گے:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
پانڈاز چند بنیادی تصورات کے گرد مرکوز ہے۔
سیریز
سیریز اقدار کا ایک سلسلہ ہے، جو فہرست یا نمپائی ارے کی طرح ہے۔ بنیادی فرق یہ ہے کہ سیریز میں ایک انڈیکس بھی ہوتا ہے، اور جب ہم سیریز پر آپریشن کرتے ہیں (جیسے، انہیں جمع کرتے ہیں)، تو انڈیکس کو مدنظر رکھا جاتا ہے۔ انڈیکس اتنا سادہ ہو سکتا ہے جتنا کہ عددی قطار نمبر (یہ وہ انڈیکس ہے جو فہرست یا ارے سے سیریز بناتے وقت ڈیفالٹ کے طور پر استعمال ہوتا ہے)، یا اس کی پیچیدہ ساخت ہو سکتی ہے، جیسے کہ تاریخ کا وقفہ۔
نوٹ: اس کے ساتھ موجود نوٹ بک
notebook.ipynbمیں پانڈاز کا کچھ ابتدائی کوڈ موجود ہے۔ ہم یہاں صرف چند مثالیں پیش کرتے ہیں، اور آپ کو مکمل نوٹ بک دیکھنے کی دعوت دیتے ہیں۔
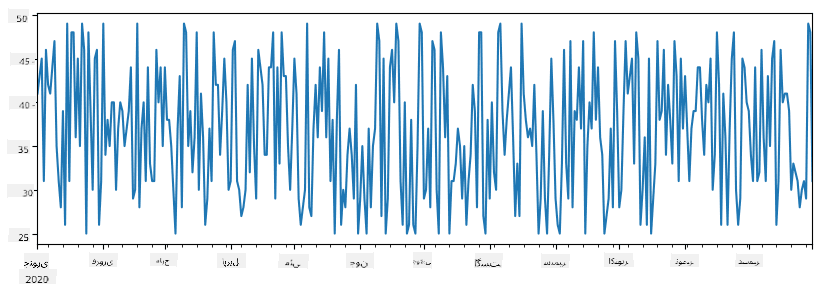
ایک مثال پر غور کریں: ہم اپنی آئس کریم کی دکان کی فروخت کا تجزیہ کرنا چاہتے ہیں۔ آئیے کچھ وقت کے لیے فروخت کے نمبروں (ہر دن فروخت ہونے والی اشیاء کی تعداد) کی ایک سیریز بنائیں:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
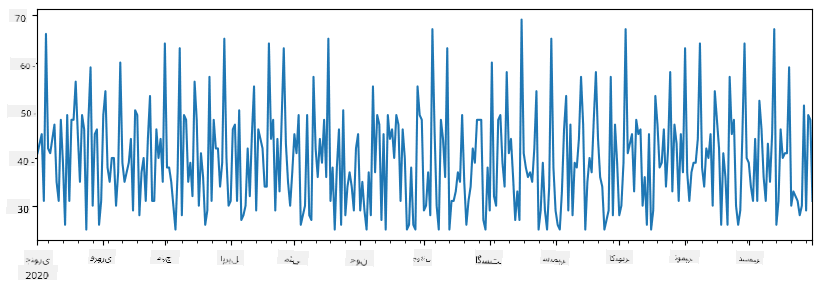
اب فرض کریں کہ ہر ہفتے ہم دوستوں کے لیے ایک پارٹی کا اہتمام کرتے ہیں، اور پارٹی کے لیے آئس کریم کے اضافی 10 پیک لیتے ہیں۔ ہم ایک اور سیریز بنا سکتے ہیں، جو ہفتے کے انڈیکس کے ذریعے ظاہر کی جائے:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
جب ہم دو سیریز کو جمع کرتے ہیں، تو ہمیں کل تعداد ملتی ہے:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
نوٹ کہ ہم سادہ نحو
total_items+additional_itemsاستعمال نہیں کر رہے ہیں۔ اگر ہم ایسا کرتے، تو ہمیں نتیجہ میں بہت سےNaN(Not a Number) اقدار ملتی۔ اس کی وجہ یہ ہے کہadditional_itemsسیریز میں کچھ انڈیکس پوائنٹس کے لیے اقدار موجود نہیں ہیں، اور کسی بھی چیز میںNaNشامل کرنے سے نتیجہNaNہوتا ہے۔ اس لیے ہمیں جمع کرتے وقتfill_valueپیرامیٹر کی وضاحت کرنی ہوتی ہے۔
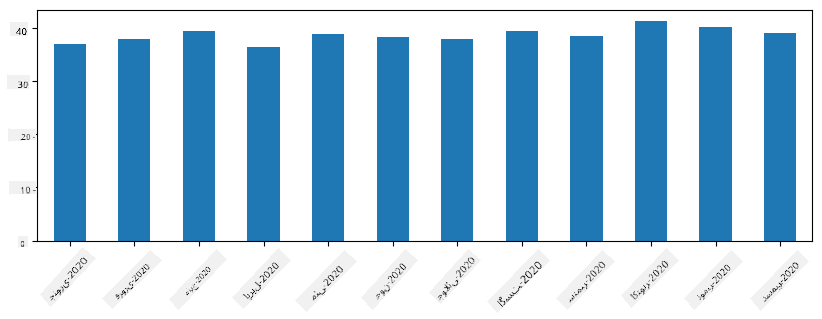
ٹائم سیریز کے ساتھ، ہم مختلف وقت کے وقفوں کے ساتھ سیریز کو دوبارہ نمونہ بنا سکتے ہیں۔ مثال کے طور پر، فرض کریں کہ ہم ماہانہ اوسط فروخت کا حجم حساب کرنا چاہتے ہیں۔ ہم درج ذیل کوڈ استعمال کر سکتے ہیں:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
ڈیٹا فریم
ڈیٹا فریم بنیادی طور پر ایک ہی انڈیکس کے ساتھ سیریز کا مجموعہ ہے۔ ہم کئی سیریز کو ایک ساتھ ڈیٹا فریم میں جمع کر سکتے ہیں:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
یہ ہمیں ایک افقی ٹیبل دے گا جیسے کہ یہ:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
ہم سیریز کو کالمز کے طور پر بھی استعمال کر سکتے ہیں، اور لغت کا استعمال کرتے ہوئے کالم کے ناموں کی وضاحت کر سکتے ہیں:
df = pd.DataFrame({ 'A' : a, 'B' : b })
یہ ہمیں ایک ٹیبل دے گا جیسے کہ یہ:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
نوٹ کہ ہم پچھلے ٹیبل کو ٹرانسپوز کر کے بھی یہ ٹیبل لے آ سکتے ہیں، جیسے کہ لکھ کر
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
یہاں .T ڈیٹا فریم کو ٹرانسپوز کرنے کا آپریشن ہے، یعنی قطاروں اور کالمز کو تبدیل کرنا، اور rename آپریشن ہمیں کالمز کو پچھلی مثال سے ملانے کے لیے نام تبدیل کرنے کی اجازت دیتا ہے۔
یہاں ڈیٹا فریمز پر انجام دی جانے والی چند اہم ترین آپریشنز ہیں:
کالم کا انتخاب۔ ہم انفرادی کالمز کو df['A'] لکھ کر منتخب کر سکتے ہیں - یہ آپریشن ایک سیریز واپس کرتا ہے۔ ہم کالمز کے ایک ذیلی سیٹ کو دوسرے ڈیٹا فریم میں منتخب کر سکتے ہیں df[['B','A']] لکھ کر - یہ ایک اور ڈیٹا فریم واپس کرتا ہے۔
فلٹرنگ صرف مخصوص قطاروں کو معیار کے مطابق۔ مثال کے طور پر، کالم A کے ساتھ صرف وہ قطاریں چھوڑنے کے لیے جو 5 سے زیادہ ہوں، ہم لکھ سکتے ہیں df[df['A']>5]۔
نوٹ: فلٹرنگ کا کام کرنے کا طریقہ درج ذیل ہے۔ اظہار
df['A']<5ایک بولین سیریز واپس کرتا ہے، جو ظاہر کرتا ہے کہ آیا اظہار اصل سیریزdf['A']کے ہر عنصر کے لیےTrueیاFalseہے۔ جب بولین سیریز کو انڈیکس کے طور پر استعمال کیا جاتا ہے، تو یہ ڈیٹا فریم میں قطاروں کا ذیلی سیٹ واپس کرتا ہے۔ اس لیے کسی بھی بے ترتیب پائتھون بولین اظہار کا استعمال ممکن نہیں ہے، مثال کے طور پر، لکھناdf[df['A']>5 and df['A']<7]غلط ہوگا۔ اس کے بجائے، آپ کو بولین سیریز پر خاص&آپریشن استعمال کرنا چاہیے، لکھ کرdf[(df['A']>5) & (df['A']<7)](بریکٹس یہاں اہم ہیں)۔
نئے قابل حساب کالمز بنانا۔ ہم اپنے ڈیٹا فریم کے لیے نئے قابل حساب کالمز آسانی سے بنا سکتے ہیں، جیسے کہ یہ:
df['DivA'] = df['A']-df['A'].mean()
یہ مثال A کی اس کی اوسط قدر سے انحراف کا حساب لگاتی ہے۔ یہاں جو اصل میں ہوتا ہے وہ یہ ہے کہ ہم ایک سیریز کا حساب لگا رہے ہیں، اور پھر اس سیریز کو بائیں طرف تفویض کر رہے ہیں، ایک اور کالم بنا رہے ہیں۔ اس لیے، ہم کسی بھی آپریشنز کا استعمال نہیں کر سکتے جو سیریز کے ساتھ مطابقت نہیں رکھتے، مثال کے طور پر، نیچے دیا گیا کوڈ غلط ہے:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
آخری مثال، جبکہ نحوی طور پر درست ہے، ہمیں غلط نتیجہ دیتی ہے، کیونکہ یہ سیریز B کی لمبائی کو کالم میں تمام اقدار پر تفویض کرتی ہے، اور انفرادی عناصر کی لمبائی نہیں جیسا کہ ہم نے ارادہ کیا تھا۔
اگر ہمیں اس طرح کے پیچیدہ اظہار کا حساب لگانے کی ضرورت ہو، تو ہم apply فنکشن استعمال کر سکتے ہیں۔ آخری مثال کو درج ذیل کے طور پر لکھا جا سکتا ہے:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
اوپر دیے گئے آپریشنز کے بعد، ہم درج ذیل ڈیٹا فریم کے ساتھ ختم ہوں گے:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
نمبرز کی بنیاد پر قطاروں کا انتخاب iloc کنسٹرکٹ کا استعمال کرتے ہوئے کیا جا سکتا ہے۔ مثال کے طور پر، ڈیٹا فریم سے پہلی 5 قطاروں کو منتخب کرنے کے لیے:
df.iloc[:5]
گروپنگ اکثر پیوٹ ٹیبلز جیسا نتیجہ حاصل کرنے کے لیے استعمال ہوتی ہے جیسا کہ ایکسل میں۔ فرض کریں کہ ہم LenB کی دی گئی تعداد کے لیے کالم A کی اوسط قدر کا حساب لگانا چاہتے ہیں۔ پھر ہم اپنے ڈیٹا فریم کو LenB کے ذریعے گروپ کر سکتے ہیں، اور mean کال کر سکتے ہیں:
df.groupby(by='LenB').mean()
اگر ہمیں گروپ میں اوسط اور عناصر کی تعداد کا حساب لگانے کی ضرورت ہو، تو ہم زیادہ پیچیدہ aggregate فنکشن استعمال کر سکتے ہیں:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
یہ ہمیں درج ذیل ٹیبل دیتا ہے:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
ڈیٹا حاصل کرنا
ہم نے دیکھا کہ Python اشیاء سے Series اور DataFrames بنانا کتنا آسان ہے۔ تاہم، ڈیٹا عام طور پر ٹیکسٹ فائل یا Excel ٹیبل کی شکل میں آتا ہے۔ خوش قسمتی سے، Pandas ہمیں ڈسک سے ڈیٹا لوڈ کرنے کا ایک آسان طریقہ فراہم کرتا ہے۔ مثال کے طور پر، CSV فائل پڑھنا اتنا ہی آسان ہے:
df = pd.read_csv('file.csv')
ہم ڈیٹا لوڈ کرنے کی مزید مثالیں دیکھیں گے، بشمول اسے بیرونی ویب سائٹس سے حاصل کرنا، "Challenge" سیکشن میں۔
پرنٹنگ اور پلاٹنگ
ایک Data Scientist کو اکثر ڈیٹا کا جائزہ لینا پڑتا ہے، اس لیے اسے بصری طور پر دیکھنا ضروری ہے۔ جب DataFrame بڑا ہو، تو اکثر ہم صرف یہ یقینی بنانا چاہتے ہیں کہ ہم سب کچھ صحیح طریقے سے کر رہے ہیں، اور اس کے لیے ابتدائی چند قطاریں پرنٹ کرتے ہیں۔ یہ df.head() کال کرکے کیا جا سکتا ہے۔ اگر آپ اسے Jupyter Notebook سے چلا رہے ہیں، تو یہ DataFrame کو ایک خوبصورت جدول کی شکل میں پرنٹ کرے گا۔
ہم نے plot فنکشن کا استعمال بھی دیکھا ہے تاکہ کچھ کالمز کو بصری طور پر دکھایا جا سکے۔ جبکہ plot بہت سے کاموں کے لیے مفید ہے اور kind= پیرامیٹر کے ذریعے مختلف قسم کے گرافز کو سپورٹ کرتا ہے، آپ ہمیشہ خام matplotlib لائبریری استعمال کر سکتے ہیں تاکہ کچھ زیادہ پیچیدہ چیزیں پلاٹ کریں۔ ہم ڈیٹا کی بصری نمائندگی کو الگ کورس کے اسباق میں تفصیل سے کور کریں گے۔
یہ جائزہ Pandas کے سب سے اہم تصورات کو کور کرتا ہے، تاہم، یہ لائبریری بہت وسیع ہے، اور آپ اس کے ساتھ جو کچھ کر سکتے ہیں اس کی کوئی حد نہیں ہے! آئیے اب اس علم کو مخصوص مسئلے کو حل کرنے کے لیے استعمال کریں۔
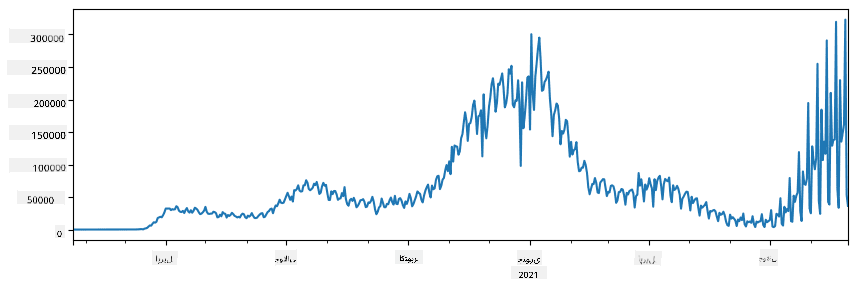
🚀 چیلنج 1: COVID کے پھیلاؤ کا تجزیہ
پہلا مسئلہ جس پر ہم توجہ مرکوز کریں گے وہ COVID-19 کے وبائی پھیلاؤ کی ماڈلنگ ہے۔ ایسا کرنے کے لیے، ہم مختلف ممالک میں متاثرہ افراد کی تعداد کے ڈیٹا کا استعمال کریں گے، جو Center for Systems Science and Engineering (CSSE) نے Johns Hopkins University میں فراہم کیا ہے۔ ڈیٹا سیٹ اس GitHub Repository میں دستیاب ہے۔
چونکہ ہم یہ دکھانا چاہتے ہیں کہ ڈیٹا کے ساتھ کیسے کام کیا جائے، ہم آپ کو دعوت دیتے ہیں کہ notebook-covidspread.ipynb کھولیں اور اسے شروع سے آخر تک پڑھیں۔ آپ سیلز کو چلا سکتے ہیں اور کچھ چیلنجز کر سکتے ہیں جو ہم نے آپ کے لیے آخر میں چھوڑے ہیں۔
اگر آپ کو Jupyter Notebook میں کوڈ چلانے کا طریقہ معلوم نہیں ہے، تو اس مضمون کو دیکھیں۔
غیر ساختہ ڈیٹا کے ساتھ کام کرنا
جبکہ ڈیٹا اکثر جدول کی شکل میں آتا ہے، کچھ معاملات میں ہمیں کم ساختہ ڈیٹا کے ساتھ کام کرنا پڑتا ہے، جیسے کہ متن یا تصاویر۔ اس صورت میں، اوپر دیکھے گئے ڈیٹا پروسیسنگ تکنیکوں کو لاگو کرنے کے لیے، ہمیں کسی طرح ساختہ ڈیٹا نکالنا ہوگا۔ یہاں کچھ مثالیں ہیں:
- متن سے کلیدی الفاظ نکالنا، اور یہ دیکھنا کہ وہ کلیدی الفاظ کتنی بار ظاہر ہوتے ہیں۔
- نیورل نیٹ ورکس کا استعمال کرتے ہوئے تصویر میں موجود اشیاء کے بارے میں معلومات نکالنا۔
- ویڈیو کیمرہ فیڈ پر لوگوں کے جذبات کے بارے میں معلومات حاصل کرنا۔
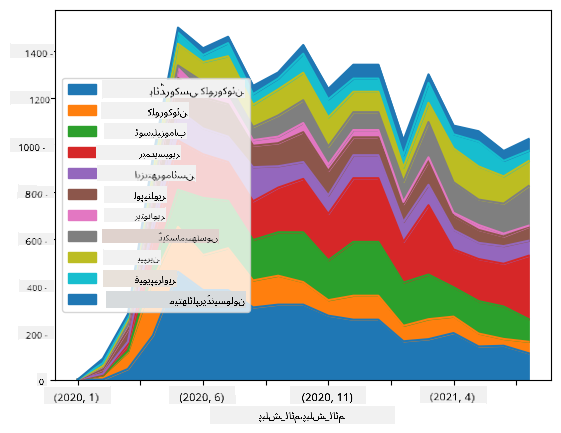
🚀 چیلنج 2: COVID کے مقالوں کا تجزیہ
اس چیلنج میں، ہم COVID وبائی مرض کے موضوع کو جاری رکھیں گے اور اس موضوع پر سائنسی مقالوں کی پروسیسنگ پر توجہ مرکوز کریں گے۔ CORD-19 Dataset میں COVID پر 7000 سے زیادہ (لکھنے کے وقت) مقالے دستیاب ہیں، جن میں میٹا ڈیٹا اور خلاصے شامل ہیں (اور ان میں سے تقریباً نصف کے لیے مکمل متن بھی فراہم کیا گیا ہے)۔
اس ڈیٹا سیٹ کا تجزیہ کرنے کی ایک مکمل مثال Text Analytics for Health کوگنیٹو سروس کا استعمال کرتے ہوئے اس بلاگ پوسٹ میں بیان کی گئی ہے۔ ہم اس تجزیے کا ایک آسان ورژن پر بات کریں گے۔
NOTE: ہم اس ریپوزٹری کے حصے کے طور پر ڈیٹا سیٹ کی کاپی فراہم نہیں کرتے۔ آپ کو پہلے
metadata.csvفائل Kaggle کے اس ڈیٹا سیٹ سے ڈاؤن لوڈ کرنے کی ضرورت ہو سکتی ہے۔ Kaggle کے ساتھ رجسٹریشن کی ضرورت ہو سکتی ہے۔ آپ رجسٹریشن کے بغیر یہاں سے ڈیٹا سیٹ ڈاؤن لوڈ کر سکتے ہیں، لیکن اس میں میٹا ڈیٹا فائل کے علاوہ تمام مکمل متن شامل ہوں گے۔
notebook-papers.ipynb کھولیں اور اسے شروع سے آخر تک پڑھیں۔ آپ سیلز کو چلا سکتے ہیں اور کچھ چیلنجز کر سکتے ہیں جو ہم نے آپ کے لیے آخر میں چھوڑے ہیں۔
تصویری ڈیٹا کی پروسیسنگ
حال ہی میں، بہت طاقتور AI ماڈلز تیار کیے گئے ہیں جو ہمیں تصاویر کو سمجھنے کی اجازت دیتے ہیں۔ بہت سے کام ہیں جو پری ٹرینڈ نیورل نیٹ ورکس یا کلاؤڈ سروسز کا استعمال کرتے ہوئے حل کیے جا سکتے ہیں۔ کچھ مثالیں شامل ہیں:
- تصویری درجہ بندی، جو آپ کو تصویر کو پہلے سے طے شدہ کلاسز میں سے کسی ایک میں تقسیم کرنے میں مدد دے سکتی ہے۔ آپ آسانی سے Custom Vision جیسی سروسز کا استعمال کرتے ہوئے اپنے تصویری درجہ بندی کرنے والے ماڈلز بنا سکتے ہیں۔
- آبجیکٹ ڈیٹیکشن، جو تصویر میں مختلف اشیاء کا پتہ لگانے میں مدد کرتا ہے۔ computer vision جیسی سروسز عام اشیاء کا پتہ لگا سکتی ہیں، اور آپ Custom Vision ماڈل کو مخصوص اشیاء کا پتہ لگانے کے لیے تربیت دے سکتے ہیں۔
- چہرے کا پتہ لگانا، بشمول عمر، جنس اور جذبات کا پتہ لگانا۔ یہ Face API کے ذریعے کیا جا سکتا ہے۔
یہ تمام کلاؤڈ سروسز Python SDKs کا استعمال کرتے ہوئے کال کی جا سکتی ہیں، اور اس طرح آپ کے ڈیٹا ایکسپلوریشن ورک فلو میں آسانی سے شامل کی جا سکتی ہیں۔
یہاں تصویری ڈیٹا ذرائع سے ڈیٹا کو دریافت کرنے کی کچھ مثالیں ہیں:
- بلاگ پوسٹ How to Learn Data Science without Coding میں ہم Instagram تصاویر کا جائزہ لیتے ہیں، یہ سمجھنے کی کوشش کرتے ہیں کہ کون سی چیز لوگوں کو تصویر پر زیادہ لائکس دینے پر مجبور کرتی ہے۔ ہم پہلے computer vision کا استعمال کرتے ہوئے تصاویر سے زیادہ سے زیادہ معلومات نکالتے ہیں، اور پھر Azure Machine Learning AutoML کا استعمال کرتے ہوئے ایک قابل وضاحت ماڈل بناتے ہیں۔
- Facial Studies Workshop میں ہم Face API کا استعمال کرتے ہوئے ایونٹس کی تصاویر میں لوگوں کے جذبات نکالتے ہیں، تاکہ یہ سمجھ سکیں کہ کون سی چیز لوگوں کو خوش کرتی ہے۔
نتیجہ
چاہے آپ کے پاس پہلے سے ساختہ یا غیر ساختہ ڈیٹا ہو، Python کا استعمال کرتے ہوئے آپ ڈیٹا پروسیسنگ اور سمجھنے سے متعلق تمام مراحل انجام دے سکتے ہیں۔ یہ ڈیٹا پروسیسنگ کا سب سے لچکدار طریقہ ہے، اور یہی وجہ ہے کہ زیادہ تر ڈیٹا سائنسدان Python کو اپنا بنیادی ٹول کے طور پر استعمال کرتے ہیں۔ اگر آپ اپنے ڈیٹا سائنس کے سفر میں سنجیدہ ہیں تو Python کو گہرائی سے سیکھنا شاید ایک اچھا خیال ہے!
لیکچر کے بعد کا کوئز
جائزہ اور خود مطالعہ
کتب
آن لائن وسائل
- Pandas کا آفیشل 10 منٹ کا ٹیوٹوریل
- Pandas Visualization پر دستاویزات
Python سیکھنا
- Learn Python in a Fun Way with Turtle Graphics and Fractals
- Python کے ساتھ اپنے پہلے قدم اٹھائیں Microsoft Learn پر لرننگ پاتھ Microsoft Learn
اسائنمنٹ
اوپر دیے گئے چیلنجز کے لیے مزید تفصیلی ڈیٹا اسٹڈی کریں
کریڈٹس
یہ سبق Dmitry Soshnikov کے ذریعے ♥️ کے ساتھ لکھا گیا ہے۔
ڈس کلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے پوری کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا عدم درستگی ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے لیے ہم ذمہ دار نہیں ہیں۔