|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
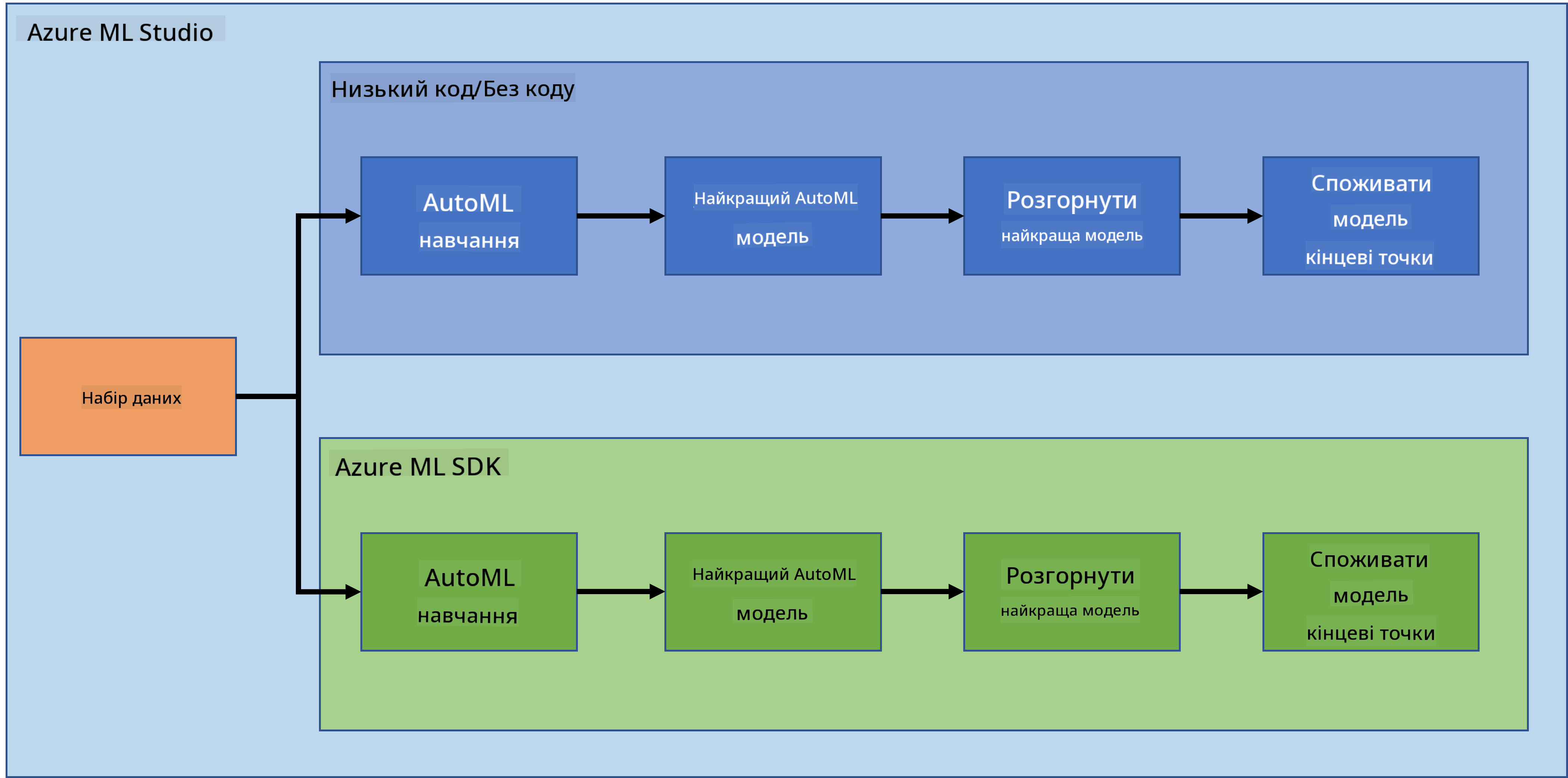
Наука про дані в хмарі: шлях "Azure ML SDK"
 |
|---|
| Наука про дані в хмарі: Azure ML SDK - Скетчнот від @nitya |
Зміст:
- Наука про дані в хмарі: шлях "Azure ML SDK"
Передлекційна вікторина
1. Вступ
1.1 Що таке Azure ML SDK?
Науковці з даних та розробники штучного інтелекту використовують Azure Machine Learning SDK для створення та виконання робочих процесів машинного навчання за допомогою сервісу Azure Machine Learning. Ви можете взаємодіяти з цим сервісом у будь-якому середовищі Python, включаючи Jupyter Notebooks, Visual Studio Code або ваш улюблений Python IDE.
Основні можливості SDK включають:
- Дослідження, підготовка та управління життєвим циклом наборів даних, які використовуються в експериментах машинного навчання.
- Управління хмарними ресурсами для моніторингу, ведення журналів та організації експериментів машинного навчання.
- Навчання моделей локально або з використанням хмарних ресурсів, включаючи прискорене GPU навчання.
- Використання автоматизованого машинного навчання, яке приймає параметри конфігурації та навчальні дані. Воно автоматично перебирає алгоритми та налаштування гіперпараметрів, щоб знайти найкращу модель для прогнозування.
- Розгортання вебсервісів для перетворення ваших навчальних моделей у RESTful сервіси, які можна використовувати в будь-якому додатку.
Дізнайтеся більше про Azure Machine Learning SDK
У попередньому уроці ми розглянули, як навчати, розгортати та використовувати модель у режимі Low code/No code. Ми використовували набір даних про серцеву недостатність для створення моделі прогнозування. У цьому уроці ми зробимо те саме, але використовуючи Azure Machine Learning SDK.
1.2 Проєкт прогнозування серцевої недостатності та ознайомлення з набором даних
Ознайомтеся з попереднім уроком для введення в проєкт прогнозування серцевої недостатності та набір даних.
2. Навчання моделі за допомогою Azure ML SDK
2.1 Створення робочого простору Azure ML
Для зручності ми будемо працювати в Jupyter Notebook. Це передбачає, що у вас вже є робочий простір і обчислювальний екземпляр. Якщо у вас вже є робочий простір, ви можете перейти безпосередньо до розділу 2.3 Створення ноутбука.
Якщо ні, будь ласка, дотримуйтесь інструкцій у розділі 2.1 Створення робочого простору Azure ML у попередньому уроці, щоб створити робочий простір.
2.2 Створення обчислювального екземпляра
У робочому просторі Azure ML, який ми створили раніше, перейдіть до меню Compute, і ви побачите різні доступні обчислювальні ресурси.
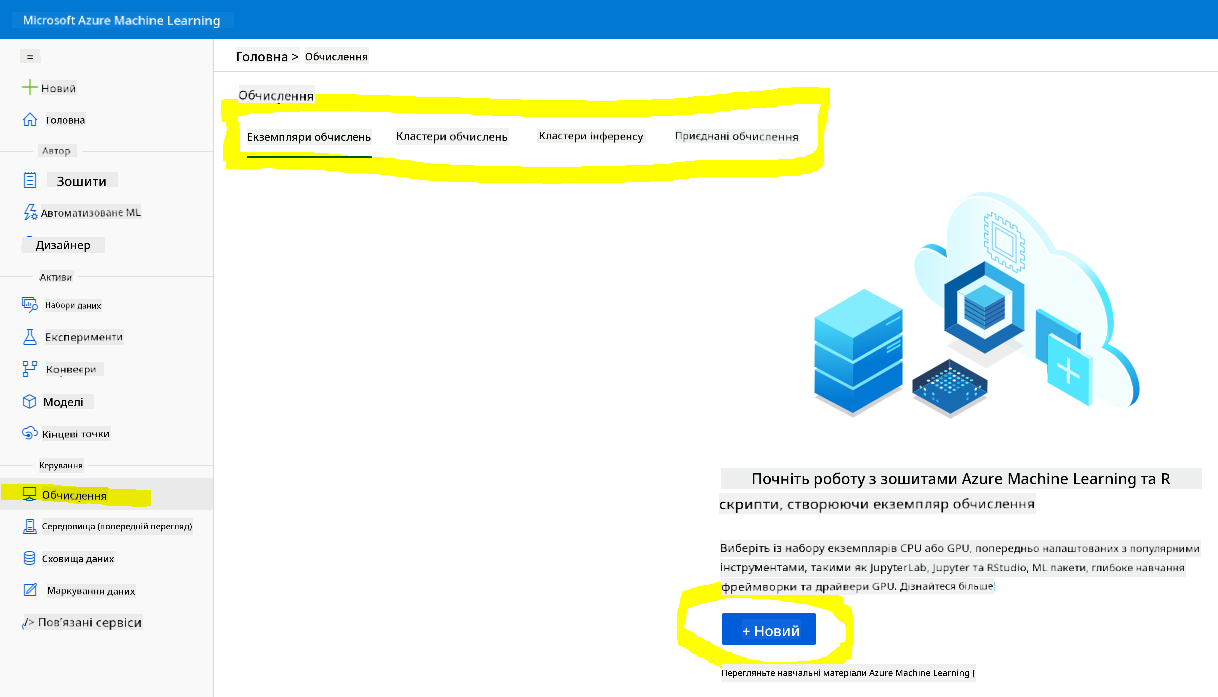
Давайте створимо обчислювальний екземпляр для запуску Jupyter Notebook.
- Натисніть кнопку + New.
- Дайте ім'я вашому обчислювальному екземпляру.
- Виберіть параметри: CPU або GPU, розмір віртуальної машини та кількість ядер.
- Натисніть кнопку Create.
Вітаємо, ви щойно створили обчислювальний екземпляр! Ми будемо використовувати цей екземпляр для створення ноутбука в розділі Створення ноутбуків.
2.3 Завантаження набору даних
Якщо ви ще не завантажили набір даних, зверніться до розділу 2.3 Завантаження набору даних у попередньому уроці.
2.4 Створення ноутбуків
ПРИМІТКА: На наступному кроці ви можете або створити новий ноутбук з нуля, або завантажити ноутбук, який ми створили у вашому Azure ML Studio. Щоб завантажити його, просто натисніть на меню "Notebook" і завантажте ноутбук.
Ноутбуки є дуже важливою частиною процесу науки про дані. Вони можуть використовуватися для проведення дослідження даних (EDA), виклику обчислювального кластера для навчання моделі, виклику кластера для розгортання кінцевої точки.
Щоб створити ноутбук, нам потрібен обчислювальний вузол, який обслуговує екземпляр Jupyter Notebook. Поверніться до робочого простору Azure ML і натисніть на Compute instances. У списку обчислювальних екземплярів ви повинні побачити екземпляр, який ми створили раніше.
- У розділі Applications натисніть на опцію Jupyter.
- Поставте галочку "Yes, I understand" і натисніть кнопку Continue.

- Це відкриє нову вкладку браузера з вашим екземпляром Jupyter Notebook. Натисніть кнопку "New", щоб створити ноутбук.
Тепер, коли у нас є ноутбук, ми можемо почати навчання моделі за допомогою Azure ML SDK.
2.5 Навчання моделі
Перш за все, якщо у вас виникнуть сумніви, зверніться до документації Azure ML SDK. У ній міститься вся необхідна інформація для розуміння модулів, які ми розглянемо в цьому уроці.
2.5.1 Налаштування робочого простору, експерименту, обчислювального кластера та набору даних
Вам потрібно завантажити workspace з конфігураційного файлу за допомогою наступного коду:
from azureml.core import Workspace
ws = Workspace.from_config()
Це повертає об'єкт типу Workspace, який представляє робочий простір. Потім вам потрібно створити experiment за допомогою наступного коду:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Щоб отримати або створити експеримент у робочому просторі, ви запитуєте експеримент за його назвою. Назва експерименту має бути від 3 до 36 символів, починатися з літери або цифри та може містити лише літери, цифри, підкреслення та дефіси. Якщо експеримент не знайдено в робочому просторі, створюється новий експеримент.
Тепер вам потрібно створити обчислювальний кластер для навчання за допомогою наступного коду. Зверніть увагу, що цей крок може зайняти кілька хвилин.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Ви можете отримати набір даних із робочого простору за назвою набору даних наступним чином:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Конфігурація AutoML та навчання
Щоб налаштувати конфігурацію AutoML, використовуйте клас AutoMLConfig.
Як описано в документації, існує багато параметрів, з якими ви можете експериментувати. Для цього проєкту ми будемо використовувати наступні параметри:
experiment_timeout_minutes: Максимальний час (у хвилинах), дозволений для виконання експерименту перед його автоматичною зупинкою.max_concurrent_iterations: Максимальна кількість одночасних ітерацій навчання, дозволених для експерименту.primary_metric: Основна метрика, яка використовується для визначення статусу експерименту.compute_target: Обчислювальна ціль Azure Machine Learning для запуску експерименту автоматизованого машинного навчання.task: Тип завдання для виконання. Значення можуть бути 'classification', 'regression' або 'forecasting' залежно від типу проблеми автоматизованого ML.training_data: Навчальні дані, які використовуються в експерименті. Вони повинні містити як навчальні ознаки, так і стовпець міток (опціонально стовпець ваг зразків).label_column_name: Назва стовпця міток.path: Повний шлях до папки проєкту Azure Machine Learning.enable_early_stopping: Чи дозволити раннє завершення, якщо оцінка не покращується в короткостроковій перспективі.featurization: Індикатор того, чи слід автоматично виконувати крок феатуризації, чи використовувати налаштовану феатуризацію.debug_log: Файл журналу для запису відомостей про налагодження.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Тепер, коли ваша конфігурація налаштована, ви можете навчати модель за допомогою наступного коду. Цей крок може зайняти до години залежно від розміру вашого кластера.
remote_run = experiment.submit(automl_config)
Ви можете запустити віджет RunDetails, щоб переглянути різні експерименти.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Розгортання моделі та використання кінцевої точки за допомогою Azure ML SDK
3.1 Збереження найкращої моделі
Об'єкт remote_run є об'єктом типу AutoMLRun. Цей об'єкт містить метод get_output(), який повертає найкращий запуск і відповідну навчальну модель.
best_run, fitted_model = remote_run.get_output()
Ви можете переглянути параметри, використані для найкращої моделі, просто вивівши fitted_model, і переглянути властивості найкращої моделі за допомогою методу get_properties().
best_run.get_properties()
Тепер зареєструйте модель за допомогою методу register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Розгортання моделі
Після збереження найкращої моделі ми можемо розгорнути її за допомогою класу InferenceConfig. InferenceConfig представляє налаштування конфігурації для користувацького середовища, яке використовується для розгортання. Клас AciWebservice представляє модель машинного навчання, розгорнуту як кінцева точка вебсервісу на Azure Container Instances. Розгорнутий сервіс створюється з моделі, скрипта та пов'язаних файлів. Отриманий вебсервіс є збалансованою за навантаженням HTTP-кінцевою точкою з REST API. Ви можете надсилати дані до цього API і отримувати прогноз, повернутий моделлю.
Модель розгортається за допомогою методу deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Цей крок має зайняти кілька хвилин.
3.3 Використання кінцевої точки
Ви можете використовувати вашу кінцеву точку, створивши зразок вхідних даних:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
А потім ви можете надіслати ці вхідні дані до вашої моделі для отримання прогнозу:
response = aci_service.run(input_data=test_sample)
response
Це має вивести '{"result": [false]}'. Це означає, що введені дані пацієнта, які ми надіслали на кінцеву точку, згенерували прогноз false, що вказує на те, що ця людина, ймовірно, не має ризику серцевого нападу.
Вітаємо! Ви щойно використали модель, розгорнуту та навчану на Azure ML за допомогою Azure ML SDK!
NOTE: Після завершення проєкту не забудьте видалити всі ресурси.
🚀 Виклик
Існує багато інших речей, які можна зробити за допомогою SDK, на жаль, ми не можемо розглянути їх усі в цьому уроці. Але гарна новина: навчитися швидко переглядати документацію SDK може значно допомогти вам у самостійному навчанні. Ознайомтеся з документацією Azure ML SDK і знайдіть клас Pipeline, який дозволяє створювати конвеєри. Конвеєр — це набір кроків, які можна виконувати як робочий процес.
ПІДКАЗКА: Перейдіть до документації SDK і введіть ключові слова, такі як "Pipeline", у рядок пошуку. Ви повинні побачити клас azureml.pipeline.core.Pipeline у результатах пошуку.
Післялекційний тест
Огляд і самостійне навчання
У цьому уроці ви дізналися, як навчати, розгортати та використовувати модель для прогнозування ризику серцевої недостатності за допомогою Azure ML SDK у хмарі. Ознайомтеся з цією документацією для отримання додаткової інформації про Azure ML SDK. Спробуйте створити власну модель за допомогою Azure ML SDK.
Завдання
Проєкт з науки про дані за допомогою Azure ML SDK
Відмова від відповідальності:
Цей документ було перекладено за допомогою сервісу автоматичного перекладу Co-op Translator. Хоча ми прагнемо до точності, звертаємо вашу увагу, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ мовою оригіналу слід вважати авторитетним джерелом. Для критично важливої інформації рекомендується професійний переклад людиною. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникли внаслідок використання цього перекладу.