16 KiB
Вступ до життєвого циклу науки про дані
 |
|---|
| Вступ до життєвого циклу науки про дані - Скетчноут від @nitya |
Тест перед лекцією
На цьому етапі ви, ймовірно, вже зрозуміли, що наука про дані — це процес. Цей процес можна розділити на 5 етапів:
- Збір
- Обробка
- Аналіз
- Комунікація
- Підтримка
Цей урок зосереджений на трьох частинах життєвого циклу: зборі, обробці та підтримці.
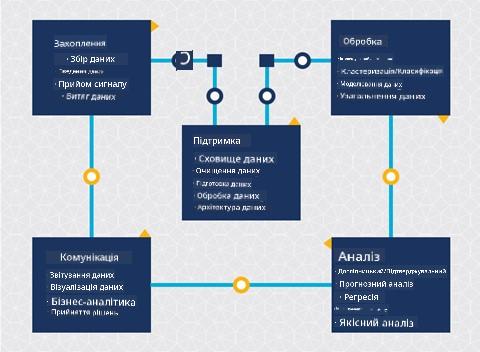
Фото від Berkeley School of Information
Збір
Перший етап життєвого циклу є дуже важливим, оскільки наступні етапи залежать від нього. Це фактично два етапи, об’єднані в один: отримання даних і визначення мети та проблем, які потрібно вирішити.
Визначення цілей проєкту потребує глибшого розуміння проблеми або питання. Спочатку потрібно ідентифікувати та залучити тих, хто потребує вирішення своєї проблеми. Це можуть бути зацікавлені сторони бізнесу або спонсори проєкту, які допоможуть визначити, хто або що отримає користь від цього проєкту, а також що і чому їм це потрібно. Добре визначена мета має бути вимірюваною та кількісною, щоб визначити прийнятний результат.
Питання, які може поставити спеціаліст з даних:
- Чи раніше вже підходили до цієї проблеми? Що було виявлено?
- Чи всі учасники розуміють мету та ціль?
- Чи є неоднозначність і як її зменшити?
- Які обмеження існують?
- Як може виглядати кінцевий результат?
- Скільки ресурсів (часу, людей, обчислювальних потужностей) доступно?
Далі потрібно ідентифікувати, зібрати, а потім дослідити дані, необхідні для досягнення визначених цілей. На цьому етапі збору спеціалісти з даних також повинні оцінити кількість і якість даних. Це потребує певного дослідження даних, щоб підтвердити, що отримані дані допоможуть досягти бажаного результату.
Питання, які може поставити спеціаліст з даних щодо даних:
- Які дані вже доступні для мене?
- Хто є власником цих даних?
- Які існують проблеми конфіденційності?
- Чи достатньо даних для вирішення цієї проблеми?
- Чи є дані прийнятної якості для цієї проблеми?
- Якщо я виявлю додаткову інформацію через ці дані, чи варто нам розглянути зміну або переосмислення цілей?
Обробка
Етап обробки в життєвому циклі зосереджений на виявленні закономірностей у даних, а також моделюванні. Деякі методи, які використовуються на етапі обробки, потребують статистичних підходів для виявлення закономірностей. Зазвичай це було б трудомістким завданням для людини при роботі з великим набором даних, тому використовуються комп’ютери для прискорення процесу. На цьому етапі наука про дані та машинне навчання перетинаються. Як ви дізналися в першому уроці, машинне навчання — це процес створення моделей для розуміння даних. Моделі є представленням взаємозв’язків між змінними в даних, які допомагають прогнозувати результати.
Поширені методи, які використовуються на цьому етапі, розглядаються в навчальній програмі ML для початківців. Перейдіть за посиланнями, щоб дізнатися більше про них:
- Класифікація: Організація даних у категорії для більш ефективного використання.
- Кластеризація: Групування даних у схожі групи.
- Регресія: Визначення взаємозв’язків між змінними для прогнозування або передбачення значень.
Підтримка
На схемі життєвого циклу ви могли помітити, що підтримка знаходиться між збором і обробкою. Підтримка — це постійний процес управління, зберігання та захисту даних протягом усього процесу проєкту, і її слід враховувати протягом усього проєкту.
Зберігання даних
Рішення про те, як і де зберігати дані, може вплинути на вартість їх зберігання, а також на продуктивність доступу до даних. Такі рішення, ймовірно, не приймаються виключно спеціалістом з даних, але він може приймати рішення про те, як працювати з даними, залежно від способу їх зберігання.
Ось деякі аспекти сучасних систем зберігання даних, які можуть вплинути на ці рішення:
Локальне зберігання vs віддалене зберігання vs публічна чи приватна хмара
Локальне зберігання передбачає управління даними на власному обладнанні, наприклад, на сервері з жорсткими дисками, які зберігають дані, тоді як віддалене зберігання покладається на обладнання, яке вам не належить, наприклад, дата-центр. Публічна хмара є популярним вибором для зберігання даних, що не потребує знань про те, як або де саме зберігаються дані, де "публічна" означає єдину інфраструктуру, яка використовується всіма користувачами хмари. Деякі організації мають суворі політики безпеки, які вимагають повного доступу до обладнання, де зберігаються дані, і покладаються на приватну хмару, яка надає власні хмарні послуги. Ви дізнаєтеся більше про дані в хмарі в наступних уроках.
Холодні vs гарячі дані
Під час навчання моделей вам може знадобитися більше навчальних даних. Якщо ви задоволені своєю моделлю, нові дані будуть надходити для виконання її функцій. У будь-якому випадку вартість зберігання та доступу до даних зростатиме зі збільшенням їх обсягу. Розділення рідко використовуваних даних, відомих як холодні дані, від часто доступних гарячих даних може бути дешевшим варіантом зберігання даних через апаратні або програмні послуги. Якщо холодні дані потрібно отримати, це може зайняти трохи більше часу порівняно з гарячими даними.
Управління даними
Під час роботи з даними ви можете виявити, що деякі дані потребують очищення за допомогою методів, розглянутих у уроці, присвяченому підготовці даних, щоб створити точні моделі. Коли надходять нові дані, їм знадобляться ті самі дії для підтримки якості. Деякі проєкти передбачають використання автоматизованого інструменту для очищення, агрегування та стиснення даних перед їх переміщенням до кінцевого місця зберігання. Azure Data Factory є прикладом одного з таких інструментів.
Захист даних
Однією з головних цілей захисту даних є забезпечення того, щоб ті, хто працює з ними, контролювали, що збирається і в якому контексті це використовується. Захист даних передбачає обмеження доступу лише для тих, хто його потребує, дотримання місцевих законів і нормативних актів, а також підтримання етичних стандартів, як розглянуто в уроці про етику.
Ось деякі дії, які команда може виконати з урахуванням безпеки:
- Переконатися, що всі дані зашифровані
- Надати клієнтам інформацію про те, як використовуються їхні дані
- Видалити доступ до даних у тих, хто залишив проєкт
- Дозволити змінювати дані лише певним членам проєкту
🚀 Виклик
Існує багато версій життєвого циклу науки про дані, де кожен етап може мати різні назви та кількість стадій, але міститиме ті самі процеси, згадані в цьому уроці.
Дослідіть життєвий цикл процесу команди науки про дані та стандартний процес для добування даних у різних галузях. Назвіть 3 схожості та відмінності між ними.
| Процес команди науки про дані (TDSP) | Стандартний процес для добування даних у різних галузях (CRISP-DM) |
|---|---|
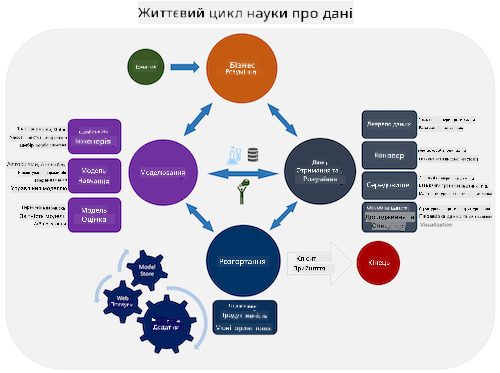 |
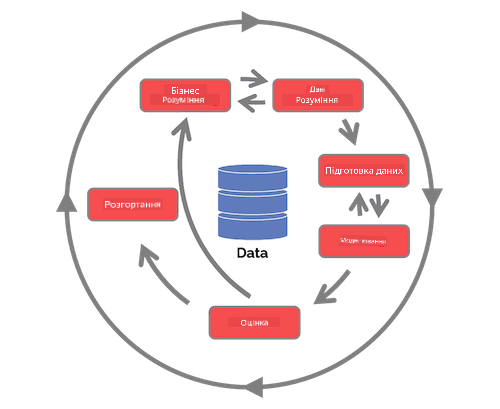 |
| Зображення від Microsoft | Зображення від Data Science Process Alliance |
Тест після лекції
Огляд і самостійне навчання
Застосування життєвого циклу науки про дані передбачає виконання різних ролей і завдань, де деякі можуть зосереджуватися на конкретних частинах кожного етапу. Процес команди науки про дані надає кілька ресурсів, які пояснюють типи ролей і завдань, які може виконувати хтось у проєкті.
- Ролі та завдання процесу команди науки про дані
- Виконання завдань науки про дані: дослідження, моделювання та розгортання
Завдання
Відмова від відповідальності:
Цей документ було перекладено за допомогою сервісу автоматичного перекладу Co-op Translator. Хоча ми прагнемо до точності, звертаємо вашу увагу, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ мовою оригіналу слід вважати авторитетним джерелом. Для критично важливої інформації рекомендується професійний переклад людиною. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникли внаслідок використання цього перекладу.